강의 복습 내용
[DAY 35]
(9강) Multi-modal: Captioning and speaking
- Challenge (1) - Different representations between modalities
- Challenge (2) - Unbalance between heterogeneous feature spaces
- Challenge (3) - May a model be biased on a specific modality
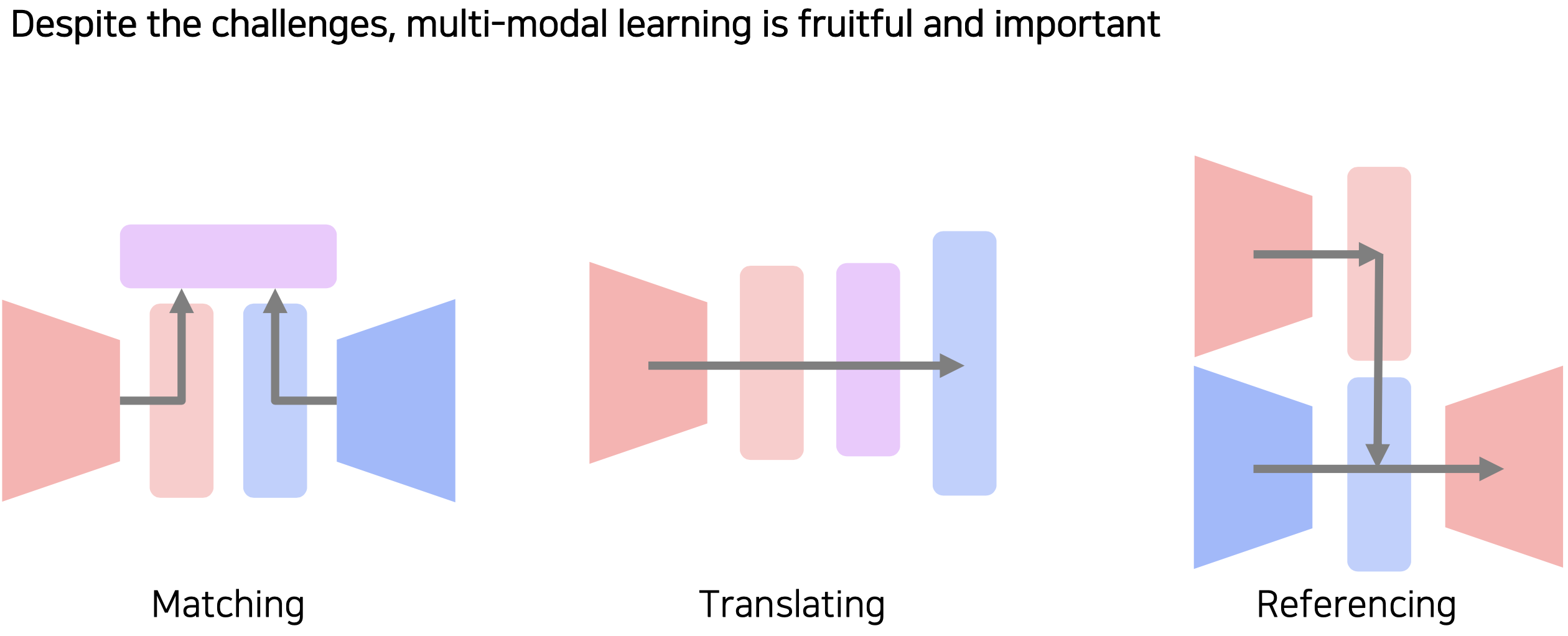
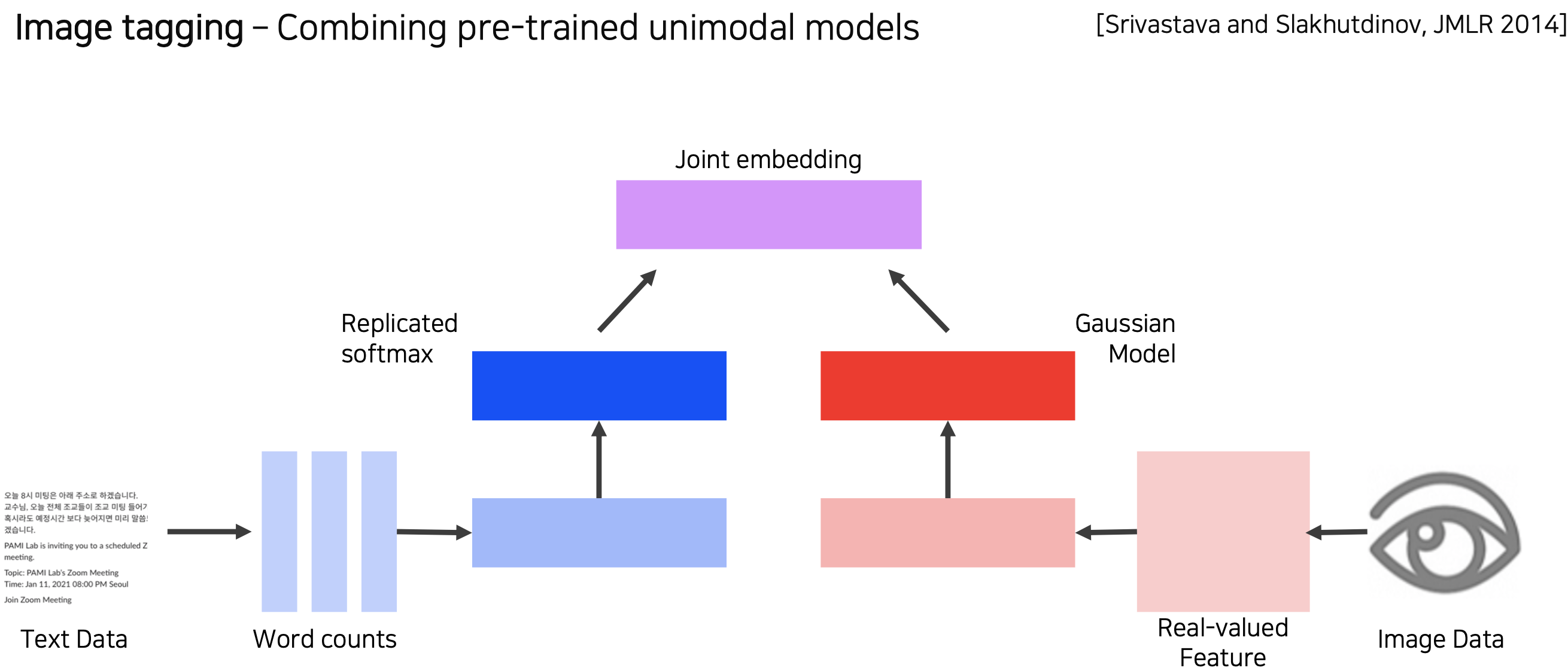


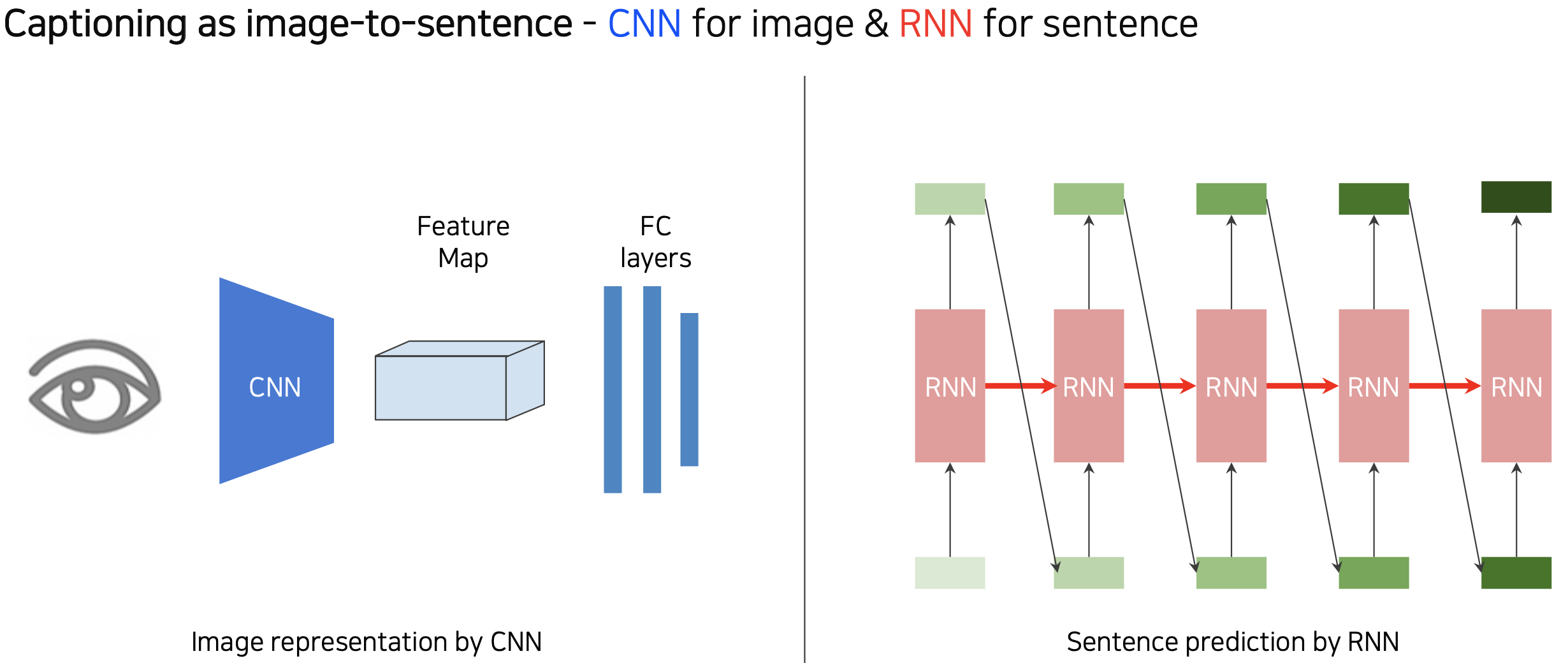

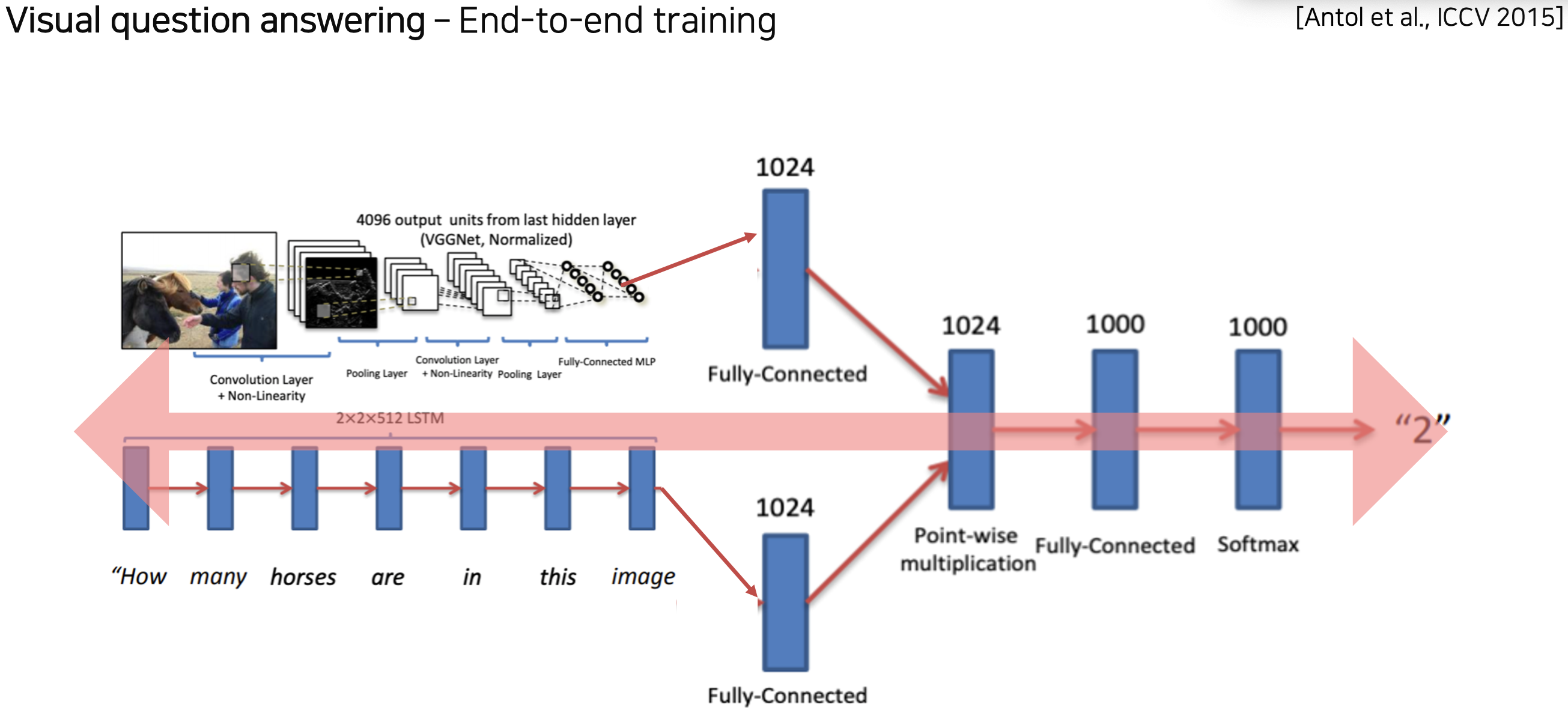
(9강 실습) Image captioning


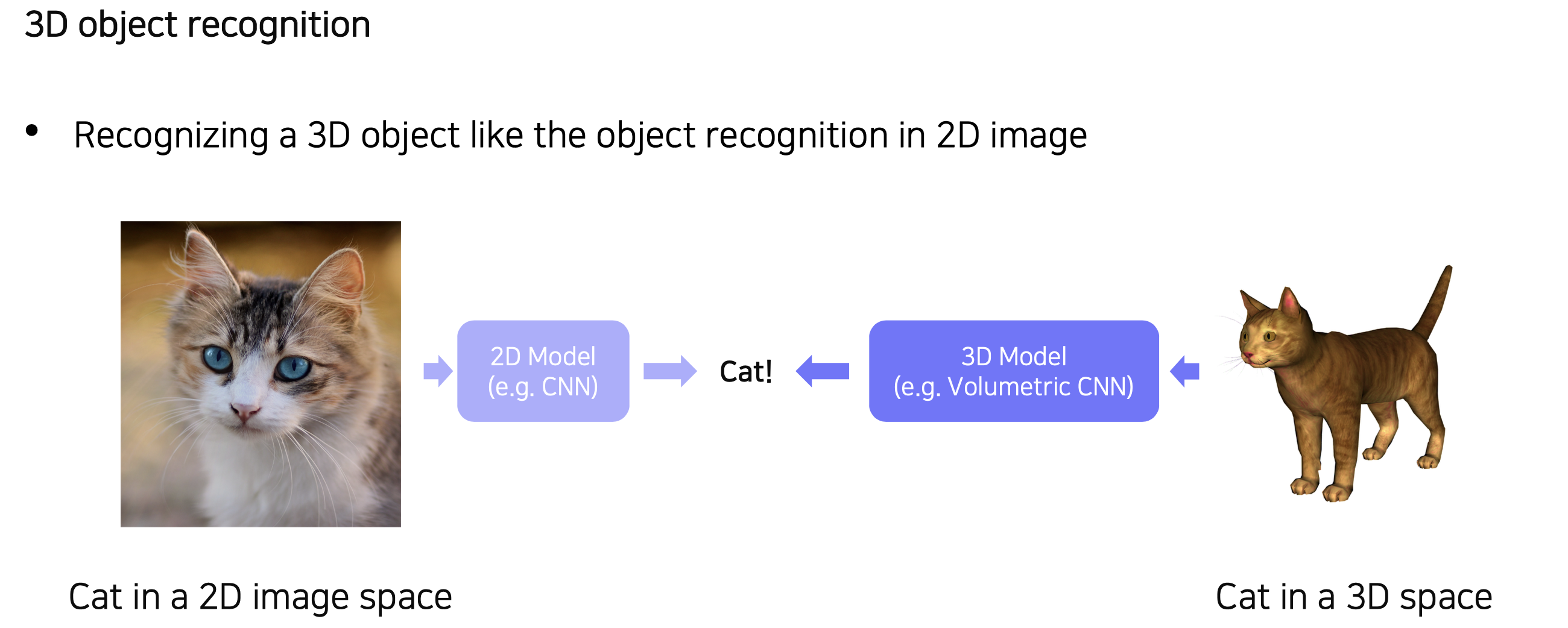
(10강) 3D understanding



Further Question
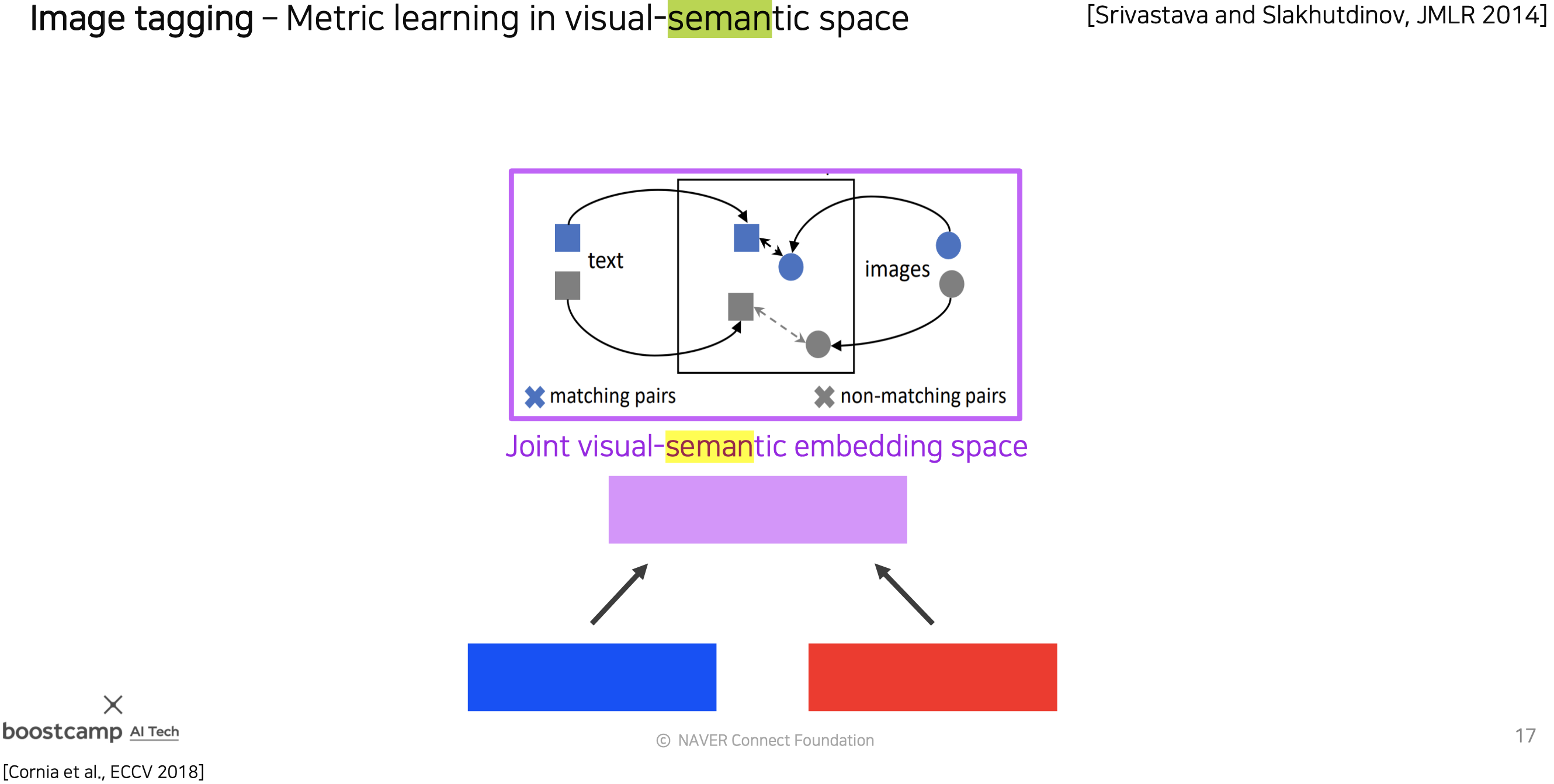
(1) Multi-modal learning에서 feature 사이의 semantic을 유지하기 위해 어떤 학습 방법을 사용했나요?
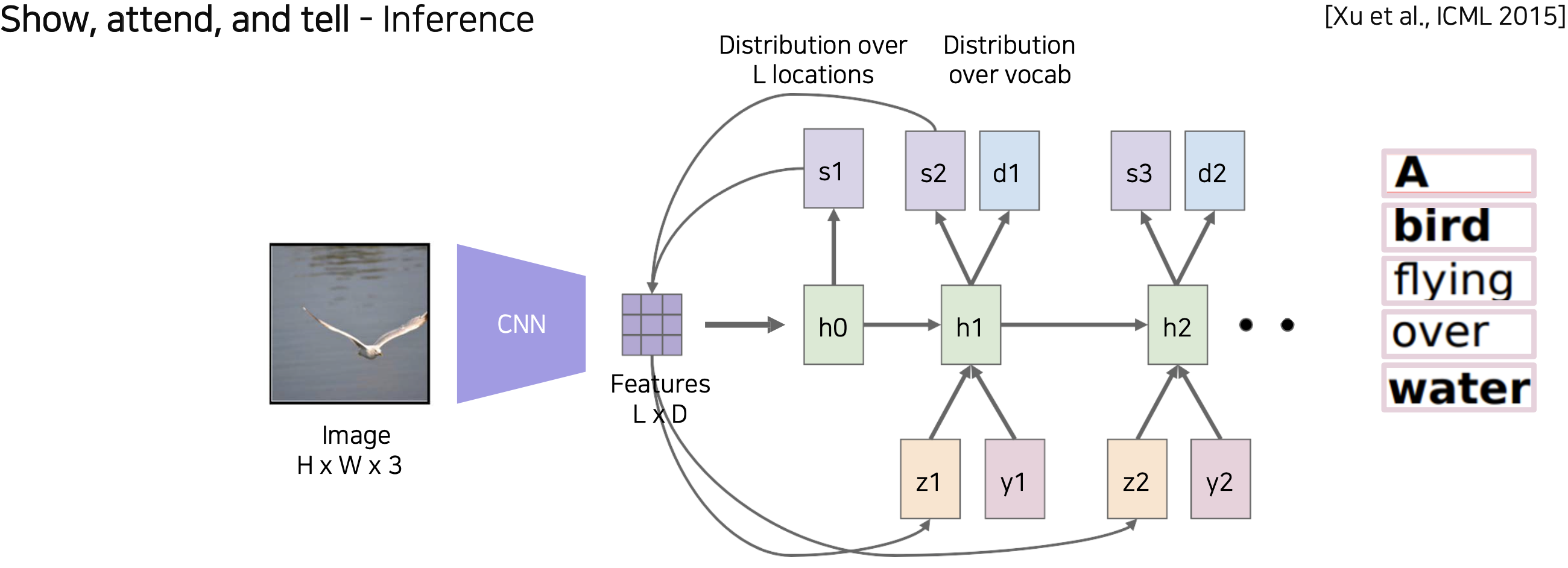
(2) Captioning task를 풀 때, attention이 어떻게 사용될 수 있었나요?
(3) Sound source localization task를 풀 때, audio 정보는 어떻게 활용되었나요?

피어 세션 정리
강의 리뷰 및 Q&A
- (9강) Multi-modal: Captioning and speaking
- (9강 실습) Image captioning
- (10강) 3D understanding
마스터 클래스
마스터 소개
Computer Vision의 오태현 교수님 (POSTECH 전자전기공학과 교수님, 전 Facebook AI Research 방문연구원)
사전 질문 답변
- 마스터님은 다양한 경험을 하신 것으로 알고 있습니다. 만약 학부로 돌아간다면 어떤 공부 또는 활동을 꼭 해야겠다고 생각하시는 것이 있으실까요? 현재의 전공을 선택하시게 된 계기와 자신의 한계를 돌파하시는 원동력은 무엇인지도 궁금합니다.
- 수학의 기초가 단단하면 공학적 사고를 하기가 쉽기 때문에, 수학 공부를 더 하고 싶다.
- 가능하다면, 장기간 해외 여행을 가보고 싶다.
- 해외에 살면서 느낀 경험은 확실히 달랐다.
- 3개월 정도 살아보면 좋을 것 같고, 짧더라도 다녀올 수 있으면 좋을 것 같다.
- 한번에 한계를 돌파하기는 쉽지 않기 때문에, 매일 조금씩 돌파해나가는 것이 중요하다.
- 마스터님께서는 동기 부여를 중요하게 생각하시는 것 같습니다. 어떤 계기로 공부를 해야겠다 생각하셨는지, 왜 해당 도메인을 선택하신 건지, 어떤 삶을 위해 교수님이 되셨는지 궁금합니다.
- 고등학생 때, 추운 겨울 밖에서 근무를 해보니 공부를 해야겠다고 생각했다.
- 중고등학생 때, 게임을 좋아서 컴퓨 공학을 선택하게 되었다.
- 차별성을 위해 컴소가 아니라 컴공을 선택했다.
- 안정적인 직업 + 연구 + 가르침을 동시에 만족할 수 있는 교수를 직업으로 삼게 되었다.
- 강의에서 굉장히 다양한 논문들을 소개해주셨는데, 강의를 준비하실 때 기대하셨던 학생들의 이해 수준은 어느정도였는지 궁금합니다.
- 100% 이해하리라고 생각하지 않았따.
- 컴퓨터 비전에는 엄청나게 많은 토픽들이 있고 어떤 흐름인지를 보여주고 싶었다.
- 대학교 4학년 ~ 수준의 강의이다.
- 과제의 난이도가 꽤 있는 편이다.
- 코드를 보고 수정할 수 있을 정도면 중급은 되는 것 같다.
- CV 분야는 다른 딥러닝 분야보다 기술이 빨리 발전했기 때문에 높은 수준의 기술을 가진 사람들도 상대적으로 더 많을 것 같습니다. 현재 CV 분야의 회사나 대학원에서는 어느 정도 수준의 구현 능력을 기대하는지 궁금합니다.
- 많을 것 같지만, 회사에서 요구하는 사람은 얼마 없다.
- 프론트엔드나 백엔드보다는 코딩을 못할 수 있지만, 꼼꼼하게 코딩하여 실수가 적고, 공유가 가능한 코드를 작성할 수 있어야 한다.
- 그리고 빠르게 프로토타입을 구현할 수 있는 능력이 중요하다.
- 각 강의마다 다양한 모델들에 대해서 설명해주시는데 현재 제한된 시간내에 강의를 수강하는 수강생의 입장에서 각 모델들에 대한 이해를 어느정도 하는게 좋을까요? 예를들어 각 모델들에 대한 논문이나 코드를 자세히 본다던지 아니면 모델에 대한 전체적인 구조와 원리정도만 짚고 넘어가는게 좋을지 또는 대표적인 모델에 대한 논문과 코드만 구체적으로 공부할지 교수님의 의견이 궁금합니다. 또한 현업에 계셨을땐 어느정도로 모델에 대해 이해하시고 그 모델을 사용하셨는지도 궁금합니다.
- 80% 정도 이해했으면 잘 했다고 생각한다.
- 모든 내용에서 대해서 논문이나 코드를 자세하게 볼 필요는 없을 것 같다.
- 대표적인 부분들만 논문이나 코드를 공부하면 좋을 것 같다.
- 학습을 하면서 들었던 생각이 모델을 만들때 end-to-end 구조로 점점 바뀌고 있다고 느꼈는데 최신 연구 동향이 데이터를 분석하여 어느정도 처리 후 모델을 학습하는 것 보다 end-to-end 구조로 모델을 학습하는 것을 더 선호하고 있나요?? 혹시 그렇다면 왜 그런지 이유와 CV 분야가 아닌 다른 분야에서도 end-to-end 구조를 선호하고 있는 것인지 알고 싶습니다.
- 사람이 디자인을 하면, 미처 고려하지 못한 부분이 생기기 마련이다.
- 따라서 end-to-end를 사용하면 사람이 만든 것 보다 좋은 모델이 나올 활률이 높다.
- 데이터가 많다면 end-to-end가 좋지만, 데이터가 적다면 사람이 직접 만들어주는 것이 좋다.
- 최근 발표된 Dall-E model은 이미지 생성에서 큰 성과를 보였고 vit등 다양한 트랜스포머 기반 모델이 등장하고 있는데 트랜스포머 구조가 CNN을 완전히 대체하게 될까요? 추가적으로 CNN와 비교하여 트랜스포머 구조가 가지는 장 단점에는 어떤 것이 있을까요?
- 개인적인 생각으로는 데이터가 충분하다면 트랜스포머로 가게 될 것 같다.
- 다만, 사용처에 따라 다를 수 있다.
- 트랜스포머가 역사적인 기술 중 하나라고 생각하고 있다.
- 데이터가 충분하다의 기준은 지극히 주관적이다.
- 트랜스포머는 자유도가 높기 때문에, 학습에 필요한 데이터가 많아야 한다.
- CycleGAN 처럼 비지도학습이 되면 데이터를 모을때 장점이 있는데, Computer Vision에서 또 다른 비지도학습 모델은 무엇이 있나요?
- pretext task : 영상를 자르고 순서를 섞은 뒤, 원래대로 맞추는 과제이다.
- 해당 과제를 해결한다는 것은 원래의 영상을 알고 있다는 것이기 때문에, 다양한 테스크에 활용될 수 있다.
- 3d의 경우 사람이 라벨링하기가 어렵기 때문에, 비지도 학습을 사용한다.
- 자율주행 자동차에서는 단순히 detection이 아닌 물체의 다음 위치 예측도 중요한 이슈라고 생각되는데 이에 관련된 대표적인 방법론과 논문을 소개해주시면 감사하겠습니다.
- 생성 모델이 중요한 이슈라고 생각한다.
- forecasting, trajectory, 3d frustum
- 현재 딥페이크는 주로 인물의 얼굴이나, 특정 부위를 합성하는 방식이 주를 이루고 있다고 들었습니다. 좀 더 자연스러운 합성을 위해서 얼굴 등 지협적인 부분에 그치지 않고 신체 전체를 합성하는 방법이 앞으로 등장할 수 있을 것 같습니다. 이에 대한 연구가 진행되고 있다면 현재 당면한 대표적인 어려움은 어떤 것인지 궁금합니다. 딥페이크로 바꾸는 신체 부위 이외에 다른 부위가 자연스럽게 연결될 수 있게 고치는 과정에서 발생하는 컴퓨팅파워를 효율적으로 처리하는 대표적인 매커니즘에는 어떤 것이 있을까요?
- knowledge distillation이 많이 사용되고 있다.
- 신체 전체를 자연스럽게 표현하는 것이, pose transfer이다.
- imposter, liguid gan
- 카메라의 한계 상 원근감을 이해하지 못하기 때문에 발생하는 문제가 있다.
- 다만, 이미지 하나 가지고는 원근감 문제가 해결되지 않는다.
- 그외에도 가려진 부분은 어떻게 처리할 것인지?
- 불가능한 자세를 생성하는 문제도 있다.
- 기업에서 자율주행에 대해 연구개발을 진행할 때, 주행 데이터를 내부 시운전을 통해서도 수집할 수 있겠지만, 그것만으로는 부족할 것으로 생각되는데, 어떻게 데이터 수집을 하는지 궁금합니다. 또한 카메라 또는 Lidar를 통해 데이터를 수집한다면 데이터 크기가 상당할텐데, 여러 저장소에 흩어져 있다면 학습을 어떻게 수행하나요?
- disrtibuted learning
- federated learning
- 영상을 처리하는 문제에 있어, 속도가 굉장히 중요할 것으로 생각되는데 python이 아닌 c언어의 비중이 어느정도 되는지 궁금합니다.
- 프로토타입이 빠르기 때문에 파이썬을 사용한다.
- 파이썬으로 만들어진 모델을 c언어로 컨버트해주는 프로그램도 많이 있기 때문에, 이를 활용하면 충분하다.
- 3D data의 경우 2D data를 처리하는 것에 비해 더 많은 연산처리량이 필요할 것으로 예상되는데, 이를 real time에서 사용하기 위한 방법론이나 연구가 진행되고 있나요?
- sparse matrix를 어떻게 최적화 할 것인가?
- 3d 데이터를 2d 데이터로 랜더링하면 연상량을 줄일 수 있다.
- CV에서 현재 가장 주목 받고 있는 분야는 무엇인가요?(ex. self-supervised, 3D segmentation 등)
- self-supervised learning도 중요하지만, semi-supervised learning까지 확장되어야지만 쓸만할 것 같다.
- 그외에는 3d 분야와 GAN이 있다.
- GAN의 경량화는 어떻게 연구가 이루어지고 있나요. GAN에서도 여러가지 task가 있겠지만 사람의 머리 색을 바꾼다던가 스타일을 바꾸다던가 원본 영상이 없는 경우 정확도 측정은 어떻게 이루어 지나요?
- 일반 딥러닝 모델과는 다르다.
- gan은 생성을 해야하기 때문에, 경량화하기 쉽지 않다.
- knowledge distillation을 활용하며
총평
많이 아쉬웠던 한 주였습니다.
오늘보다 더 성장한 내일의 저를 기대하며, 다음 주에 뵙도록 하겠습니다.
읽어주셔서 감사합니다!

PLUS ULTRA