NoSQL
What is NoSQL
- NoSQL(Not Only SQL)은 Non-relational DB
- SQL과 같은 풍부한 질의언어를 포기하는 대신 대규모의 질의를 빠르게 처리할 수 있다.
- 수평적으로 무한히 확장가능, 빠르고 회복탄력성이 뛰어나다.
- HBase
- HDFS 위에서 동작함
- 굉장히 빠르고 확장성있는 transactional system
- 대규모 데이터에 대한 간단한 쿼리가 요구되는 상황이라면 → NoSQL
- for a given key or put information into a given key → NoSQL(key-value data stores)
SQL(RDB)을 극한까지 확장하기
- Denormalization
- JOIN의 overhead를 줄여 latency를 줄일 수 있다.
- in-memory caching layers
- RDB위에 거대한 caching layers(eg. memcached)를 두어 DB접근 트래픽을 차단
- DB와 cache사이에 동기화되지 않는 문제가 발생할 수 있다.
- Master / slave setups
- 여러개의 데이터베이스를 두어 하나에게
쓰기권한을 주고 나머지는 그 데이터를 복제해서읽기를 담당
- 여러개의 데이터베이스를 두어 하나에게
- Sharding
- 하나의 데이터베이스를 나눠서 특정 데이터베이스는 특정 범위의 키만 다루게 하는 방법
- 새로운 shard를 추가할때 번거로울 수 있다.
- Materialized views(CTAS)
- RDB는 대규모 데이터에 대한 대규모 transaction을 처리하기에 적절치 않다.
Sample architecture
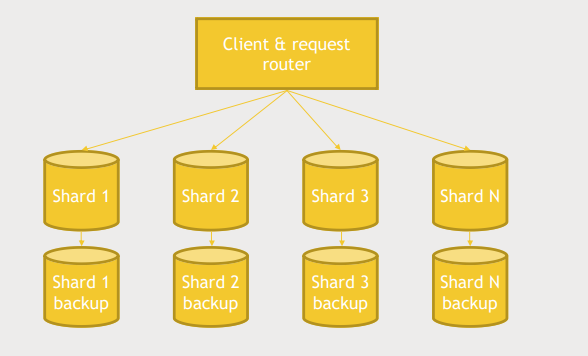
- customer를 나눠놓은 multiple shards가 있을때 client가 주어지면 hash함수를 통해 어떤 shard에 원하는 정보가 있을지 쉽게 찾을 수 있다.
- shard를 추가함으로서 확장할 수 있다.
- 이 방법은 확장성 있고 간단한 방법이다.
- 항상 문제를 해결하는 방법은 간단할 수록 좋다. 복잡한 방법은 고장이날 확률이 높다.
Use the right tool for the job
- 대규모 데이터에 대한 분석 쿼리로는 Hive, Pig, Spark가 좋다.
- MySQL만으로도 상당한 규모의 데이터를 처리할 수 있다. 만약 application이 감당해야할 최대 크기가 MySQL만으로 가능하다면 MySQL을 쓰는 것이 좋다.
- 하지만 그 이상이 된다면 NoSQL고려 해봐야한다.
HBase
What is HBase?
- HDFS 위에서 동작하는 scalable한 NoSQL
- 대량의 데이터를 바깥으로 노출시킬 수 있음
- 요청에 빠르게 답을 줄 수 있는 API가 존재,
- Google's BigTable database의 idea를 재구성한 것
- no query language, only CRUD API's
- HBase의 핵심은 large scale을 빠르게 처리
HBase architecture
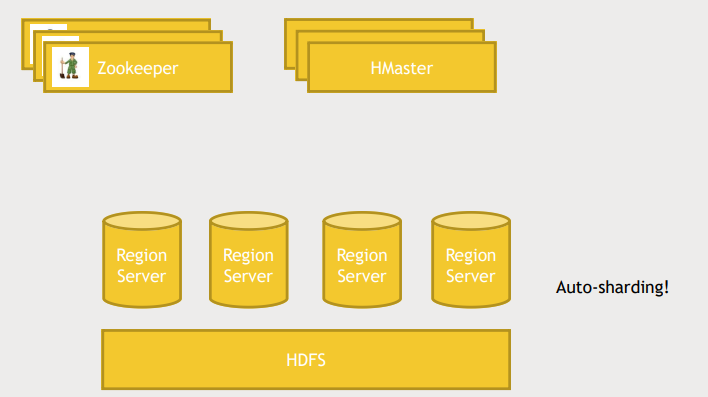
- ranges of keys를 기준으로 "region servers" 로 나뉨(기존의 DB의 sharding, range partitioning과 유사)
- data가 많아지면 자동으로 repartitioning함
- application이 HBase와 소통할때 master node를 거치지 않고 region servers와 직접 소통함
- master server는 데이터의 schema를 추적한다.(데이터가 어떻게 partition되있고 어디 있는지)
- Zookeeper의 도움으로 High availablility를 가질 수 있다. master server의 상태를 체크하고 다운되면 다음 master server를 작동시키고 모두에게 master server가 변경되었음을 알린다.
- data 자체는 HDFS의 big file에 저장됨
HBase data model
- ROW는 unique key로 식별된다.
- 각 ROW는 column families를 가짐
- column families 는 column들을 가지고 이로인해 sparse data가 됨
- HBase modeling을 할때 생각해야하는 것은 어떻게 하면 column families를 최소화할지
- row 와 column의 intersection을 cell이라고 한다.
- 하나의 cell에는 여러개의 version의 값을 가질 수 있으며 cell내에서 version들은 timestamp에 의해 정렬된다.
Some ways to access HBase
- HBase shell
- HBase가 작동하는 서버에 접속해서 "HBase shell"를 입력하면 HBase와 command로 상호작용할 수 있음
- Java API
- HBase는 Java로 작성되어서 Java-based 웹 서버나 어플리케이션은 바로 access 가능
- 다른 언어도 접근할 수 있게 해주는 wrapper도 있음
- Spark, Hive, Pig
- Spark, Hive, Pig로 복잡한 변형, 특정한 view를 생성하고 HBase에 쏴주는 방식
- REST server
- HBase에는 REST server가 구현되어 있음.
- REST server를 작동시키면 HBase와 RESTful interface로 소통 가능
- protocol buffers
- Thrift by Facebook
- Avro by Hadoop
- binary format을 사용해서 데이터를 더 컴팩트하게 표현할 수 있음
- 따라서 효율적인 저장, 빠른 전송이 가능
- 단점은 client와 server가 강하게 coupling되어 있어 서로의 버전을 알아야하고 동기화에 문제가 생기기 쉬움
- 간단하게 사용하려면 REST, 최대 성능을 원한다면 protocol buffer
Rest server 이용해보기
- Ambari에서 Hbase 켜기
- Hbase의 rest server열기
/usr/hdp/current/hbase-master/bin/hbase-daemon.sh start rest -p 8000 --infoport 8001- infoport를 통해 HBase의 현 상황을 볼 수 있음. 사용하지 않더라도 지정해줘야함
- python으로 HBase의 Rest와 connection을 생성
- connection을 통해 로컬의 데이터를 HBase로 upload
→ Big data 관점에서는 유용하지 않다. 로컬머신이 감당할 수 있는 양의 데이터는 빅데이터가 아니다.
Pig로 HBase에 데이터 저장
-
- HBase Shell을 통해 table 생성
- hbase shell
- list : list tables
- create 'users', 'userinfo' : 첫번째 인자는 table name, 2번째 부터 column family name
-
- Pig로 HDFS의 데이터를 LOAD하고 hbase에 저장
- pig ~.pig
- STORE [LOAD한 데이터] INTO 'hbase://users' USING [pig로 HBase에 매핑해줄 코드] (~) (자세한 내용은 코드)
-
- HBase shell에 접속해서 확인
- scan 'users' : table을 추력해줌
- disable 'users' : drop하기전에 disable먼저
- drop 'users' : table 삭제
-
HBase는 row에 transactional해서 conflict를 걱정할 필요 없음
-
importtsv 라는 스크립를 통해 HDFS의 데이터를 HBase로 바로 가져올 수도 있음
Cassandra
What is Cassandra?
- 분산 NoSQL DB의 한 종류이며 Big table, HBase와 같은 Column Family Storage이다.
- HBase와 유사하게 대용량의 데이터를 다루는 transactional queries에 최적화 되어 있다.
- CQL(Cassandra query language)를 가지고 CQL은 SQL과 매우 유사하다. 하지만 SQL에 비해 할 수 있는일이 제한되어 있다.
- Cassandra, Oracle은 그리스 로마신화에서 미래를 예언하는 서로 다른 인물이다. 몇몇의 application에서 Oracle을 대체할 수 있다는 것을 강조하기 위해서 Cassandra라는 이름을 가짐
- no single point of failure: master node가 없다. 그래서 availability를 가짐
CAP theory
- CAP은 "consistency, availability, and partition tolerance" 를 뜻하며 CAP theory는 데이터베이스 시스템은 이 3개중 최대 2개만 가질수 있다는 이론이다.
- consistency : DB에 새로운 값을 쓰면 어떤일이 있더라도 즉각적으로 그 값을 읽을 수 있어야한다. (ACID의 consistency개념과 약간 다름)
- Availability : 데이터베이스가 reliable하고 항상 동작중이여야한다. 데이터베이스에 대한 복제본을 가지는 디자인이라면 more available하다고 할 수 있다.
- partition tolerance : 데이터베이스가 쉽게 나눠지고 cluster 전반에 분산될 수 있다
- Hadoop cluster는 분산환경을 다루므로 포기할 수 없는 특성, consistency 와 availability 중 하나를 선택해야함
- Cassandra는 consistency를 포기하고 availability를 취함
- 대신 eventually consistent 하다. 쓰기에 대해 즉각적인 읽기는 힘들더라도 1~2초 후에는 전체 cluster에게 변화를 전파해서 원하는 값을 얻을 수 있음
- 또한 tuneable consistency를 제공한다. query에 대해 얼마나 많은 node들의 동의를 얻어야 answer를 얻을 수 있는지 정할 수 있음
- 그래서 consistency와 availability의 tradeoff를 사용자가 조절할 수 있음
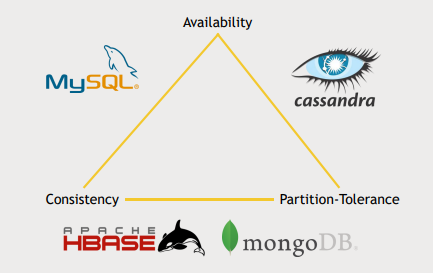
- Cassandra : consistency < availability
- query의 consistency를 조절할 수 있다는 특징
- HBase, MongoDB : consistency > availability
- HBase
- Masternode를 가짐 → consistency
- Masternode의 복제본을 운영하지만 결국 그게 down되거나 Masternode의 상태를 추적하는 Zookeeper가 down되면 availability를 보장 못함
- HBase
Cassandra Architecture
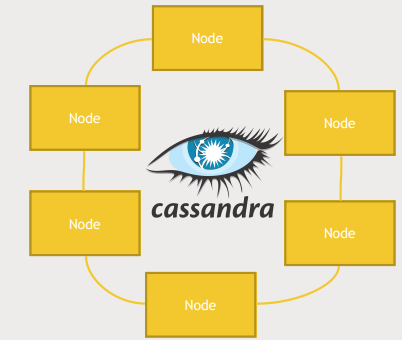
- 어떤 node가 어떤 data를 가지고 있는지 추적하는 master node가 존재하지 않음
- ring architecture : node들은 ring으로 연결되어 있으며 데이터를 분산하여 저장한다.
- 각 노드들은 특정 범위의 primary key를 담당하며 이 범위는 hash 함수에 의해 결정된다.
- 모든 노드들은 gossip protocol을 이용해 서로 통신하여 어떤 노드가 특정 데이터를 책임지며 데이터의 복제본은 어디에 저장되어 있는지 추적한다. 그리고 snitch라는 기술을 활용해 데이터에 빠르게 접근하는 방법을 추적한다. 모두 내부적으로 관리된다.
- 모든 노드들은 같은 software를 가지며 같은 임무를 수행하며 같은 함수를 가진다. 그래서 사용자가 데이터를 찾을때 어떤 노드에 물어보든지 상관없이 답을 얻을 수 있다.
Cassandra 활용
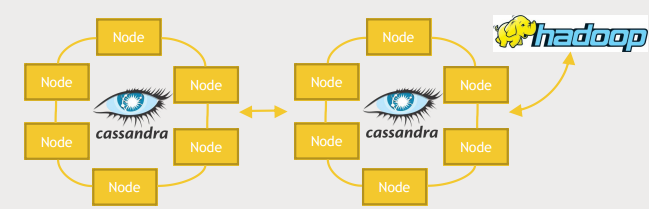
- Cassandra cluster를 복제해서 하나는 웹서버, 웹사이트에서 온라인 쿼리를 다루는 역할을 하고 다른 하나는 Hadoop cluster와 통합해서 Hive, Spark 쿼리를 통한 batch 형식으로 분석하는 역할을 할 수 있다.
- 이렇게 운영하면 서비스에서 제공하는 트랜잭션 시스템의 성능에 영향을 주지않고 대규모 분석을 할 수있다.
CQL
- CQL은 Primary key를 가지고 read, write를 하는 API일 뿐이다.
- JOIN이나 LOOKUP과 같은 기능을 지원하지 않는다.
- 모든 쿼리는 Primary key를 통해서 가능하다.
- seondary index를 지원하지만 최고 성능을 위해서 Primary key가 필요하다.
- CQL은 application으로 하여금 기존의 db driver처럼 보이게해준다.
- Oracle이나 MySQL같은 RDB와 소통하도록 만들어진 application을 가지고 Cassandra로 옮겨올때 constraint만 지켜 쿼리한다면 application을 사용할 수도 있다.
- CQLSH(CQL SHell) : command line을 통해 table을 생성하거나 뭐가 어디 있는지 탐색하는데 사용
- keyspace : MySQL의 Database와 유사
Cassandra and Spark
- Spark는 HBase, MongoDB, Cassandra, MySQL ... 과 잘 어울림
- DataStax에서 Spark-Cassandra connector를 제공해서 Spark를 이용해 Cassandra를 이용할 수 있음, Spark에게 Cassandra가 dataframe처럼 보이게 해줌
- 활용 예
- Cassandra에 저장된 데이터를 분석하는 용도로 Spark사용
- Spark로 data를 transform하고 Cassandra(for transactional use)에 저장
Cassandra 실행해보기
- Hortonworks의 운영체제인 CentOS에서 Python 2.6을 요구하는데 Cassandra는 Python 2.7을 요구함
- SCL-UTILS 를 설치하면 Python version간의 switch가능
yum install scl-utils yum install centos-release-scl-rh yum install python27 scl enable python27 bash
-
DataStax 저장소 정보를 가진 파일을 저장, dsc30 설치
cd /etc/yum.repos.d cat >datastax.repo [datastax] name = DataStax Repo for Apache Cassandra baseurl = http://rpm.datastax.com/community enabled = 1 gpgcheck = 0 cntrl+d yum install dsc30 -
cqlsh 설치 및 cassandra, cqlsh 실행
pip isntall cqlsh service cassandra start cqlsh --cqlversion="3.4.0" -
원하는 특성을 가진 keysapce 만들기고 사용하기
cqlsh> CREATE KEYSPACE movielens WITH replication = {'class': 'SimpleStrategy','replication_factor':'1'} AND durable_writes = true; cqlsh> USE movielens; -
table 만들고 확인하기
cqlsh> CREATE TABLE users (user_id int, age int, gender text, occupation text, zip text, PRIMARY_KEY (user_id)); cqlsh> DESCRIBE TABLE users; cqlsh> SELECT * FROM users; -- PRIMARY KEY가 무조건 포함되야함!!
Cassandra에 Spark로 Write, Read
- Spark 2.0 으로 세팅
export SPARK_MAJOR_VERSION=2 - 작성한 CassandraSpark.py 실행
spark-submit --package datastax:spark-cassandra-connector:2.0.0-M2-s_2.11 CassandraSpark.py - Cassandar stop
service cassandar stop
MongoDB
What is Mongodb
- NoSQL의 한 종류이며 document based storage라서 유연하다.
- MongoDB의 주요 타겟은 Coporate
- consistency와 partition tolerance를 추구함
- big data를 다루기위해 partition tolerance는 필수불가결
- Sigle master(primary node)를 가져서 consistent하고 unavailable함
- 다양한 type의 데이터를 저장할 수 있다.(특히 JSON blob)
- 기본적으로 document들이 같은 스키마를 가질 필요가 없다. 옵션으로 schema를 지정할 수 있지만 데이터베이스에 대한 flexibility와 빠른 look-up을 원한다면 필요하지 않다.
- MongoDB는 각 document를 식별하기위해 자동으로 _id 필드를 생성하고 이것이 일종의 primary key 역할을 한다. 그래서 따로 Mongodb에게 Cassandra의 key와 같은것이 없다.
- 하지만 index는 존재한다. index는 여러필드를 조합하여 생성할 수 있다.
- index는 sharding을 위해 필요하다.
- flexibility 에는 great responsibility가 따른다.
- 어떤 query를 주로 쓰는지에 따라 database의 schema를 디자인할 필요가 있다.
- query에 대한 fast look-up을 위해 적절한 index 설정이 필요하다.
- MongoDB 4.0부터 transaction을 지원
- Database, collection, document로 구성된다.
- MongoDB:Database:collection:document = RDB:Database:table:row
Mongodb Architecture
- replica sets
- a single master architecture
- Primary database의 백업 개념의 secondary database가 존재
- operation log를 통해 secondary 는 primary의 내용을 복제함
- Primary에 문제가 생겼을때 차기 primary를 선출하는 과정
- 사용자가 지정한 sync source를 확인. replSetSyncFrom command를 통해 지정 가능
- node를 돌면서 condition을 체크. condition을 만족하면서 lowest ping을 가진 node 투표및 가장많은 투표를 받은 node를 primary로 선출
- replica set에 포함되는 server의 수는 짝수로 설정되는 것이 권장된다.
- primary 재선출 과정에서 동점상황을 막기위해
- splitbrain현상이 일어났을때를 대비해서
- 그래서 최소 3개의 server가 요구된다.
- 3개를 구성하기 부담스럽다면 arbiter node를 두는 것도 좋은 방법
- arbiter node : 투표권은 가지지만 백업은 수행하지 않는 노드
- Mongodb를 사용하는 application은 Mongodb cluster 내의 몇개의 server에 대한 정보를 가지고 있어야함. 그래야 primary node가 어떤 것인지 물어볼 수 있으니까
- DNS seedlist connection format을 이용해 수월하게 할 수 있음
- delayed secondary를 두어 일종의 checkpoint 개념으로 사용할 수 있다.
Sharding
- 데이터가 많아지면 scale out이 요구된다. scale out 하게되면 replica set의 데이터가 특정 index에 의해 나눠지며 각 replica set은 특정 범위의 index 값을 담당한다.
- 이 index는 replica set에 load balancing, 데이터가 어떤 replica set에 존재하는지 찾는데 이용된다.
- mongos
- mongodb를 사용하는 application들은 mongos를 가지며 mongos는 config server와 소통하면서 작동한다.
- mongos는 Index, user Id와 같은 것을 통해 어떤 replica set에 read/write해야하는지 알아낸다.
- background에 balancer를 동작시켜 데이터 분포를 실시간으로 확인하며 불균형이 발견되면 재분배함
- config server가 down되면 autosharding이 불가능해져 split storm 라고 불리는 bad state가 될 수 있음
- configuration servers
- 원하는 데이터에 접근하기위해 어떤 replica set에 접근해야하는지, 데이터가 어떻게 나눠져 있는지에 대한 정보를 담고 있다.
- 적어도 3개가 필요하다.
- sharding에 쓰이는 key의 uniqueness를 신경쓰는 것이 중요하다. cardinality가 높은 field를 key로 지정하는 것이 권장됨
Neat Things About MongoDB
- flexible : 다양한 정보를 저장할 수 있다.
- Shell is a full JavaScript interprete
- You can actually run JavaScript functions across your entire MongoDB
- supports many indices
- sharding에는 하나의 index만 쓸 수 있음
- 2~3개 이상은 권장되지 않음
- mongoDB에서 text search를 효율적으로 하기위해 text index를 둘 수 있음
- geospatial index : you can actually do searches across latitudes and longitudes
- 특정 상황에서 Hadoop의 역할을 대체할 수 있음
- built in aggregation capabilities
- Mongodb에 MapReduce code가 있음
- Mongodb에 GridFS(like HDFS)가 있음
- 하지만 MongoDB를 Hadoop, Spark와 함께 사용해서 더욱 효율적으로 사용하는 방법도 있다.
- SQL connector available for MongoDB
- Join과 같은 연산이 불가능하고 normalized data를 효율적으로 다루지는 못함
실습 MongoDB with Spark
- MongoDB의 Ambari 커넥터를 이용해 MongoDB 설치
cd /var/lib/ambari-server/resources/stacks/HDP/2.5/services
git clone https://github.com/nikunjness/mongo-ambari.git
sudo service ambari restart
# Ambari Actions-Add service 로 MongoDB install, start- Spark로 MongoDB에 데이터를 쓰고 읽기
pip install pymongo
wget http://media.sundog-soft.com/hadoop/MongoSpark.py
export SPARK_MAJOR_VERSION=2
spark-submit --packages org.mongodb.spark:mongo-spark-connector_2.11:2.0.0 MongoSpark.py실습 MongoDB Shell 사용하기
- MongoShell 실행
mongo- MongoShell 사용해 Index 생성
> use movielens
> db.users.find( {user_id:100} ) # user_id가 100인 document 출력
> db.users.explain().find( {user_id:100} )
# explain : 위의 명령어가 내부적으로 어떻게 실행되는지 보여줌
# winningPlan.stage:"COLLSCAN", winningPlan.direction:"forward" 처음부터 순차접근
> db.users.createindex( {user_id:1} ) # index를 오름차순으로 생성
> db.users.explain().find( {user_id:100} )
# winningPlan.inputstage.stage:"IXSCAN"- Aggregation, Count, collectionInfo, drop
> db.users.aggregate( [
{ $group: { _id: { occupation: "$occupation"}, avgAge: { $avg: "$age"}}}
] )
# $는 다음에 올 것이 special command라는 것을 알려줌
> db.users.count()
> db.getCollectionInfos()
> db.users.drop()Choosing Database
현재 환경 파악하기
- Apache Spark에서 big analytics job을 돌리는 상황이라면 Apache Spark와 호환이 잘되는 database를 선택해야함
- front-end system이 back-end database의 SQL interface에 의존하고 있는 상황일때 RDB를 NoSQL로 변경하려고 하면 SQL-like interface를 제공하는 NoSQL로 변경하는게 좋을 것이다.
System 요구사항 파악하기
Sclaing requirements- 저장하려는 데이터가 unbounded over time 인가 limited 인가?
- 만약 unbounded over time이라면 Cassandra, MongoDB, HBase와 같은 분산 저장이 가능하고 Horizontal scaling이 용이한 DB를 쓰는 것이 좋음
Transaction rate- 1초에 얼마나 많은 request를 처리할 수 있어야하는가?
- 수 천개의 request를 처리해야하면 단일 데이터베이스 서버로는 힘들 것이다. 여러개의 서버를 사용해서 transaction의 부하를 분산시킬 필요가 있다.
- 가장 간단한 예로 거대 website에서 이러한 요구사항을 가지고 있다.
Support you might need- 내부에 이런 새로운 기술을 구성하고 운용할 전문가가 있는가?
- NoSQL을 default setting으로 사용하면 security를 보장할 수 없다. Security를 보장하도록 NoSQL을 구성할 수 있는 전문가가 필요하다. 회사 내부에 전문가가 없다면 paid professional support를 이용할 수 있다.(MongoDB...)
Budget considerations- AWS, GCP... : 돈을 지불하고 필요한 만큼 빌려쓸 수 있다.
CAP- 하나의 server로 감당 가능한가?(Partition tolerance)
- Y/N : 단일 서버 / 분산 환경
- 몇 초 혹은 몇 분의 system down을 허용할 것인가? (Consistency)
- Y : HBase, MongoDB...
- Availability가 중요하고 eventually consistency만 만족하면 되는가?
- Y : Cassandra...
- 요즘은 CAP 이론이 조금 허물어지고 있다.
- Cassandra를 는 query의 consistency를 조절할 수 있어서 3개 모두 만족할 수도 있다.
- 하나의 server로 감당 가능한가?(Partition tolerance)
- 하지만 가장 중요한 것은 가능한 문제를 간단하게 해결하는 것이 최선의 해결책이라는 것이다.
Example 1
- building an internal phone directory application
- 회사 내부의 구성원들의 전화번호, 이메일과 같은 정보를 찾을 수 있는 웹사이트를 구성하려고한다. 회사 구성원은 만명정도이고 전화번호, 이메일과 같은 정보는 자주 바뀌지 않을 뿐더러 변경내용을 실시간으로 적용할 필요는 없다. 그리고 이 시스템은 다운되더라도 그다지 치명적이지 않다. 그리고 회사 내부에는 MySQL 서버가 있고 그에 대한 전문가도 있다.
- Scale : limited
- Consistency : eventually consistency
- Availability : Consistency보다 중요하지만 필수는 아님
- 이런 상황에서는 가장 간단하고 이미 회사 내부에 존재하는 MySQL
Example 2
- web-server log를 수집하고 내부적으로 분석하는 작업
- Scale : unbounded
- 높은 transaction rate이 요구되지않음 → NoSQL 필요 없음
- log 를 HDFS에 수집하고 Spark, Hive, Pig와 같은 것으로 분석하면됨. 더 나아가 Tableau로 시각화 하는 것도 좋은 방법이 될 수 있음. 외부 DB는 필요없음
Example 3
- Example 2에서 수집한 데이터를 통해 영화추천을 해야하는 상황, system down은 용납할 수 없음 (Netflix..)
- 실시간 추천결과를 보여줄 필요는 없음(daily) → eventually consistency
- Cassandra!
- Example 2에서 수집한 정보를 활용하여 영화추천 머신러닝 모델을 돌리고 결과를 Cassandra에 저장하는 Job을 Spark로 하루에 한번씩 실행
Example 4
- 주식 거래 시스템을 설계
- 아무래도 돈을 다루다 보니 security가 중요하고 거래라는 측면에서 consistency도 중요함
- 많은 양의 데이터를 다루기때문에 partition tolerance도 중요함
- MongoDB! 기업차원에서 기술적 지원을 하기때문에 security를 보장할 수 있고 단일 마스터 노드가 존재해 consistency를 보장할 수 있어 좋은 선택지
- HBase나 Apache 프로젝트에 지원을 제공하는 일에 특화된 회사도 있으고 HBase도 MongoDB와 동일하게 단일 마스터 노드를 가지므로 consistency를 보장할 수 있다. 이것도 고려해볼 수 있다.
- 심지어 Cassandra도 기업차원에서 기술적 지원을 하고 consistency를 가지도록 설정할 수 있으니 쓸 수 있다.
- MySQL도 그리 나쁘진 않다. 데이터 규모를 잘 가늠하고 얼마만큼의 partition tolerance가 필요한지 파악하면 MySQL의 shard만으로도 충분할 수 있다.
