논문 제목: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN 개요
SPPnet과 Fast R-CNN은 region proposal computation에 많은 시간을 사용한다. 이는 병목현상을 일으킨다. Faster R-CNN은 이런 문제를 해결하기 위해 detection network와 convolutional features를 공유하는 Region Proposal Network(RPN)을 제안한다. RPN은 Fast R-CNN의 detection에 사용되는 region proposals를 제공하기 위해 end-to-end로 학습된다. 논문의 저자들은 RPN과 Fast R-CNN의 convolutional features를 공유하므로써 이들을 하나의 네트워크로 합쳤다.
Faster R-CNN은 VGG-16 모델을 pre-trained로 사용할 때 GPU 환경에서 5fps를 보여줬고, ILSVRC와 COCO2015 competition에서 1등을 차지했다.
Faster R-CNN의 RPN은 동시에 각 위치의 region bounds와 objectness scores를 구하기 위해 pre-trained 된 convolutional layers를 통과한 convolution features에 약간의 추가적인 convolution layers를 추가하므로써 구성했다. 따라서 RPN은 fully convolutional network(FCN)의 한 종류이고, detection proposals를 위해 end-to-end 학습이 가능하다. RPN은 여러 크기와 이미지 비율을 처리하기에 효율적으로 고안되었다. 저자들은 새로운 anchor boxes 방법을 이용했고, 속도를 향상시킬 수 있었다. 또한 RPN과 Fast R-CNN을 통합하기 위해 새로운 training scheme을 제안했다.
Faster R-CNN
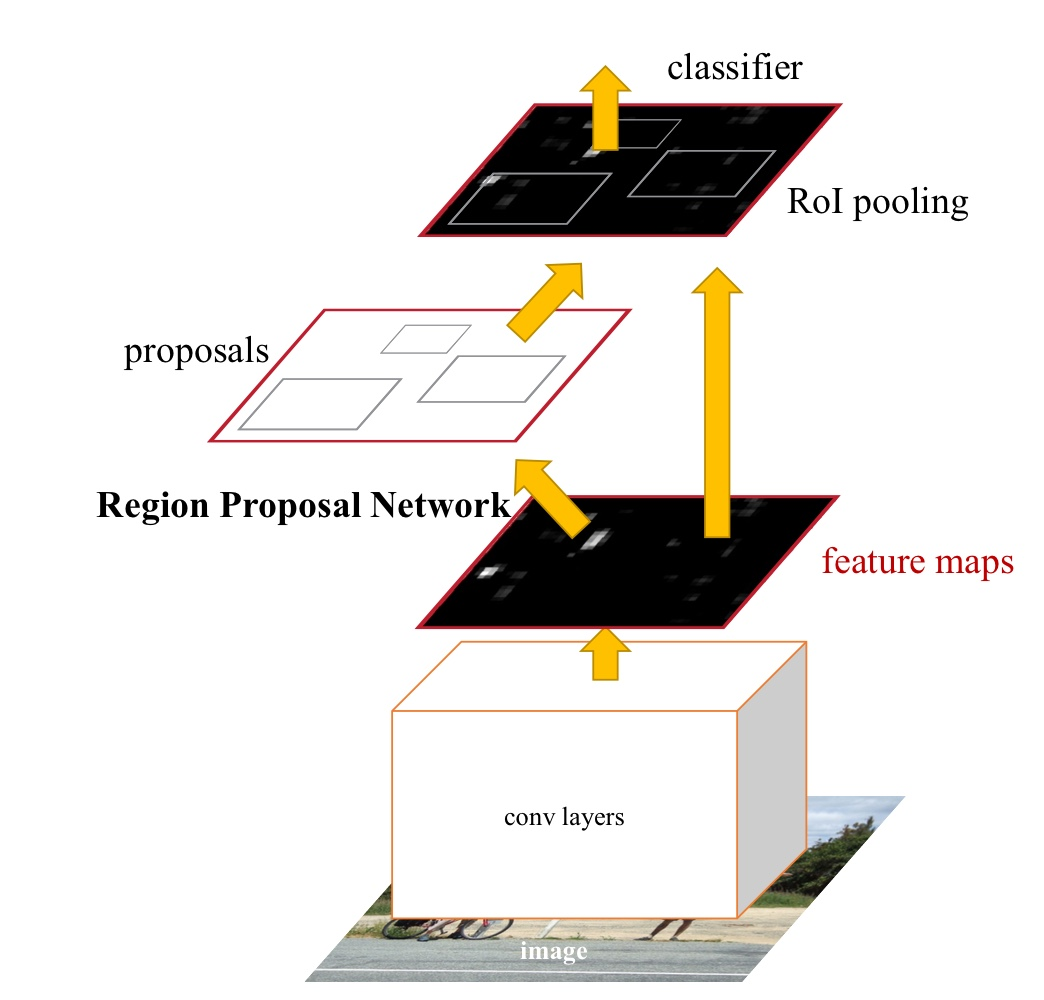
 사진1. Faster R-CNN Architecture
사진1. Faster R-CNN Architecture
- regions propose를 위한 deep fully convolutional network
- proposed regions를 이용하는 Fast R-CNN
위의 사진1과 같이 전체 구조는 하나의 통합된 네트워크로 object detection을 수행한다. RPN module은 Fast R-CNN module에게 어떤 부분이 중요한지 설명해주는 'attention' mechanisms을 수행한다.
3.1 Region Proposal Networks(RPN)
 사진2. RPN network
사진2. RPN network
anchor
기존의 sliding window 방법은 고정된 크기의 window를 이미지에서 sliding하며 각 window에서 객체를 탐지한다. 이때 고정된 고정된 크기의 window를 사용한다는 것은 객체를 탐지할 때, 객체의 크기들이 다 유사하다는 가정을 하는 것과 마찬가지가 된다. 하지만 객체들은 다 제각각의 크기를 갖고 있으므로 이러한 가정을 통해 object detection을 하게 되면 좋은 결과를 얻기 어렵다. (참고: sliding window란?)
anchor를 사용하면 이러한 문제를 해결할 수 있다. 위의 사진2에서 sliding window를 보면 가운데 pixel(파란 점)을 기준으로 k개의 anchor boxes가 있는 것을 확인할 수 있다. 이렇게 k개의 anchor boxes를 이용하면 하나의 window에서 여러 가지의 scale 및 aspect ratio(비율)의 bounding box를 고려할 수 있게 된다. 논문의 저자들은 3가지의 scale과 3가지의 aspect ratio를 이용해 각각의 sliding position 마다 k=9(3x3)개의 achor boxes를 사용했다.
feature map(pre-trained된 conv를 통과한)에 zero-padding을 1 적용하면 각 픽셀이 sliding position의 중심점이 된다. 따라서, feature map의 size가 WxH라면 feature map에서 WxHxk개의 anchor boxes가 있다는 것을 알 수 있다.
RPN의 입력과 출력
 사진3. RPN network
사진3. RPN network
anchor에 대한 설명과 위의 사진3을 참고하여 RPN의 입력과 출력을 설명하면 다음과 같다.
-
pre-trained convolutional networks를 통과해 얻은 feature map(WxHxC)을 입력으로 사용한다.
-
feature map에 3x3 conv 연산을 수행한다. zero-padding을 1 적용하여 입력과 intermediate feature map의 크기를 WxH로 유지한다.
-
intermediate feature map에 대해 유사한 2개의 1x1 conv 연산을 각각 수행한다. 하나는 classification(object의 존재)이고, 다른 하나는 bounding box regression(object의 위치)이다.
-
classification result는 WxHx18이다. WxH에서 각각의 grid는 sliding position의 중심점을 나타낸다. 18은 2x9로 2는 classification score(object vs not object)를 나타내고, 9(=k)는 각각의 anchor boxes를 나타낸다
-
Bounding box regression result는 WxHx36이다. 18이 아니고 36인 이유는 bounding box를 4개의 좌표를 이용해 regression하기 때문이다.
Loss function and training
Loss function은 다음과 같다
: index of an anchor
: predicted probability
: parameterized coordinates
: mini-batch size
: the number of anchor locations
: balancing parameter (default = 10)
: cross-entropy loss
: L1 smooth loss
윗첨자로 쓰인 *는 ground-truth를 의미한다.
참고) Fast R-CNN의 multi-task loss와 유사하다. 해당 loss에 대한 자세한 설명은 Fast R-CNN 리뷰를 참고
= 1인 경우 positive sample이고, = 0인 경우 negative sample이다.
positive sample과 negative sample의 정의는 다음과 같다
positive sample: IoU가 가장 높은 anchors 또는 IoU가 0.7 이상인 경우
negative sample: IoU가 0.3이하인 경우
ignore sample: positive 또는 negative가 아닌 anchors로 학습에 사용되지 않는다. (참고: -1로 labeling)
IoU(intersection of Union)는 anchor와 ground-truth box간의 계산으로 얻어진 것이다.
RPN을 학습하기 위한 mini-batch를 구성하는 방법을 알아보자.
일단 mini-batch에 대해 간단히 알아보면, 하나의 이미지로 얻어진 anchor들 중에서 positive 128개+negative 128개 = 256개의 anchor로 구성된다.
mini-batch에 대한 자세한 설명은 다음과 같다.
사진 2에서 conv feature map은 WxH의 size를 갖는다. (W,H)= (50,50), k=9라 해보자. 그러면 하나의 이미지에 anchor box의 개수는 50x50x9 = 22500개이다. 이 중에서 이미지의 경계를 벗어나는 anchor들을 제외한다(-1로 labeling). 그 다음 위의 positive/negative의 기준에 따라 labeling을 한 후 각각 랜덤하게 128개씩 sampling을 수행해서 256개의 anchor box를 얻게 된다. 이렇게 얻은 256개의 anchor box들이 mini-batch가 된다. (나머지 ignore sample들 -1로 labeling)
위의 Loss function과 mini-batch를 backpropagation과 SGD를 이용해 RPN을 학습시킨다.
참고) ignore labeling을 하는 이유??
22500개의 anchor 중에서 256개의 anchor만을 이용해서 loss를 구하지만, loss를 구할 때는 22500개의 모든 anchor를 고려해야 하기 때문이다. 즉, RPN의 output과 ground-truth의 차원을 맞춰줘야 되므로 ignore labeling을 하고, loss를 계산할 때는 무시하도록 한다.
3.2 Sharing Features for RPN and Fast R-CNN
 사진4. Faster R-CNN
사진4. Faster R-CNN
RPN과 Fast R-CNN의 features 공유를 설명하기 전에 Fast R-CNN module은 Fast R-CNN 논문의 학습 방법으로 학습한다. 한 가지 다른 점은 selective search를 통해 RoI를 받는 것이 아니라 RPN을 통해 RoI를 받는다. 이 때, 모든 anchor를 RoI로 설정하는 것이 아니라 Non-maximum suppression을 사용해 2000개의 RoI들만 이용한다.
4-Step Alternating Training
RPN과 Fast R-CNN을 통합해서 학습하는 방법은 다음과 같다.
 사진5. Alternating Training
사진5. Alternating Training
사진 5에서 파란색 네트워크는 업데이트가 되지 않는 네트워크이다.
- RPN training 방법을 통해 학습을 한다. 이때, pre-trained VGG도 같이 학습
- (1)로 학습된 RPN을 이용해 RoI를 추출하여 Fast R-CNN 부분을 학습시킨다. 이때, pre-trained VGG도 같이 학습
- (1)과 (2)로 학습된 pre-trained VGG를 통해 추출한 feature map을 이용해 RPN을 학습시킨다. 이때, pre-trained VGG는 학습시키지 않는다.
- (1),(2)를 통해 학습된 pre-trained VGG와 (3)을 통해 학습된 RPN을 이용해 Fast R-CNN을 학습한다. 이때, pre-trained VGG와 RPN은 학습시키지 않는다.
참고) 해당 논문에는 다른 학습 방법들도 소개되었으나 논문의 모든 실험은 위의 방법으로 실행되었다. 이외에 Approximate joint training 방법이 있는데, 이는 모든 RPN loss와 Fast R-CNN loss를 더해서 학습시키는 방법이고 꽤 좋은 성능을 보였다. 그리고 위의 방법보다 짧은 학습시간을 보여줬다.
Detection
 사진6. Training
사진6. Training
 사진7. Detection
사진7. Detection
사진 7은 Faster R-CNN의 detection 작동 방식을 나타낸 사진이다.
사진 6은 training 작동 방식을 나타내고, 사진 7과 다르게 'Anchor target layer'와 'Proposal target layer'가 존재한다. 이는 학습을 위해 필요햔 ground truth를 만들어 주는 layer들이다.
결론
Faster R-CNN은 RPN을 사용해 기존의 object detection network들 보다 좋은 성능을 보여주는 것과 동시에 거의 실시간의 처리 속도를 갖는 object detection network 이다.
코드 구현
코드는 개인 github에 pytorch를 사용해 구현했다.
chenyuntc님의 깃허브에 pytorch로 구현된 Faster R-CNN repository를 참고해서 코드 구현을 진행했다.
코드 자체를 수정한 부분은 적지만, 학습과정이나 학습에 사용되는 네트워크들의 쓰임세를 주석으로 설명했다.
References
Faster R-CNN 논문: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
https://yeomko.tistory.com/17
https://herbwood.tistory.com/10?category=856250
https://www.youtube.com/watch?v=kcPAGIgBGRs
chenyuntc님의 깃허브
https://metar.tistory.com/entry/Sliding-window%EB%8A%94-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8Cobject-detection
