Spark Streaming
Why Spark Streaming?
- "Big data" 는 계속 흐르기때문에 realtime 으로 받은 데이터를 realtime으로 처리하는 것도 필요함
- Spark Streaming은 batch processing을 넘어 realtime processing을 수행한다.
Spark Streaming: Hig Level
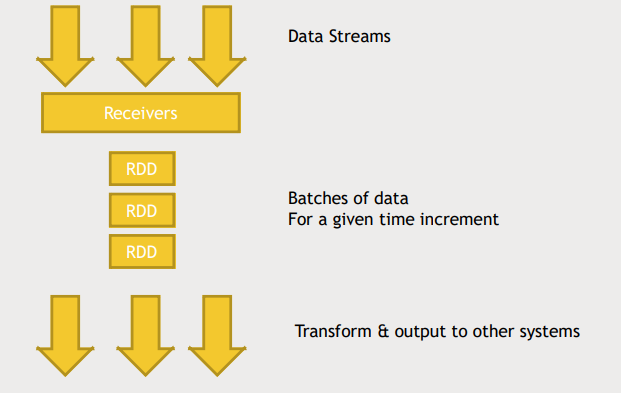
- Data Streams을 Recievers로 받아서 주어진 time increment(보통 1~2초)마다 받은 데이터를 하나의 RDD로 만든다.
- 사실 Spark Streaming은 realtime으로 데이터를 처리하는것이 아니라 micro batch 작업을 수행한다고 보는 것이 맞다.
- 생성된 RDD chunk들을 Spark cluster에서 분산처리하게된다.
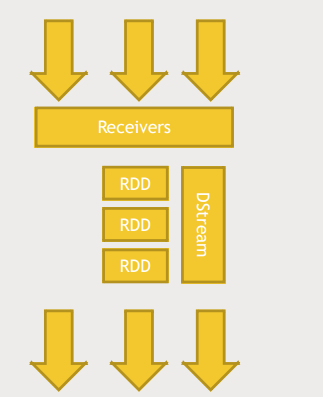
- DStream로 각 batch를 수신하자마자 어떠한 작업을 할 수도 있고 time interval을 설정해 batch를 쌓아뒀다가 작업할 수도 있다.
- Stateless transformation
- 이전 데이터 처리 내역을 유지하지 않는 변환작업
- 이전 데이터를 전혀 고려하지 않고, 현재의 데이터만을 바탕으로 연산을 수행
- Map, Flatmap, Filter, reduceByKey 와 같은 작업이 이에 해당됨
- Stateful transformation
- 이전 데이터 처리 내역을 유지하면서 새로운 데이터를 처리하는 변환 작업
- 상태(state)를 유지하기 위한 저장소를 필요로 하며, 이전 데이터를 저장하고 이후에 들어오는 데이터와 결합하여 처리
- updateStateByKey, reduceByKeyAndWindow 등이 여기에 해당
Windowed transformation
- batch interval보다 더 긴 주기를 가지는 작업
- 관련 용어
- batch interval : Dstream으로 data가 capture되어 들어가는 주기
- slide interval : Windowed transformation이 계산되는 주기
- window interval : Windowed transformation을 적용할 데이터의 범위
- code
ssc = StreamingContext(sc, 1) # batch interval=1s
hashtagCounts = hashtagKeyValues.reduceByKeyAndWindow(lambda x, y: x
+ y, lambda x, y : x - y, 300, 1) # slide interval=1s, window interval=300sStructured Streaming
- Structured data를 streaming처리하는 고급 API
- DataFrame과 Dataset API를 사용
- 스트리밍 데이터를 처리하기 위한 SQL 질의, 조인, 집계, 윈도우 함수 등 다양한 연산을 사용
- RDD, Dstream 대신 표형식의 구조화 데이터를 가진 DataFrame을 가지며 이 테이블에는 지속적으로 새 행이 추가된다.
- dataset API를 쓰기 때문에 Streaming 처리를 위한 코드와 Batch 처리를 위한 코드가 별반 다르지 않다.
- dataset API를 사용함으로써 perforamnce 측면에서 이점이 있다.
- structured streaming의 코드 예시
val inputDF = spark.readStream.json("s3://logs")
inputDF.groupBy($"action", window($"time", "1 hour")).count()
.writeStream.format("jdbc").start("jdbc:mysql//...")실습 Log-Flume-SparkStreaming
- Flume config, python code 다운로드
wget media.sundog-soft.com/hadoop/sparkstreamingflume.conf
wget media.sundog-soft.com/hadoop/SparkFlume.py- Spark python 코드 실행
mkdir checkpoint
export SPARK_MAJOR_VERSIOn=2
spark-submit --packages org.apahce.spark:spark-streaming-flume_2.11:2.0.0 SparkFlume.py- Flume 실행
/usr/hdp/current/flume-server/bin/flume-ng agent --conf conf --conf-file ~/sparkstreamingflume.conf --name a14.spool directory에 log file 복사
wget media.sundog-soft.com/hadoop/access_log.txt
cp access_log.txt spool/log22.txtStorm
What is Storm?
- cluster에서 지속적으로 stream data를 처리하는 framework
- spark와 마찬가지로 YARN위에서 동작할 수 있다.
- micro-batch로 동작하지 않고 개별 event에 의해 동작함
- SparkStreaming의 동작 최소 주기는 1초
- 만약 초단위보다 작은 latency를 원한다면 Storm이 적절
Strom terminology
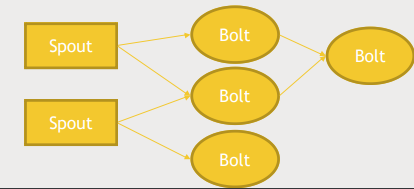
- Stream은 tuple의 형태를 가짐
- Spout : stream data의 source (Kafka, Twitter, DB, TCP...)
- Bolt
- Spout에서 가져온 데이터를 실제로 처리하는 곳
- 데이터를 받으면 즉시 처리
- 데이터베이스, HDFS..에 작성하는 역할도 함
- Spark의 DAG는 자동으로 최적화 경로를 찾아주지만 Storm에서는 스스로 구성해야함
- Storm은 대부분의 상황에서 JAVA로 작성됨
- Bolt는 모든 언어와 호환되지만 이마저도 보통 JAVA로 작성됨
- Storm Core
- Storm을 위한 저수준의 API
- 작업을 분산하고 잘 실행되는지 확인
- 'At-least-once' 시멘틱을 제공. 즉 적어도 한번은 처리되는 것을 보장
- Trident
- Storm Core위에서 동작하는 고수준 API
- 'Exactly once' 시멘틱을 제공
- micro batch를 사용
- Storm을 실행하면 스크립트가 작업을 완료해도 끝난 것이 아니고 사용자가 명시적으로 멈추라고 할 때 까지 작동
- Storm + Kafka 조합이 자주 사용됨
Strom architecture
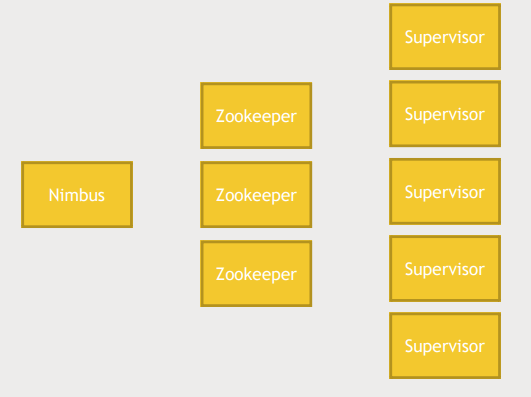
- Nibus
- JobTracker 역할
- 뭐가 어디서 돌아가는지 기록
- Single point failure이지만 다운되더라도 잃어버리는 것 없이 빨리 살려낼 수 있음
- Nibus 서버 백업을 두어 High availability를 가질 수 있음
- Zookeeper : 모든 서버는 zookeeper를 통해 관리됨
- Supervisor
- Storm의 작업이 어디서 일어나는지 추적
- Worker, work process를 실행하는 주체
SparkStreaming vs Storm
- Spark의 다른 기능을 사용한다면 SparkStreaming
- event별로 처리되며 1초 미만의 latency가 요구되면 Storm
- tumbling window : sliding interval=window interval Storm Core
- sliding window : sliding interval!=window interval SparkStreaming
- Storm → SparkStreaming으로 넘어가는 추세
실습
- ambari-storm/kafka-service action-start
- WordCountTopology 실행(Storm에서 제공하는 sample java code)
cd /usr/hdp/current/storm-client/contrib/sotrm-starter/src/jvm/org/apahce/storm/starter/
storm jar /usr/hdp/current/storm-client/contrib/sotrm-starter/storm-starter-topologies-*.jar ort.apache.storm.starter.WordCountTopology wordcount- Storm UI(127.0.0.1:8744) 로 접속
- 결과 확인
cd /usr/hdp/current/storm-client/logs/workers-artifacts/wordcount~/port
tail -f worker.logFlink
What is Flink
- Flink는 빠르고 영리하다는 독일어
- Flink는 Storm과 유사하게 event기반 작업을 한다.
- YARN, Mesos 위에서 동작할 수도 있고 Standalone도 가능
- Highly scalable(1,000여개의 노드까지 확장할 수 있음)
- Fault-tolerant
- 'state snapshots'을 사용하여 failure가 일어나도 exactly-once processing 보장
- 금융 거래 등을 다룰때 굉장히 유용
Flink vs SparkStreaming vs Storm
- 처리량 관점에서 Flink > Storm
- Flink는 Storm Core API 처럼 이벤트별 실시간 스트리밍을 제공
- Flink는 Trident나 Spark같은 고수준 API를 제공하지만 그 와중에도 실시간 스트리밍을 할 수 있음
- Flink에서의 프로그래밍은 Spark Streaming과 굉장히 유사합니다
- Flink는 Scala를 잘 지원, park 코딩을 할 줄 안다면 Flink도 쉽게 배울 수 있음
- Flink는 Spark처럼 스스로의 생태계를 갖고 있다.
- FlinkML : MLlib
- Gelly : Graphx
- Table : SparkSQL
- Flink는 데이터를 받은 순간이 아닌 이벤트 시간을 기준으로 데이터를 처리할 수 있다
- 그 외의 고려해야하는 사항
- 스트리밍 솔루션에 어떤 커넥터를 갖고 있는지
- 기존의 스트리밍 데이터 소스와 어떻게 교류하는지
- 데이터를 어디에 저장할 것인지 등을 고려합니다
Flink architecture
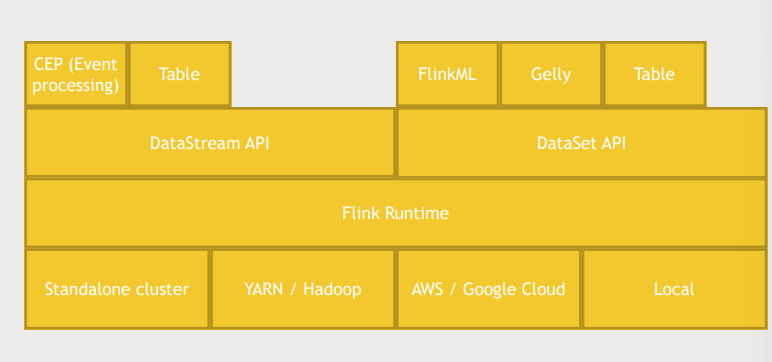
- Standalone : Spark 처럼 Flink 자체는 runtime engine이라서 독립적으로 클러스터에
- YARN, AWS/GCP, local.. 에서 실행할 수 있다.
- DataStream API
- CEP(Event proccesing)을 사용해 이벤트를 처리
- Table로 데이터에 SQL과 유사한 쿼리를 날릴 수 있다.
- Dataset API
- stream data외에도 batch data도 처리할 수 있다.
- FlinkML : MLlib
- Gelly : Graphx
- Table : SparkSQL
- Connectors
- HDFS, Cassandra, Kafka..
실습
- flink.apache.org - download 링크 복사
wget https://dlcdn.apache.org/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
tar -xvf flink-1.17.0-bin-scala_2.12.tgz- configuration 설정 및 실행
cd flink-1.17.0/conf
vi flink-conf.yaml
jobmanager.web.port: 8082
cd ..
./bin/start-local.sh- Flink UI(127.0.0.1:8082) 접속
- 새로운 shell에 netcat : TCP 포트로 데이터를 복사
netcat -l 9000- flink 실행
./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000- netcat으로 메시지를 입력
- log 파일 확인 및 종료
cat log/flink-maria_dev-job~
./bin/stop-local.sh