강의 복습 내용
[DAY 13] Convolutional Neural Networks
[DLBasic] CNN - Convolution은 무엇인가?
- Convolutional Neural Networks
- CNN consists of convolution layer, pooling layer, and fully connected layer.
- Convolution and pooling layers: feature extraction
- Fully connected layer: decision making (e.g., classification)
- CNN consists of convolution layer, pooling layer, and fully connected layer.
- Stride
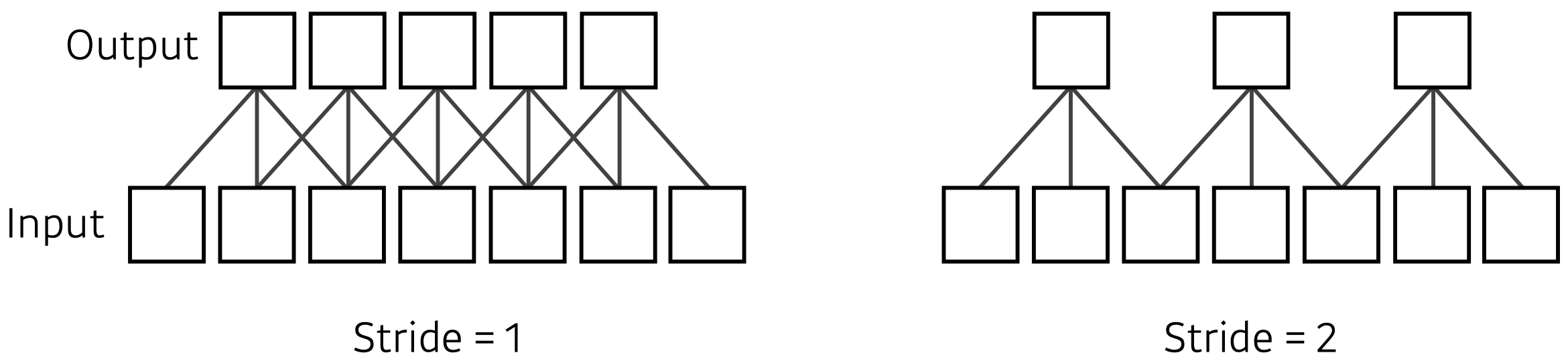
- Padding
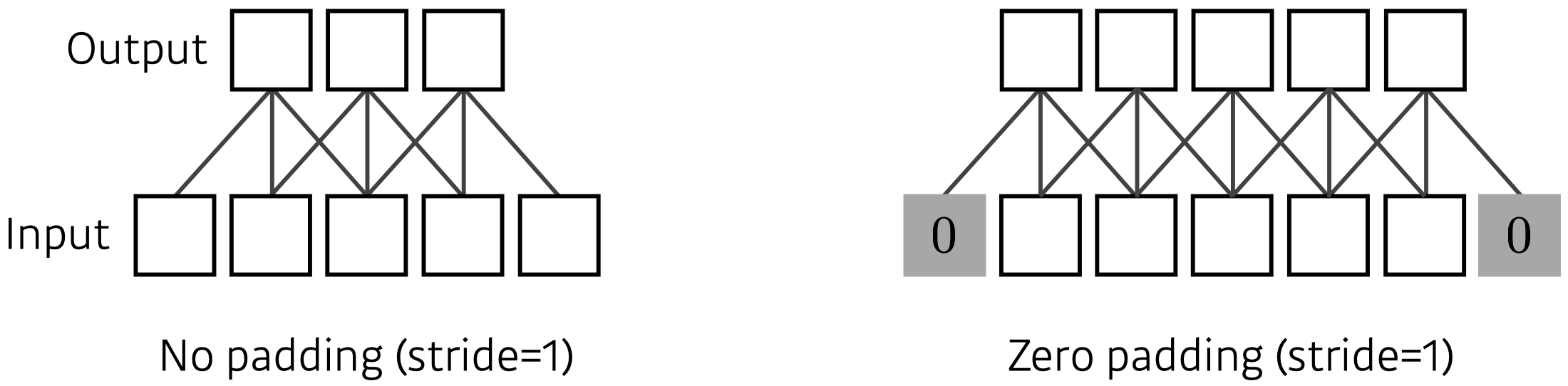
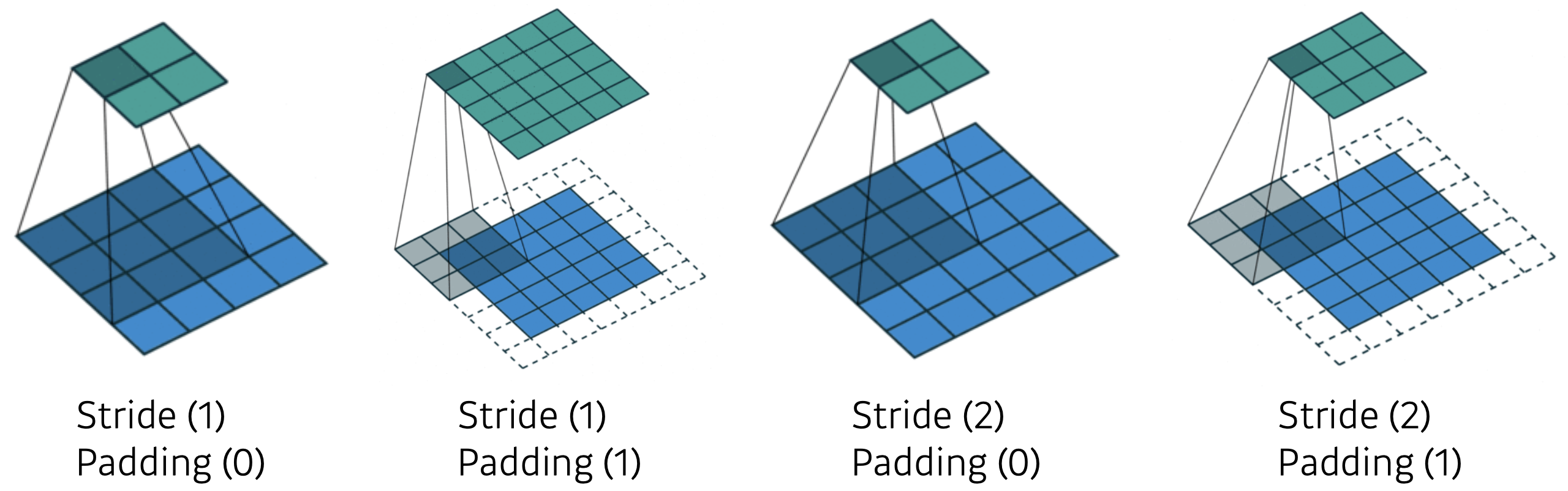
- Stride & Padding
[DLBasic] Modern CNN - 1x1 convolution의 중요성
-
ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)
- Classification / Detection / Localization / Segmentation
- 1,000 different categories
- Over 1 million images
- Training set: 456,567 images
-
AlexNet
- Key ideas
- Rectified Linear Unit (ReLU) activation
- GPI implementation (2 GPUs)
- Local response normalization, Overlapping pooling
- Data augmentation
- Dropout
- ReLU Activation
- Preserves properties of linear models
- Easy to optimize with gradient descent
- Good generalization
- Overcome the vanishing gradient problem
- Key ideas
-
VGGNet
- Increasing depth with 3 × 3 convolution filters (with stride 1)
- 1x1 convolution for fully connected layers
- Dropout (p=0.5)
- VGG16, VGG19
- Why 3 × 3 convolution?
-
GoogLeNet
- GoogLeNet won the ILSVRC at 2014
- It combined network-in-network (NiN) with inception blocks.
- Inception blocks
- What are the benefits of the inception block?
- Reduce the number of parameter.
- How?
- Recall how the number of parameters is computed.
- 1x1 convolution can be seen as channel-wise dimension reduction.
