강의 복습 내용
[DAY 20]
(9강) Self-supervised Pre-training Models
1. Self-Supervised Pre-Training Models
-
Recent Trends
- Transformer model and its self-attention block has become a general-purpose sequence (or set) encoder and decoder in recent NLP applications as well as in other areas.
- Training deeply stacked Transformer models via a self-supervised learning framework has significantly advanced various NLP tasks through transfer learning, e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA...
- Other applications are fast adopting the self-attention and Transformer architecture as well as self-supervised learning approach, e.g., recommender systems, drug discovery, computer vision, ...
- As for natural language generation, self-attention models still requires a greedy decoding of words one at a time.
-
GPT-1
- Improving Language Understanding by Generative Pre-training
- It introduces special tokens, such as <"S">/<"E">/$, to achieve effective transfer learning during fine-tuning
- It does not need to use additional task-specific architectures on top of transferred
- Improving Language Understanding by Generative Pre-training
-
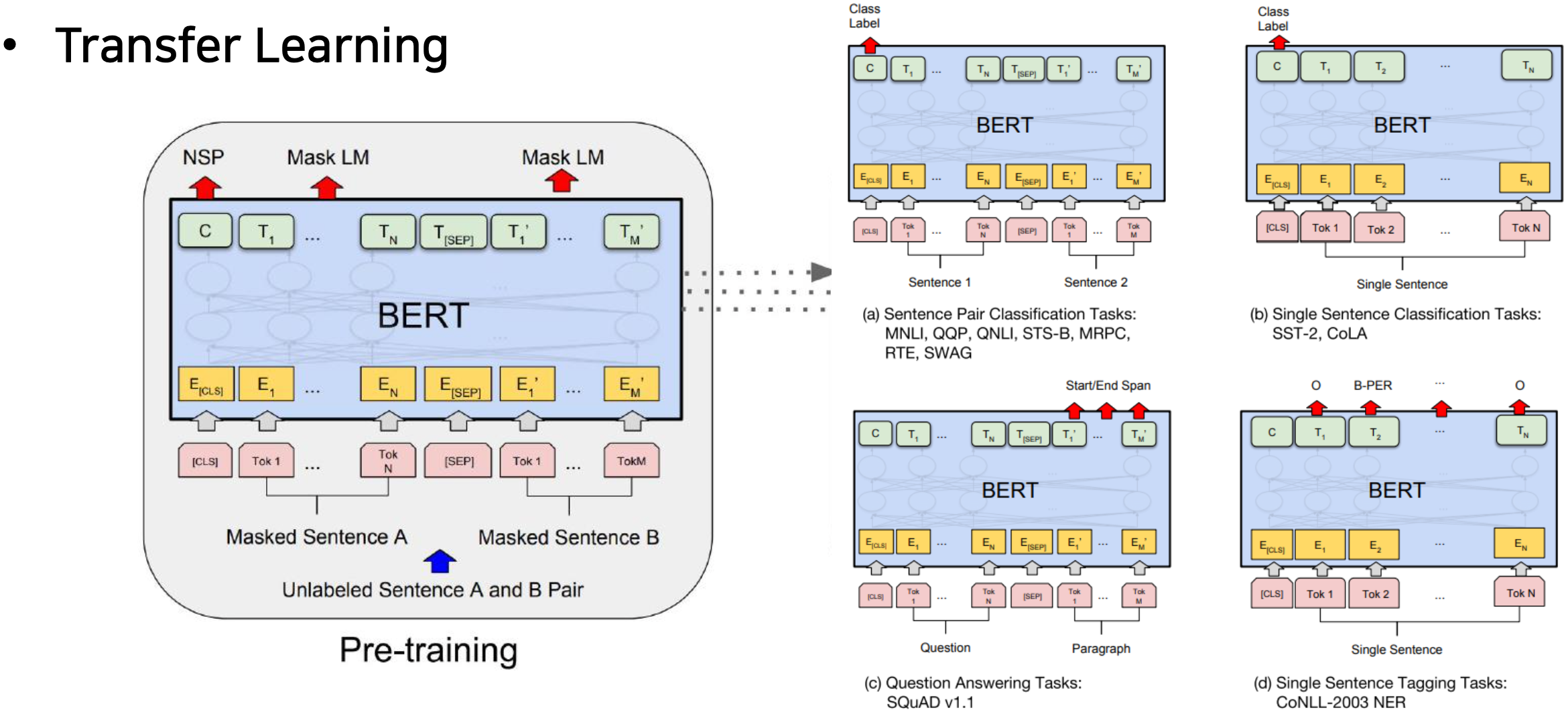
BERT
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Learn through masked language modeling task
- Use large-scale data and large-scale model
- Masked Language Model
- Motivation
- Language models only use left context or right context, but language understanding is bi-directional
- If we use bi-directional language model?
- Problem: Words can “see themselves” (cheating) in a bi-directional encoder
- Motivation
- Pre-training Tasks in BERT
- Masked Language Model (MLM)
- Mask some percentage of the input tokens at random, and then predict those masked tokens.
- 15% of the words to predict
- 80% of the time, replace with [MASK]
- 10% of the time, replace with a random word
- 10% of the time, keep the sentence as same
- Next Sentence Prediction (NSP)
- Predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence
- Masked Language Model (MLM)
- Pre-training Tasks in BERT: Masked Language Model
- How to
- Mask out k% of the input words, and then predict the masked words
- Too little masking : Too expensive to train
- Too much masking : Not enough to capture context
- Problem
- Mask token never seen during fine-tuning
- Solution
- 15% of the words to predict, but don’t replace with [MASK] 100% of the time. Instead:
- 80% of the time, replace with [MASK]
- went to the store → went to the [MASK]
- 10% of the time, replace with a random word
- went to the store→went to the running
- 10% of the time, keep the same sentence
- went to the store→went to the store
- 80% of the time, replace with [MASK]
- 15% of the words to predict, but don’t replace with [MASK] 100% of the time. Instead:
- How to
- Pre-training Tasks in BERT: Next Sentence Prediction
- To learn the relationships among sentences, predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence
- BERT Summary
- Model Architecture
- BERT BASE: L = 12, H = 768, A = 12
- BERT LARGE: L = 24, H = 1024, A = 16
- Input Representation
- WordPiece embeddings (30,000 WordPiece)
- Learned positional embedding
- [CLS] – Classification embedding
- Packed sentence embedding [SEP]
- Segment Embedding
- Pre-trainingTasks
- Masked LM
- Next Sentence Prediction
- BERT: Input Representation
- The input embedding is the sum of the token embeddings, the segmentation embeddings and the position embeddings
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Learn through masked language modeling task
- Use large-scale data and large-scale model
- BERT: Fine-tuning Process
- BERT vs GPT-1
- Comparison of BERT and GPT-1
- Training-data size
- GPT is trained on BookCorpus(800M words) ; BERT is trained on the BookCorpus and Wikipedia (2,500M words)
- Training special tokens during training
- BERT learns [SEP],[CLS], and sentence A/B embedding during pre-training
- Batch size
- BERT – 128,000 words ; GPT – 32,000 words
- Task-specific fine-tuning
- GPT uses the same learning rate of 5e-5 for all fine-tuning experiments; BERT chooses a task-specific fine-tuning learning rate.
- Training-data size
- Comparison of BERT and GPT-1
- BERT: GLUE Benchmark Results
- GLUE Benchmark Results
- Machine Reading Comprehension (MRC), Question Answering
- BERT: SQuAD 1.1
- BERT: SQuAD 2.0
- Use token 0 ([CLS]) to emit logit for “no answer”
- “No answer” directly competes with answer span
- Threshold is optimized on dev set
- BERT: On SWAG
- Run each Premise + Ending through BERT
- Produce logit for each pair on token 0 ([CLS])
- BERT: Ablation Study
- Big models help a lot
- Going from 110M to 340M params helps even on datasets with 3,600 labeled examples
- Improvements have not asymptoted
- Big models help a lot
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
(10강) Advanced Self-supervised Pre-training Models
2. Advanced Self-supervised Pre-training Models
-
GPT-2
- GPT-2: Language Models are Unsupervised Multi-task Learners
- Just a really big transformer LM
- Trained on 40GB of text
- Quite a bit of effort going into making sure the dataset is good quality
- Take webpages from reddit links with high karma
- Language model can perform down-stream tasks in a zero-shot setting – without any parameter or architecture modification
- GPT-2: Motivation (decaNLP)
- The Natural Language Decathlon: Multitask Learning as Question Answering
- Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, Richard Socher
- The Natural Language Decathlon: Multitask Learning as Question Answering
- GPT-2: Datasets
- A promising source of diverse and nearly unlimited text is web scrape such as common crawl
- They scraped all outbound links from Reddit, a social media platform, WebText
- 45M links
- Scraped web pages which have been curated/filtered by humans
- Received at least 3 karma (up-vote)
- 45M links
- 8M removed Wikipedia documents
- Use dragnet and newspaper to extract content from links
- They scraped all outbound links from Reddit, a social media platform, WebText
- Preprocess
- Byte pair encoding (BPE)
- Minimal fragmentation of words across multiple vocab tokens
- A promising source of diverse and nearly unlimited text is web scrape such as common crawl
- GPT-2: Model
- Modification
- Layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network
- Additional layer normalization was added after the final self-attention block.
- Scaled the weights of residual layer at initialization by a factor of 1/root(𝑛) where 𝑛 is the number of residual layer
- Modification
- GPT-2: Question Answering
- Use conversation question answering dataset(CoQA)
- Achieved 55 F1 score, exceeding the performance 3 out of 4 baselines without labeled dataset
- Fine-tuned BERT achieved 89 F1 performance
- Use conversation question answering dataset(CoQA)
- GPT-2: Summarization
- CNN and Daily Mail Dataset
- Add text TL;DR: after the article and generate 100 tokens
- (TL;DR: Too long, didn’t read)
- CNN and Daily Mail Dataset
- GPT-2: Translation
- User WMT14 en-fr dataset for evaluation
- Use LMs on a context of example pairs of the format:
- English sentence = French sentence
- Achieve 5 BLEU score in word-by-word substitution
- Slightly worse than MUSE (Conneau et al., 2017)
- Use LMs on a context of example pairs of the format:
- User WMT14 en-fr dataset for evaluation
- GPT-2: Language Models are Unsupervised Multi-task Learners
-
GPT-3
- GPT-3: Language Models are Few-Shot Learners
- Language Models are Few-shot Learners
- Scaling up language models greatly improves task-agnostic, few-shot performance
- An autoregressive language model with 175 billion parameters in the few-shot setting
- 96 Attention layers, Batch size of 3.2M
- Prompt: the prefix given to the model
- Zero-shot: Predict the answer given only a natural language description of the task
- One-shot: See a single example of the task in addition to the task description
- Few-shot: See a few examples of the task
- Zero-shot performance improves steadily with model size
- Few-shot performance increases more rapidly
- Language Models are Few-shot Learners
- GPT-3: Language Models are Few-Shot Learners
-
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- Is having better NLP models as easy as having larger models?
- Obstacles
- Memory Limitation
- Training Speed
- Solutions
- Factorized Embedding Parameterization
- Cross-layer Parameter Sharing
- (For Performance) Sentence Order Prediction
- Obstacles
- Factorized Embedding Parameterization
- V = Vocabulary size
- H = Hidden-state dimension
- E = Word embedding dimension
- Cross-layer Parameter Sharing
- Shared-FFN: Only sharing feed-forward network parameters across layers
- Shared-attention: Only sharing attention parameters across layers
- All-shared: Both of them
- Sentence Order Prediction
- Next Sentence Prediction pretraining task in BERT is too easy
- Predict the ordering of two consecutive segments of text
- Negative samples the same two consecutive segments but with their order swapped
- Is having better NLP models as easy as having larger models?
-
ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- Learn to distinguish real input tokens from plausible but synthetically generated replacements
- Pre-training text encoders as discriminators rather than generators
- Discriminator is the main networks for pre-training.
- Replaced token detection pre-training vs masked language model pre-training
- Outperforms MLM-based methods such as BERT given the same model size, data, and compute
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately
-
Light-weight Models
- DistillBERT (NeurIPS 2019 Workshop)
- A triple loss, which is a distillation loss over the soft target probabilities of the teacher model leveraging the full teacher distribution
- TinyBERT (Findings of EMNLP 2020)
- Two-stage learning framework, which performs Transformer distillation at both the pre-training and task-specific learning stages
- DistillBERT (NeurIPS 2019 Workshop)
-
Fusing Knowledge Graph into Language Model
- ERNIE: Enhanced Language Representation with Informative Entities (ACL 2019)
- Informative entities in a knowledge graph enhance language representation
- Information fusion layer takes the concatenation of the token embedding and entity embedding
- KagNET: Knowledge-Aware Graph Networks for Commonsense Reasoning (EMNLP 2019)
- A knowledge-aware reasoning framework for learning to answer commonsense questions
- For each pair of question and answer candidate, it retrieves a sub-graph from an external knowledge graph to capture relevant knowledge
- ERNIE: Enhanced Language Representation with Informative Entities (ACL 2019)
Further Question
BERT의 Masked Language Model의 단점은 무엇이 있을까요? 사람이 실제로 언어를 배우는 방식과의 차이를 생각해보며 떠올려봅시다.
피어 세션 정리
강의 리뷰 및 Q&A
- (9강) Self-supervised Pre-training Models
- (10강) Advanced Self-supervised Pre-training Models
과제 진행 상황 정리 & 과제 결과물에 대한 정리
[과제] Named Entity Recognition(NER) with Transformers library
마스터 클래스
마스터 소개
NLP의 주재걸 교수님 (카이스트 인공지능대학원 교수님, 전 고려대학교 컴퓨터학과 교수님)
라이브 Q&A
총평
오늘보다 더 성장한 내일의 저를 기대하며, 다음 주에 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA