강의 복습 내용
[DAY 10] 시각화 / 통계학
[AI Math 7강] 시각화 도구
- matplotlib
- pyplot 객체를 사용하여 데이터를 표시
- pyplot 객체에 그래프들을 쌓은 다음 flush
- 최대 단점 argument를 kwards로 받음
- 고정된 argument가 없어서 alt+tab으로 확인이 어려움
- Graph는 원래 figure 객체에 생성됨
- pyplot 객체 사용시, 기본 figure에 그래프가 그려짐
- Figure & Axes
- Matploylib은 Figure 안에 Axes로 구성
- Figure 위에 여러 개의 Axes를 생성
- subplot : Subplot의 순서를 grid로 작성
- set color
- color 속성을 사용
- float : 흑백, rgd color, predefined color 사용
- set linestyle : ls 또는 linestyle 속성 사용
- set title
- pyplot에 title 함수 사용, figure의 subplot별 입력 가능
- latex 타입의 표현도 가능 (수식 표현 가능)
- set legend : legend 함수로 범례를 표시함, loc 위치 등 속성 지정
- set grid & xylim : Graph 보조선을 긋는 grid와 xy축 범위 한계를 지정
- scatter
- scatter 함수 사용, marker : scatter 모양 지정
- s : 데이터의 크기를 지정, 데이터의 크기 비교 가능
- bar chart : bar 함수 사용
- histogram : hist 함수 사용
- boxplot : boxplot 함수 사용
- seaborn
- statistical data visualization
- 기존 matplotlib에 기본 설정을 추가
- 복잡한 그래프를 간단하게 만들 수 있는 wrapper
- 간단한 코드 + 예쁜 결과
- basic plots
- matplotlib과 같은 기본적인 plot
- 손쉬운 설정으로 데이터 산출
- lineplot, scatterplot, countplot 등
- predefined plots
- Viloinplot : boxplot에 distribution을 함께 표현
- Stripplot : scatter과 category 정보를 함께 표현
- Swarmplot : 분포와 함께 scatter을 함께 표현
- Pointplot : category 별로 numeric의 평균, 신뢰구간 표시
- replot : scatter + 선형함수를 함께 표시
- multiple plots
- 한 개 이상의 도표를 하나의 plot에 작성
- Axes를 사용해서 grid를 나누는 방법
- predefined multiple plots
- replot : Numeric 데이터 중심의 분포 / 선형 표시
- catplot : category 데이터 중심의 표시
- FacetGrid : 특정 조건에 따른 다양한 plot을 grid로 표시
- pairplot : 데이터 간의 상관관계 표시
- Import : regression 모델과 category 데이터를 함께 표시
[AI Math 7강] 통계학 맛보기
- 모수가 뭐에요?
- 통계적 모델링은 적절한 가정 위에서 확률분포를 추정(inference)하는 것이 목표이며, 기계학습과 통계학이 공통적으로 추구하는 목표입니다.
- 그러나 유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정할 수 밖에 없습니다.
- 데이터가 특정 확률분포를 따른다고 선험적으로(a priori) 가정한 후 그 분포를 결정하는 모수(parameter)를 추정하는 방법을 모수적(parametric) 방 법론이라 합니다.
- 특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수(nonparametric) 방법론이라 부릅니다.
- 확률분포 가정하기: 예제
- 확률분포를 가정하는 방법: 우선 히스토그램을 통해 모양을 관찰합니다.
- 데이터가 2개의 값(0 또는 1)만 가지는 경우 → 베르누이분포
- 데이터가 n개의 이산적인 값을 가지는 경우 → 카테고리분포
- 데이터가 [0,1] 사이에서 값을 가지는 경우 → 베타분포
- 데이터가 0 이상의 값을 가지는 경우 → 감마분포, 로그정규분포 등
- 데이터가 R 전체에서 값을 가지는 경우 → 정규분포, 라플라스분포 등
- 기계적으로 확률분포를 가정해서는 안 되며, 데이터를 생성하는 원리를 먼저 고려하는 것이 원칙입니다.
- 확률분포를 가정하는 방법: 우선 히스토그램을 통해 모양을 관찰합니다.
- 데이터로 모수를 추정해보자!
- 데이터의 확률분포를 가정했다면 모수를 추정해볼 수 있습니다.
- 정규분포의 모수는 평균 μ과 분산 σ^2으로 이를 추정하는 통계량(statistic)은 다음과 같다.
