
본 논문 : https://arxiv.org/abs/1802.05365
ELMo는 2018년에 제안된 새로운 워드 임베딩 방법론입니다. ELMo라는 이름은 세서미 스트리트라는 미국 인형극의 케릭터 이름이기도 한데, 뒤에서 배우게 되는 BERT나 최근 마이크로소프트가 사용한 Big Bird라는 NLP 모델 또한 ELMo에 이어 세서미 스트리트의 캐릭터의 이름을 사용했다고 합니다.
Introduction
Word2Vec이나 Skip-gram 등 이전 모델들은 각 단어가 한 개의 벡터로만 표현됩니다. 이렇게 한 개의 벡터로만 표현된다면 문법구조나 다의어에 따른 뜻 변형을 적절히 반영하기 어렵습니다. 예를 들어서 임베딩 방법론으로 present란 단어를 임베딩하였다고 하면, 이 단어가 선물이라는 뜻으로 사용될 때도 있고 현재라는 뜻으로 사용될 수도 있음에도 불구하고 모두에서 동일한 벡터가 사용됩니다.
그렇다면 같은 표기의 단어라도 문맥에 따라서 다르게 워드 임베딩을 할 수 있으면 자연어 처리의 성능이 더 올라가지 않을까요? 단어를 임베딩하기 전에 전체 문장을 고려해서 임베딩을 하겠다는 것이죠. 그래서 탄생한 것이 문맥을 반영한 워드 임베딩(Contextualized Word Embedding)입니다.
ELMo는 Embeddings from Language Model의 약자로 해석하면 '언어 모델로 하는 임베딩'입니다. ELMo의 가장 큰 특징은 사전 훈련된 언어 모델(Pre-trained language model)을 사용한다는 점입니다. 즉, 엘모는 사전훈련과 문맥을 고려하는 문맥 반영 언어 모델입니다. 또한, 이 representation은 (문장 내) 각 token이 전체 입력 sequence의 함수인 representation를 할당받는다는 점에서 전통적인 단어 embedding과 다릅니다. 이를 위해 이어붙여진 language model(LM)로 학습된 bidirectional LSTM(biLM)로부터 얻은 vector를 사용합니다.
또한, lstm의 마지막 레이어만 사용하는 기존의 방법론과는 달리, ELMo는 lstm의 모든 내부 레이어를 사용해서 만들어지기 때문에 더욱 많은 정보를 사용할 수 있다.
• higher-level LSTM : 문맥을 반영한 단어의 의미를 잘 표현
• lower-level LSTM : 단어의 문법적인 측면을 잘 표현

두 문장을 보시면 read라는 단어가 있는데 왼쪽 문장의 read는 현재형, 뒤쪽 문장은 과거형임을 알 수 있습니다. 뒤쪽 문장의 read가 과거형인 것은 yesterday라는 단어를 통해 알 수 있는데 이전 모델들 같은 경우엔 이 단어를 구분하지 못하지만 ElMo는 이를 구별해낼 수 있습니다.
ELMo
ELMo는
- 전체 문장을 input으로 받고, 그에 대한 각 단어들의 representation 생산
- Character convolution로부터 얻은 biLM의 가장 위 2개 layer의 가중합으로 계산
- 큰 사이즈로 biLM pretrain 시켰을 때 semi-supervised learning 가능
- 쉽게 다른 모델에 붙일 수 있음
biLM
biLM = forward language model + backward language model
N개의 token (t1,t_2, …,t_N)이 있다고 하면
Forward Language Model : (t_1,t_2, …,t(k-1))이 주어졌을 때 token t_k가 나올 확률을 계산하는 것
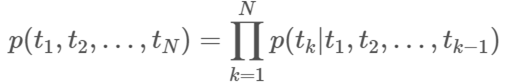
I read a book yesterday라는 문장을 가지고 설명해보도록 하겠습니다.
1. 우선 문장이 주어졌을 때, 단어는 character 임베딩으로 전환됩니다. 그리고 character 임베딩은 첫 lstm 셀로 입력됩니다. Char 임베딩을 사용하는 이유는 첫번째로, 최초 임베딩은 문맥의 영향을 받지 않아야하기 때문입니다. 하지만 이후 레이어들은 문맥에 영향을 받도록 설계되었습니다.
2. 첫 lstm의 출력은 char 임베딩과 residual connection을 가지고 있습니다. 논문에서 자세히 다루진 않았지만, residual connection은 두가지 장점을 가지고 있는데 첫번재로 상위 레이어들이 하위 레이어의 특징을 잃지 않고 활용하도록 도와주고. 두번째로는 학습 시 역전파를 통한 gradient vanishing 현상을 극복하도록 도와줍니다.
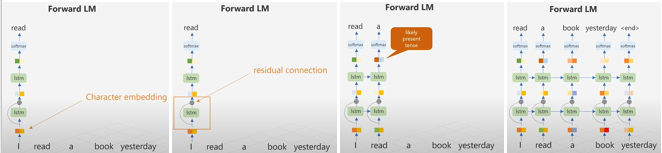
3. Forward LM은 항상 다음 단어를 예측하도록 학습됩니다. 따라서 여기서는 I 라는 단어밖에 없을 때 read가 과거형이라는 정보가 없기 때문에 read를 현재형의 임베딩으로 출력할 가능성이 높습니다. 이런 점을 극복하고자 backward LM도 사용하는 것입니다.
4. Forward LM은 이런식으로 마지막 단어까지 예측합니다.
Backward Language Model: (𝑡(𝑘+1),𝑡(𝑘+2), …,𝑡𝑁)이 주어졌을 때 token 𝑡𝑘가 나올 확률을 계산
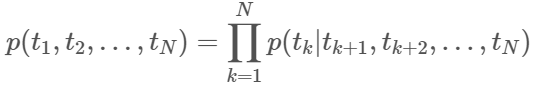
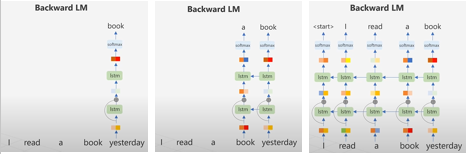
이제 backward LM을 보면 Backward LM은 단순히 Forward LM과 방향만 바뀔 뿐 하는 일은 동일합니다. 따라서 미래의 단어들로 이전 단어들을 예측하도록 학습됩니다.
이전에도 말했듯이 backward LM은 yesterday를 알고 있었기 때문에 read를 과거형으로 구분하기 쉽습니다. 이렇게 backward LM도 끝 단어부터 첫단어까지 예측을 모두 진행합니다.
biLM을 요약해보면 첫째, 최초 임베딩 레이어는 char 임베딩을 사용하고
lstm 레이어 사이에는 residual connection이 존재합니다.
그리고 forward LM은 다음 단어를 예측하도록, backward LM은 이전단어를 예측하도록 학습됩니다.
그리고 이때 두 방향의 log likelihood를 최대화 시키는 방향으로 학습 진행합니다.
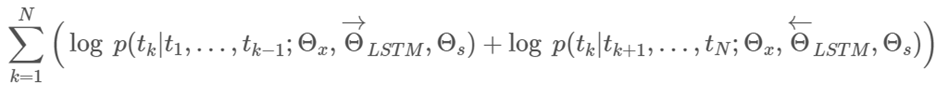
(Θx는 token representation, Θs는 Softmax layer)
ELMo representation
ELMo는 biLM에서 등장하는 중간 매체 layer의 표현들을 특별하게 합친 것입니다. biLM의 L개의 layer는 각 token t_k당 2L+1개의 representation을 계산합니다.
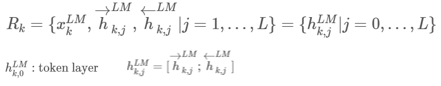
ELMo는 R의 모든 layer를 하나의 벡터로 압축

예시로, 가장 간단한 ELMo 버전은 가장 높은 layer를 취하는 방법이 있습니다.
이 식은 다음과 같이 task에 맞게 또 변형될 수 있습니다.
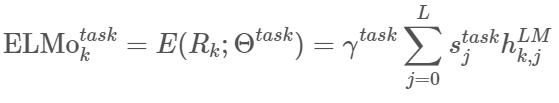
(𝑠^𝑡𝑎𝑠𝑘 : softmax-정규화된 가중치
γ^𝑡𝑎𝑠𝑘: 전체 ELMo 벡터의 크기를 조절하는 역할(scalar parameter))
즉 과정을 다시 정리해보면
(1) BiLSTM layer의 꼭대기층의 token이 softmax layer를 통해 다음 token을 예측하도록 훈련시킨다.
(2) 훈련된 BiLSTM layer에 input sentence를 넣고 각 layer의 representation 합을 가중치를 통해 합한다.
(3) input sentence length만큼 single vector가 생성된다.

ELMo 활용
task 모델을 향상시키도록 biLM을 쓰는 과정
1) biLM을 돌리고 각 단어마다 모든 layer representation을 기록
2) 모델이 이 representation들의 선형결합을 배우도록 함
2-1) biLM이 없는 지도 모델을 고려
2-2) (𝑡1,𝑡_2, …,𝑡𝑁)이 주어지면 pretrain된 단어 임베딩을 사용하여 각 token마다 𝑥𝑘 를 만듦
2-3) 모델이 biRNN 등을 사용해 문맥-의존적 representation ℎ𝑘를 생성
-> ELMo를 지도 모델에 추가하려면
1) biLM의 weight 고정
2) ELMo 벡터 〖𝐸𝐿𝑀𝑜〗𝑘^𝑡𝑎𝑠𝑘와 𝑥𝑘 연결
3) [𝑥𝑘; 〖𝐸𝐿𝑀𝑜〗𝑘^𝑡𝑎𝑠𝑘]를 task RNN에 전달
SNLI, SQuAD 등의 task에서는 hk를 [xk ;ELMo taskk] 로 대체하면 성능이 더 향상되었다.
또한 ELMo에 dropout을 적용하는 것과, λ||w||22를 loss에 더해 ELMo weight를 정규화하는 것이 ELMo weight에 inductive bias를 유도하여 모든 biLM layer의 평균에 더 가까워지도록 하여 성능에 도움을 주는 것을 발견하였다.
Evaluation
주요 task에 대한 성능 비교

6개의 NLP down task에 대하여 단지 ELMo를 추가하는 것만으로도 SOTA(최고성능)보다 좋은 성능을 보이는 것을 알 수 있습니다.
(Question answering(질의응답), Textual entailment = 주어진 전제에서 가설이 참인지 판단하는 문제, Semantic role labeling(의미역 결정), Coreference resolution(상호참조), Named entity extraction(개체명 인식), Sentiment analysis(감성 분석))
λ 에 대한 성능 비교
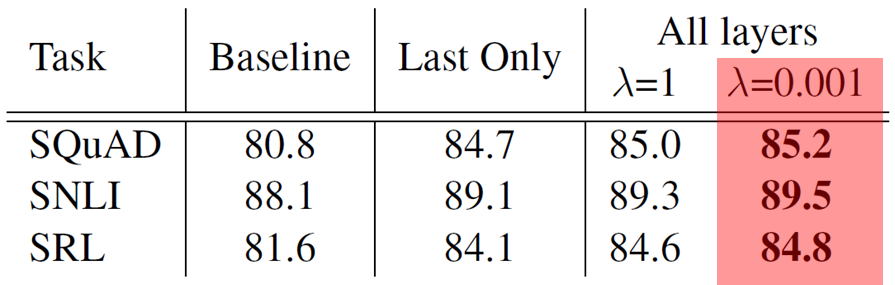
- 마지막 layer만 쓰는 것보다 모든 layer를 쓰는 것이 더 좋음
- λ를 작게 하는 것이 더 좋은 성능을 나타내며 task의 종류에는 크게 영향받지 않는 것을 보임
ELMo 위치에 대한 성능 비교
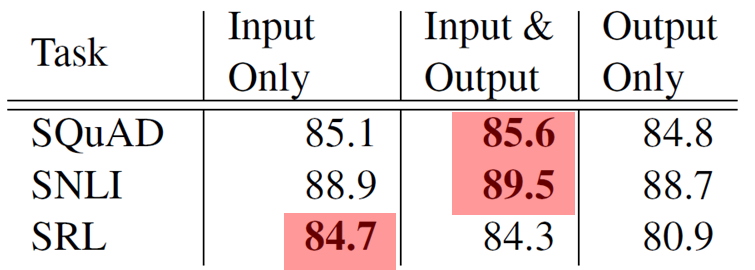
SQuAD, SNLI에서는 biRNN의 Output에도 ElMo를 추가하는 것이 더 좋은 성능을 보임
-> Task에 따라 적절한 architecture가 있다고 생각할 수 있음.
Glove와 ELMo에서의 “play”

Glove에서는 “play”에 관련된 단어들로 스포츠와 유사한 것들이 나옴
biLM에서는 “play“와 유사한 의미로 사용되는 문장이 유사한 것으로 나옴
Word-Sense Disambiguation - 단어 중의성 해소
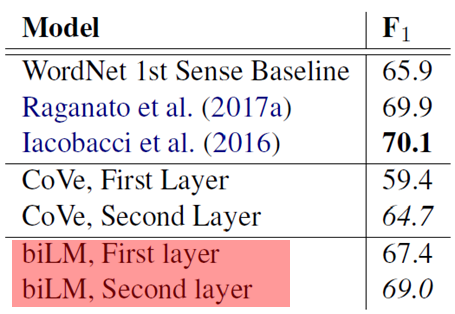
- BiLM이 CoVe보다 성능이 우수함
- BiLM의 first layer를 이용하는 것보다 Second layer를 이용하는 것이 성능이 우수
-> 높은 layer일수록 문맥 정보 학습
POS tagging-형태소 분석
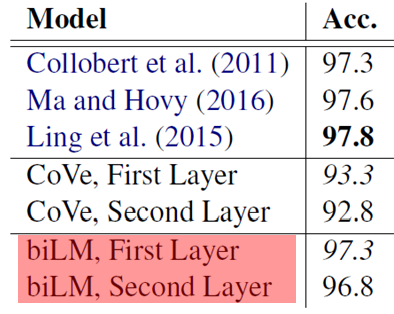
- BiLM이 CoVe보다 성능이 우수함
- BiLM의 first layer가 second layer보다 성능이 우수
-> 낮은 layer일수록 문법 정보 학습
training set 크기에 따른 성능 비교

모델에 ELMo를 추가했을 때가 그렇지 않을 때보다 학습속도가 빠름
더 작은 훈련 세트를 더 효율적으로 훈련함
학습된 weights 시각화
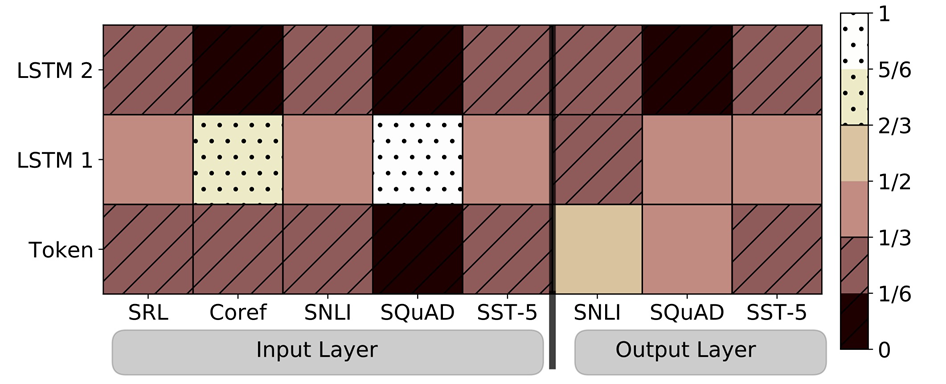
- 소프트맥스 정규화된 학습 계층 가중치를 시각화한 것
- Input Layer에서는 첫번째 biLSTM layer를 선호
- Output Layer에서는 weight가 균형있게 분배되었지만, 낮은 layer를 좀 더 선호
Conclusion
- biLM으로부터 고품질의 깊은 문맥의존 representation을 학습하는 일반적인 접근법을 도입함.
- 광범위한 NLP작업들에서 ELMo를 적용했을 때 큰 향상이 있는 것을 볼 수 있음.
- biLM 계층이 문맥 내 단어들에 대한 다른 유형의 구문 및 의미 정보를 효율적으로 인코딩하고, 모든 계층 사용 시 전반적인 작업 향상이 있음.
참고자료:
https://greeksharifa.github.io/nlp(natural%20language%20processing)%20/%20rnns/2019/08/20/ELMo-Deep-contextualized-word-representations/
https://wikidocs.net/33930
https://www.youtube.com/watch?v=YZerhaFMPTw
