논문 제목: Densely Connected Convolutional Networks
DenseNet 개요
CNN model들이 굉장히 깊어지면서 새로운 문제가 등장했다. 그 문제는 바로 입력의 정보가 깊은 신경망을 통과하면서 사라지는 문제이다.(반대의 경우 역전파를 통한 gradient가 사라지는 문제) 이러한 문제를 해결하기 위해 ResNet, Highway Networks, Fractal Nets 등이 제안되었지만, 해당 모델들은 앞부분에서 뒷부분 layer로 short path를 생성했다는 특징이 있다.
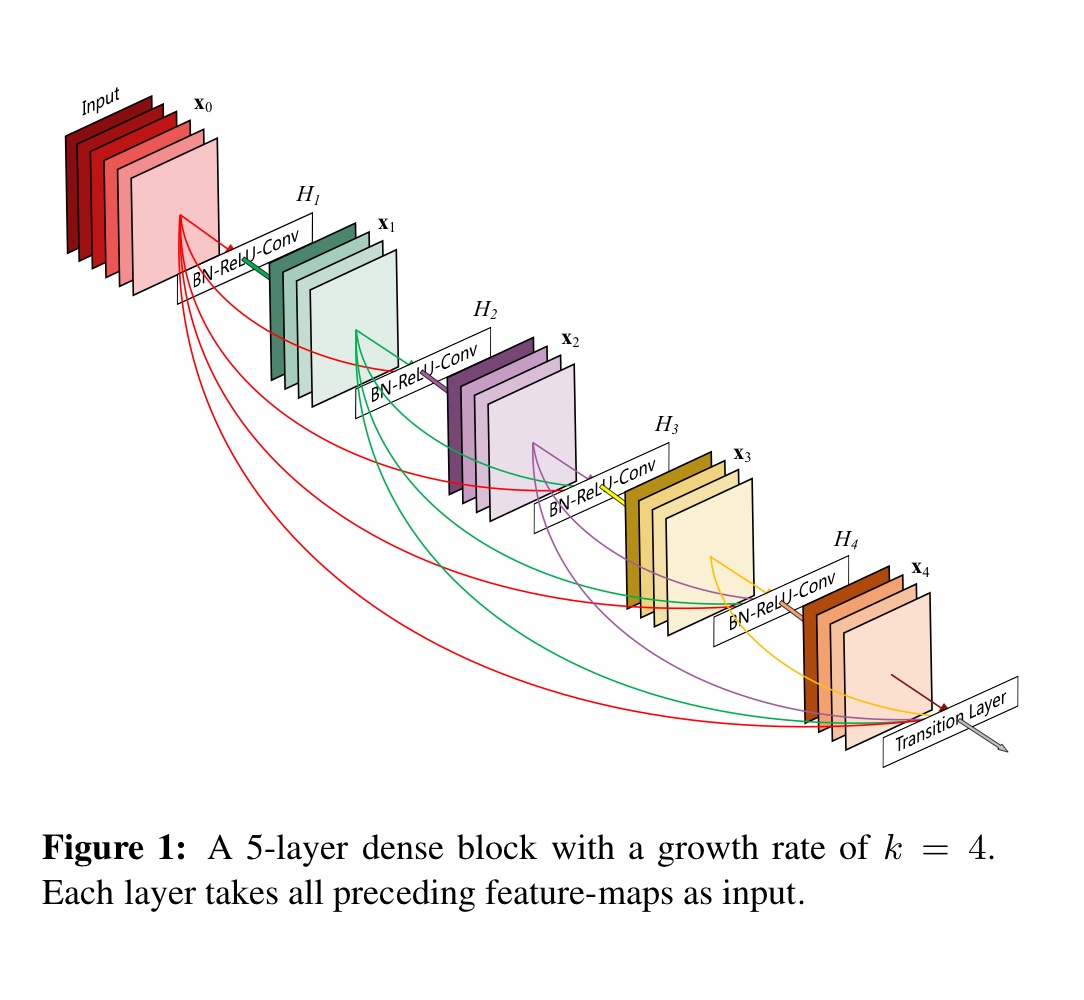
본 논문의 저자들은 이러한 insight를 통해 모든 layer들을 연결하는 단순한 패턴의 모델 구조를 제안했다. 기존의 모델들은 L개의 layer가 있을 때 L개의 연결이 있었던 반면에 해당 모델은 L개의 layer가 있을때 각 layer가 그 후속 layer들과 연결되어 총 개의 연결이 생긴다. 이런 연결의 위해 layer에서 연산을 할 때, layer 전의 layer에서 나온 feature map들을 모두 concatenate하여 사용했다. 이러한 dense connectivitiy 때문에, 저자들은 해당 모델을 DenseNet이라 명명했다. DenseNet의 개요는 다음 사진1과 같다.
 사진 1
사진 1
이러한 구조를 통한 장점은 다음과 같다.
- vanishing gradient 개선
- feature propagation 강화
- feature reuse
- 학습 parameters 수 감소
DenseNet Architecture
ResNet
DenseNet 구조 이전에 ResNet 구조를 확인해보자.
: output of layer
: non-linear transformation
은 Batch Normalization, ReLU 그리고 Convolution(or Pooling)으로 이뤄진 composite function이다.
ResNet은 non-linear transformation과 identity function으로 skip connetction을 사용한다. ResNet은 identity function을 통해 뒤의 layer에서 앞의 layer로 직접적으로 gradient를 전달할 수 있다는 장점이 있다. 하지만 합(summation)을 통해 구현된 skip connection이 information flow를 방해한다.
Dense connectivity
layer들 사이의 information flow를 개선시키기 위해 임의의 layer를 그 후속 layer들과 직접 연결을 했다.(사진1 참조)
결론적으로, layer는 이전 layer들의 feature map들을 입력 받는다. 식으로 표현하면 다음과 같다.
: output of layer
: non-linear transformation
는 ~ -1 layer들에서 나온 feature map들의 concatenation이다.
Composite function
composite function 는 batch normalization - ReLU - 3x3 convolution 순으로 구성된 non-linear transformation이다.
위의 composite function은 보통의 CNN과 다르게 ReLU(activation function) 이후 convolution 연산을 수행하는데, 이는 "identity mappings in deep residual networks" 논문의 pre-activation구조를 이용했기 때문이다.
pre-activation 구조
(pre-activation 설명 부분에서 "해당 논문"은 "identity mappings in deep residual networks"를 나타낸다.)
 사진 2
사진 2
pre-activation은 말그대로 CNN연산 전에 activation function을 수행하는 것을 말한다. 사진2에서 (d)와(e)가 pre-activation에 속하고, 해당 논문에서 제안하는 pre-activation은 (e)이다. 논문의 저자들은 (d)의 경우 ReLU와 batch normalization가 함께 쓰이지 않아서 ReLU가 batch normalization의 효과를 제대로 이용하지 못한다고 얘기한다.
사진2의 구조들의 성능 비교는 다음 사진3과 같다.
 사진 3
사진 3
pre-activation 구조의 효과는 다음과 같다.
- 최적화가 더 쉽다.
- overfitting을 줄인다.
 사진 4
사진 4
위의 사진4는 pre-activation구존의 더 빠른 수렴을 보인다.(점선: training loss, 실선: test error)
 사진 5
사진 5
위의 사진5는 각 network별 classification error를 나타낸 것이다. 이를 통해 pre-activation을 사용한 ResNet은 깊은 신경망일수록 original ResNet와 성능 비교를 할 때, 성능 향상 폭이 증가한다. 즉, 깊은 신경망을 구성할 때 pre-activation의 효과를 알 수 있다.
pooling layers
 사진 6
사진 6
Dense connectiviy에서 사용되는 concatenation 연산으로 인해 dense block내에서 feature map의 size를 바꾸는 down-sampling을 수행할 수 없다. 하지만 CNN의 본질은 down-sampling에 있다. 따라서 이를 수행하기 위해 dense block 사이에 convolution과 pooling 연산을 수행하는 transition layer를 둔다.
Transition layer는 1x1 convolution 연산과 2x2 average pooling을 수행한다.
Growth rate
만약 각각의 non-linear transformation 가 k개의 feature map들을 만든다면, layer는 개의 input feature map들을 갖는다.(: 입력 채널의 필터 수) Densenet이 기존의 CNN들과 중요한 다른 점은 DenseNet이 k=12와 같을 때 매우 narrow layers를 갖는다는 것이다. 저자들은 hyperparameter k를 growth rate라 명명했다.
실험을 통해 상대적으로 작은 growth rate도 뛰어난 결과를 얻는 것을 확인했다. 이에 대한 설명은 각 layer들이 block내에 있는 모든 이전 feature map들, 즉 네트워크의 collective knowledge(집단적인 지식)에 접근한다는 것이다.
feature map들을 global state로 생각하면, growth rate k는 global state에 각 layer가 얼마나 기여하는지를 규제(regulate)하는 것으로 생각할 수 있다.
개인적 생각
- 논문에서 growth rate는 12, 24, 40을 사용해 실험을 진행한다. 위의 input feature map의 개수를 구하는 공식을 통해 생각해보면 growth rate가 두 자리 정수이므로 dense block의 마지막 layer에서의 입력 채널의 개수가 1000이 되는 경우가 드물다. 즉, DenseNet은 growth rate를 통해 점진적으로 입력 채널이 증가된다. 또한 다음 layer의 입력으로 항상 growth rate만큼의 증가를 갖는 concat된 입력을 사용하므로 convolution 연산의 출력채널의 개수는 항상 growth rate가 되어야 한다.
ResNet, GoogLeNet등 대부분 1x1 또는 3x3 filter를 사용하므로 모델의 학습 파라미터 개수의 결정은 convolution 연산을 할 때 사용되는 입력 feature map의 채널 개수와 filter의 개수에 큰 영향을 받는다. 다른 네트워크들은 입력 채널과 출력 채널의 개수가 (256, 512,1024)등으로 매우 크다. 또한 이러한 개수를 반복해서 사용한다. 하지만 DenseNet은 입력 및 출력의 채널 크기가 점진적으로 증가하긴 하지만 절대적인 개수는 다른 네트워크 보다 적으므로 모델 전체의 학습 파라미터의 개수 또한 적다라고 생각할 수 있다.
Bottleneck layers
DenseNet에서는 ResNet과 Inception module에서 사용하는 Bottleneck layers를 사용한다. bottleneck layers는 1x1 convolution(batch normalization & ReLU포함)을 추가하므로 차원(channel 차원)을 줄여 computational 효율을 개선시키고, 모델의 비선형성을 증가시킨다.
저자들은 실험에서 비교를 위해 Bottleneck layers를 사용한 DenseNet을 DenseNet-B라 한다.
Compression
모델의 compactness를 개선시키기 위해 trainstion layer에서 feature map들의 수를 감소시킨다. transition layer이전 dense block에서 m개의 feature map들을 갖고 있다면, 라는 compression factor를 사용해 transition layer에서 출력하는 feature map들의 개수를 로 만든다. (: 보다 작은 정수들 중 가장 큰 정수) 출력 feature map을 줄이는 연산은 transition layer의 1x1 convolution의 output feature map을 조절하면 된다.
논문의 저자들은 실험에서 비교를 위해 일 때를 DenseNet-C라 했고, 위의 bottleneck layers와 같이 사용될 때를 DenseNet-BC라 했다.
Experiments
 사진 7
사진 7
CIFAR, SVHN, ImageNet 데이터셋을 사용하여 실험을 진행했다.
사진7을 보면 DenseNet이 당시 sota 모델보다 좋은 성능을 보이며, 학습 파라미터 개수도 적은 것을 알 수 있다.
Training
해당 부분에서는 epochs, batch size와 같은 hyper parameter 및 경사하강법 방법에 대해 나와있다. 또한 Densenet의 memory 문제를 말하면서 efficient한 implement를 추가 논문을 통해 보이고 있다.
Memory-efficient implement
 사진 8
사진 8
concatenate되는 feature들과 batch normalization을 통과한 feature들을 기록할 때 naive implementation처럼 새로운 메모리에 할당하지 않고, 미리 할당된 shared memory storage에 메모리 포인터를 이용해 기록한다. 이를 통해 GPU memory의 과도한 사용을 막는다.
Discussion
DenseNet은 Model compactness, Feature reuse면에서 탁월하고, 수많은 shortcut connection들이 deep supervision처럼 중간 layer들이 discriminative한 특징을 배우도록 강제하는 효과가 있다고 한다. 또한 stochastic depth에 대한 DenseNet만의 해석이 regularizing 효과가 있다는 것을 보여준다.
 사진 9
사진 9
위의 사진9를 보면 ResNet보다 적은 학습 파라미터로 동일한 성능을 보여주는 걸 확인할 수 있다. 특히 맨 오른쪽 그림에서 학습파라미터의 개수가 100배 가량 차이나는데 성능이 비슷한걸 확인할 수 있다.
Conclusion
direct connection을 사용한 DenseNet을 새로 만들었고, 그 당시에state-of-the-art 성능을 보여주었다. DenseNet의 compact internal representations와 reduced feature redundancy 덕분에 computer vision task에서 좋은 feature extractor로 사용 가능할 것이다.
References
DenseNet 논문: Densely Connected Convolutional Networks
pre-activate 논문: Identity Mappings in Deep Residual Networks
memory efficient implementaion 논문: Memory-Efficient Implementation of DenseNets
pytorch 공식 코드: https://pytorch.org/vision/0.8/_modules/torchvision/models/densenet.html
https://kangbk0120.github.io/articles/2018-01/identity-mapping-in-deep-resnet
https://phil-baek.tistory.com/entry/DenseNet-Densely-Connected-Convolutional-Networks
