강의 복습 내용
[Day 23] 군집 탐색 & 추천시스템 (기초)
[Graph 5강] 그래프의 구조를 어떻게 분석할까?
1. 군집 구조와 군집 탐색 문제
1.1 군집의 정의
- 군집(Community)이란 다음 조건들을 만족하는 정점들의 집합입니다
(1) 집합에 속하는 정점 사이에는 많은 간선이 존재합니다
(2) 집합에 속하는 정점과 그렇지 않은 정점 사이에는 적은 수의 간선이 존재합니다 - 수학적으로 엄밀한 정의는 아닙니다
1.2 실제 그래프에서의 군집들
- 온라인 소셜 네트워크의 군집들은 사회적 무리(Social Circle)을 의미하는 경우가 많습니다
- 온라인 소셜 네트워크의 군집들이 부정 행위와 관련된 경우도 많습니다
- 조직 내의 분란이 소셜 네트워크 상의 군집으로 표현된 경우도 있습니다
- 키워드 – 광고주 그래프에서는 동일한 주제의 키워드들이 군집을 형성합니다
- 뉴런간 연결 그래프에서는 군집들이 뇌의 기능적 구성 단위를 의미합니다
1.3 군집 탐색 문제
- 그래프를 여러 군집으로 ‘잘’ 나누는 문제를 군집 탐색(Community Detection) 문제라고 합니다
- 보통은 각 정점이 한 개의 군집에 속하도록 군집을 나눕니다
- 비지도 기계학습 문제인 클러스터링(Clustering)과 상당히 유사합니다
- 먼저 성공적인 군집 탐색부터 정의합시다
2. 군집 구조의 통계적 유의성과 군집성
2.1 비교 대상: 배치 모형
- 성공적인 군집 탐색을 정의하기 위해 먼저 배치 모형(Configuration Model)을 소개합니다
- 주어진 그래프에 대한 배치 모형은,
1) 각 정점의 연결성(Degree)을 보존한 상태에서
2) 간선들을 무작위로 재배치하여서 얻은 그래프를 의미합니다 - 배치 모형에서 임의의 두 정점 𝑖와 𝑗 사이에 간선이 존재할 확률은 두 정점의 연결성에 비례합니다
2.2 군집성의 정의
- 군집 탐색의 성공 여부를 판단하기 위해서, 군집성(Modularity)가 사용됩니다
- 그래프와 군집들의 집합 S가 주어졌다고 합시다
- 각 군집 𝑠 ∈ 𝑆가 군집의 성질을 잘 만족하는 지를 살펴보기 위해, 군집 내부의 간선의 수를 그래프와 배치 모형에서 비교합니다
- 구체적으로, 군집성은 다음 수식으로 계산됩니다

- 즉, 배치 모형과 비교했을 때, 그래프에서 군집 내부 간선의 수가 월등이 많을 수록 성공한 군집 탐색입니다
- 즉, 군집성은 무작위로 연결된 배치 모형과의 비교를 통해 통계적 유의성을 판단합니다 군집성은 항상 –1과 +1 사이의 값을 갖습니다
- 보통 군집성이 0.3 ~ 0.7 정도의 값을 가질 때, 그래프에 존재하는 통계적으로 유의미한 군집들을 찾아냈다고 할 수 있습니다
3. 군집 탐색 알고리즘
3.1 Girvan-Newman 알고리즘
- Girvan-Newman 알고리즘은 대표적인 하향식(Top-Down) 군집 탐색 알고리즘입니다
- Girvan-Newman 알고리즘은 전체 그래프에서 탐색을 시작합니다
- 군집들이 서로 분리되록, 간선을 순차적으로 제거합니다
- 어떤 간선을 제거해야 군집들이 분리될까요?
- 바로 서로 다른 군집을 연결하는 다리(Bridge) 역할의 간선입니다
- 서로 다른 군집을 연결하는 다리 역할의 간선을 어떻게 찾아낼 수 있을까요?
- 간선의 매개 중심성(Betweenness Centrality)을 사용합니다
- 이는 해당 간선이 정점 간의 최단 경로에 놓이는 횟수를 의미합니다
- 정점 𝑖로 부터 𝑗로의 최단 경로 수를 𝜎𝑖,𝑗라고 하고 그 중 간선 (𝑥,𝑦)를 포함한 것을 𝜎𝑖,𝑗(𝑥,𝑦) 라고 합시다
- 간선 (𝑥,𝑦)의 매개 중심성은 다음 수식으로 계산됩니다
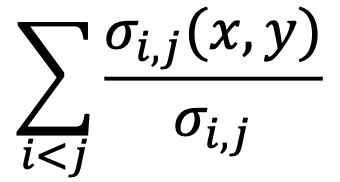
- 매개 중심성을 통해 서로 다른 군집을 연결하는 다리 역할의 간선을 찾아낼 수 있습니다
- Girvan-Newman 알고리즘은 매개 중심성이 높은 간선을 순차적으로 제거합니다
- 간선이 제거될 때마다, 매개 중심성을 다시 계산하여 갱신합니다
- 간선이 모두 제거될 때까지 반복합니다
- 간선의 제거 정도에 따라서 다른 입도(Granularity)의 군집 구조가 나타납니다
- 간선을 어느 정도 제거하는 것이 가장 적합할까요?
- 앞서 정의한 군집성을 그 기준으로 삼습니다
- 즉, 군집성이 최대가 되는 지점까지 간선을 제거합니다
- 단, 현재의 연결 요소들을 군집으로 가정하되, 입력 그래프에서 군집성을 계산합니다
- 정리하면, Girvan-Newman 알고리즘은 다음과 같습니다
1) 전체 그래프에서 시작합니다
2) 매개 중심성이 높은 순서로 간선을 제거하면서, 군집성을 변화를 기록합니다
3) 군집성이 가장 커지는 상황을 복원합니다
4) 이때,서로연결된정점들,즉연결요소를하나의군집으로간주합니다 - 즉, 전체 그래프에서 시작해서 점점 작은 단위를 검색하는 하향식(Top-Down) 방법입니다
3.2 Louvain 알고리즘
- Louvain 알고리즘은 대표적인 상향식(Bottom-Up) 군집 탐색 알고리즘입니다
- Louvain 알고리즘은 개별 정점에서 시작해서 점점 큰 군집을 형성합니다
- 그러면 어떤 기준으로 군집을 합쳐야 할까요?
- 정답은 이번에도 군집성입니다!
- 구체적으로 Louvain 알고리즘의 동작 과정은 다음과 같습니다
1) Louvain 알고리즘은 개별 정점으로 구성된 크기 1의 군집들로부터 시작합니다
2) 각 정점 𝑢를 기존 혹은 새로운 군집으로 이동합니다. 이 때, 군집성이 최대화되도록 군집을 결정합니다
3) 더 이상 군집성이 증가하지 않을 때까지 2)를 반복합니다
4) 각 군집을 하나의 정점으로하는 군집 레벨의 그래프를 얻은 뒤 3)을 수행합니다
5) 한 개의 정점이 남을 때까지 4)를 반복합니다
4. 중첩이 있는 군집 탐색
4.1 중첩이 있는 군집 구조
- 실제 그래프의 군집들을 중첩되어 있는 경우가 많습니다
- 앞서 배운 Girvan-Newman 알고리즘, Louvain 알고리즘은 군집 간의 중첩이 없다고 가정합니다
- 그러면 중첩이 있는 군집은 어떻게 찾아낼 수 있을까요?
4.2 중첩 군집 모형
- 이를 위해 아래와 같은 중첩 군집 모형을 가정합니다
1) 각 정점은 여러 개의 군집에 속할 수 있습니다
2) 각 군집 𝐴에 대하여, 같은 군집에 속하는 두 정점은 𝑃𝐴 확률로 간선으로 직접 연결됩니다
3) 두 정점이 여러 군집에 동시에 속할 경우 간선 연결 확률은 독립적입니다
4) 어느 군집에도 함께 속하지 않는 두 정점은 낮은 확률 𝜖으로 직접 연결됩니다 - 중첩 군집 모형이 주어지면, 주어진 그래프의 확률을 계산할 수 있습니다
- 그래프의 확률은 다음 확률들의 곱입니다
1) 그래프의 각 간선의 두 정점이 (모형에의해) 직접 연결될 확률
2) 그래프에서 직접 연결되지 않은 각 정점 쌍이 (모형에의해) 직접 연결 되지 않을 확률
4.2 커뮤니티 모형과 완화된 커뮤니티 모형
- 중첩 군집 탐색은 주어진 그래프의 확률을 최대화하는 중첩 군집 모형을 찾는 과정입니다
- 통계 용어를 빌리면, 최우도 추정치(Maximum Likelihood Estimate)를 찾는 과정입니다
4.3 완화된 중첩 군집 모형
- 중첩 군집 탐색을 용이하게 하기 위하여 완화된 중첩 군집 모형을 사용합니다
- 완화된 중첩 군집 모형에서는 각 정점이 각 군집에 속해 있는 정도를 실숫값으로 표현합니다
- 즉, 기존 모형에서는 각 정점이 각 군집에 속하거나 속하지 않거나 둘 중 하나였는데, 중간 상태를 표현할 수 있게 된 것입니다
- 최적화 관점에서는, 모형의 매개변수들이 실수 값을 가지기 때문에
- 익숙한 최적화 도구 (경사하강법 등)을 사용하여 모형을 탐색할 수 있다는 장점이 있습니다
5강 정리
- 군집 구조와 군집 탐색 문제
- 실제 그래프의 군집들은 무엇을 의미할까?
- 군집을 어떻게 찾아낼까?
- 군집 구조의 통계적 유의성과 군집성
- 배치 모형과의 비교를 통해 군집성을 측정
- 군집 탐색 알고리즘
- 하향식 알고리즘: Girvan-Newman 알고리즘
- 상향식 알고리즘: Louvain 알고리즘
- 중첩이 있는 군집 탐색
- (완화된) 중첩 군집 모형
[Graph 6강] 그래프를 추천시스템에 어떻게 활용할까? (기본)
1. 우리 주변의 추천 시스템
1.1 아마존에서의 상품 추천
- Amazon.com 메인 페이지에는 고객 맞춤형 상품 목록을 보여줍니다
- Amazon.com에서 특정 상품을 살펴볼 때, 함께 혹은 대신 구매할 상품 목록을 보여줍니다
1.2 넷플릭스에서의 영화 추천
- 넷플릭스 메인 페이지에는 고객 맞춤형 영화 목록을 보여줍니다
1.3 유튜브에서의 영상 추천
- 유튜브 메인 페이지에는 고객 맞춤형 영상 목록을 보여줍니다
- 유튜브는 현재 재생 중인 영상과 관련된 영상 목록을 보여줍니다
1.4 페이스북에서의 친구 추천
- 페이스북에서는 추천하는 친구의 목록을 보여줍니다
1.5 추천 시스템과 그래프
- 추천 시스템은 사용자 각각이 구매할 만한 혹은 선호할 만한 상품을 추천합니다
- 사용자별 구매 기록은 아래 예시처럼 그래프로 표현 가능합니다 구매 기록이라는 암시적(Implicit)인 선호만 있는 경우도 있고, 평점이라는 명시적(Explicit)인 선호가 있는 경우도 있습니다
- 추천 시스템은 사용자 각각이 구매할 만한 혹은 선호할 만한 상품/영화/영상을 추천합니다
- 추천 시스템의 핵심은 사용자별 구매를 예측하거나 선호를 추정하는 것입니다
- 그래프 관점에서 추천 시스템은 “미래의 간선을 예측하는 문제” 혹은 “누락된 간선의 가중치를 추정하는 문제”로 해석할 수 있습니다
2. 내용 기반 추천시스템
2.1 내용 기반 추천시스템의 원리
- 내용 기반(Content-based) 추천은 각 사용자가 구매/만족했던 상품과 유사한 것을 추천하는 방법입니다
- 예시는 다음과 같습니다
- 동일한 장르의 영화를 추천하는 것
- 동일한 감독의 영화 혹은 동일 배우가 출현한 영화를 추천하는 것
- 동일한 카테고리의 상품을 추천하는 것
- 동갑의 같은 학교를 졸업한 사람을 친구로 추천하는 것
- 내용 기반 추천은 다음 네 가지 단계로 이루어집니다
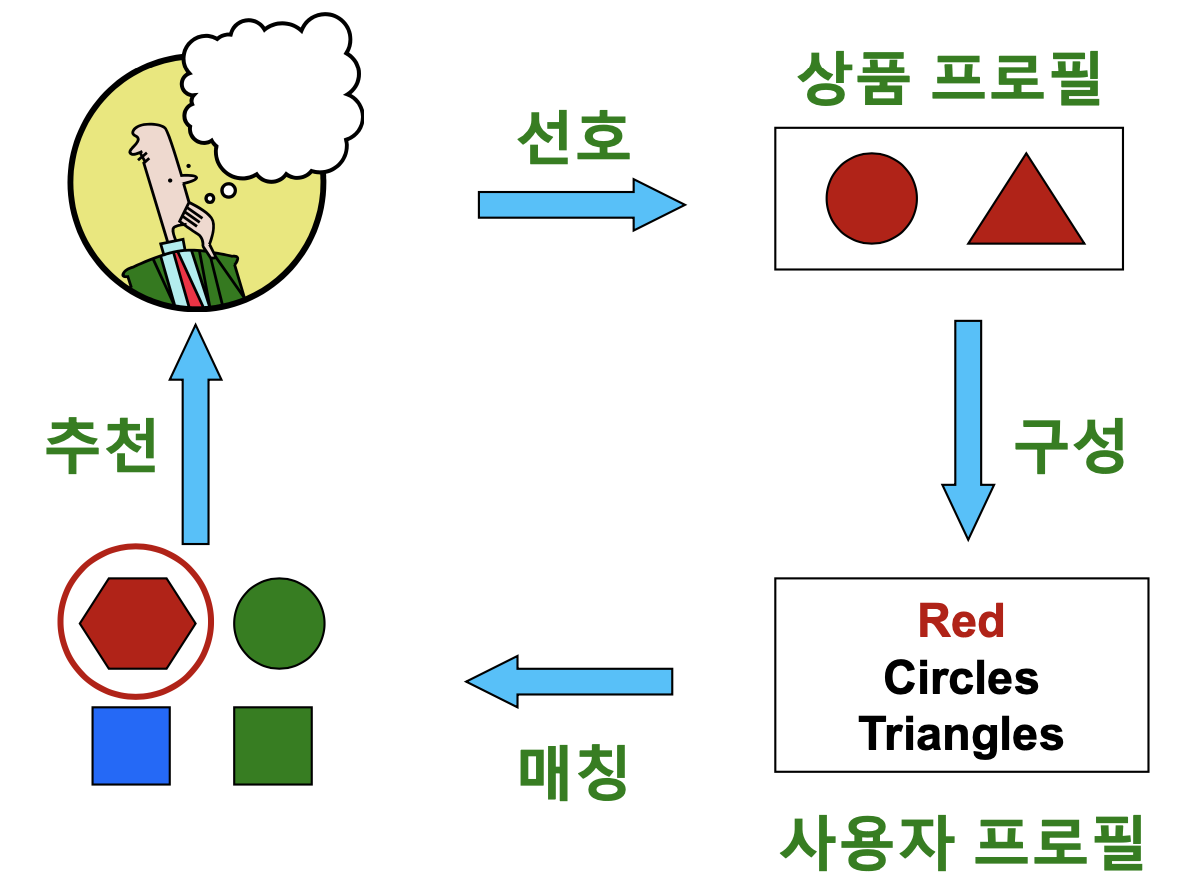
- 첫 단계는 사용자가 선호했던 상품들의 상품 프로필(Item Profile)을 수집하는 단계입니다
- 어떤 상품의 상품 프로필이란 해당 상품의 특성을 나열한 벡터입니다
- 영화의 경우 감독, 장르, 배우 등의 원-핫 인코딩이 상품 프로필이 될 수 있습니다
- 다음 단계는 사용자 프로필(User Profile)을 구성하는 단계입니다
- 사용자 프로필은 선호한 상품의 상품 프로필을 선호도를 사용하여 가중 평균하여 계산합니다
- 즉 사용자 프로필 역시 벡터입니다
- 다음 단계는 사용자 프로필과 다른 상품들의 상품 프로필을 매칭하는 단계입니다
- 사용자 프로필 벡터와 상품 프로필 벡터로 코사인 유사도를 계산합니다
- 즉, 두 벡터의 사이각의 코사인 값을 계산합니다
- 코사인 유사도가 높을 수록, 해당 사용자가 과거 선호했던 상품들과 해당 상품이 유사함을 의미합니다
- 마지막 단계는 사용자에게 상품을 추천하는 단계입니다
- 계산한 코사인 유사도가 높은 상품들을 추천합니다
- 첫 단계는 사용자가 선호했던 상품들의 상품 프로필(Item Profile)을 수집하는 단계입니다
2.2 내용 기반 추천시스템의 장단점
- 내용 기반 추천시스템은 다음 장점을 갖습니다
(1) 다른 사용자의 구매 기록이 필요하지 않습니다
(2) 독특한 취향의 사용자에게도 추천이 가능합니다
