강의 복습 내용
[DAY 19]
(7강) Transformer I
1. Transformer
- Transformer: High-Level View
- Attention is all you need, NeurIPS’17
- No more RNN or CNN modules
- Attention is all you need, NeurIPS’17
- RNN: Long-Term Dependency

- Bi-Directional RNNs
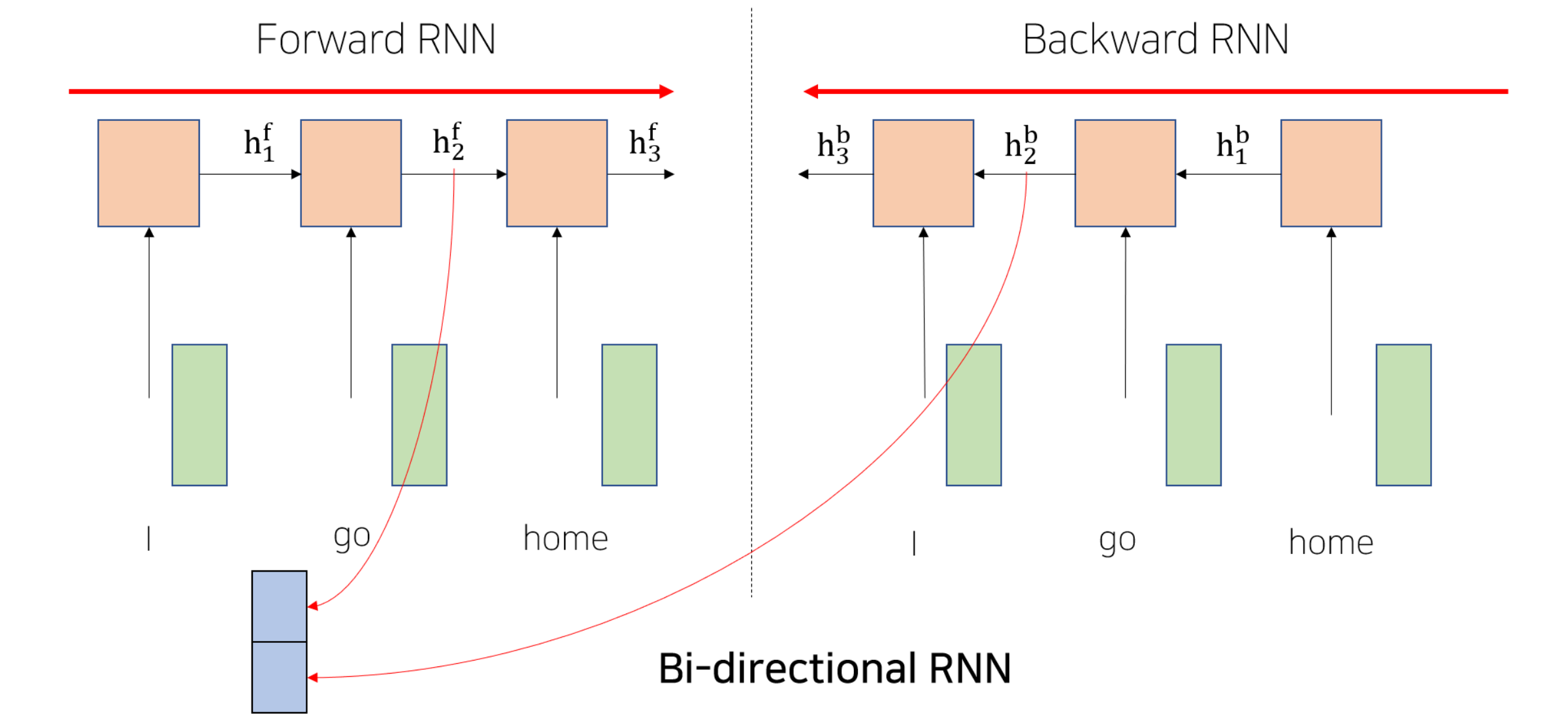
- Transformer: Long-Term Dependency
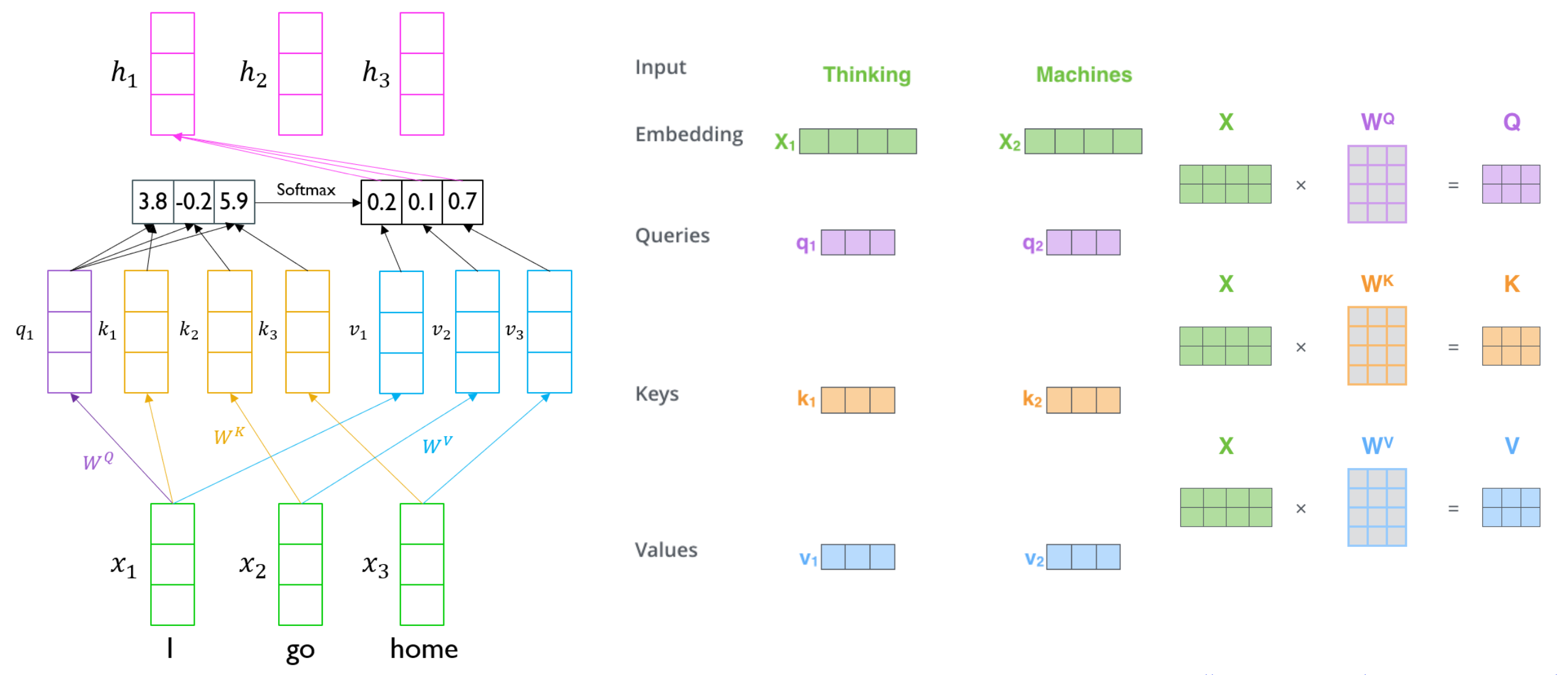
- Transformer: Scaled Dot-Product Attention
- Inputs: a query 𝑞 and a set of key-value (𝑘, 𝑣) pairs to an output
- Query, key, value, and output is all vectors
- Output is weighted sum of values
- Weight of each value is computed by an inner product of query and corresponding key
- Queries and keys have same dimensionality 𝑑𝑘, and dimensionality of value is 𝑑𝑣
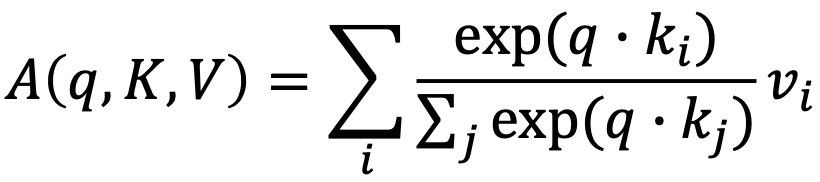
- When we have multiple queries 𝑞, we can stack them in a matrix 𝑄:
- Becomes:

- Example from illustrated transformer

- Problem
- As 𝑑𝑘 gets large, the variance of 𝑞𝑇𝑘 increases
- Some values inside the softmax get large
- The softmax gets very peaked
- Hence, its gradient gets smaller
- Solution
- Scaled by the length of query / key vectors:
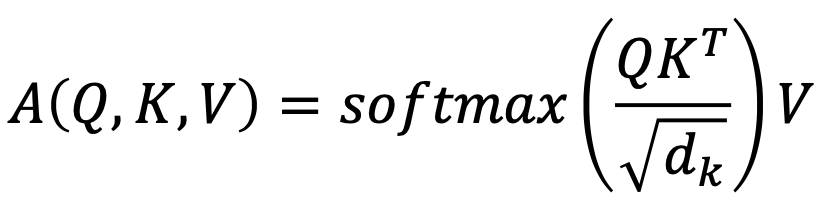
- Scaled by the length of query / key vectors:
(8강) Transformer II
2. Transformer (cont’d)
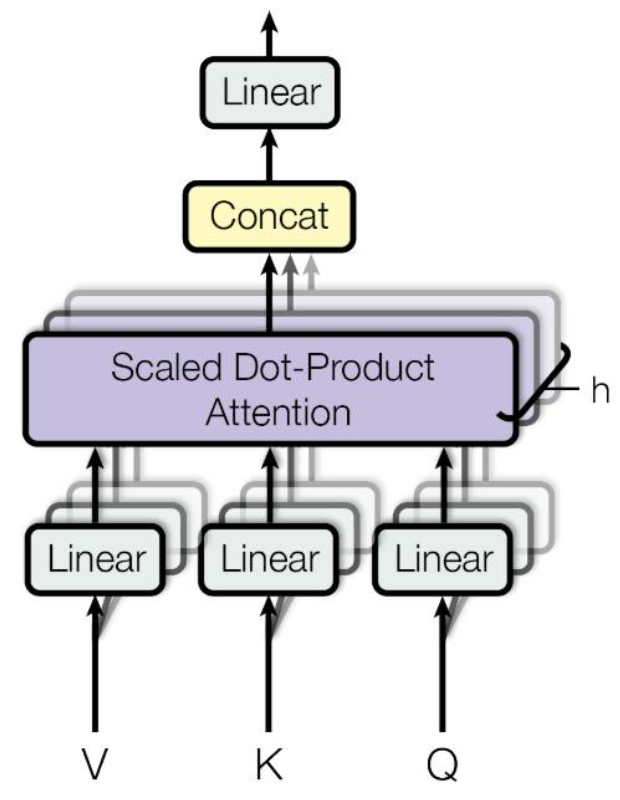
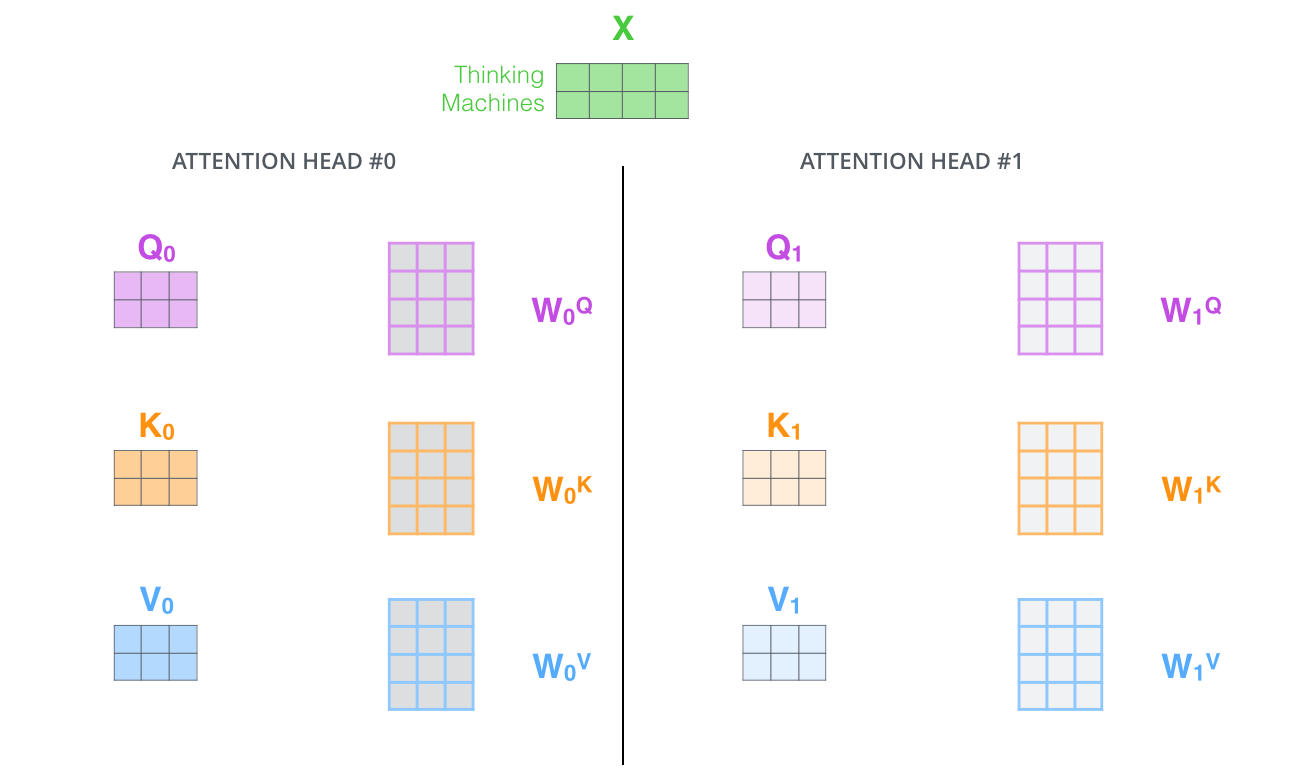
- Transformer: Multi-Head Attention
- The input word vectors are the queries, keys and values
- In other words, the word vectors themselves select each other
- Problem of single attention
- Only one way for words to interact with one another
- Solution
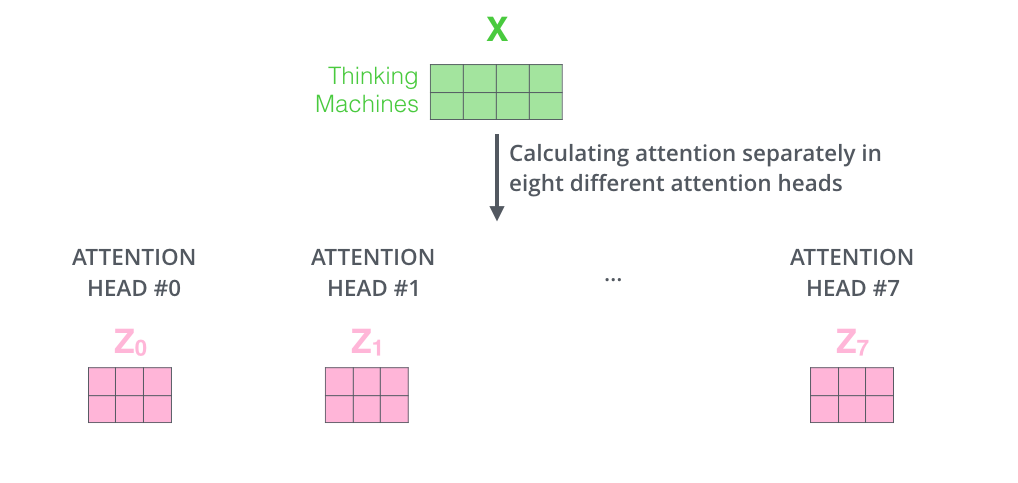
