보통 이진분류든 다중분류든 많은 경우 데이터가 불균형한 것을 볼 수 있을것이다.
이 글은 서울대학교 빅데이터 핀테크 과정을 진행하면서 한 프로젝트중 실제 비지니스에서 그저 데이터를 잘 맞추는것이 아닌 비지니스에 적합한 목적함수로 optimal threshold를 정해야하는것을 알게되어 쓰게 되었다.
먼저 해당 과제는 해외 p2p lending 업체의 Lending club 데이터를 통해 해당 고객이 대출을 신청했을시 이 고객이 대출을 갚을 사람인가 아니면 대출을 갚지 못할 사람인가를 예측하는 이진분류 문제였다.
해당 이진분류 문제의 target데이터의 class 비율 약 (8:2)로 다음과 같았다. 보통 불균형 데이터일때 positive label을 1로 둔다.
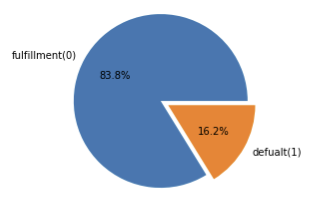
해당 클래스 비율을 확인한 이후 어떤 분류 metric을 써서 학습을 해야할지 고민하게 되었다. 일단, accuracy로 접근하는건 아니였다. 이유는 그냥 모델자체를 모든걸 다 fulfillment(0)으로 예측하면 accuracy는 83%가 나오게 된다.
여러가지 분류지표를 알아보고싶다면 해당 사이트에 들어가서 확인해보면된다.
https://dacon.io/forum/405817
결국 여러가지 분류 지표중에 AUC_score 를 사용하기로 하였다. AUC_score를 사용한 이유는 총 2가지가 있다.
💡2번째 이유:
AUC_score가 좋은 모델의 optimal threshold의 변경을 통해 비지니스의 목적에 맞는 모델을 결정할 수 있기때문이다. 이는 아래의 예시를 통해 보면 더 이해가 빠를것이다.
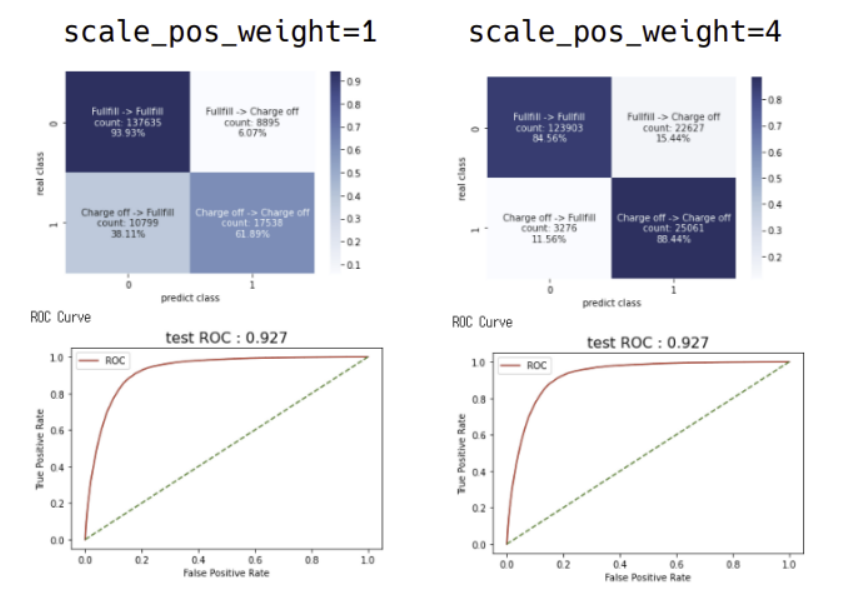
아래는 2개는 LGBM Classifier 의 나머지 파라미터는 동일 하게 설정하고 scale_pos_weight (postive를 더 잘맞추는쪽으로 가중치를 줄것이냐 주지 않을것이냐에 대한 파라미터로 default값은 1이다. 이는 roc curve에서 optimal threshold를 변경해주는 것과 동일한 역할을 한다.)를 1과 4로 설정했을때의 모델이다.
roc_auc_score는 동일하지만 confusion matrix 의 양상이 다른것을 볼수 있을것이다. scale_pos_weight=1의 경우에는 상대적으로 positive보다 비율이 많은 negative를 잘 맞춘 케이스이고 scale_pos_weight=4의 경우에는 postive쪽으로 가중치를 둬 상대적으로 적은 비율의 positive를 더 잘맞춘 케이스다.
이 두개를 보고 어느것이 더 좋다고 말할수 있는가? 그럴수 없을 것이다. 따라서 이는 해당 모델을 사용하고자 하는 비지니스에 맞는 목적식을 세워 해당 목적을 최소화 또는 최대화 시키는 모델을 찾아야할것이다.
프로젝트의 비지니스 모델 관점에서 생각해보면 즉, Lending club의 관점에서 생각해 아래와 같은 이유를 통해 목적함수를 만들었다.


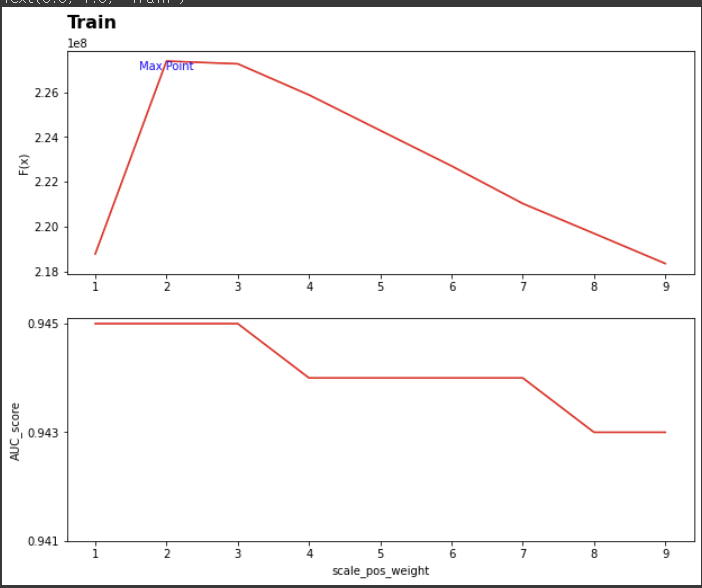
해당 목적함수를 통해 LGBM의 파라미터인 scale_pos_weigh를 1에서 부터 9까지 적용해보며 어떤 값일때 목적함수(F(x))값이 최대가 되는지 확인하였고 그 결과 scale_pos_weigh=2 일때가 최고가 됨을 아래 그래프를 통해서 볼 수 있다.
이제 마지막으로 학습시킨 LGBM 모델에 대한 해석을 진행하고 글을 마무리하려고 한다. 이번에 모델 해석을 위해 처음으로 shap value를 알게되었고 XAI의 중요성 또한 알게되었다. 왜냐하면 만약 해당 모델을 실제 비지니스에서 사용하고자 하면 어떠한 이유로 해당 모델에서 대출을 거부 또는 승인을 했는지를 알아야 하기 때문이다.
[Sharp Value of LGBM]
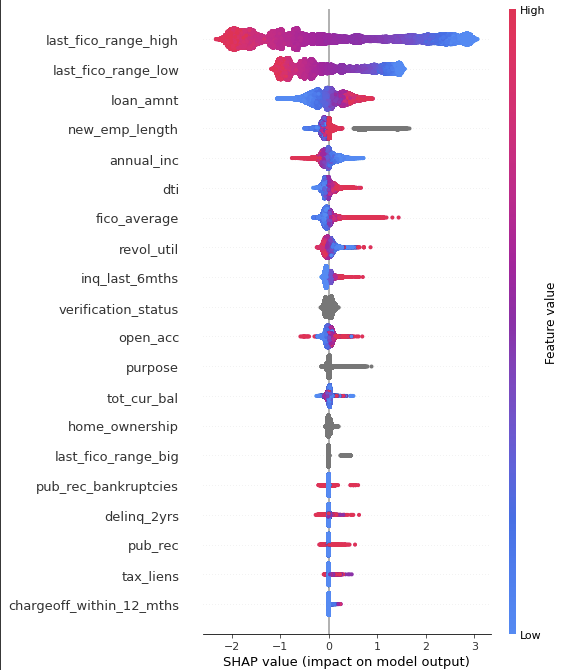
해당 분석에 사용한 코드와 PPT자료는 github에 올려두었다.
reference:
