[와인데이터분석] 비지도학습 1차시
- 비지도학습
비지도 학습(unsupervised learning)은 기계 학습의 한 유형으로, 데이터에 대한 명시적인 레이블이나 지도 없이 모델을 훈련하는 방법을 나타냄.
이는 데이터의 구조나 패턴을 발견하거나 데이터를 그룹화하는 데 사용됨
일반적으로 비지도 학습은 군집화(clustering)와 차원 축소(dimensionality reduction)와 관련이 있음
- 군집화(Clustering):
군집화는 비슷한 특성을 가진 데이터를 그룹화하는 작업임. 예를 들어, k-평균 군집화는 데이터를 k개의 그룹으로 나누는 데 사용됨. 군집화 알고리즘을 사용하여 데이터의 패턴이나 그룹을 찾을 수 있음.
<군집화의 평균 코드>
from sklearn.cluster import KMeans
import numpy as np
# 데이터 생성
data = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# k-평균 군집화 모델 생성
kmeans = KMeans(n_clusters=2)
kmeans.fit(data)
# 각 데이터 포인트의 소속 군집 확인
labels = kmeans.labels_
print(labels)- 차원 축소 (Dimensionality Reduction):
차원 축소는 데이터의 특성을 줄이는 작업으로, 주로 주성분 분석(PCA)이나 t-SNE와 같은 기법을 사용. 이를 통해 데이터를 시각화하거나 불필요한 특성을 제거하여 모델의 성능을 향상.
<차원 축소의 평균 코드>
from sklearn.decomposition import PCA
import numpy as np
# 데이터 생성
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# PCA 모델 생성
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
# 차원 축소된 데이터 확인
print(reduced_data)
<와인데이터>
- 데이터 전처리 과정은 뜀
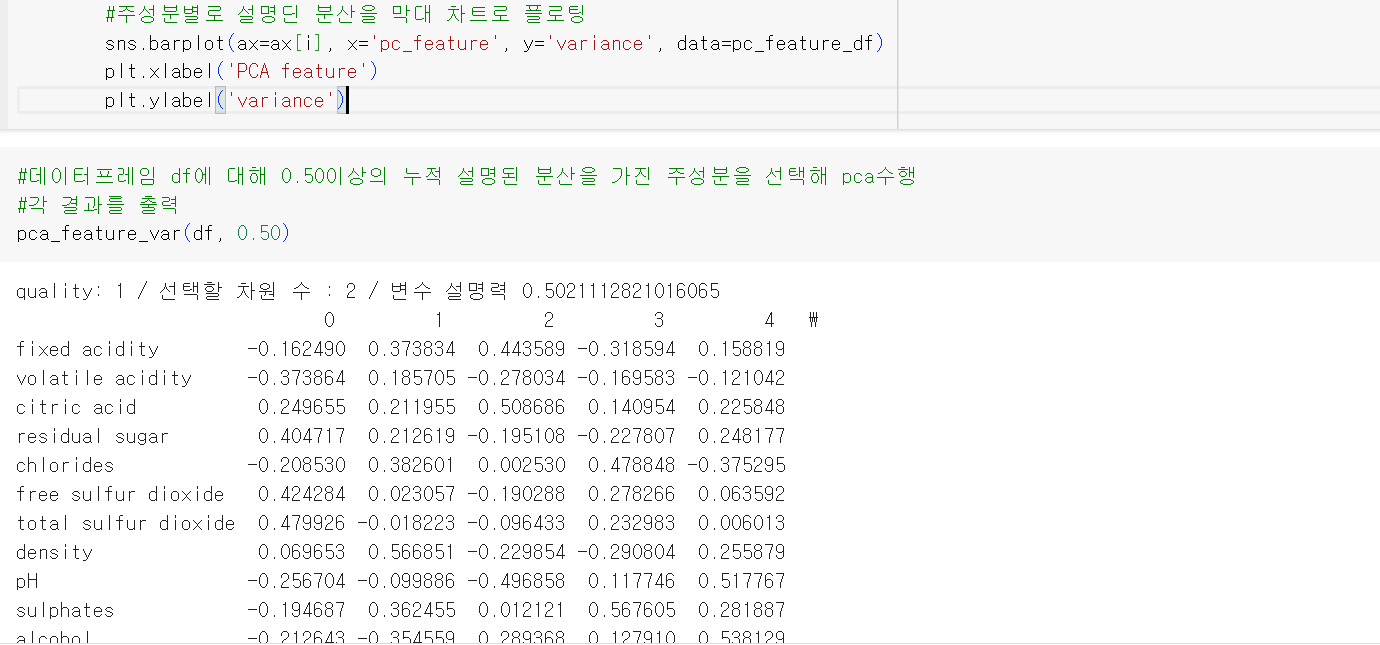
- 차원축소
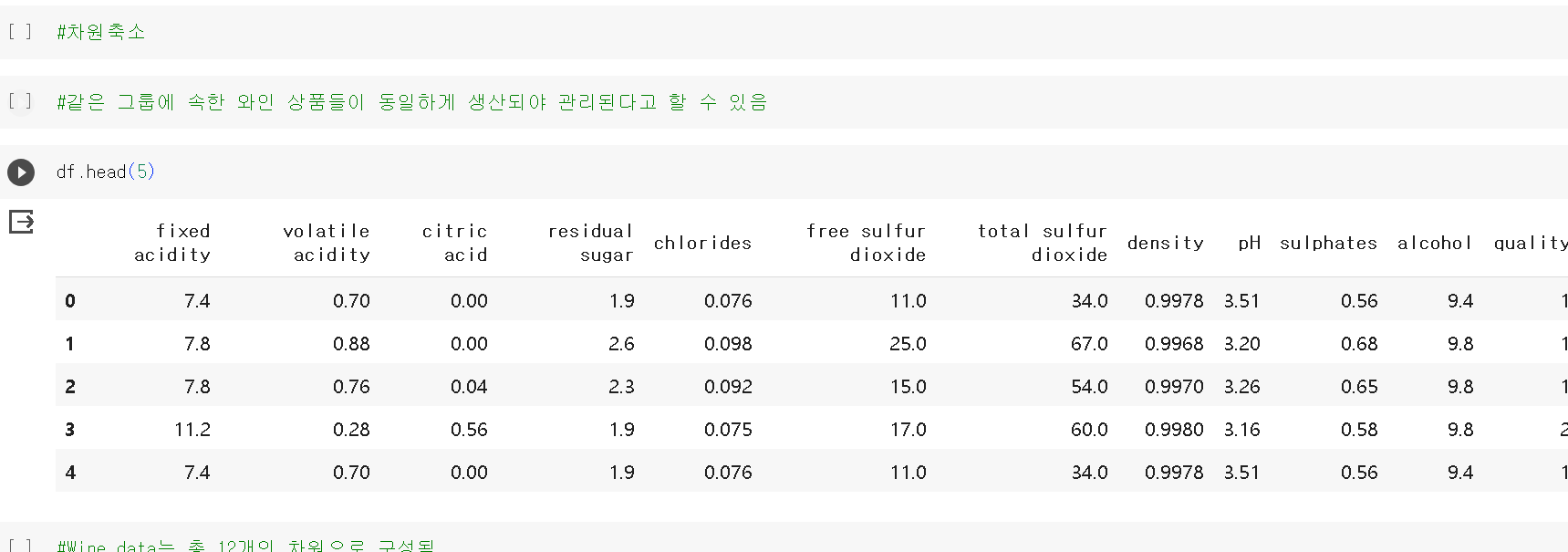
- Wine data는 총 12개의 차원으로 구성됨
- 그래프로 표현할 수 있는 2차원으로 차원을 축소해 평균으로부터 멀어진 제품-> 낮은 품질의 제품으로 판정







- 품질 등급화



- np where if문


- 품질에 따른 공정변수 확인

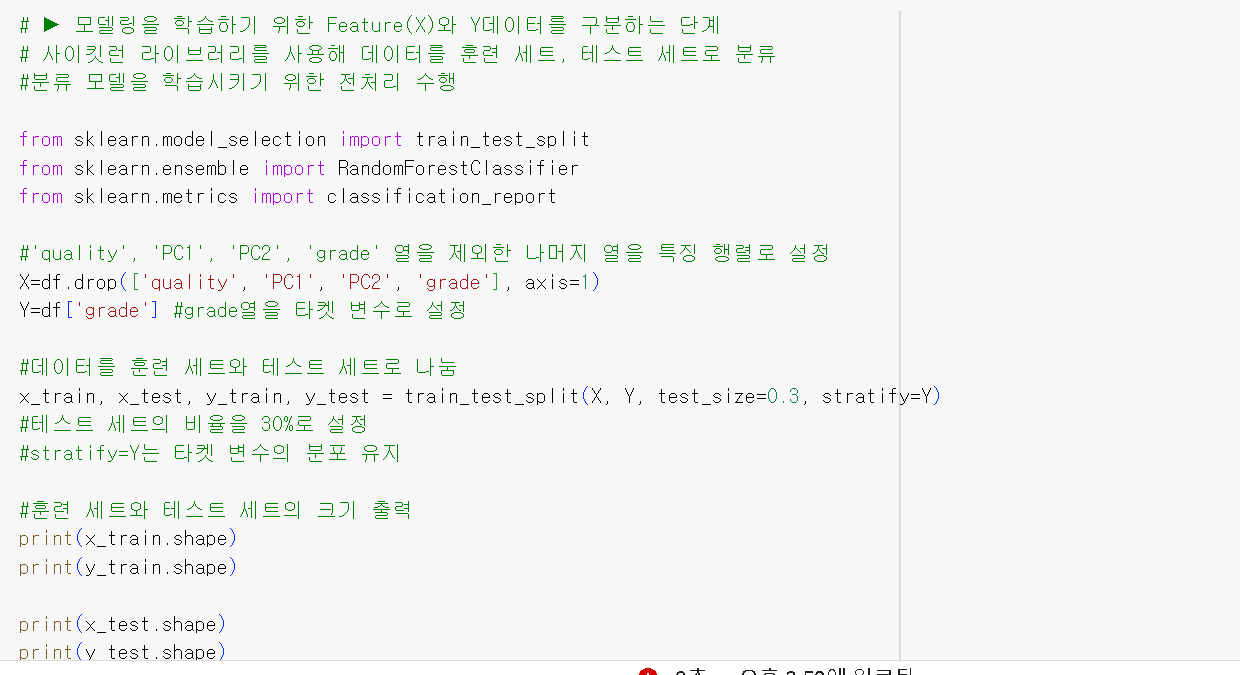


- K-means
: 주성분 분석(PCA)에서 k-means로 변경하려면 먼저 주성분 분석으로 얻은 주성분들을 사용하여 k-means 군집화를 수행
<예제 코드>
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
# 데이터 생성
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 주성분 분석 (PCA)을 사용하여 데이터 차원 축소
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
# k-means 군집화 모델 생성
kmeans = KMeans(n_clusters=2)
kmeans.fit(reduced_data)
# 각 데이터 포인트의 소속 군집 확인
labels = kmeans.labels_
print(labels)-> 그래서 이 코드로 변환해서 적용했는데 실패함, 한번 더 시도해보겠음
<시도한 코드>
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 데이터 준비 (X는 특성 행렬)
X = df.drop(['quality'], axis=1)
# 데이터 표준화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# K-means 클러스터링
kmeans = KMeans(n_clusters=3, random_state=42) # 원하는 클러스터 수로 설정
kmeans_labels = kmeans.fit_predict(X_scaled)
# 클러스터링 결과 시각화를 위한 PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 클러스터별로 색깔을 다르게 표시하여 시각화
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=kmeans_labels, cmap='viridis', edgecolor='k', s=50)
plt.title('K-means 클러스터링 결과 (PCA)')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
안녕하세요. 일로 인해 잠시 쉽니다 :)