- 통계량의 확률분포를 표집분포(sampling distribution)라 부르며, 특히 표본평균의 표집분포는 N 이 커질수록 정규분포 𝒩(μ, σ2/N)를 따릅니다.
- 최대가능도 추정법
- 표본평균이나 표본분산은 중요한 통계량이지만 확률분포마다 사용하는 모수가 다르므로 적절한 통계량이 달라지게 됩니다.
- 이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나는 최대가능도 추정법(maximum likelihood estimation, MLE)입니다.
- 데이터 집합 X 가 독립적으로 추출되었을 경우 로그가능도를 최적화합니다.
- 왜 로그가능도를 사용하나요?
- 로그가능도를 최적화하는 모수 θ 는 가능도를 최적화하는 MLE 가 됩니다.
- 데이터의 숫자가 적으면 상관없지만 만일 데이터의 숫자가 수억 단위가 된다면 컴퓨터의 정확도로는 가능도를 계산하는 것은 불가능합니다.
- 데이터가 독립일 경우, 로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀 수 있기 때문에 컴퓨터로 연산이 가능해집니다.
- 경사하강법으로 가능도를 최적화할 때 미분 연산을 사용하게 되는데, 로그가능도를 사용하면 연산량을 O(n2) 에서 O(n) 으로 줄여줍니다.
- 대게의 손실함수의 경우 경사하강법을 사용하므로 음의 로그가능도(negative log-likelihood)를 최적화하게 됩니다
- 딥러닝에서 최대가능도 추정법
- 최대가능도 추정법을 이용해서 기계학습 모델을 학습할 수 있습니다.
- 딥러닝 모델의 가중치를 θ = (W(1), ..., W(L))라 표기했을 때 분류 문제에서 소프트맥스 벡터는 카테고리분포의 모수 (p1, ..., pK)를 모델링합니다.
- 원핫벡터로 표현한 정답레이블 y = (y1, ..., yK) 을 관찰데이터로 이용해 확률분포인 소프트맥스 벡터의 로그가능도를 최적화할 수 있습니다.
- 확률분포의 거리를 구해보자
- 기계학습에서 사용되는 손실함수들은 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도합니다.
- 데이터공간에 두 개의 확률분포 P(x), Q(x) 가 있을 경우 두 확률분포 사이의 거리(distance)를 계산할 때 다음과 같은 함수들을 이용합니다.
- 총변동 거리 (Total Variation Distance, TV)
- 쿨백-라이블러 발산 (Kullback-Leibler Divergence, KL)
- 쿨백-라이블러 발산(KL Divergence)은 다음과 같이 정의합니다.
- 쿨백 라이블러는 다음과 같이 분해할 수 있습니다.
- 분류 문제에서 정답레이블을 P, 모델 예측을 Q 라 두면 최대가능도 추정법은 쿨백-라이블러 발산을 최소화하는 것과 같습니다.
- 바슈타인 거리 (Wasserstein Distance)
퀴즈 결과 회고
[AI Math 7강 퀴즈] 통계학 맛보기-1~5
- 표본 X의 평균 계산 (O)
- ans : 3
- 표본 X의 표본분산 계산 (O)
- ans : 2.5
- 표본 X의 표본표준편차 계산 (O)
- ans : 2
- 정답 레이블을 one-hot 벡터로 표현한다면 하나의 정답 레이블 벡터의 크기는 1이다. (O)
- ans : 아니오
- KL(P∥Q)는 KL(Q∥P)와 같다. (O)
- ans : 아니오
Further Question
1. 확률과 가능도의 차이는 무엇일까요? (개념적인 차이, 수식에서의 차이, 확률밀도함수에서의 차이)
- 개념적인 차이
- 확률 : 어떤 사건의 발생 확률은 그것이 일어날 수 있는 경우의 수 대 가능한 모든 경우의 수의 비입니다. 단, 이는 어떠한 사건도 다른 사건들 보다 더 많이 일어날 수 있다고 기대할 근거가 없을 때, 그러니까 모든 사건이 동일하게 일어날 수 있다고 할 때에 성립됩니다.
- 가능도 : 어떤 확률변수의 표집값과 일관되는 정도를 나타내는 값입니다. 구체적으로, 주어진 표집값에 대한 모수의 가능도는 이 모수를 따르는 분포가 주어진 관측값에 대하여 부여하는 확률입니다. 가능도 함수는 확률 분포가 아니며, 합하여 1이 되지 않을 수 있습니다.
- 수식에서의 차이
- 확률
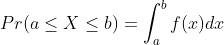
- 가능도 :

- 확률
- 확률 밀도 함수에서의 차이
- 확률
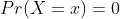
- 가능도
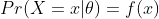
- 확률 질량 함수의 경우 : 확률 = 가능도
- 확률
2. 확률 대신 가능도를 사용하였을 때의 이점은 어떤 것이 있을까요?
- 최대가능도 추정법(maximum likelihood estimation, MLE)으로 이론적으로 가장 가능성이 높은 모수를 추정할 수 있다.
3. 다음의 code snippet은 어떤 확률분포를 나타내는 것일까요? 해당 확률분포에서 변수 theta가 의미할 수 있는 것은 무엇이 있을까요?
import numpy as np
import matplotlib.pyplot as plt
theta = np.arange(0, 1, 0.001)
p = theta ** 3 * (1 - theta) ** 7
plt.plot(theta, p)
plt.show()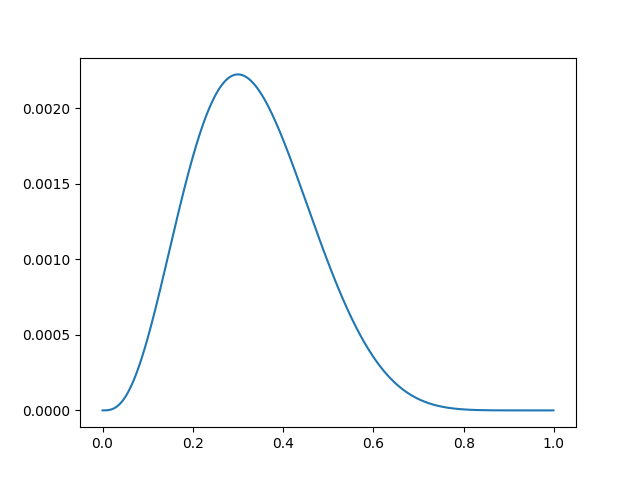
- n = 10, k = 3, p = θ인 이항 분포를 나타냅니다.
피어 세션 정리
강의 리뷰 및 Q&A
- [AI Math 7강] 시각화 도구
- [AI Math 7강] 통계학 맛보기
[개인] 총변동 거리 (Total Variation Distance, TV) & 바슈타인 거리 (Wasserstein Distance)
- 총변동 거리 (Total Variation Distance, TV) : 두 확률측도의 측정값이 벌어질 수 있는 값 중 가장 큰 값을 의미합니다.
- 바슈타인 거리 (Wasserstein Distance) : 모든 결합확률분포 Π(P,Q) 중에서 d(X,Y)의 기대값을 가장 작게 추정한 값을 의미합니다.
마스터 클래스
마스터 소개
AI를 위한 수학의 임성빈 교수님 (UNIST 인공지능대학원 교수님, 전 Kakao Brain Research Scientist)
사전 질문 답변
- AI 관련해서 추천 해주실만한 책이 있나요?
- 영어 : Dive into Deep Learning
- 한국어 : 밑바닥부터 시작하는 딥러닝
- AI를 공부하면서 수학의 중요성을 느낍니다. 확률론, 통계학, 선형대수 공부를 어떤 식으로 공부하는 것이 좋을까요?
- 수학과 코드를 함께 공부하는 것을 추천한다.
- 그래서 Dive into Deep Learning 교재를 추천했다.
- 강화학습 같은 경우 목적함수 설정이 어렵다고 알고 있습니다. 간단한 태스크가 아닌 복잡한 태스크의 목적함수는 수학자를 통해서 뚝딱 나오는 건지 아니면 거듭된 수정을 통해 나오는 건지 궁금합니다.
- 목적함수를 수학자들도 만들기는 하겠지만, 대부분의 경우 엔지니어들이 만든다.
- 그리고 강화학습에는 하드코어한 엔지니어링이 들어간다.
- 효율적인 계산이 필요할 때, 수학 지식을 사용한다.
- 강의에서 배운 수학뿐만 아니라 AI에는 많은 수학이 쓰이는 것으로 알고 있습니다. 여러 모델들의 수학적 원리를 다 이해하고 있어야 하는건지 그리고 이러한 수학적 수식이 실제로 일을 할 때 어떻게 쓰이는지 궁금합니다.
- 수학적 원리를 전부 이해하고 있다면 좋겠지만, 대부분의 경우 필요할 때마다 수학을 학습한다.
- 단, 수학을 학습하기 위한 기초적인 수학 능력은 필요하다.
- 특히, 논문에 있는 수식을 구현할 때, 수학적 수식을 사용한다.
- 추천시스템 및 AI 금융 트레이딩에 관심이 있는데, 알아야 할 선행 지식이 있을까요?
- 추천시스템 : 선형대수학, 베이지안 통계
- AI 금융 트레이딩 : 확률론, 통계, 패턴 인식, 노이즈 처리 + 강화학습을 위한 선행 지식(벨만 방정식을 이해하기 위한 선형대수, 확률론, 다이나믹 프로그래밍 등)
- ML/DL 리서치가 아닌 엔지니어가 수학을 어느정도 알아야 할까요?
- 어느정도 알아야 하느냐가 아니라, 수학을 학습하기 위한 기초 지식이 중요하다.
- 강화학습이 현업에서 적용되고 있나요?
- 현업에서 많이 사용되고 있다.
- 로보틱스나 하드웨어에서는 사용하기 어려움이 있으나, 소프트웨어에서는 사용할 수 있다.
- 교수님이 부스트캠프 수강생이라면 어떤 공부를 중점적으로 하실 것 같으신가요?
- 수학과 코드를 병행하며 공부할 것 같다.
- 수식<->코드 연습
- 수학이 많이 어렵습니다. 많은 이론을 설명해주시지만 예제나 예시가 부족하여 이해하기 어렵습니다. 강의 내용을 자세히 볼 수 있는 책이나 강의가 있을까요?
- 딱 하나 특정지어서 소개하기 어려울 것 같음.
라이브 Q&A
- 인공지능 관련으로 공부하고 취직하기 위해서는 대학원이 아무래도 필수일까요?? 만약 그렇다면, 대학원 취직을 위해서 갖추어야할 조건이 무엇일까요?? 대학원에 입학하기 위해선 어떤 준비를 해야할까요??
- 교수님 피셜 : 필수는 아니라고 생각한다.
- 필수는 아니지만, 도움은 많이 된다.
- 특히, 모르는 부분을 대학원을 통해서 해소할 수 있다는 점에서 좋다.
- 그리고 한 분야의 전문가가 되기 위해서는 대학원을 가는 것이 좋다고 생각한다.
- 즉, 필수는 아니지만, 성장에 도움이 된다.
- 조건과 준비는 부스트캠프 내용을 기준으로 하면 될 것 같다.
- 교수님께서 학생을 선발하시는 기준이 궁금합니다. 교수님 랩실 석사로 들어가기 위해서는 어떤 과정이 필요할까요??
- 메일을 통해서 문의
- 딥러닝에선 기존 변수를 결합해 파생변수를 만드는 것 (피처엔지니어링)이 결과에 도움이 되나요? 기존 변수를 1. 선형결합하거나 2. 나누거나 곱해 새로운 변수를 만드는 것이 모델에 어떤 영향을 주는지 궁금합니다. (2번의 예: 거리와 시간 데이터를 가지고 속력 변수를 추가할 때)
- 대부분의 경우 피처 엔지니어링 보다는 데이터 전처리가 성능에 더 큰 영향을 미쳤다.
- 그렇다고 해서 피처 엔지니어링이 도움이 안되는 것은 아니다.
- 엔지니어의 의도에 따라서 사용 할 수 있다.
- 이번 통계학 수업 이해가 쉽지 않은데 이해의 기반이 될 책 추천을 해주실 수 있을까요??
- 인공지능 대학원에 가려면 수학 공부 비중을 어느 정도로 잡고 준비해야할까요?
- 부스트캠프를 기준으로 준비하면 될 것 같다.
- 시계열 데이터를 다룰 때 데이터의 시기(t)에 의해 모델이 오버피팅 될 수 있을 것 같은데, 어떻게 해야 현재의 예측을 잘 해낼 수 있을까요? 사회과학에서 과거부터 지금까지 변수들 간의 관계가 시기에 따라 바뀌어 왔을 때 과거데이터를 통째로 학습시키면 너무 과거에 피팅되지 않을까요?
- ...
- 음성이나 이미지같은 특수한 비정형 도메인이 아닌 가장 일반적인 table 데이터에서 딥러닝은 tree기반 모델이나 regression 모델에 비해 어떤 장점을 가지나요?
- 테이블 데이터라고 해서 꼭 트리 또는 회귀 모델을 사용해야 한다는 고정 관념은 없애도 될 것 같다.
- 딥러닝에서도 적합한 모델을 사용한다면, 충분히 성능을 낼 수 있다.
- 특히, 테이블 데이터가 엄청 크고 넓을 때에는 딥러닝을 사용하면 성능이 잘 나온다.
- 딥러닝을 확률론적으로 접근하는 것과 백프로게이션을 통해서 딥러닝을 하는것과 다른 관점인가요?? 제가 생각하기엔 백프로게이션을 통해 학습을 하는 점에서는 확률과 통계학이 사용되지 않는 것 같아서요. 확률과 통계는 다른 관점에서 접근하는것인가요?
- 역전파에서 거시적인 관점으로 보면 확률과 통계를 사용한다.
- 미니 배치 샘플링에서 확률과 통계가 기반으로 사용된다.
- 그 뿐만 아니라, 손실함수와 dropout 등을 설계하는 관점에서 확률과 통계가 기반으로 사용된다.
- 계속 말씀하시는 엔지니어링은 어떤 것을 말씀하시는걸까요?
- 리서치들은 문제를 해결 할 때에는 이론을 기반으로 문제를 해결하려고 한다.
- 반면에 엔지니어들은 문제를 해결 할 때에는 휴리스틱을 기반으로 문제를 해결하려고 한다.
- 그 뿐만 아니라, 엔지니어들은 컴퓨팅 파워와 리소스 관리의 측면으로 문제를 바라본다.
- KL(Pk||Q) 나 argmax 같은 처음 보는 수학 수식을 제대로 알려주셨으면 합니다..
- 조교님께...
- 논문 수식 구현하는 것도 다이브인투딥러닝 보고 수학 수식을 코드 구현해보는걸로 충분할까요?
- 충분하며, 도움이 된다.
- 이번 수학강의를 검색하거나 찾아보면서 이해할수 있을 정도라면 논문에 나오는 수학도 찾아보면서 이해할 수 있을까요?
- 충분히 이해 할 수 있다.
- aws(아마존웹서비스)에서 제공하는 ml툴이 완성도있게 나온걸로 알고 있습니다. aws에서 제공하는 ai 서비스를 개발하는 것과 // 아마존에서 제공하는 ai 서비스를 활용하여 다른서비스를 개발하는 것의 차이점은 무엇일까요? 후자라면 ai엔지니어라는 역할이 과연 필요한가요?
- 본인이 답변하기에는 적절하지 않은 것 같다.
- 실제로 서비스 중인 AI 엔지니어들에게 물어보는 것다 좋다.
- ai math에서 r.v 말고 random process를 쓰는 경우도있나요? 있다면 수식전개과정이나 쓰는경우를 설명해주세요!!
- 가우시안 프로세스 또는 뉴럴 프로세스에서는 사용이 되지만, 마이너한 부분이기 때문에 수업에서는 생략했다.
- 울산도 추운가요?
- 원래는 별로 안 추웠는데, 오늘은 추웠다.
- 강의 너무 잘 들었습니다! 아직 기초도 부족한 상태인데, 특정 분야(경량화, NLP, 이미지, 추천시스템 등등)을 목표하고 공부하는게 좋을까요?
- 특정 분야를 목표하고 공부하는 것을 추천한다.
- 왜냐하면, 목적을 가지고 공부하는 것이 셀프 모티베이션이 되기 때문이다.
- 표본분산을 구할 때 N-1로 나눠주는 부분에 대해서 어느정도까지의 이해가 필요할까요?
- 통계학의 불편추정량에서 출발한 개념인데, 머신러닝에서는 크게 중요한 개념은 아니다.
- Causal Learning 이 분야는 수학이 어느정도 필요할까요? 대학원 수준의 확률론이 필요할까요??
- 만약 연구자를 목표로 하고 있다면, 대학원 수준의 확률론이 필요하다.
후기
Dive into Deep Learning, 이거 하나 기억에 남는 마스터 클래스였습니다.
나중에 여유가 생기면, 꼭 읽어볼 생각입니다.
총평
이번 한 주 동안, 수학이 많이 부족하다는 것을 깨달았습니다.
특히, 잊어버린 개념들이 많아 복습의 필요성을 절실하게 느꼈습니다.
새로운 개념을 공부하는 것도 좋지만, 마스터 클래스에서 들은 것처럼 기초 체력을 위한 재정비 시간을 가져야겠습니다.
오늘보다 더 성장한 내일의 저를 기대하며, 다음 주에 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA