코드 살펴보기 - 공통
evaluate 방법
data 불러오기
인공지능 기본개념
모델과 데이터가 준비되었으면, 데이터에 매개변수를 최적화하여 모델을 학습하고, 검증하고, 테스트할 차례입니다. 모델을 학습하는 과정은 반복적인 과정을 거칩니다. (이 반복 과정에서 epoch, batch, iteration 개념을 사용) 각 반복 단계에서 모델은 출력을 추측하고, 추측과 정답 사이의 오류(손실(loss))를 계산하고, 매개변수에 대한 오류의 도함수(derivative)를 수집한 뒤, 최적화 알고리즘을 사용하여 이 파라미터들을 최적화(optimize) 합니다. 즉 딥러닝에서 모델을 학습시킨다는건 최적화(optimization) 태스크를 수행하는 것과 같습니다.
model
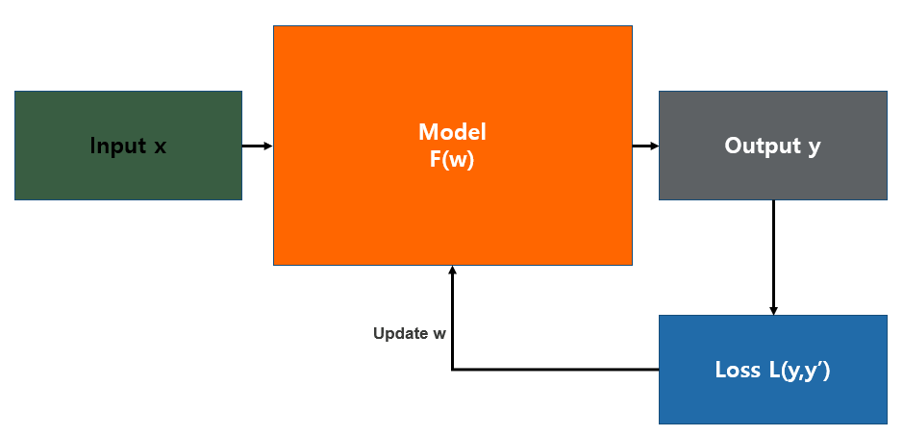
입력 값(input)을 먹고 예측 값(output)을 돌려주는 프로그램.
이 예측 값과 실제 값의 차이가 loss이다.
모델은 loss를 줄이는 학습을 반복해서 더 정교한 예측 값을 산출하는 모델이 될 수 있다.
loss_fn
손실함수는 loss를 표현하는 지표다.
loss가 크면 클수록 모델이 데이터를 잘 처리하지 못하는 정도가 크다. = 성능이 나쁘다.👿
이 나쁜 정도를 어떻게 표현하는지에 따라 여러 가지 손실함수가 존재한다.
통계학적 모델이 회귀(regression), 분류(classification) 두 종류로 나뉘고 손실함수도 이에 따라 두 가지 종류로 나뉜다.
회귀 타입
평균 오차 계산법이 대표적으로 사용되며, 평균 오차를 계산하는 방식에 따라 아래와 같이 구분됨
- MAE
- MSE
- RMSE
분류 타입
- Binary cross-entropy
- Categorical cross-entropy
이 이상으로 종류마다 파고들면 무시무시한 수식들이 나와서 조사는 여기까지..
dataloader
pytorch에서 사용되는 듯.
DataLoader는 아래의 복잡한 과정들을 추상화해서 순회하며 사용할 수 있는 객체다.
Dataset은 데이터셋의 특징(feature)을 가져오고 하나의 샘플에 정답(label)을 지정하는 일을 한 번에 합니다. 모델을 학습할 때, 일반적으로 샘플들을 “미니배치(minibatch)”로 전달하고, 매 에폭(epoch)마다 데이터를 다시 섞어서 과적합(overfit)을 막고, Python의 multiprocessing 을 사용하여 데이터 검색 속도를 높이려고 합니다.
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)optimizer
optimize (최적화)
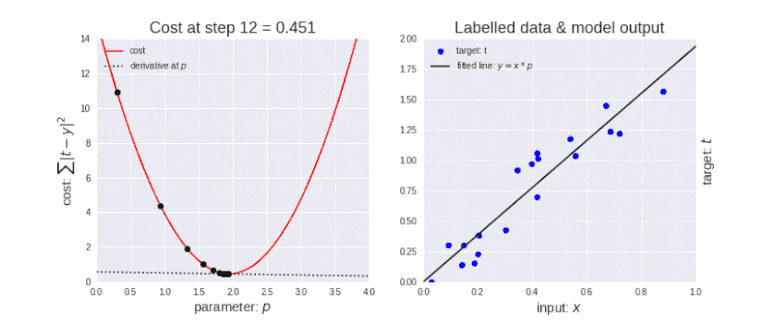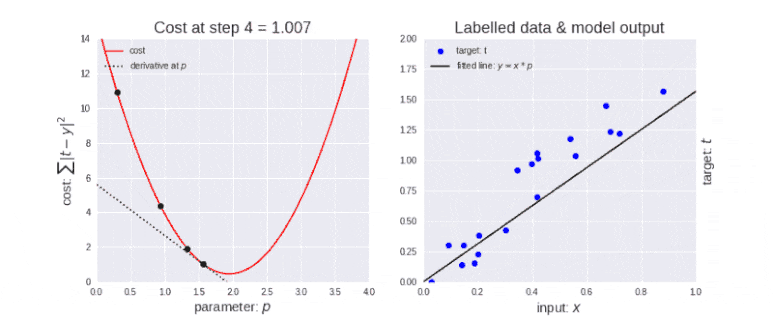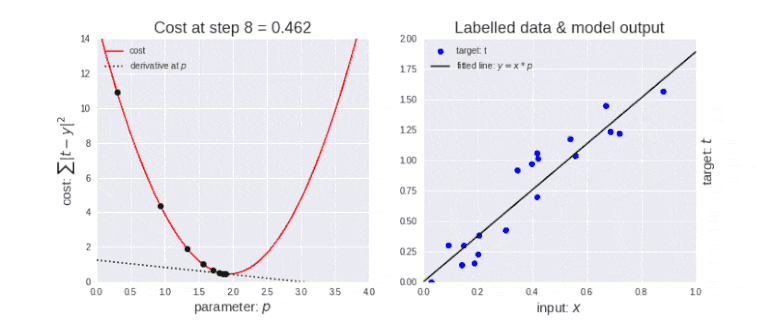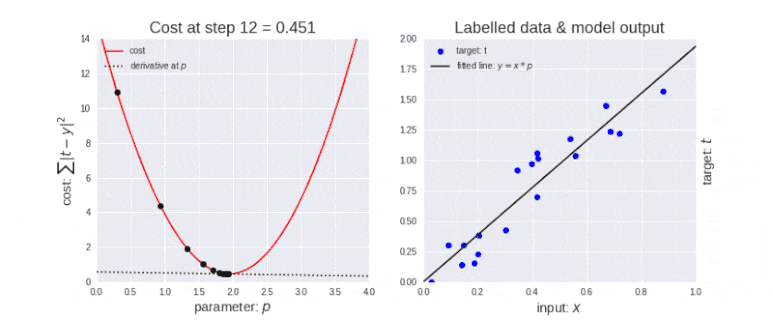
최적화: 각 학습 단계에서 모델의 오류를 줄이기 위해 모델 매개변수를 조정하는 과정
optimizer
딥러닝에서 학습 속도를 빠르고 안정적이게 하기 위해 손실함수(loss function)를 최소화하는 최적의 가중치(weight)를 업데이트 하는 방법.
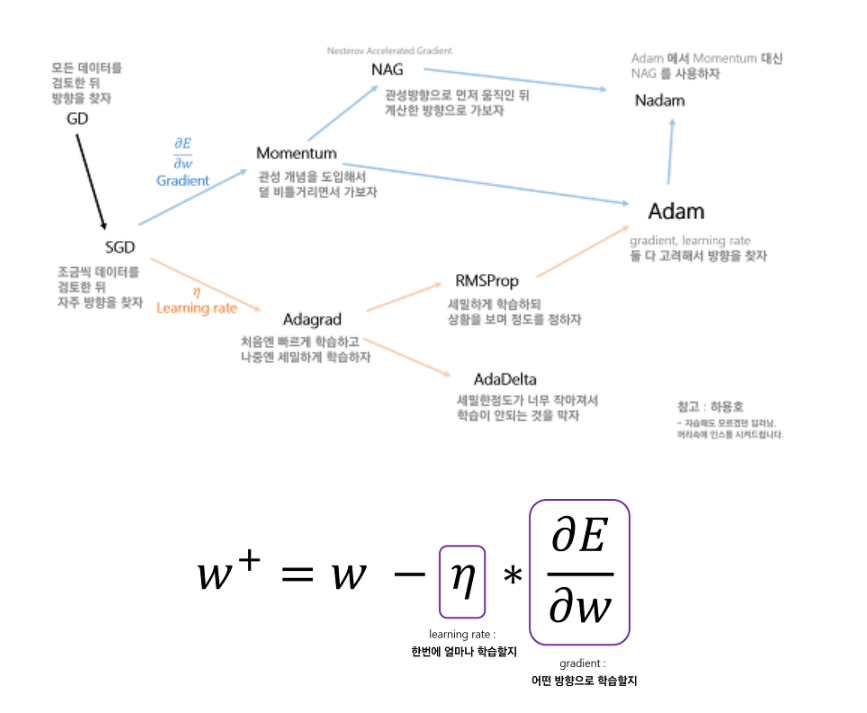
학습 식을 보면 수정할 수 있는 부분이 다음 두 가지이며,
optimizer의 발전 과정은 이 두 가지 중 어떤 것을 개선해나갔는지로 볼 수 있다.
- gradient
- 어떤 방향으로 학습할 것인가?
- Momentum, NAG
- Learning rate
- 한 번에 얼마나 학습할 것인가?
- Adagrad, RMSProp, AdaDelta
- gradient + learning rate
- Adam, Nadam
lr_scheduler
learning rate
https://wikidocs.net/157282
learning rate는 gradient의 보폭을 말한다. learning rate는 성능에 꽤나 영향을 주는 요소(learning rate를 잘못 설정하면 아예 학습이 안되기도 한다.)이기 때문에 learning rate를 어떻게 설정할 지가 중요하다. 아래의 그림이 learning rate 설정에 따라 loss 그래프에서 어떻게 최적의 weight를 찾아나가는 지를 보여준다.
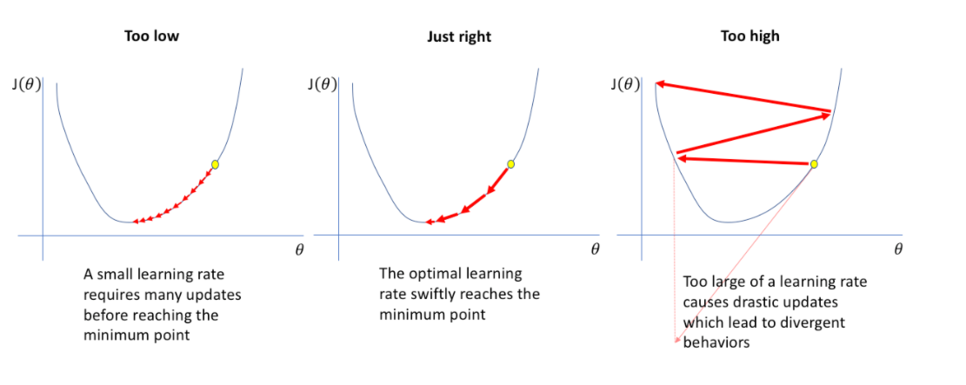
Learning rate schedule는 학습이 진행됨에 따라 epoch 또는 iteration 간에 학습률을 조정하는 사전 정의된 프레임워크다.
- 일정한 Learning rate: 이름에서 알 수 있듯이 학습률을 초기화하고 훈련 중에 변경하지 않습니다.
- Learning rate 감소: 초기 학습률을 선택한 다음 스케줄러에 따라 점차적으로 감소시킵니다.
epoch / batch size / iteration
한 번의 계산으로 최적화를 찾는 것은 불가능에 가까운 일이다.
때문에 머신 러닝에서 optimization(최적화)를 할 때에는 여러 번의 학습을 시켜야 한다.
이 반복되는 작업에서 epoch, batch size, iteration의 개념이 쓰인다.
1 epoch = batch * iteration
Epoch
1Epoch은 전체 데이터 셋으로 한 번 학습을 완료했다는 뜻이다.
cf. 1 iteration: 1회 학습
Batch Size
batch: 보통 mini batch를 이르는 것 같다.
- full batch: 모든 학습데이터
- mini batch: 일부 학습데이터. 각 iteration마다 사용하는 데이터의 크기
예시
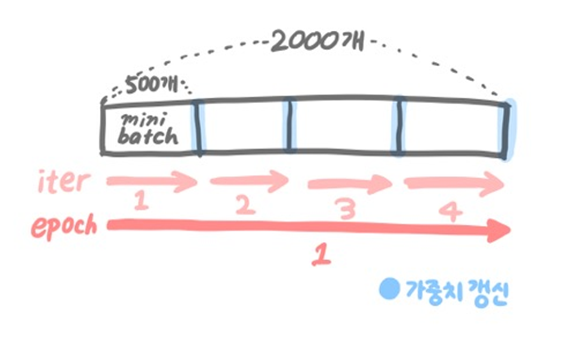
-
전체 데이터: 2000개
-
epochs = 20
-
batch_size = 500
1 epoch = size가 500인 batch * 4번의 iteration,
전체 데이터셋에 대해서 20번의 학습이 이뤄졌고, iteration 기준으로 보면 총 80번의 학습이 이루어졌다.
🤔근데 왜 input data를 batch로 나눠 사용하는 걸까?
그냥 데이터 하나씩 학습시키면 안돼?
그럼 물론 1 iteration을 엄청 빨리 돌 수 있을 것이다.
근데 문제가 있다.
- 데이터 전체의 경향을 놓치기 때문에 iteration 당 loss가 일정하지 않고 헤매게 된다.
어떤 데이터에서는 cost가 적게 들지만 어떤 데이터에서는 엄청 많이 들 수도..? - 엄청난 병렬연산능력 때문에 GPU를 쓰는 건데 데이터를 하나만 학습한다?
이건 닭 잡는 데 소 잡는 칼 쓰는 거나 마찬가지.
그냥 데이터 전체를 한번에 학습시키면 안돼?
그러면 전체 데이터가 반영돼서 최적의 루트로 학습이 될 것이다.
그렇지만 데이터 크기가 크다면 그만큼의 비용이 드는데,
- ⏰ 시간적 비용: 너~~~무 느리다. iteration 다 돌 때까지 모델이 배울 게 너무 많음.
- 💰 메모리 비용: 데이터 뿐 아니라 전처리한 내용이나 layer를 거친 output도 메모리에 오르락 내리락한다. 이 모든 걸 돌리고도 터지지 않는 메모리는 천문학적으로 비싸다.
(사실상 이 비용 때문에 한번에 학습시키고 싶어도 못 시킨다.)
결론: 데이터를 잘게 나눠 쓰면 빠르지만, 목표 지점까지 갈팡질팡 헤매고
크게 쓰면 정확하지만 너무 느려서 적당한 속도와 방향을 채택하기 위해 데이터를 쪼개 batch를 쓴다.
(물론 하드웨어가 허락하는 한 batch 크기를 최대한 크게 잡아서 해야 효율성이 최고😄)
train / valid / test
머신러닝/딥러닝 모델링을 할 때에는 데이터 셋을 나누어 사용하는데,
보통 train : validation : test 셋을 6 : 2 : 2 비율로 나눈다.
(validation/test set은 학습에 이용되는 게 아닌데 비율이 꽤 있네... 데이터 아깝다)
training set (훈련 데이터)
training set은 모델을 학습할 때 사용된다. 학습하는 데에는 training set만 이용한다.
보통 training set으로 hidden layer / hyper parameter에 약간씩 변화를 준 모델들을 서로 다른 epoch으로 학습시킨다.
학습을 할 때 너무 높은 epoch로 학습시키면 overfitting된다.
overfitting (과적합)
학습 모델이 training set에 존재하는 noise까지 학습해 test set에서는 정확도가 낮은 상황
cf. underfitting : 학습 모델이 데이터의 뚜렷한 특징을 찾지 못해 training set에서 cost가 줄어들지 않는 상황
validation set (검정 데이터)
훈련된 모델의 성능을 측정하기 위해 사용되는 데이터 셋.
어떤 모델이 일반적으로 가장 적합한지 찾아내기 위해 다양한 파라미터와 모델을 사용해보게 되며 validation set으로 가장 성능이 좋았던 최종 모델이 선택된다.
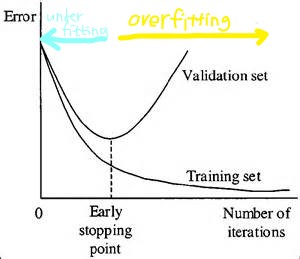
위 그림에서 우측으로 갈수록 epoch를 늘려가며 training set을 학습시킨 과정이다.
적절하게 epoch가 설정된 가운데 부분은 training set 뿐 아니라 측정되지 않았던 데이터에 대해서도 좋은 성능을 보일 것으로 기대된다.
하지만 최우측의 적정치를 초과한 epoch가 설정된 모델을 보면 training set에 overfitting된 모습을 볼 수 있습니다. 너무 높은 epoch로 학습시키면 overfitting으로 모델의 정확도가 낮아지기 때문에 가장 성능이 좋은 모델을 찾는다.
validation set을 사용해 training set에 대한 epoch / hyperparameter / hidden layer를 조정하며 error 곡선을 그린 후 test error가 가장 적게 발생하는 epoch / hyperparameter / hidden layer까지만 모델을 학습시킨다. validation set의 정확도는 '학습에서 overfitting에 빠지지 않고 unseen data에 대해 성능이 좋아야 한다는 것이 핵심적'이기에 중요함.
test set (테스트 데이터)
모델 학습 과정에서는 전혀 입력되지 않고 순수히 최종 성능 평가에만 사용되는 데이터.
이미 validation set은 여러 모델들에 반복적으로 사용되었고 그 중 운 좋게 성능이 실제보다 뛰어난 것으로 측정됐을 수도 있다.
벼락치기하는데 시험 직전에 본 게 나와서 맞은 것처럼..
그래서 이런 오차를 줄이기 위해 test set으로 관찰되지 않은 데이터에 대한 예측 정확도를 짐작한다.
또 validation set은 모델을 평가하기 위해 여러 번 사용할 수 있으나 test set은 한 번만 사용한다.
학습 모델의 궁극적인 목표는 관찰된 적 없는 데이터를 정확하게 예측하는 것
-> 모델의 성능 평가에 사용되는 데이터는 학습에 관여해본 적 없는 데이터여야만 한다.
-> test set은 모델 학습 과정에 관여하면 안됨!
tokenizer
tokenization
텍스트를 여러 개의 token으로 나누는 것.
보통 의미 있는 단위로 token을 정의하며, 나누는 방법에 따라 다양한 tokenizer가 있다.
tokenizer
tokenizer별로 token을 생성하는 방식이 다르기 때문에 어떤 형식의 데이터를 다루냐에 따라 그에 맞는 tokenizer를 이용해야 한다.
예시
- 단어 토큰화
- 문장을 형태소 단위로 나눔
- 문장을 단어 별로 나눔
- 문장을 띄어쓰기(어절) 단위로 나눔
- 문장 토큰화 (ex. kss)
한글에서의 토큰화
- 영어에서의 단어 토큰화와 유사한 형태를 얻으려면 어절 토큰화보다는 형태소 토큰화를 하자
- 영어는 독립적인 단어를 띄어쓰기로 분리 가능
- 한글은 의존 형태소(접사, 어미, 조사, 어간)까지 분리해주어야 한다.
- 분리하지 않으면 '그가', '그에게', '그를', '그와', '그는' 등의 각각 다른 조사가 붙은 '그'라는 목적어를 모두 다른 단어로 인식하게 됨 -> 자연어 처리가 어려워짐
- 예
오늘은 날씨가 정말로 맑았다.- 띄어쓰기 단위 토큰화 => '오늘은', '날씨가', '정말로', '맑았다'
- 형태소 단위 토큰화 => '오늘', '은', '날씨', '가', '정말', '로', '맑', '았', '다'
- 한국어는 영어에 비해 띄어쓰기가 잘 지켜지지 않는다.
- 띄어쓰기가지켜지지않아도쉽게이해할수있다.
- 국어 표준에서도 띄어쓰기 생략이 가능한 부분이 많다.
- 결론적으로 띄어쓰기가 무시되는 부분이 많아 자연어 처리가 어렵다.
품사 태깅
같은 단어라도 품사에 따라 의미가 달라지기도 하므로 단어의 품사가 의미를 파악하는 지표가 되기도 한다.
- 예
- fly
- 명사: 파리
- 동사: 날다
- 안
- 명사: 물체, 공간 가에서 가운데로 향한 쪽
- 관형사: 사물이나 상황에 대한 정보, 지식을 갖추고 있음
- 부사: '아니'의 준말.
- fly
따라서 토큰화를 할 때 각 단어가 어떤 품사로 쓰였는지를 구분해 놓기도 하는데, 이것이 품사 태깅.
대표 패키지: KoNLPy
