Kafka
What is Streaming?
- Streaming은 데이터를 실시간으로 cluster에 publish하는 것을 의미한다.
- web servers에서 나오는 log data
- IoT system에서 나오는 sensor data
- 주식 거래 data ..
- Streaming scenario
- data source로 부터 cluster에 어떻게 publish할지?
- 이렇게 publish된 데이터를 어떻게 활용할지?
- Kafka는 주로 1번문제에 대해서 다룬다.
What is Kafka
- publish/subscribe messaging system
- publisher로 부터의 message를 일정기간 동안 저장한다.
- 이러한 message들은 특정한 topic으로 분류되며 cosumer들은 이러한 topic을 subscribe한다.
- publisher로 부터 message를 받으면 해당 topic을 subscribe하고 있는 consumer에게 보내준다.
- message를 일정기간 저장하기 때문에 consumer가 어떤 이유로 받지 못한 message를 catch up 할 수 있다.
- 같은 stream에 대해 다양한 관점을 가진 multiple consumer를 효율적으로 관리할 수 있다.
- Kafka는 Hadoop만을 위한것이 아니라 범용적으로 사용된다.
Kafka architecture
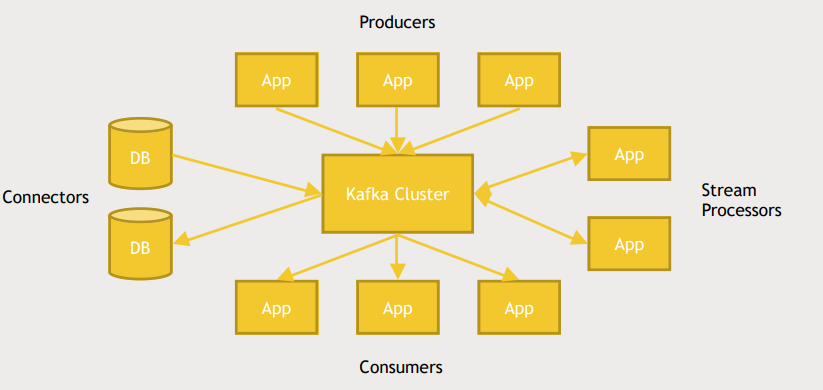
- Producer는 데이터를 생성하고 Kafka cluseter에게 데이터를 전송한다.
- Consumer는 topic을 subscribe해서 Producer가 해당 topic을 publish하면 Kafka의 도움으로 해당 데이터를 받는다.
- Connector를 가지고있어 database를 publisher, subscriber로 모두 활용할 수 있다.
- database에 새로운 row가 추가되면 Kafka에 message를 날린다.
- database가 특정 topic을 subscribe할 수 있다.
- Producer가 publish한 message를 가공하여 republish하는 작업도 가능하다.(stream processor)
How Kafka scales
- Kafka는 multiple processes 에 분산되어 있다.
- Kafka cluster ⊂ multiple servers ⊂ multiple processes
- Stream data또한 multiple servers에 분산되어 저장된다.
- Consumer 또한 분산시킬 수 있다.
- Consumer group이 여러개의 consumer servers로 구성되어 있어 Kafka가 자동으로 messages를 분산하여 Consumer group에게 골고루 뿌려준다.
실습(kafka 실행해보기)
- ambari - Kafka - service actions - start
- kafka topic 생성
- zookeeper가 kafka topic을 추적함
cd /usr/hdp/current/kafka-broker/bin
./kafka-topic.sh --create --zookeeper sandbox.hortonworks.com:2181 --replication-factor 1 --partitions 1 --topic fred
./kafka-topic.sh --list --zookeeper sandbox.hortonworks.com:2181- sample producer를 활용해 topic에 data publish
- topic의 thread에 두 개의 메시지 publish
./kafka-console-producer.sh --broker-list sandbox.hortonworks.com:6667 --topic fred
This is a line of data
I am sending this on the fred topic- 새로운 session을 열어서 consumer 생성
--from-beginning: 이미 발행된 메시지도 받을 수 있음
cd /usr/hdp/current/kafka-broker/bin
./kafka-console-consumer.sh --bootstrap-server sandbox.hortonworks.com:6667 --zookeeper sandbox.hortonworks.com:2181 --topic fred --from-beginning실습 (connector 사용해보기)
- access_log_small.txt 의 변화를 감지
- logout.txt로 저장
- log-test topic publish
- connector의 sample configuration properties 확인
cd /usr/hdp/current/kafka-broker/conf
cp connect-standalone.properties ~/
cp connect-file-sink.properties ~/
cp connect-file-source.properties ~/- configuration file 수정
cd ~
vi connect-standalone.properties
bootstrap.servers=sandbox.hortonworks.com:6667
vi connect-file-source.properties
file=/home/maria_dev/acess_log_small.txt
topics=log-test
vi connect-file-sink.properties
file=/home/maria_dev/logout.txt
topics=log-test- connect-standalone.properties
- standalone connector server를 위한 네트워크 환경 구성
- connect-file-source.properties
- /home/maria_dev/acess_log_small.txt 의 변화를 감지하면 log-test topic publish
- connect-file-sink.properties
- lot-test topic을 subscribe하고 수신한 내용을 /home/maria_dev/logout.txt에 저장
- log file 다운로드
wget http://sundog-soft.com/hadoop/access_log_small.txt- 새로운 session을 열어서 consumer 생성
./kafka-console-consumer.sh --bootstrap-server sandbox.hortonworks.com:6667 --zookeeper sandbox.hortonworks.com:2181 --topic log-test- 다시 원래 session으로 돌아와 connector 실행
cd /usr/hdp/current/kafka-broker/bin/
./connect-standalone.sh ~/connect-standalone.properties ~/connect-file-source.properties ~/connect-file-sink.propertiesFlume
What is Flume?
- Streaming data를 cluster에 적제하는 또 다른 방법
- Hadoop ecosystem의 일부이다.
- Hadoop cluster에 data를 적제하는 것을 제1 목표로 한다.
- HDFS, HBase를 위한 built-in sink가 존재한다.
- 원래는 log aggregation을 위해 만들어 졌다.
Components of an agent
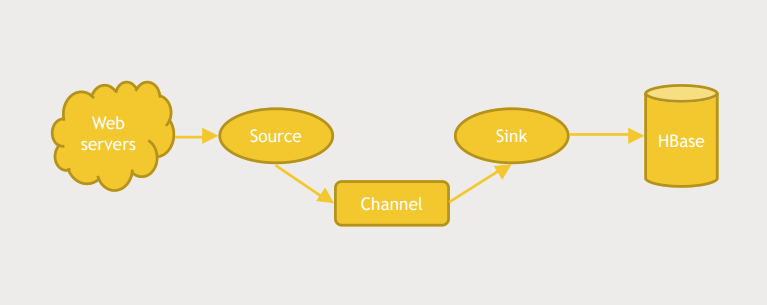
- Flume은 발생하는 data와 저장소 사이에서 완충제 역할을 한다.
- HDFS and HBase don't really like having a million things connected to it at once
- log traffic 은 굉장히 들쑥날쑥하기 때문에 HBase, HDFS에 부담이 될 수 있다.
Source- web server의 log를 저장하는 log directory를 감시하고 변화가 감지되면 channel에게 데이터를 보낸다.
channel selector라는 logic을 통해 데이터의 형태에 따라 데이터를 어떤 channel로 보낼지 결정할 수 있다.interceptor를 통해 data를 reshape하거나 add해서 channel에게 보낼 수 있다.
Channel- Source 에서 받은 데이터를 Sink로 특정 방식으로 전송한다.
- 기본적으로 memory, file 두개의 선택지가 있다.
- memory는 빠르게 전송할 수 있다. 하지만 데이터를 잃을 가능성이 있다.
- file은 느리지만 persistent 한 방법으로 데이터를 전송할 수 있다.
- 대부분의 상황에서 memory 방식이 선호된다.
Sink- 데이터를 어디에 저장할지 결정한다.
- Sink Group에 multiple sinks를 구성할 수 있다.
- Kafka는 data를 유효기간동안 저장하지만 Flume은 Sink가 데이터를 쥐는 순간 data가 삭제된다.
- 그래서 Kafka는 data를 여러곳으로 보내는 것이 쉽다.
- Flume도 가능하지만 약간 까다롭다.
Built-in Source Types
- Spooling directory : UUCP(Unix-to-Unix-Copy)를 위한 작업 요청이나 log file을 저장하는 디렉토리
- Avro : 데이터 직렬화 및 RPC 프레임워크, JSON을 이용하여 데이터 스키마를 정의, 다른 에이전트와 연결할 수 있음
- Kafka
- Exec : Linux에서 실행중인 Command line prompt의 출력과도 연결 가능
- ex) tail -f
- Thrift : 다른 에이전트와 연결할 수 있음
- Netcat : 임의의 TCP 포트에서 스트림되는 데이터 수신에 사용
- HTTP
- Custom : Java를 활용하여
Built-in Sink Types
- HDFS, HBase, Hive
- Avro, Thrift : 다른 에이전트와 연결할 수 있음
- Elasticsearch, Kafka
- Custom
Avro를 통해 Agent간의 연결

- multitiered fan in design
- 이런 architecture는 scalable 함
- Avro는 agent를 연결하는 접착제 역할을 함
- Flume은 완충제 역할을 한다. 하지만 Flume이 모두 차오르게 되면 data source에서 부터 더이상 데이터를 받지 못하는 문제가 생긴다.
- 목적지의 일정 정지기간 동안 각 레이어의 한계를 초과하지 않도록 설계하는 것이 중요하다.
실습 1
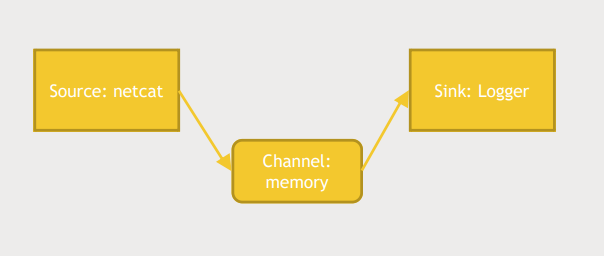
1. config 파일 다운로드
wget media.sundog-soft.com/hadoop/example.conf- agent, source, sink, channel에 대한 설정 정보를 담고있다.
- flume agent 실행
cd /usr/hdp/current/flume-server/
bin/flume-ng agent --conf conf --conf-file ~/example.conf --name a1 -Dflume.root.logger=INFO,consolebin/flume-ng agent: agent 실행--conf: configuration folder를 지정--conf-file: configuration file 위치 지정--name: 어떤 agent를 사용할지 지정Dflume.root.logger=INFO,console: flume에서 발생하는 log를 INFO단위까지 console에 출력
- 다른 shell을 열어서 데이터를 생성
telnet localhost 44444
Hello ~- a1 agent는 source.type이 netcat이며 localhost:44444를 listen중임
실습 2
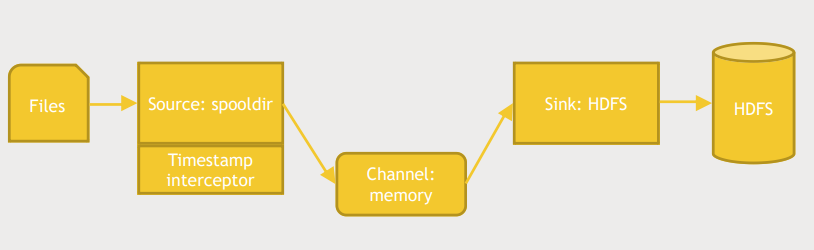
1. config 파일 다운로드
wget media.sundog-soft.com/hadoop/flumelogs.conf- 필요한 dir 생성 및 flume agent 실행
mkdir spool
hadoop fs -mkdir /usr/maria_dev/flume
/usr/hdp/current/flume-server/bin/flume-ng agent --conf conf --conf-file ~/flumelogs.conf --name a1 -Dflume.root.logger=INFO,console- spool에 파일 복사
cp acess_log_small.txt spool/fred.txt
ls spool
fred.txt .COMPLETED.COMPLETED: 작업이 완료되었음을 알림
