Query Engines
Apache Drill
What is Apache Drill?
- 다양한 source로부터 SQL query를 실행할 수 있게 해주는 query engine
- MongoDB, HDFS, S3, GCP, Azure Storage, Hive, HBase 등의 RDB가 아닌, shcema가 없는 source에 대해서도 SQL query가 가능
- 심지어 flat JSON format, Parquet file 도 가능
- 그리고 이 모든 것을 Single SQL query engine을 통해 통합적으로 접근가능
- 이러한 복잡한 일을 reliable하고 효율적으로 처리함
- 2000년대 구글이 발표한 Dremel을 기초로 개발되었고 그 후에도 계속 발전을 거듭해서 Dremel과는 다른 현재의 모습을 가지고 있다.
- 다른 tool(ex Tableau)들과 JDBC/ODBC driver를 통해 연결할 수 있다. 그리고 연결된 tool들은 마치 RDB에 접근하듯이 여러 source들을 사용할 수 있다.
- 하지만 결국 Non-relational db로부터 긁어오는 것이기 때문에 big data로 big join을 효율적으로 처리하지는 못함
- Drill의 최대 장점은 다양한 source로부터의 데이터를 transform, load를 먼저 하지 않아도 SQL anlaysis가 가능하게 해준다는 것이다.
- 내부적으로는 loosely structured JSON-like format 을 사용한다.
- 1.1.9.0 버전부터 Storage plugin for Cassandra 지원
실습
- Hive, MongoDB에 데이터를 Load
- Apache Drill을 설치
- Apache Drill 실행
bin/driibit.sh start --Drill.exec.http.port=8765
- 127.0.0.1:8765에 접속해서 Hive, MongoDB Storage를 Update
- Query에 들어가서 query를 실행
- bin/driibit.sh stop
Apache Phoenix
What is Apache Phoenix?
- HBase 만을 위한 SQL driver
- Transaction을 지원
- HBase에 대해서 highly optimized 되어 있어서 매우 빠르고 latency가 낮아서 OLTP application에 적합하다.
- 높은 transaction rate, 빠른 응답 속도를 요구하는 거대한 웹 application과 같은 곳에 query가 충분히 단순할 경우 적합하다.
- 하지만 HBase는 NoSQL이기때문에 거대한 join을 그리 효율적으로 처리하지는 못함
- Phoenix의 주 목적은 HBase에 SQL query를 날리기 위해서이지만 HBase위에 하나의 layer를 더 둔것임에도 불구하고 더 빠르다.
- index된 것에 대한 query는 매우 빠르게 처리한다. 어떤 경우에는 native HBase connector를 사용하는 것보다 훨씬 빠를 것이다.
- Salesforce.com에 의해 개발되었고 open source화 되었다. 지금은 Apache project의 일부임
- HBase로의 JDBC connector를 expose해 이미 JDBC interface를 사용하는 application이나 Tableau에 큰 힘을 들이지 않고도 연결가능
- Secondary index와 UDF를 지원하여 더 복잡한 작업을 가능하게함
- integration jar 파일을 가지고 있어 MapReduce, Spark, Hive, Pig, Flume 등과 연결할 수 있다
- Phoenix를 통해 복잡한 query를 수행하는 것 보다 새로운 HBase table을 만드는 것이 더 좋은 방법인지 고민해볼 필요가 있다.
Phoenix architecture
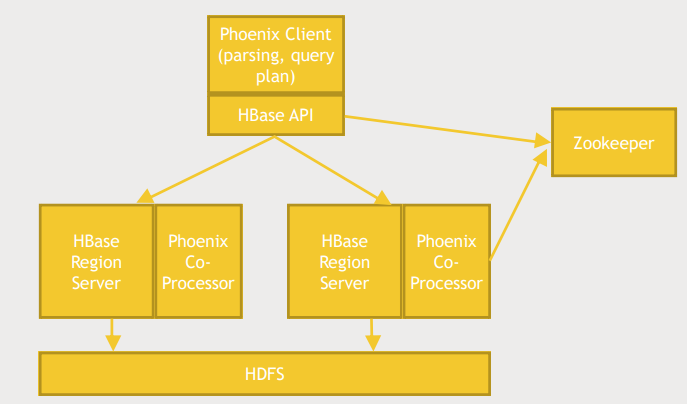
- Phoenix client는 HBase API위에서 돌거나 database driver안에서 돈다.
- HBase region server에는 Phoenix co-processor가 설치되어 Phoenix가 원하는 일을 할 수 있게 도와준다.
- HBase server, client에 모두 관여하며 Zookeeper를 통해 어떤 region server가 사용가능한지 추적한다.
Using Phoenix
- CLI
- Phoenix API for JAVA
- JDBC Driver
- Phoenix Query Server
- JDBC의 업무 부담을 Phoenix query server로 일부 넘길 수 있다.
- 잠재적으로 Phoenix client의 일을 분담하는 여러개의 phoenix query server를 가질 수 있음
- 하지만 궁극적인 목표는 non-Java based application도 Phoenix와 직접적으로 소통할 수 있게 해주는 것이다.
- MapReduce, Hive, Pig, Flume, Spark를 위한 jar 파일을 제공
실습(CLI)
- phoenix 실행
$ cd /usr/hdp/current/phoenix-client/bin
$ python sqlline.py
- 명령어 실행
jdbc:phoenix:> !tables
jdbc:phoenix:> CREATE TABLE IF NOT EXISTS us_population (
. . . . . . .> state CHAR(2) NOT NULL,
. . . . . . .> city VARCHAR NOT NULL,
. . . . . . .> population BIGINT
. . . . . . .> CONSTRAINT my_pk PRIMARY KEY (state,city));
# Phoenix엔 INSERT가 없음
jdbc:phoenix:> UPSERT INTO us_popluation VALUES ('NY','New York',8143197);
jdbc:phoenix:> UPSERT INTO us_popluation VALUES ('CA','Los Angeles',3744829);
jdbc:phoenix:> SELECT * FROM us_population WHERE state='CA';
jdbc:phoenix:> DROP TABLE us_population;
jdbc:phoenix:> !quit
실습(Pig와 통합하기)
- phoenix를 통해 HBase에 테이블 생성
$ cd /usr/hdp/current/phoenix-client/bin
$ python sqlline.py
jdbc:phoenix:> CREATE TABLE IF NOT EXISTS users (
. . . . . . .> USERID INTEGER NOT NULL,
. . . . . . .> AGE INTEGER,
. . . . . . .> GENDER CHAR(1),
. . . . . . .> OCUPATION VARCHAR,
. . . . . . .> ZIP VARCHAR
. . . . . . .> CONSTRAINT my_pk PRIMARY KEY (USERID));
jdbc:phoenix:> !quit
- pig에서 phoenix 커넥터를 이용해 HBase에 데이터 저장, 불러오기
$ cd /home/maria_dev
$ wget http://media.sundog-soft.com/hadoop/phoenix.pig
$ less phoenix.pig
REGISTER /usr/hdp/current/phoenix-client/phoenix-client.jar # phoenix-client.jar 위치 등록
users = LOAD '/user/maria_dev/ml-100k/u.user'
USING PigStorage('|')
AS (USERID:int, AGE:int, GENDER:chararray, OCCUPATION:chararray, ZIP:chararray);
STORE users into 'hbase://users' using
org.apache.phoenix.pig.PhoenixHBaseStorage('localhost','-batchSize 5000');
# PhoenixHBaseStorage 커넥터를 사용하여 hbase의 user 테이블에 저장
# -batchsize 5000 5000개를 모았다가 한번에 저장하겠다. (default 1000)
occupations = load 'hbase://table/users/USERID,OCCUPATION' using org.apache.phoenix.pig.PhoenixHBaseLoader('localhost');
grpd = GROUP occupations BY OCCUPATION;
cnt = FOREACH grpd GENERATE group AS OCCUPATION,COUNT(occupations);
DUMP cnt;
$ pig phoenix.pig
- table drop
$ cd /usr/hdp/current/phoenix-client/bin
$ python sqlline.py
jdbc:phoenix:> DROP TABLE users;
jdbc:phoenix:> !quit
Presto
What is Presto
- Drill과 유사하게 다양한 source에 대한 SQL query를 지원함
- OLAP에 최적화 되어 있음(analytical queries, data warehouse)
- 복잡한 쿼리를 효율적으로 수행하며 복잡한 쿼리인만큼 초단위의 시간이 걸림
- Facebook에 의해 개발었고 지속적으로 관리되고 있음
- 0.146부터 MongoDB connector 지원
- JDBC driver, CLI 심지어 Tableau interfaces를 위한 connector도 존재
- 대용량 데이터에대한 신속한 분석/처리를 지원함
- Facebook에서는 다양한 data sotre에 저장된 300PB의 데이터에대해 1000여명의 직원들이 30,000 queries를 매일 날린다. 그만큼 대용량 데이터 처리에 특화됨
- multiple sources에 통합적으로 분석용 쿼리를 날릴 수 있다.
- presto는 in-memory기반이라 데이터 처리에 특화됨
What can Presto connect to?
- Cassandra
- Hive
- MongoDB
- MySQL
- Local files
- Kafka(streaming data application), JMX, Postgresql, Redis, Accumulo...
실습(presto 설치 및 CLI 환경에서 사용해보기)
- Presto 설치
- 현업에서는 홈디렉토리가 아니라 많은 사람들이 사용할 수 있는 위치에 설치
- Prestodb.io - Docs - installation - Deploying Presto - presto-server-0.280.tar.gz 링크 복사
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.280/presto-server-0.280.tar.gz
$ tar -xvf presto-server-0.280.tar.gz
$ cd presto-server-0.280
- Presto는 configuration을 제공하지 않음
- etc 디렉토리에 있어야하는 여러 configuration file을 직접 생성해야함
- 어떤 서버와 데이터베이스를 사용하고 어떤 포트에서 실행하는지에 따라 모든 것이 바뀌기 때문에
- 공식 문서에 자세히 설명되어 있음
- 강의에서 제공하는 configuration file 설치
$ wget http://media.sundog-soft.com/hadoop/presto-hdp-config.tgz
$ tar -xvf presto-hdp-config.tgz
$ ls etc
catalog config.properties jvm.config log.properties node.properties
- config.properties : port 지정
- jvm.config : garbage collection과 java parameter를 담고있다.
- log.properties : log level을 지정
- node.properties : node.id(unique identifier of machine in cluster)
- catalog/hive.properties : 우리가 사용할 hive connector
- catalog/jmx.properties
- cli 설치
- Prestodb.io - Docs - installation - CLI - presto-cli-0.280-executable.jar 링크 복사
$ cd /home/maria_dev/presto/presto-server-0.280/bin
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.280/presto-cli-0.280-executable.jar
$ mv presto-cli-0.280-executable.jar presto
$ chmod +x presto
- presto server run
$ cd ..
$ bin/lancher start
- localhost:8090 (Web dashboard)
- cli로 sql 실행해보기
$ bin/presto --server 127.0.0.1:8090 --catalog hive
presto> show tables from default;
presto> select * from default.ratings limit 10;
presto> select * from default.ratings where rating = 5 limit 10;
presto> select count(*) from default.ratings where rating = 1 limit 10;
presto> quit
$ bin/lancher stop
실습(Cassandra, Hive 통합)
- cassandra 실행 및 thrift 서비스 활성화
$ scl enable python27 bash
$ service cassandra start
$ nodetooll enabletrift # nodetool : cassandra utility
- cqlsh 실행
$ cqlsh --cqlversion="3.4.0"
cqlsh> describe keysapces;
cqlsh> use movielens;
cqlsh:movielens> describe tables;
cqlsh:movielens> select * from users limit 10;
cqlsh:movielens> quit
- cassandra properties 구성하기
$ cd /home/maria_dev/presto/presto-server-0.280/etc/catalog
$ cat >cassandra.properties
connector.name=cassandra
cassandra.contect-points=127.0.0.1
ctrl+d
- 실제 cassandra database였다면 서버가 다운될 경우를 대비해 잠재적으로 연결할 수 있는 서버의 목록을 지정해야함
- presto 실행 및 cli 환경에서 query 날려보기
$ cd ../..
$ bin/lancher start
$ bin/presto --server 127.0.0.1:8090 --catalog hive,cassandra
presto> show tables from cassandra.movielens;
presto> describe cassandra.movielens.users;
presto> select * from cassandra.movielens.users limit 10;
presto> select * from hive.default.ratings limit 10;
presto> select u.occupation, count(*) cnt from hive.default.ratings r join cassandra.movielens.users u on r.user_id=u.user_id group by u.occupation;
presto> quit
$ bin/launcher stop
$ service cassandra stop
- cli는 presto에 연결하는 하나의 방법일 뿐이다.
