Gradient
기계학습에서 모든 변수의 편미분을 벡터로 정리한 것.
기계학습에서 손실 함수(loss function, 예측값과 실제값과 차이 정도로 이해하자)를 경사하강법(gradient descent)을 통해 최솟값을 갖는 지점을 찾는다. 여기서 경사하강법(gradient descent)은 기울기를 이용해서 함수의 최솟값이 어디에 있는지 찾는다.
기울기를 통해서 손실함수의 최솟값이 그쪽에 있는지 보는 것이며 최소한의 방향을 나타낸다. (기울기가 0이라고 반드시 그 지점이 최솟값이라고 할 수 없지만 말이다.)
gradient clipping
gradient exploding을 방지해 학습을 안정적으로 진행하게 한다.
수식: gradient가 일정 threshold(gradient가 가질 수 있는 최대 L2norm)를 넘어가면 clip한다.
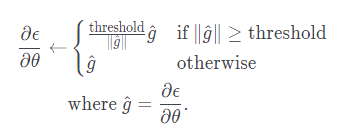
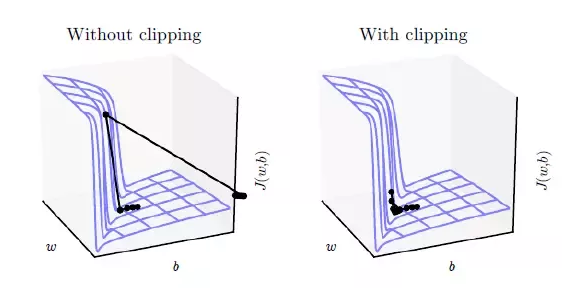
- clipping이 없다면 global mininum에 도달하지 못한 채 엉뚱한 방향으로 튀어버림
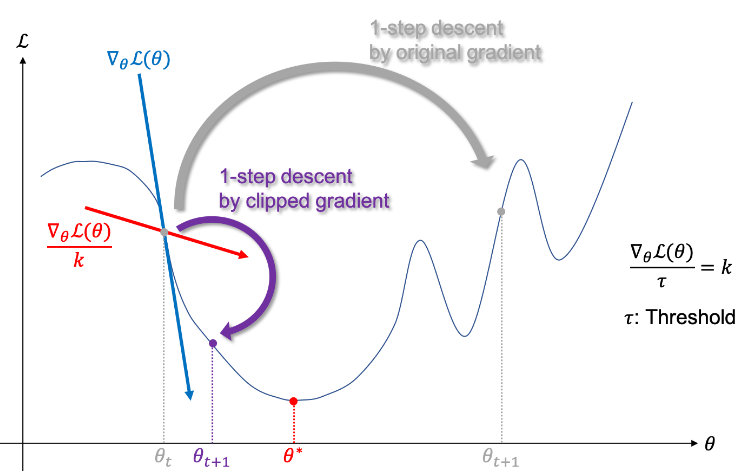
- clipping 적용 시 gradent vector가 방향은 유지하되 조금 이동 -> 안정적
- 기존의 SDG(확률적 경사하강법)가 아닌 Adam 같은 동적인 학습률을 가지는 옵티마이저를 사용할 경우 -> 굳이 gradient clipping을 적용할 필요 X
import torch.optim as optim
import torch.nn.utils as torch_utils
learning_rate = 1.
max_grad_norm = 5.
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# In orther to avoid gradient exploding, we apply gradient clipping.
torch_utils.clip_grad_norm_(model.parameters(),
max_grad_norm
)
# Take a step of gradient descent.
optimizer.step()RNN 계열에서 gradient exploding이나 gradient vanishing이 자주 발생함.
gradient exploding (기울기 폭주)
gradient가 점점 커지더니 가중치들이 비정상적으로 큰 값이 되면서 결국 확 튀어버림
vanish gradient (기울기 소실)
역전파 과정에서 입력층으로 갈 수록 gradient가 점점 작아짐
기울기 폭주와 소실을 완화하는 다른 방법으로는 수렴하지 않는 활성화 함수 사용도 있다.
gradient_accumulation (그래디언트 축적)
단일 GPU로 학습하는 경우 메모리의 제한 때문에 배치 사이즈를 크게 할당할 수 없다.
이 때 이 작은 메모리를 가지고 큰 배치로 모델을 학습시키는 것 같은 효과를 내기 위해 그래디언트 축적을 사용한다.
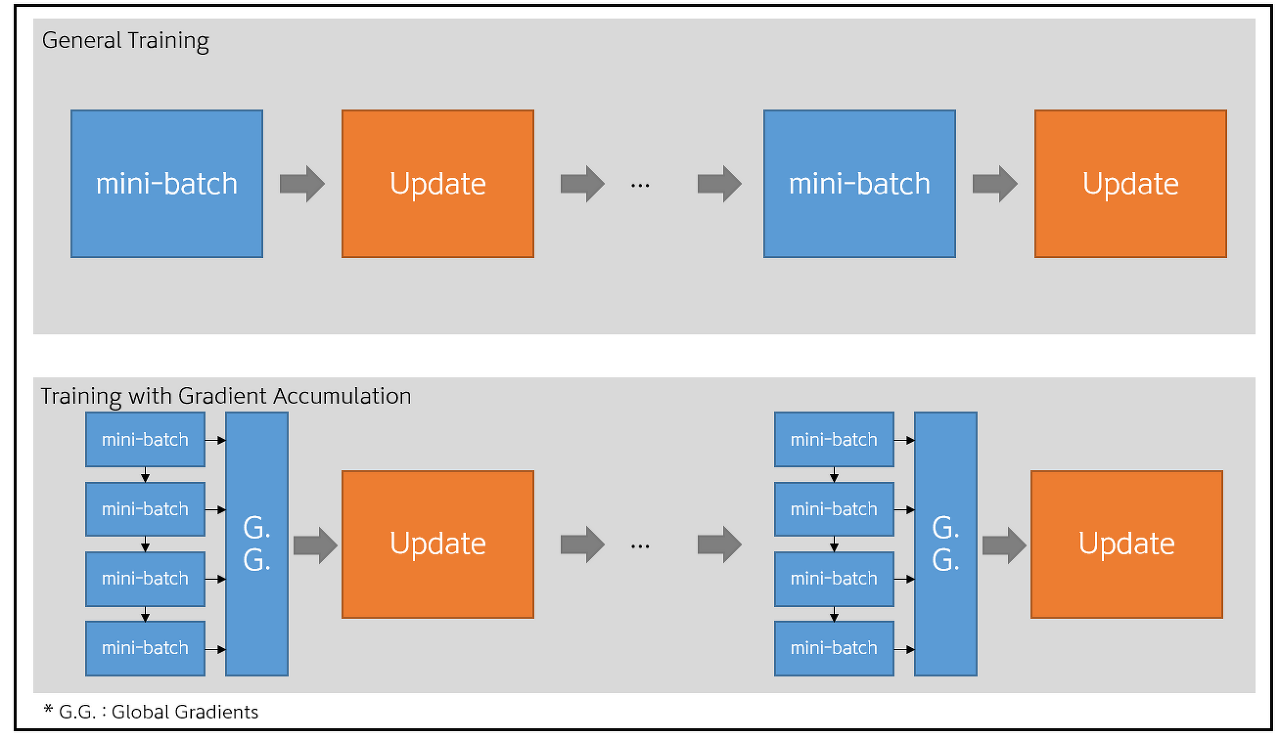
gradient accumulation 시 gradient를 n step동안 global gradients에 누적시킨 후 한 번에 forward/back propagation을 수행한다.
무조건 높은 배치 사이즈가 더 좋은 성능을 내는 것은 아니나 제한된 GPU 사이즈를 가지고 있고 배치 사이즈를 늘리고 싶을 때 시도해볼 만 함.
CrossEntropyLoss
- 손실 함수 종류 중 하나
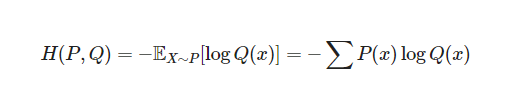
- 입력 데이터의 feature (특성) 값이 모델을 통과하면 출력 층의 softmax에 의해 각 클래스에 속할 확률이 계산됨
https://velog.io/@cha-suyeon/%EC%86%90%EC%8B%A4%ED%95%A8%EC%88%98loss-function-Cross-Entropy-Loss
softmax
- 출력층에서 사용하는 함수
- 다중 클래스 분류 모델을 만들 때 사용
- 결과를 확률로 해석할 수 있도록 변환해주는 함수
https://syj9700.tistory.com/38
