
replace
str1 = 'python are easy are'
str2 = str1.replace('are', 'is')
# 3번째 파라미터 없을 땐 'are'에 해당하는 문자열 모두 수정
print(str2) # 'python is easy is'
str1 = 'python are easy are'
str2 = str1.replace('are', 'is', 1)
# 3번째 파라미터에 수정하고 싶은 갯수를 지정
print(str2) # 'python is easy are' 인덱스가 감소하는 반복문
for i in range(4, 0, -1): # 0은 미포함
print(i) # 4, 3, 2, 1
# 3번째 파라미터: 감소하는 간격
list = [0, 1, 2, 3]
for i in range(len(list) - 1, -1, -1):
print(list[i]) # 3, 2, 1, 0
for i in reversed(range(5)):
print(i) # 4, 3, 2, 1, 02차원 배열의 반복문
arr = [[0, 0], [1, 10], [2, 20], [3, 30]]
for i, j in arr:
print(i, j)
# 0 0
# 1 10
# 2 20
# 3 30
arr = [[0, 0 ,0], [1, 11, 111], [2, 22, 222], [3, 33, 333]]
for x, y, z in arr: # for 뒤의 변수의 갯수는 2차원 배열의 row 길이와 같아야 한다.
print(x, y, z)
# 0 0 0
# 1 11 111
# 2 22 222
# 3 33 333collections.Counter
import collections
arr = ['a', 'b', 'c', 'a', 'b', 'e'] # 배열
print(collections.Counter(arr)) # 기본적으로 Counter()는 내림차순
# Counter({'a': 2, 'b': 2, 'c': 1, 'e': 1})
dic = {'가': 3, '나': 12, '다': 4}
print(collections.Counter(dic)) # 딕셔너리 타입은 value를 기준으로 카운팅이 동작 된다
# Counter({'나': 12, '다': 4, '가': 3})
string = "aabcdeffgg" #문자열
container = collections.Counter(string)
print(container)
# Counter({'a': 2, 'f': 2, 'g': 2, 'b': 1, 'c': 1, 'd': 1, 'e': 1})
container.update('aaabbbccc') # Counter값 갱신 -> 기존 값들에 누적시킨다.
print(container)
# Counter({'a': 5, 'b': 4, 'c': 4, 'f': 2, 'g': 2, 'd': 1, 'e': 1})
import collections
c = collections.Counter("Hello Python")
print(list(c.elements())) # elements() => 입력 값 요소들을 무작위로 출력 + 대소문자 구분
# [' ', 'H', 'P', 'e', 'h', 'l', 'l', 'n', 'o', 'o', 't', 'y']
교집합 및 합집합
import collections
a = collections.Counter('aabbccdd')
b = collections.Counter('aabbbce')
print(a & b)
print(a | b)
print(list(a & b)) # 교집합 원소만 뽑을 때
# Counter({'a': 2, 'b': 2, 'c': 1})
# Counter({'b': 3, 'a': 2, 'c': 2, 'd': 2, 'e': 1})
# ['a', 'b', 'c']
# list로 감싸지 않으면 교집합 및 합집합 모두 {key: value} 출력deque
from collections import deque
queue = deque([10, 20, 30])
queue.append(40)
print(queue) # deque([10, 20, 30, 40])
queue.popleft() # 가장 앞단 원소 꺼내기
print(queue) # deque([20, 30, 40])
queue.appendleft(50) # 가장 앞단에 원소 추가
print(queue) # deque([50, 20, 30, 40])find, index
string = 'hello python'
print(string.find('l')) # 2
print(string.find('p')) # 6
# find는 해당 타겟이 탐색 영역에서 처음 나온 위치를 반환, 아예 안나오면 -1. 또한 find는 문자열에서만 가능
string = 'hello python'
print(string.index('p')) # 6
print(string.index('a')) # ValueError: substring not found
# 기본적으로 find와 같이 처음 나온 위치를 출력하지만 나오지 않으면 -1이 아닌 오류를 발생시킨다. 모든 이터러블 객체는 사용 가능
chr, ord (아스키 코드)
alphabetList = list(range(97, 123)) # 아스키 코드값 a(97) - z(123)
for i in alphabetList: # chr은 아스키코드 넘버를 해당 문자로 반환
print(chr(i)) # a, b, c, d, ∙∙∙, y, z
string = 'a'
print(ord(string)) # 97
# ord: chr의 반대로 해당 문자열의 아스키코드를 탐색
strip, rstrip, lstrip
string = ' hi python '
print(string.rstrip()) # ' hi python' => 오른쪽 공백삭제
print(string.lstrip()) # 'hi python ' => 왼쪽 공백삭제
print(string.strip()) # 'hi python' => 좌우 양쪽 공백삭제내장함수 복잡도
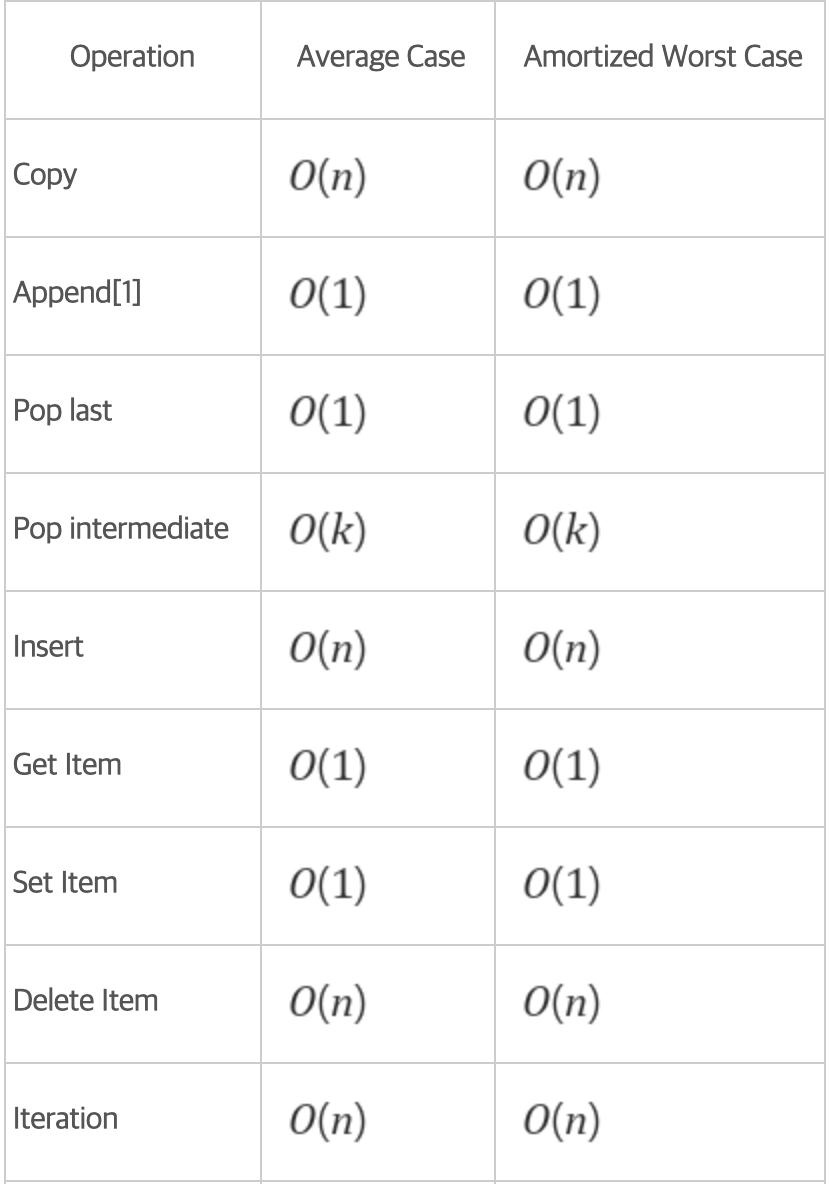
참고)
replace
https://ponyozzang.tistory.com/334
인덱스 감소 반복문
https://dojang.io/mod/page/view.php?id=1271
2차원 배열 반복문
https://dojang.io/mod/page/view.php?id=2292
collections.Counter & 교집합 합집합
https://excelsior-cjh.tistory.com/94
deque
https://www.daleseo.com/python-queue/
find, index
https://wikidocs.net/13
chr, ord
https://ooyoung.tistory.com/68
https://wikidocs.net/32
strip, lstrip, rstrip
https://dojang.io/mod/page/view.php?id=1334
내장함수 복잡도
https://daimhada.tistory.com/56

프론트 개발자 준비