강의 복습 내용
[DAY 16]
(1강) Intro to NLP, Bag-of-Words
1. Intro to Natural Language Processing(NLP)
-
Goal of This Course
- Natural language processing (NLP), which aims at properly understanding and generating human languages, emerges as a crucial application of artificial intelligence, with the advancements of deep neural networks.
- This course will cover various deep learning approaches as well as their applications such as language modeling, machine translation, question answering, document classification, and dialog systems.
-
Academic Disciplines related to NLP
- Natural language processing (major conferences: ACL, EMNLP, NAACL)
- Includes state-of-the-art deep learning-based models and tasks
- Low-level parsing
- Tokenization, stemming
- Word and phrase level
- Named entity recognition(NER), part-of-speech(POS) tagging, noun-phrase chunking, dependency parsing, coreference resolution
- Sentence level
- Sentiment analysis, machine translation
- Multi-sentence and paragraph level
- Entailment prediction, question answering, dialog systems, summarization
- Text mining(major conferences: KDD, The WebConf (formerly, WWW), WSDM, CIKM, ICWSM)
- Extract useful information and insights from text and document data
- Document clustering (e.g., topic modeling)
- Highly related to computational social science
- Information retrieval (major conferences: SIGIR, WSDM, CIKM, RecSys)
- Highly related to computational social science
- This area is not actively studied now
- It has evolved into a recommendation system, which is still an active area of research
- Highly related to computational social science
- Natural language processing (major conferences: ACL, EMNLP, NAACL)
-
Trends of NLP
- Text data can basically be viewed as a sequence of words, and each word can be represented as a vector through a technique such as Word2Vec or GloVe.
- RNN-family models (LSTMs and GRUs), which take the sequence of these vectors of words as input, are the main architecture of NLP tasks.
- Overall performance of NLP tasks has been improved since attention modules and Transformer models, which replaced RNNs with self-attention, have been introduced a few years ago.
- As is the case for Transformer models, most of the advanced NLP models have been originally developed for improving machine translation tasks.
- In the early days, customized models for different NLP tasks had developed separately.
- Since Transformer was introduced, huge models were released by stacking its basic module, self-attention, and these models are trained with large-sized datasets through language modeling tasks, one of the self-supervised training setting that does not require additional labels for a particular task.
- Afterwards, above models were applied to other tasks through transfer learning, and they outperformed all other customized models in each task.
- Currently, these models has now become essential part in numerous NLP tasks, so NLP research become difficult with limited GPU resources, since they are too large to train.
2. Bag-of-Words
-
Bag-of-Words Representation
- Step 1. Constructing the vocabulary containing unique words
- Example sentences: “John really really loves this movie“, “Jane really likes this song”
- Vocabulary:{“John“,“really“,“loves“,“this“,“movie“,“Jane“,“likes“,“song”}
- Step 2. Encoding unique words to one-hot vectors
- Vocabulary:{“John“,“really“,“loves“,“this“,“movie“,“Jane“,“likes“,“song”}
- John: [1 0 0 0 0 0 0 0]
- really: [0 1 0 0 0 0 0 0]
- loves: [0 0 1 0 0 0 0 0]
- this: [0 0 0 1 0 0 0 0]
- movie: [0 0 0 0 1 0 0 0]
- Jane: [0 0 0 0 0 1 0 0]
- likes: [0 0 0 0 0 0 1 0]
- song: [0 0 0 0 0 0 0 1]
- For any pair of words, the distance is 2^0.5
- For any pair of words, cosine similarity is 0
- Vocabulary:{“John“,“really“,“loves“,“this“,“movie“,“Jane“,“likes“,“song”}
- A sentence/document can be represented as the sum of one-hot vectors
- Sentence 1: “John really really loves this movie“
- John + really + really + loves + this + movie: [1 2 1 1 1 0 0 0]
- Sentence 2: “Jane really likes this song”
- Jane + really + likes + this + song: [0 1 0 1 0 1 1 1]
- Sentence 1: “John really really loves this movie“
- Step 1. Constructing the vocabulary containing unique words
-
NaiveBayes Classifier for Document Classification
- Bayes’ Rule Applied to Documents and Classes
- For a document d, which consists of a sequence of words w, and a class c
- The probability of a document can be represented by multiplying the probability of each word appearing

- Bayes’ Rule Applied to Documents and Classes
(2강) Word Embedding
-
What is Word Embedding?
- Express a word as a vector
- 'cat' and 'kitty' are similar words, so they have similar vector representations → short distance
- 'hamburger' is not similar with 'cat' or 'kitty’, so they have different vector representations → far distance
-
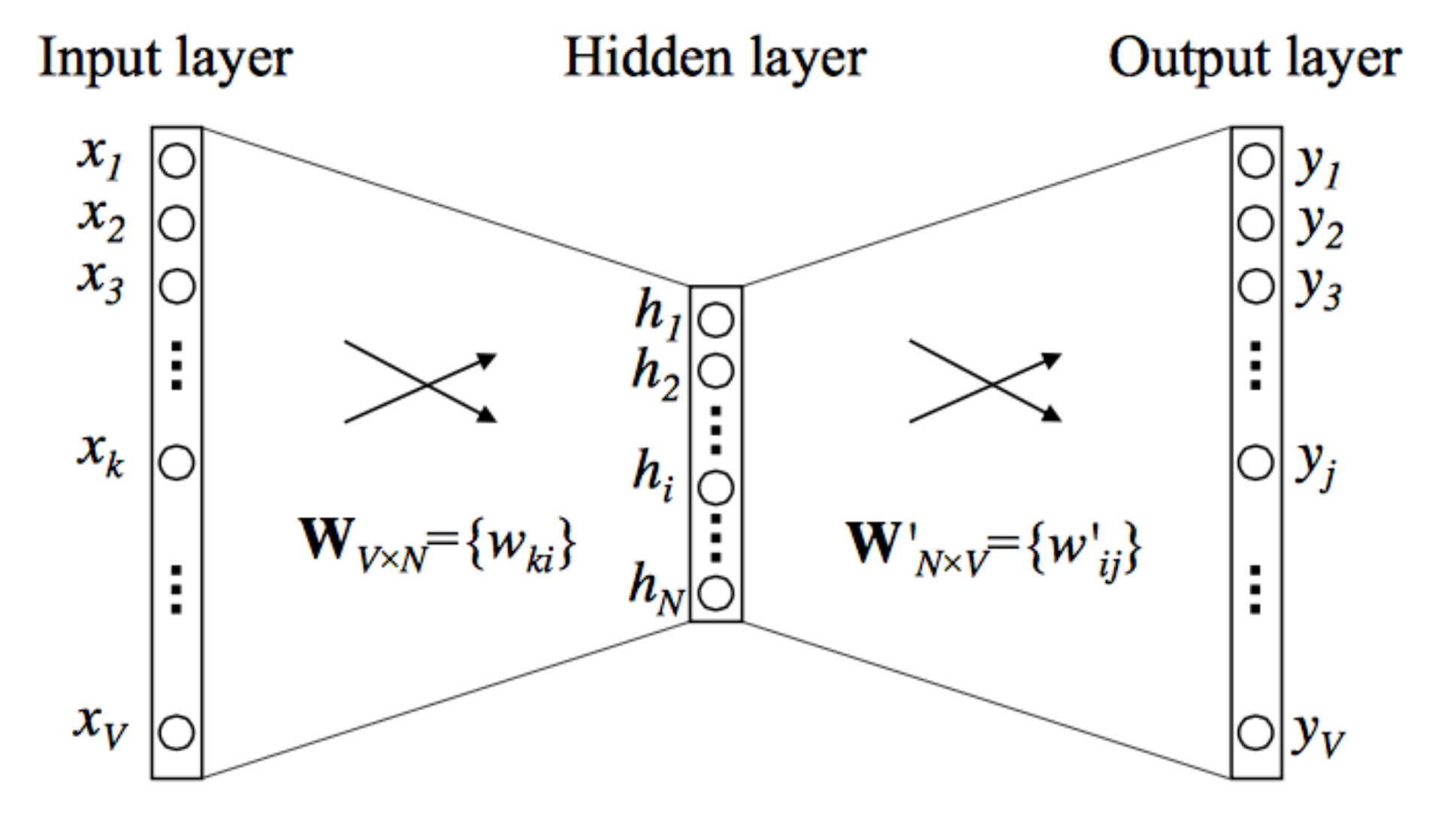
Word2Vec
- An algorithm for training vector representation of a word from context words (adjacent words)
- Assumption: words in similar context will have similar meanings
- Idea of Word2Vec : “You shall know a word by the company it keeps” –J.R. Firth 1957
- How Word2Vec Algorithm Works
- Property of Word2Vec
- The word vector, or the relationship between vector points in space, represents the relationship between the words.
- The same relationship is represented as the same vectors.
- Application of Word2Vec
- Word2Vec improves performances in most areas of NLP
- Word similarity
- Machine translation
- Part-of-speech (PoS) tagging
- Named entity recognition (NER)
- Sentiment analysis
- Clustering
- Semantic lexicon building
- Word2Vec improves performances in most areas of NLP
-
GloVe: Another Word Embedding Model
- GloVe: Global Vectors for Word Representation
- Rather than going through each pair of an input and an output words, it first computes the co-occurrence matrix, to avoid training on identical word pairs repetitively.
- Afterwards, it performs matrix decomposition on this co-occurrent matrix.
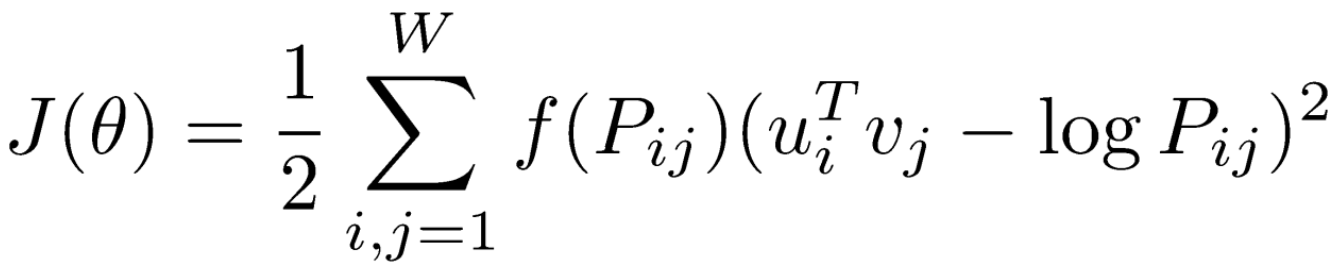
- Fast training
- Works well even with a small corpus
- GloVe: Global Vectors for Word Representation
Further Question
Word2Vec과 GloVe 알고리즘이 가지고 있는 단점은 무엇일까요?
- Word2Vec의 단점 : 사용자가 지정한 윈도우 내에서만 학습이 이뤄지기 때문에, 말뭉치 전체의 정보를 반영하기 어렵다. 그리고 학습을 위해서는 데이터가 많아야 하고 학습 속도가 느리다는 단점이 있다.
- Golve의 단점 : 계산 복잡도가 높기 때문에 메모리가 많이 필요하다. 특히, 동시 발생 행렬과 관련된 하이퍼 파라미터를 변경하는 경우 행렬을 다시 재구성해야 하므로 시간이 많이 걸린다.
피어 세션 정리
강의 리뷰 및 Q&A
- (1강) Intro to NLP, Bag-of-Words
- (2강) Word Embedding
[개인] Word2Vec의 학습 트릭
subsampling frequent words
Word2Vec의 파라메터는 앞서 설명드린대로 𝑊, 𝑊′입니다. 각각 크기가 𝑉 x 𝑁, 𝑁 x 𝑉인데요. 보통 말뭉치에 등장하는 단어수가 10만개 안팎이라는 점을 고려하면 𝑁(임베딩 차원수, 사용자 지정)이 100차원만 되어도 2000만개(2 x 10만 x 100)나 되는 많은 숫자들을 구해야 합니다. 단어 수가 늘어날 수록 계산량이 폭증하는 구조입니다.
이 때문에 Word2Vec 연구진은 말뭉치에서 자주 등장하는 단어는 학습량을 확률적인 방식으로 줄이기로 했습니다. 등장빈도만큼 업데이트 될 기회가 많기 때문입니다.
Word2Vec 연구진은 i번째 단어(𝑤𝑖)를 학습에서 제외시키기 위한 확률은 아래와 같이 정의했습니다.
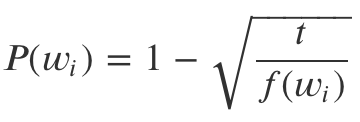
위 식에서 𝑓(𝑤𝑖)는 해당 단어가 말뭉치에 등장한 비율(해당 단어 빈도/전체 단어수)를 말합니다. 𝑡는 사용자가 지정해주는 값인데요, 연구팀에선 0.00001을 권하고 있습니다.
만일 𝑓(𝑤𝑖)가 0.01로 나타나는 빈도 높은 단어(예컨대 조사 ‘은/는’)는 위 식으로 계산한 𝑃(𝑤𝑖)가 0.9684나 되어서 100번의 학습 기회 가운데 96번 정도는 학습에서 제외하게 됩니다. 반대로 등장 비율이 적어 𝑃(𝑤𝑖)가 0에 가깝다면 해당 단어가 나올 때마다 빼놓지 않고 학습을 시키는 구조입니다. subsampling은 학습량을 효과적으로 줄여 계산량을 감소시키는 전략입니다.
negative sampling
Word2Vec은 출력층이 내놓는 스코어값에 소프트맥스 함수를 적용해 확률값으로 변환한 후 이를 정답과 비교해 역전파(backpropagation)하는 구조입니다.
그런데 소프트맥스를 적용하려면 분모에 해당하는 값, 즉 중심단어와 나머지 모든 단어의 내적을 한 뒤, 이를 다시 exp를 취해줘야 합니다. 보통 전체 단어가 10만개 안팎으로 주어지니까 계산량이 어마어마해지죠.
이 때문에 소프트맥스 확률을 구할 때 전체 단어를 대상으로 구하지 않고, 일부 단어만 뽑아서 계산을 하게 되는데요. 이것이 바로 negative sampling입니다. negative sampling은 학습 자체를 아예 스킵하는 subsampling이랑은 다르다는 점에 유의하셔야 합니다.
negative sampling의 절차는 이렇습니다. 사용자가 지정한 윈도우 사이즈 내에 등장하지 않는 단어(negative sample)를 5~20개 정도 뽑습니다. 이를 정답단어와 합쳐 전체 단어처럼 소프트맥스 확률을 구하는 것입니다. 바꿔 말하면 윈도우 사이즈가 5일 경우 최대 25개 단어를 대상으로만 소프트맥스 확률을 계산하고, 파라메터 업데이트도 25개 대상으로만 이뤄진다는 이야기입니다.
윈도우 내에 등장하지 않은 어떤 단어(𝑤𝑖)가 negative sample로 뽑힐 확률은 아래처럼 정의됩니다. 𝑓(𝑤𝑖)는 subsampling 챕터에서 설명한 정의와 동일합니다.
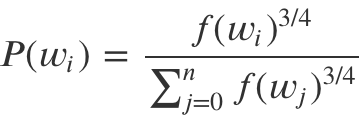
참고로 subsampling과 negative sampling에 쓰는 확률값들은 고정된 값이기 때문에 학습을 시작할 때 미리 구해놓게 됩니다.
[DLBasic] CNN - 나만의 데이터셋 만들기
- 합성곱 신경망의 미세조정(finetuning): 무작위 초기화 대신, 신경망을 ImageNet 1000 데이터셋 등으로 미리 학습한 신경망으로 초기화합니다. 학습의 나머지 과정들은 평상시와 같습니다.
- 고정된 특징 추출기로써의 합성곱 신경망: 여기서는 마지막에 완전히 연결된 계층을 제외한 모든 신경망의 가중치를 고정합니다. 이 마지막의 완전히 연결된 계층은 새로운 무작위의 가중치를 갖는 계층으로 대체되어 이 계층만 학습합니다.
과제 진행 상황 정리 & 과제 결과물에 대한 정리
[과제] NLP 전처리
NLP 전처리에 대한 것으로, 어렵지 않게 해결했습니다.
총평
1주일간의 휴식을 마치고 일상으로 돌아왔습니다.
계획했던 일들을 전부 수행하지는 못해서 아쉬웠지만, 잠깐이나마 재충전할 수 있어서 너무 좋았습니다.
오늘은 약간의 적응하는 시간이 필요하지 않을까 생각했었는데, 이번 주의 강의 주제가 저의 도메인이기도 한 NLP인 덕분에 재미있게 공부했습니다.
그리고 이번 주 마지막 과제로 예정된 "사전학습된 언어 모델을 이용한 개체명 인식 task"가 캐글 프라이빗 챌린지로 진행된다고 하여 기대하고 있습니다.
특히, 제가 승부욕이 강한 성격이라서 그런지 더욱더 기다려지는 것 같습니다.
이번 주 열심히 공부하여, 좋은 성적을 낼 수 있도록 최선을 다해보겠습니다.
오늘보다 더 성장한 내일의 저를 기대하며, 내일 뵙도록 하겠습니다.
읽어주셔서 감사합니다!
