deep learning
1.Python 경사하강법(BGD), 확률적경사하강법(SGD), 미니배치 구현하기

BGD(Batch Gradient Descent):전체 학습 데이터를 기반으로 계산예를들어 피처가 100개라고 생각하면 뉴럴네트워크에서 weight의 개수가 기하급수적으로 증가한다. 이를 GD로 계산하는데는 많은 computing자원이 소모된다. 이를 극복하기 위해 S
2.Neural Network 활성화 함수(Activation Function)

활성화 함수의 사용 이유: 활성화 함수는 이전 층의 output값을 함수에 적용시켜 다음 층의 뉴런으로 신호를 전달한다. 활성화 함수가 필요한 이유는 모델의 복잡도를 올리기 위함인데 모델의 복잡도를 올리는 이유는 비선형 문제를 해결하기 위해서이다. perceptr
3.Neural Network 오차 역전파(back propagation)

심층신경망에서는 신경망의 크기가 너무 커지고, 입력이나 출력의 개수가 많아지면서 graient descent의 방법은 사실상 불가능하다. 따라서 Neural Network에서는 출력층부터 역순으로 Gradient 를 전달하여 전체 Layer의 가중치를 Update하는
4.Neural Network 손실함수(Loss funstion, Cost function)

신경망은 "하나의 지표"를 기준으로 최적의 매개변수 값을 탐색한다. 신경망 학습에서 사용하는 지표를 손실함수라고 한다.손실 함수는 신경망 성능의 "나쁨"을 나타내는 지표로, 현재의 신경망이 훈련 데이터를 얼마나 잘 처리하지 "못"하느냐를 나타낸다.일반적으로 손실함수로
5.Neural Network 순전파 행렬곱셈 과 배치처리

사이킷 런의 iris 데이터는 feature의 수가 총 4개 그리고 타겟은 3가지의 class이다.이를 1번째층은 50개의 hidden layer, 2번째 층은 100개의 hidden layer를 가진 신경망 모델을 만든다고 하면 하나의 데이터에 대한 신경망 배열의 현
6.Neural Network Optimizer(Momentum, AdaGrad, RMSprop, Adam)

신경망 학습의 목적은 손실 함수의 값을 가능한 한 낮추는 매개변수를 찾는 것이다. 이는 곧 매개 변수의 최적값을 찾는 문제이며, 이러한 문제를 투는 것을 최적화(optimization)이라 한다.Optimizer는 optimization을 하기위해 보다 최적으로 gra
7.텐서(Tensor)의 이해

최근의 모든 머신 러닝 시스템은 일반적으로 텐서를 기본 데이터 구조로 사용한다.데이터를 위한 컨테이너라고 생각하면된다.축의 개수:랭크라고도 부르며 넘파이 배열에서는 ndim을 통해 확인할수있다. 크기:텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타낸 튜플 넘
8.Neural Network의 Fully Connected Layer는 Linear Transform이다.

Neural Network 의 Fully Connected Layer는 사실 $y = x_1 + x_2 + 3$ 과 같이 Linear Transfom이 아니다.Linear Transform 설명:https://velog.io/@skkumin/%ED%96%89%
9.RNN - 딥러닝의 기본적인 시퀀스 모델(이론&Pytorch)
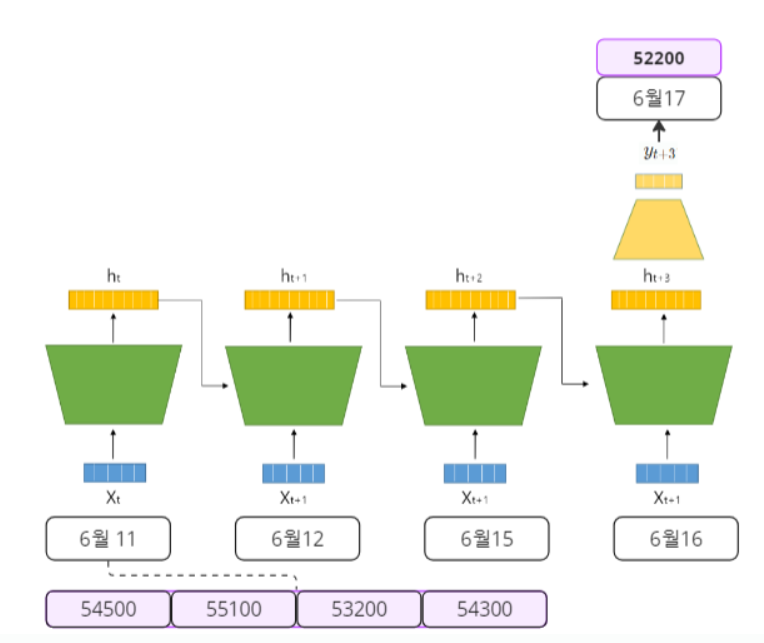
RNN 그림으로 쉽게 이해하기 & Pytorch Scratch