- What are the benefits of the inception block?
- Benefit of 1x1 convolution
- 1x1 convolution enables about 30% reduce of the number of parameters!
- GoogLeNet won the ILSVRC at 2014
-
Quiz
- Which CNN architecture has the least number of parameters?
- AlexNet (8-layers) (60M)
- VGGNet (19-layers) (110M)
- GoogLeNet (22-layers) (4M)
- The answer is GoogLeNet.
- Which CNN architecture has the least number of parameters?
-
ResNet
- Deeper neural networks are hard to train.
- Overfitting is usually caused by an excessive number of parameters.
- But, not in this case.
- Add an identity map (skip connection)
- Add an identity map after nonlinear activations:
- Batch normalization after convolutions:
- Performance increases while parameter size decreases.
- Deeper neural networks are hard to train.
-
DenseNet
- DenseNet uses concatenation instead of addition.
- Dense Block
- Each layer concatenates the feature maps of all preceding layers.
- The number of channels increases geometrically.
- Transition Block
- BatchNorm -> 1x1 Conv -> 2x2 AvgPooling
- Dimension reduction
-
Summary
- VGG: repeated 3x3 blocks
- GoogLeNet: 1x1 convolution
- ResNet: skip-connection
- DenseNet: concatenation
[DLBasic] Computer Vision Applications
- Fully Convolutional Network
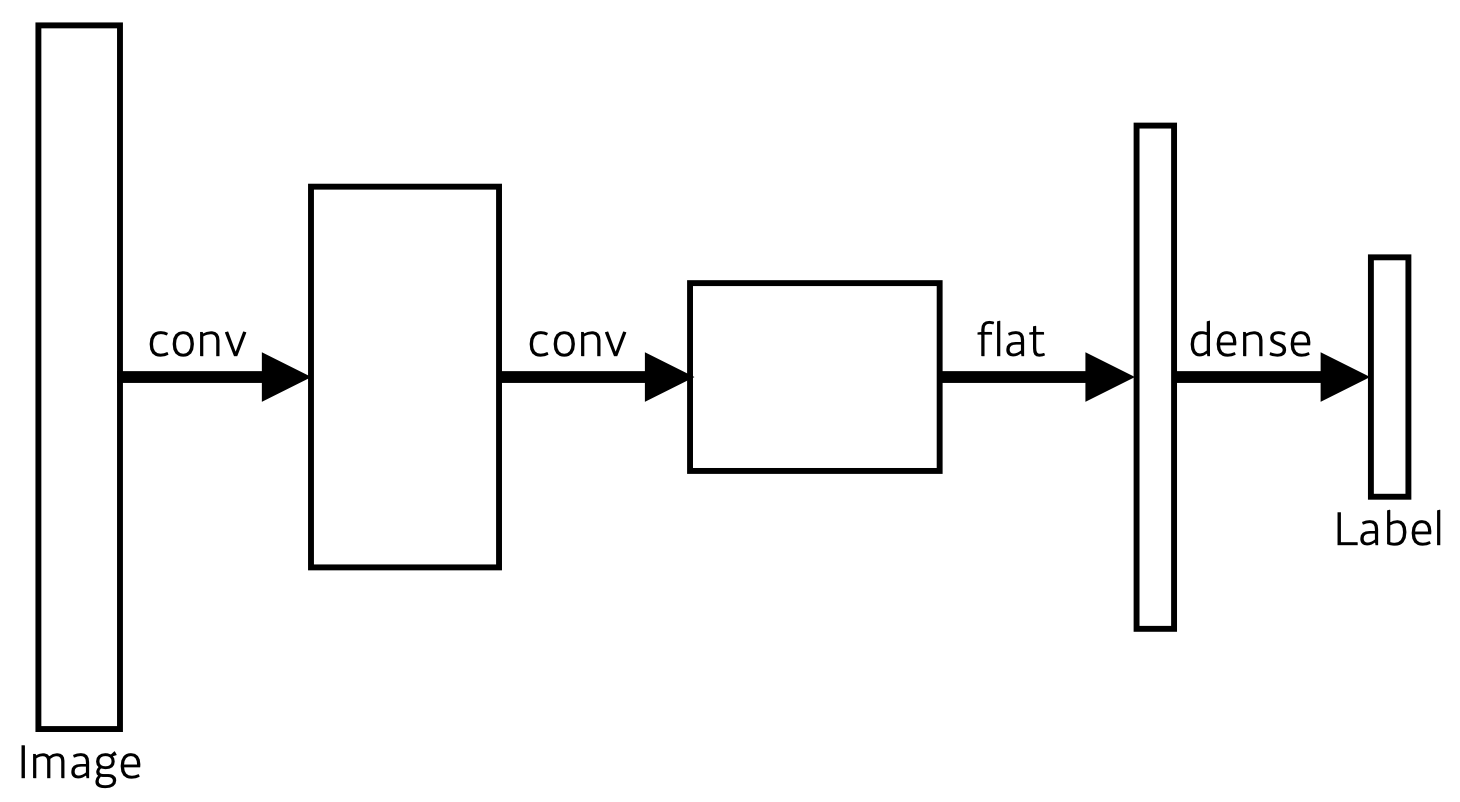
- This is how an ordinary CNN looks like.
- This is a fully convolutional network.
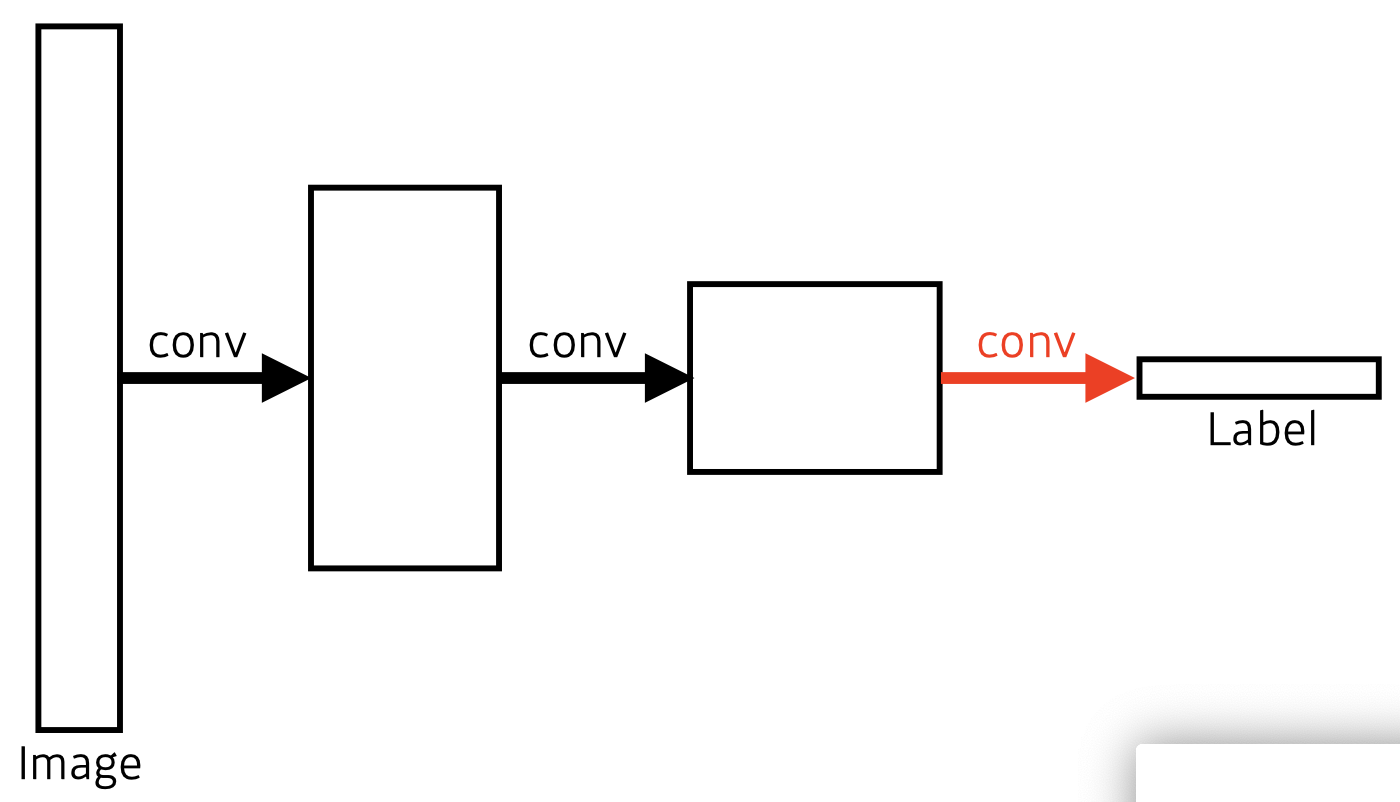
- Transforming fully connected layers into convolution layers enables a classification net to output a heap map.
- While FCN can run with inputs of any size, the output dimensions are typically reduced by subsampling.
- So we need a way to connect the coarse output to the dense pixels.
- This is how an ordinary CNN looks like.
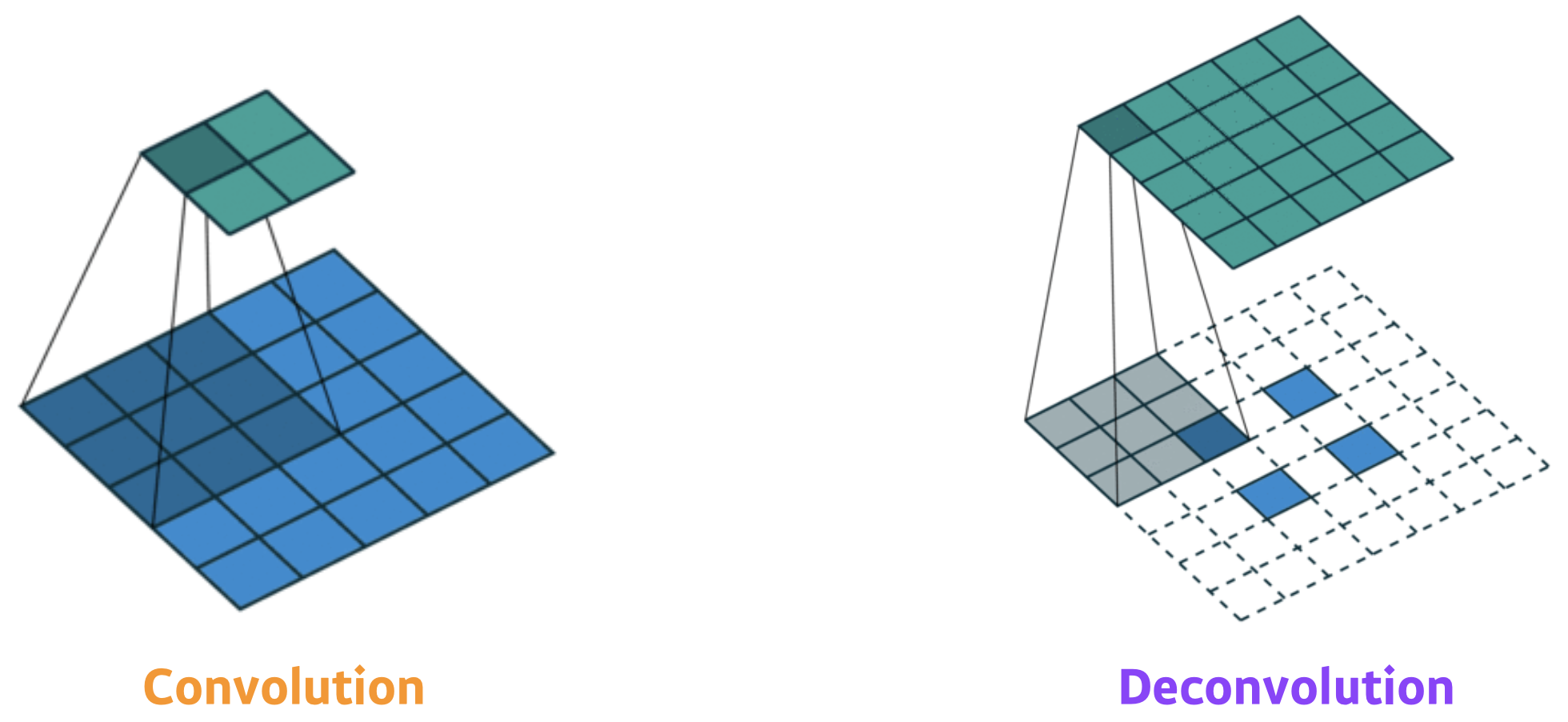
- Deconvolution (conv transpose)
- Detection
- R-CNN
- takes an input image,
- extracts around 2,000 region proposals (using Selective search),
- compute features for each proposal (using AlexNet), and then
- classifies with linear SVMs.
- SPPNet
- In R-CNN, the number of crop/warp is usually over 2,000 meaning that CNN must run more than 2,000 times (59s/image on CPU).
- However, in SPPNet, CNN runs once.
- Fast R-CNN
- Takes an input and a set of bounding boxes.
- Generated convolutional feature map
- For each region, get a fixed length feature from ROI pooling
- Two outputs: class and bounding-box regressor.
- Faster R-CNN = Region Proposal Network + Fast R-CNN
- YOLO
- YOLO (v1) is an extremely fast object detection algorithm.
- baseline: 45fps / smaller version: 155fps
- It simultaneously predicts multiple bounding boxes and class probabilities.
- No explicit bounding box sampling (compared with Faster R-CNN)
- Given an image, YOLO divides it into SxS grid.
- If the center of an object falls into the grid cell, that grid cell is responsible for detection.
- Each cell predicts B bounding boxes (B=5).
- Each bounding box predicts
- box refinement (x / y / w / h)
- confidence (of objectness)
- Each bounding box predicts
- Each cell predicts C class probabilities.
- In total, it becomes a tensor with SxSx(B*5+C) size.
- SxS: Number of cells of the grid
- B*5: B bounding boxes with offsets (x,y,w,h) and confidence
- C: Number of classes
- YOLO (v1) is an extremely fast object detection algorithm.
- R-CNN
[DLBasic] CNN - 강아지 종류 분류하기
- Self-study guide
- Dog breed 데이터셋의 다운로드부터 Dataloader 생성까지의 전 과정을 기존의 CNN 모델 파일(py) 파일 수정하여 작성해 볼 것
[DLBasic] CNN - 나만의 데이터셋 만들기
- Self-study guide
- 팀별로 수집할 데이터 주제를 선정한다.
- 구글을 통해 관련된 데이터를 다운로드 받는다.
- 같은 class의 데이터를 폴더별로 모은다.
- 해당 데이터중 관련이 없는 데이터를 삭제하거나 새로운 분류를 만들어 따로 모은다.
- CNN 모델을 만들어 학습한다.
Further Question
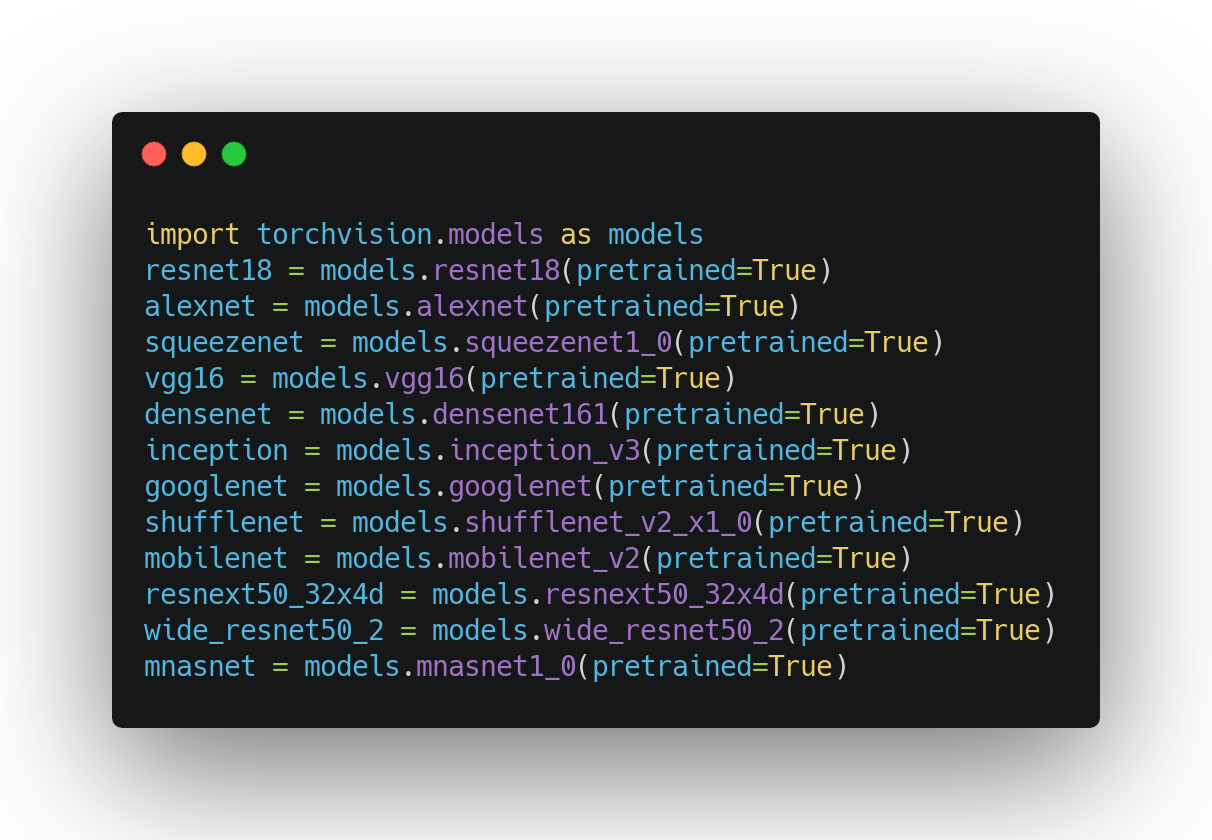
수업에서 다룬 modern CNN network의 일부는, Pytorch 라이브러리 내에서 pre-trained 모델로 지원합니다. pytorch를 통해 어떻게 불러올 수 있을까요?
피어 세션 정리
강의 리뷰 및 Q&A
- [DLBasic] CNN - Convolution은 무엇인가?
- [DLBasic] Modern CNN - 1x1 convolution의 중요성
- [DLBasic] Computer Vision Applications
- [DLBasic] CNN - 강아지 종류 분류하기
- [DLBasic] CNN - 나만의 데이터셋 만들기
과제 진행 상황 정리 & 과제 결과물에 대한 정리
[DLBasic] CNN Assignment
CNN(Convolutional Neural Network)에 대한 것으로, 어렵지 않게 해결했습니다.
총평
이론 공부도 재미있지만, 역시 저는 어떤 목적을 가지고 문제를 해결할 때가 가장 즐겁고 많이 배우는 것 같습니다.
그래서 오늘 강의에서 언급된 Self-study를 위한 실습이 너무 반가웠습니다.
해당 실습을 통해서, PyTorch를 가지고 놀다 보면 금방 익숙해질 것 같습니다.
물론, 데이터 수집부터 전처리, 모델링까지 해야 할 일이 더 늘었지만, 다음 주를 이용하면 어떻게든 해낼 수 있다고 생각합니다.
오늘보다 더 성장한 내일의 저를 기대하며, 내일 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA