2023년 LLM이 뜨게되면서 나역시 LLM을 이용한 application을 만드는법과 Fine-tuning 등을 공부하며 NLP 기초부터 공부해보자 라는 생각을 가지게 되었고 따라서(RNN,LSTM,seq2seq,bert,transformer)등의 모델들을 공부해보자 라는 계획을 새웠다.
이번 글은 그중 가장 기초인RNN 을 공부한 내용을 정리해볼예정이다.
해당 글은 Kaist RNN 강의 를 참고하였다.(링크에 PPT, 코드자료가 있다.)
Idea of RNN
RNN 모델 자체의 아이디어는 생각보다 간단했다. 기존의 MLP 만으로는 Sequential한 특징을 모델에서 학습할 수 없기에 이를 학습할 수 있도록 history를 반영하겠다는 것이다.
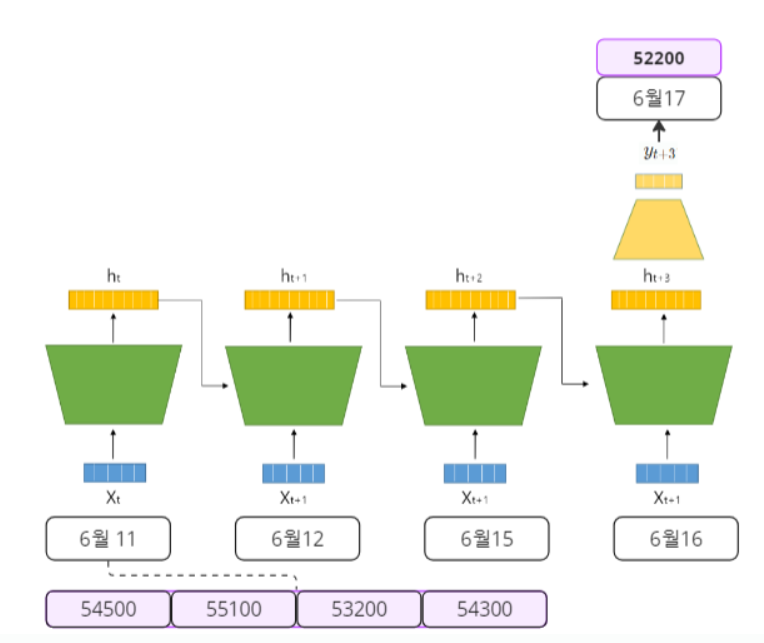
주식을 예로 들어보자, 주식 데이터는 여러개가 있지만 4일 동안의 "Open", "High", "Low", "Close"을 가지고 다음날(5일째)의 종가를 예측해보고 싶다고 하자.

이걸 RNN의 다이어그램으로 표현해보면 아래와 같다.
먼저 모델을 이해하는데 중요한 용어를 설명하고 해당 용어는 굵은 글씨로 표현하도록 하겠다.
- 4일 동안의 데이터를 통해 다음날의 종가를 예측하는 문제이므로 RNN에서는 many to one 의 케이스이다.(다른것도 있지만 해당 포스팅에서는 many to one만 다루도록 하겠다.)
- 4일 동안의 데이터가 입력에 들어가므로 sequence length 는 4다.
- X에 들어가는 데이터는 (Open, High, Low, Close)이므로 model의 input Dimension은 4다.
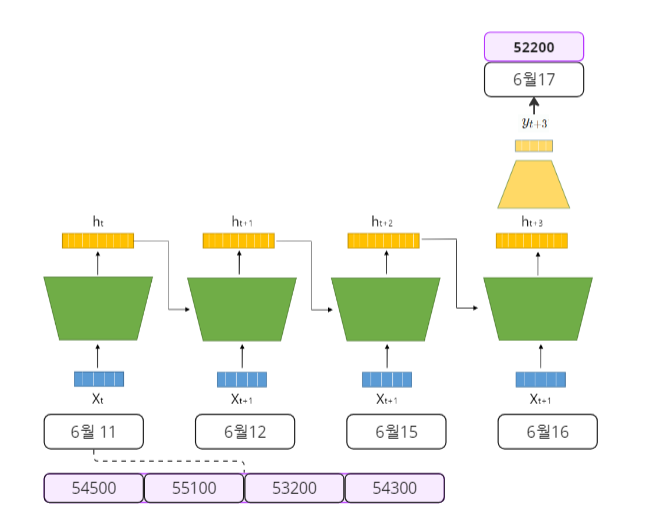
그러면 이제 RNN의 작동원리를 살펴보자. RNN을 공부하기 위해 구글링을 해보면 대표적으로 많이 보이는 도식도가 나오는데 개인적으로 Kaist RNN 강의에 나오는 도식도가 이해하기 제일 쉬웠다!

해당 도식을 이해하기 위해 중요한 용어는 굵은 글씨로 표현하였다.
(1). 먼저 t시점에서 와 를 hidden dimension으로 선형변환 시켜준다.
(2). 그 다음 선형변환한 두 벡터를 더한뒤 non-linear activation을 통과시켜 를 만든다.
(3). 이과정을 sequence length만큼 반복한후 마지막 는 Task의 목적에 맞는 function을 통과시켜서 결과값을 얻는다.
다시 위의 주식예측의 Case로 돌아와서 수식과 함께 이해해보자!
해당 그림을 수식으로 표현하면 고작 아래가 전부이다.
여기서 는 각각 벡터 를 hidden state의 차원인 차원으로 선형변환 해주는 행렬이며 는 모델의 마지막 시퀀스(4번째 시퀀스)인 를 output인 1차원 데이터로 선형변환 시켜주는 행렬이다.
는 non-linear-activation function으로 보통 를 사용한다.
초기값인 는 0벡터나 random initialization을 해주면된다.
Pytorch scratch RNN
Kaist RNN 강의의 퀄리티가 좋아 해당 자료만으로 충분히 RNN의 구조가 이해가 되었지만 결국 Pytorch로 해당 모델을 직접 만들고 task에 적용해봐야 그 모델을 완벽히 이해할 수 있는거 같다.
그래서 Kaist RNN 코드 자료를 참고해 직접 해당 포스팅의 Task인 4일의 4일 동안의 "Open", "High", "Low", "Close"을 가지고 다음날(5일째)의 종가를 예측해보는 실습을 진행하였다.
먼저 make_sequence_data() 함수를 통해 다운받은 데이터를 (data_num, sequence_length, input_dim)의shape으로 만들어 주었다.
def make_sequence_data(data, seq_length):
X = []
y = []
for i in range(len(data)-seq_length):
try:
X.append(data[i: i+seq_length, :])
y.append(data[i+seq_length, 3])
except:
pass
return np.array(X), np.array(y).reshape(-1, 1)따라서 해당 함수를 사용하게 되면 우리의 Task와 적합한 (data_num, 4, 4) shape의 numpty array가 만들어진다.
X_train.shape = (685, 4, 4)
y_train.shape = (685, 1)
X_test.shape = (57, 4, 4)
y_test.shape = (57, 1)✨이제 다음과정이 실습할때 제일 아리까리한 내용이였다.
바로 위에서 만든 데이터를 RNN의 input data 형태인 (seq_length, Batch_size, input_dim)의 형태로 바꿔주어야 한다는 것이였다. 왜일까?
일단 X_train을 다음 코드를 통해 (Batch_size, sequence length, input_dim)의 shape를 (seq_length, Batch_size, input_dim)으로 변환해보겠다.(이때 Batch_Size는 685로 한다. 즉, 1epoch마다 X_train 데이터를 전부 학습시키겠다는 것이다.)
X_train = np.swapaxes(X_train, 0, 1)X_train.shape = (4, 685, 4)이러한 차원으로 바꿔줘야 하는 이유는 바로 아래 반복문 코드를 통해 이해할 수 있다.
for sequence, batch_data in enumerate(X_train):
print(f"sequence: {sequence+1}, batch_data: {batch_data.shape}")sequence: 1, batch_data: (685, 4)
sequence: 2, batch_data: (685, 4)
sequence: 3, batch_data: (685, 4)
sequence: 4, batch_data: (685, 4)즉, Sequence의 순서대로 batch_data만큼 연산을 해주기 위해서다.
더욱더 직관적인 이해를 위해 그림으로 표현하면 아래와 같다.

RNN의 input_data를 어떤식으로 만들면 되는지 다 알아봤으므로 이제는 모델 코드와 학습 코드를 보고 포스팅을 마치도록 하겠다.
- 모델 코드
class RNN(nn.Module):
def __init__(self, input_dim, output_dim, hid_dim, batch_size):
super(RNN, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.hid_dim = hid_dim
self.batch_size = batch_size
# nn.Linear는 선형 변환을 의미한다.즉, (output_dim, input_dim)의 matrix를 만드는것과 동일
self.w_x = nn.Linear(self.input_dim, self.hid_dim, bias=False)
self.w_h = nn.Linear(self.hid_dim, self.hid_dim, bias=False)
self.w_y = nn.Linear(self.hid_dim, self.output_dim, bias=True)
self.activation = nn.Tanh()
self.hidden = self.init_hidden() #hidden은 연산을 위해 필요할뿐 결국 모델은(w_x, w_h, w_y)
def init_hidden(self, batch_size=None):
if batch_size is None:
batch_size = self.batch_size
return torch.zeros(batch_size, self.hid_dim)
def forward(self, x):
h = self.activation(self.w_x(x) + self.w_h(self.hidden))
y = self.w_y(h)
return y, h- 학습 코드
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.005)
epoch = 100
for i in range(epoch):
model.train()
model.zero_grad()
optimizer.zero_grad()
model.hidden = model.init_hidden()
for x in X_train:
x = torch.Tensor(x).float()
y_train = torch.Tensor(y_train).float()
y_pred, hidden = model(x) #y_pred 도 계산은 하지만 결국 필요한건 마지막의 y_pred만 필요하게 된다. y_pred.shape()
model.hidden = hidden
loss = loss_fn(y_pred, y_train)
loss.backward()
optimizer.step()
if i%10==0:
print(f"EPOCH: {i} Loss:{loss.item()}")해당 실습코드는 아래 Github에서 확인할 수 있습니다.😀
Full code
https://github.com/skkumin/deeplearning/tree/main/RNN
