논문 제목: Feature Pyramid Networks for Object Detection
개요
Feature pyramids는 다른 크기들의 객체를 탐지하는 시스템의 기본 요소이다. 그러나 최근의 딥러닝 detection들은 pyramid representation을 피하는데, 그 이유는 연산과 메모리 문제 때문이다.
본 논문에서는 feature pyramid들을 구성하기 위해 deep convolutional network의 내재된 multi-scale, pyramida hierarchy를 이용한다. 이를 위해 측면(lateral)연결을 이용한 top-down 구조를 개발했다. 이 구조는 Feature Pyramid Network(FPN)이라 명명되었고, 상당한 성능 향상을 보여줬다.
Feature Pyramid Networks
 사진 1. architecture
사진 1. architecture
FPN은 임의의 크기의 이미지를 입력으로 받아 fully convolutional 방법으로 다양한 단계의 적합한 크기의 feature map들을 출력한다. 이러한 과정은 backbone network와는 독립적으로 이뤄진다. FPN 구조는 bottom-up pathway, top-down pathway, lateral connections을 수반한다.
Bottom-up pathway
Bottom-up pathway는 backbone ConvNet의 feed-forward 연산이다. 같은 output을 size를 갖는 경우 같은 stage라하고, FPN는 각 stage마다 pyramid level 하나를 정의한다. 각 stage의 마지막 layer의 출력을 reference feature map으로 사용한다.
ResNet을 사용해서 각 stage의 마지막 residual block의 feature activations output을 사용한다. conv2, conv3, conv4, conv5 마지막 residual block의 출력을 라 명시했고, 각각은 입력 size에{4, 8, 16, 32}의 stride를 갖는다.
Top-down pathway and lateral connections
Top-down pathway는 공간적으로 coarser하지만 의미적으로 stronger한 higher pyramid level에서 upsampling 함으로써 고해상도 특징들을 환각(hallucinates)을 일으킨다. 이 특징들은 lateral connection을 통해 bottom-up pathway로 부터의 특징들과 함께 향상된다. 각각의 lateral connection은 bottom-up pathway와 top-down pathway의 같은 크기의 feature map들을 병합시킨다. Bottom-up feature map은 낮은 수준의 의미로 여겨지진만, 적은 횟수로 subsample 되었기 때문에 더욱 정확한 localization을 가능하게 한다.
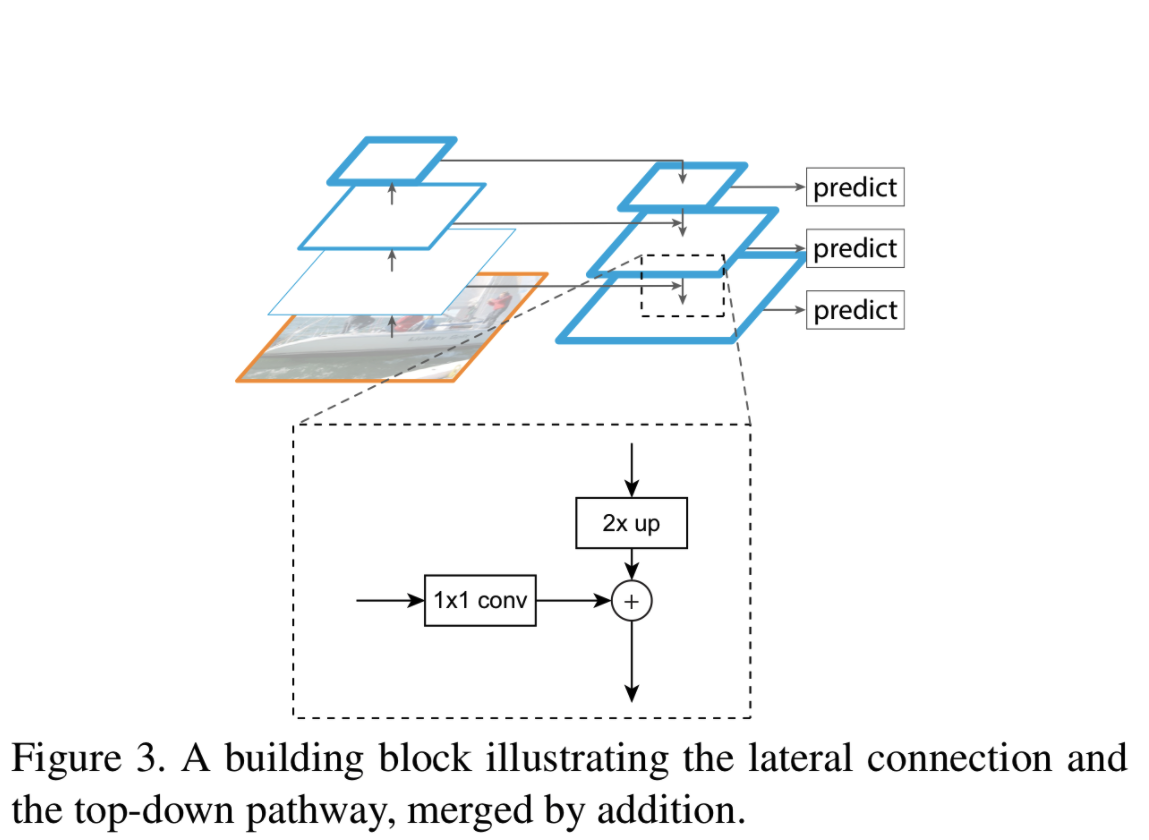
 사진 2. top-down pathway & lateral connection
사진 2. top-down pathway & lateral connection
위의 사진2는 top-down feature map을 구성하는 building block을 보여준다. Coarser한 feature map을 2배 upsample한다. 이때 간단함을 위해 nearest neighbor upsampling을 사용한다. 이후 대응되는 크기의 bottom-up feature map(차원 축소를 위해 1x1 conv 수행)과 element-wise addition에 의해 병합된다. 이를 반복적으로 수행하고 각각 size에 대해 최종 feature map을 얻기 위해 3x3 convolution을 수행한다. 3x3 convolution을 수행하는 이유는 upsampling의 aliasing 효과를 줄이기 위해서이다. 따라서 최종 feature map은 로 에 대응된다.
pyramid의 모든 level들은 공유된 classifier와 regressor들을 사용하므로 고정된 feature dimension (feature map의 channel 수)를 사용한다. 본 논문에서 d=256 이고, 이를 위해 추가적인 convolution을 수행해서 256-channel의 출력을 갖는다. 추가적인 convolution은 비선형성을 추가하지 않는데 이는 실험적으로 추가했을때 minor impact를 발견했기 때문이다.
Applications
FPN은 deep ConvNets에 feature pyramid를 구성하는 일반적인 방법이다. 본 논문에서는 RPN과 Fast R-CNN에 적용했다.
cf)
RPN & Fast R-CNN: Faster R-CNN 논문 리뷰 및 코드 구현
Feature Pyramid Networks for RPN
 사진 3. RPN
사진 3. RPN
RPN은 sliding-window class agnostic object detector 이다. 기존의 RPN의 구조는 위의 사진3과 같다. Backbone network를 통과한 feature map에 3x3 convolution을 적용한 후 1x1을 각각 classification, regression을 위한 bracnh로 적용한다. Object/non-object의 기준과 bounding box regression target은 anchors라는 reference box들로 정의된다. Anchors는 객체들의 서로 다른 모양(크기)를 커버하기 위해 사전에 정의된 크기와 화면비(aspect ratio)로 이뤄진다.
FPN에서는 RPN을 이용하기 위해 feature pyramid 각각 level에 head(3x3 conv + two 1x1 conv)를 붙인다. Head가 모든 pyramid level들의 모든 구역에 밀집되게 슬라이드(slides)하기 때문에 특정 level에 multi-scale anchors가 필요하지 않다. 따라서 각각 level에 single-scale anchors를 할당한다. 크기로 각각 에 할당한다. 또한 화면비는 {1:2, 1:1, 2:1}을 사용한다. 따라서 pyramid 전역에 15개의 anchors가 생긴다.
Anchor와 ground-truth bounding box의 IoU(Intersection over Union)이 0.7 이상인 경우 positive label, 0.3 이하인 경우 negative label을 할당한다.
RPN의 모든 head들은 공유된 가중치를 갖는다. 공유되지 않는 head들을 사용하는 모델과 비교 실험했을 때 비슷한 성능을 보여줬다. Head들이 공유된 가중치를 사용할 때 좋은 성능을 보여주는 것은 모든 level에서 유사한 semantic level들을 공유한다는 것을 보여준다.
Feature Pyramid Networks for Fast R-CNN
 사진 3. Fast R-CNN
사진 3. Fast R-CNN
Fast R-CNN은 region-based object detector이다. Fast R-CNN은 대부분 single-scale feature map에 적용된다. 따라서 FPN 구조를 활용하기 위해서는 pyramid level마다 맞는 다른 크기의 RoI(Region of Interest)를 할당해야 한다.
논문의 저자들은 RoI의 (width)와 h(height)에 따라 할당할 level 를 정하는 방법을 수식화 했다.
ResNet을 기반으로 한 Faster R-CNN에서 를 single-scale feature map으로 사용하는 것과 유사하게 하기 위해 이다.
즉, 예를 들어 하나의 RoI가 224x224인 경우 k=4가 되어 에 사상된다.
모든 level들의 모든 RoI에 predictor head(class-specific classifier & bounding box regressor)들을 붙이다. 이때 head들은 level에 관계없이 모두 가중치를 공유한다.
기존의 방법의 경우 ResNet의 Conv4 이후 head에 ResNet의 Conv5가 적용되는 반면에 FPN의 경우 이미 backbone network에서 Conv5를 사용했으므로 RoI pooling으로 7x7의 feature map들을 추출하고 이후 2개의 fc layer를 적용한다. 이후 최종 classification과 regression을 수행한다. 기존의 방법과 비교했을 때 2개의 fc layer들을 사용한 방법이 더욱 가볍고 속도가 빨랐다.
Experiments
성능 평가를 위해 80category를 갖는 COCO-detection dataset을 사용했다. 사용된 모든 네트워크의 backbone은 ImageNet1k classification dataset으로 pre-train된 ResNet-50, ResNet-101을 사용했다.
 사진 4. RPN ablation
사진 4. RPN ablation
 사진 5. Fast R-CNN ablation
사진 5. Fast R-CNN ablation
위의 사진 4,5를 통해 각각의 ablation experiments를 확인할 수 있다.
 사진 6. Comparison with other single-models
사진 6. Comparison with other single-models
Conclusion
Convolution network 내부에 feature pyramids를 구성하는 간단한 framework를 제공했다. FPN을 통해 deep convolutional network의 강력한 표현력과 scale variation의 견고함에 불구하고 여전히 multi-scale문제를 다루는 것이 중요하다는 것을 확인할 수 있다.