- Multi-head attention maps 𝑄, 𝐾, 𝑉 into the h number of lower-dimensional spaces via 𝑊 matrices
- Then apply attention, then concatenate outputs and pipe through linear layer

- Example from illustrated transformer
- Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types
- 𝑛 is the sequence length
- 𝑑 is the dimension of representation
- 𝑘 is the kernel size of convolutions
- 𝑟 is the size of the neighborhood in restricted self-attention
- Transformer: Block-Based Model
- Each block has two sub-layers
- Multi-head attention
- Two-layer feed-forward NN (with ReLU)
- Each of these two steps also has
- Residual connection and layer normalization:
- 𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(𝑥 + 𝑠𝑢𝑏𝑙𝑎𝑦𝑒𝑟(𝑥))
- Each block has two sub-layers
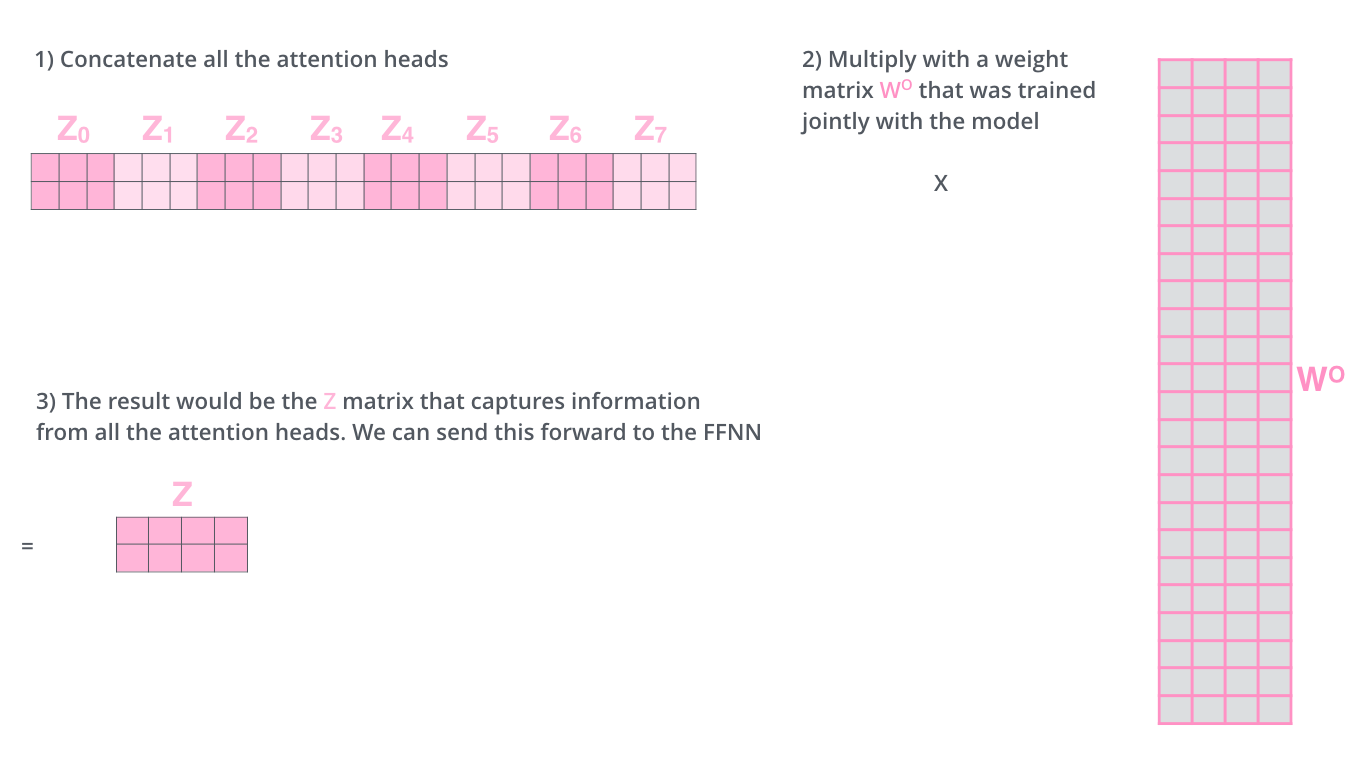
- Transformer: Layer Normalization
- Layer normalization changes input to have zero mean and unit variance, per layer and per training point (and adds two more parameters)
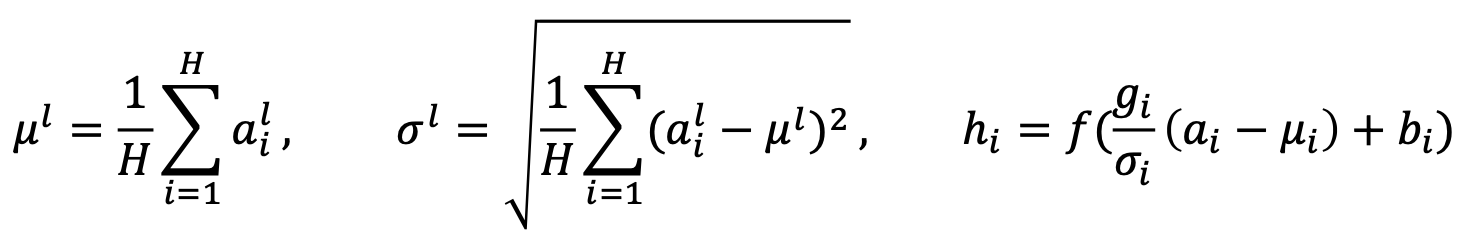
- Layer normalization consists of two steps:
- Normalization of each word vectors to have mean of zero and variance of one.
- Affine transformation of each sequence vector with learnable parameters
- Layer normalization changes input to have zero mean and unit variance, per layer and per training point (and adds two more parameters)
- Transformer: Positional Encoding
- Use sinusoidal functions of different frequencies
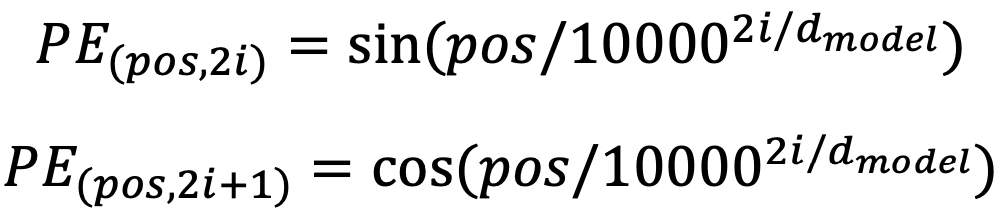
- Easily learn to attend by relative position, since for any fixed offset 𝑘, 𝑃𝐸(𝑝𝑜𝑠+𝑘) can be represented as linear function of 𝑃𝐸(𝑝𝑜𝑠)
- Use sinusoidal functions of different frequencies
- Transformer: Warm-up Learning Rate Scheduler
- Transformer: Encoder Self-Attention Visualization
- Words start to pay attention to other words in sensible ways
- Transformer: Decoder
- Two sub-layer changes in decoder
- Masked decoder self-attention on previously generated output
- Encoder-Decoder attention, where queries come from previous decoder layer and keys and values come from output of encoder
- Transformer: Masked Self-Attention
- Those words not yet generated cannot be accessed during the inference time
- Renormalization of softmax output prevents the model from accessing ungenerated words
Further Question
Attention은 이름 그대로 어떤 단어의 정보를 얼마나 가져올 지 알려주는 직관적인 방법처럼 보입니다. Attention을 모델의 Output을 설명하는 데에 활용할 수 있을까요?
Attention is not Explanation
In this work we perform extensive experiments across a variety of NLP tasks that aim to assess the degree to which attention weights provide meaningful “explanations" for predictions. We find that they largely do not. For example, learned attention weights are frequently uncorrelated with gradient-based measures of feature importance, and one can identify very different attention distributions that nonetheless yield equivalent predictions. Our findings show that standard attention modules do not provide meaningful explanations and should not be treated as though they do.
Attention is not not Explanation
We challenge many of the assumptions underlying this work, arguing that such a claim depends on one’s definition of explanation, and that testing it needs to take into account all elements of the model. We propose four alternative tests to determine when/whether attention can be used as explanation: a simple uniform-weights baseline; a variance calibration based on multiple random seed runs; a diagnostic framework using frozen weights from pretrained models; and an end-to-end adversarial attention training protocol. Each allows for meaningful interpretation of attention mechanisms in RNN models. We show that even when reliable adversarial distributions can be found, they don’t perform well on the simple diagnostic, indicating that prior work does not disprove the usefulness of attention mechanisms for explainability.
피어 세션 정리
강의 리뷰 및 Q&A
- (7강) Transformer I
- (8강) Transformer II
과제 진행 상황 정리 & 과제 결과물에 대한 정리
[과제] Byte Pair Encoding
Byte Pair Encoding에 대한 것으로, Neural Machine Translation of Rare Words with Subword Units을 참고하여 해결했습니다.
총평
오늘이 아니면 더 이상 기회가 없을 것 같아, 오늘은 꼭 transformer를 제대로 배우자고 생각했습니다.
그래서 학습 정리하면서 강의를 한번 보고, 복습하면서 강의를 한 번 더 보았습니다.
처음에는 제대로 이해하지 못했는데, 머릿속에 전체적인 윤곽을 가지고 다시 보니 제대로 이해할 수 있었습니다.
자연어 처리의 표준이 되어가고 있는 transformer를 이해한 만큼 마음이 든든해졌습니다.
그리고 과제 해설에서 hyperparameter tuning에 대한 강의가 너무 좋았습니다.
유용한 꿀팁이 많았던 만큼 내일 과제에서 바로 활용할 계획입니다.
오늘보다 더 성장한 내일의 저를 기대하며, 내일 뵙도록 하겠습니다.
읽어주셔서 감사합니다!