(3) 새 상품에 대해서도 추천이 가능합니다
(4) 추천의 이유를 제공할 수 있습니다 - 내용 기반 추천시스템은 다음 단점을 갖습니다
(1) 상품에 대한 부가 정보가 없는 경우에는 사용할 수 없습니다
(2) 구매 기록이 없는 사용자에게는 사용할 수 없습니다
(3) 과적합(Overfitting)으로 지나치게 협소한 추천을 할 위험이 있습니다
3. 협업 필터링 추천시스템
3.1 협업 필터링의 원리
- 사용자-사용자 협업 필터링은 다음 세 단계로 이루어집니다
- 추천의 대상 사용자를 𝑥라고 합시다
- 우선 𝑥와 유사한 취향의 사용자들을 찾습니다
- 다음 단계로 유사한 취향의 사용자들이 선호한 상품을 찾습니다
- 마지막으로 이 상품들을 𝑥에게 추천합니다
- 사용자-사용자 협업 필터링의 핵심은 유사한 취향의 사용자를 찾는 것입니다
- 그런데 취향의 유사도는 어떻게 계산할까요?
- 취향의 유사성은 상관 계수(Correlation Coefficient)를 통해 측정합니다
- 사용자 𝑥의 상품 𝑠에 대한 평점을 𝑟𝑥𝑠라고 합시다
- 사용자 𝑥가 매긴 평균 평점을 𝑟𝑥라고 합시다
- 사용자 𝑥와 𝑦가 공동 구매한 상품들을 𝑆𝑥𝑦라고 합시다
- 사용자 𝑥와 𝑦의 취향의 유사도는 아래 수식으로 계산합니다
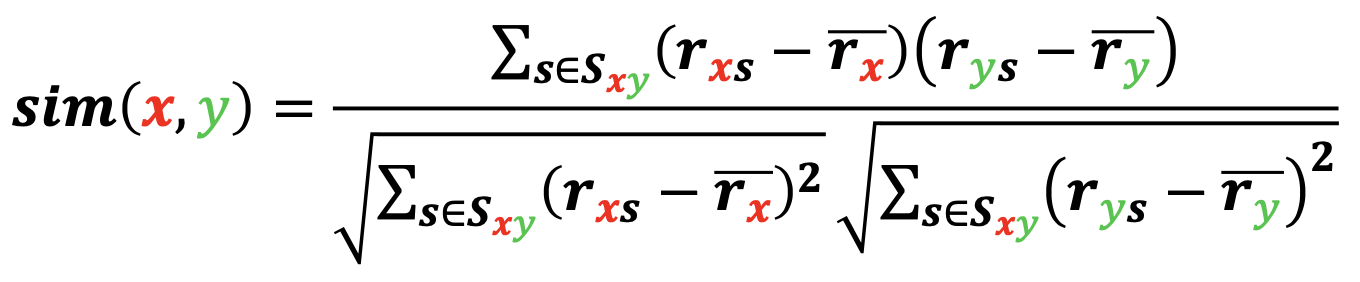
- 즉, 통계에서의 상관 계수(Correlation Coefficient)를 사용해 취향의 유사도를 계산합니다
- 구체적으로 취향의 유사도를 가중치로 사용한 평점의 가중 평균을 통해 평점을 추정합니다
- 사용자 𝑥의 상품 𝑠에 대한 평점을 𝑟𝑥𝑠를 추정하는 경우를 생각합시다
- 앞서 설명한 상관 계수를 이용하여 상품 𝑠를 구매한 사용자 중에 𝑥와 취향이 가장 유사한 𝑘명의 사용자 𝑁(𝑥; 𝑠)를 뽑습니다
- 평점 𝑟𝑥𝑠는 아래의 수식을 이용해 추정합니다

- 즉, 취향의 유사도를 가중치로 사용한 평점의 가중 평균을 계산합니다
- 마지막 단계는 추정한 평점이 가장 높은 상품을 추천하는 단계입니다
- 추천의 대상 사용자를 𝑥라고 합시다
- 앞서 설명한 방법을 통해, 𝑥가 아직 구매하지 않은 상품 각각에 대해 평점을 추정합니다
- 추정한 평점이 가장 높은 상품들을 𝑥에게 추천합니다
3.2 협업 필터링의 장단점
- 협업 필터링은 다음 장점과 단점 갖습니다
(+) 상품에 대한 부가 정보가 없는 경우에도 사용할 수 있습니다
(−) 충분한 수의 평점 데이터가 누적되어야 효과적입니다
(−) 새 상품, 새로운 사용자에 대한 추천이 불가능합니다
(−) 독특한 취향의 사용자에게 추천이 어렵습니다
4. 추천 시스템의 평가
4.1 데이터 분리
- 추천 시스템의 정확도는 어떻게 평가할까요?
- 먼저 데이터를 훈련(Training) 데이터와 평가(Test) 데이터로 분리합니다
- 평가 데이터는 주어지지 않았다고 가정합시다
- 훈련 데이터를 이용해서 가리워진 평가 데이터의 평점을 추정합니다
- 추정한 평점과 실제 평가 데이터를 비교하여 오차를 측정합니다
4.2 평가 지표
- 추정한 평점과 실제 평가 데이터를 비교하여 오차를 측정합니다
- 오차를 측정하는 지표로는 평균 제곱 오차(Mean Squared Error, MSE)가 많이 사용됩니다
- 평가 데이터 내의 평점들을 집합을 𝑇라고 합시다
- 평균 제곱 오차는 아래 수식으로 계산합니다

- 평균 제곱근 오차(Root Mean Squared Error, RMSE)도 많이 사용됩니다
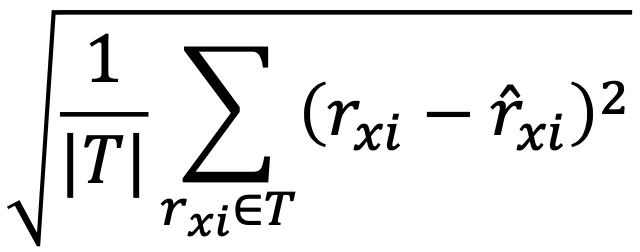
- 이 밖에도 다양한 지표가 사용됩니다
- 추정한 평점으로 순위를 매긴 후, 실제 평점으로 매긴 순위와의 상관 계수를 계산하기도 합니다
- 추천한 상품 중 실제 구매로 이루어진 것의 비율을 측정하기도 합니다
- 추천의 순서 혹은 다양성까지 고려하는 지표들도 사용됩니다
6강 정리
- 우리 주변의 추천 시스템
- Amazon.com, 넷플릭스, 페이스북, 유튜브 등
- 내용 기반 추천 시스템
- 장점: 새로운 상품에 대한 추천이 가능
- 단점:상품에대한부가정보가있는경우에만사용가능
- 협업 필터링
- 장점:부가정보가없는경우에도사용가능 – 단점: 새로운 상품에 대한 추천이 불가능
- 추천 시스템의 평가
- 학습/평가 데이터 분리, 평균 제곱(근) 오차
피어 세션 정리
강의 리뷰 및 Q&A
- [Graph 5강] 그래프의 구조를 어떻게 분석할까?
- [Graph 6강] 그래프를 추천시스템에 어떻게 활용할까? (기본)
과제 진행 상황 정리 & 과제 결과물에 대한 정리
[과제 2] UV 분해를 활용하여 추천시스템 구현하기



총평
카카오 아레나의 브런치 사용자를 위한 글 추천 대회를 준비하고 있어서 그런지 오늘 두 번째 강의였던 추천시스템에 대한 강의가 너무 좋았습니다.
그뿐만 아니라, 과제도 구현하는 맛이 있어서 재미있었습니다.
그리고 오늘 강의와 과제가 비교적 가벼웠기 때문에, 바쁜 일상 속에서 간만의 여유가 반가웠습니다.
최근 피로감이 없잖아 쌓여있어, 오늘만큼은 조금 쉬어가려고 합니다.
오늘보다 더 성장한 내일의 저를 기대하며, 내일 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA