논문 리뷰
1.Enriching Word Vectors with Subword Information(FastText) 논문 리뷰

FastText 논문 : https://arxiv.org/abs/1607.04606 Abstract 기존 모델(word2vec)은 단어마다 다른 벡터를 할당하여 단어의 형태를 무시하게 된다. 이는 큰 어휘들과 많은 드물게 사용되는 단어들에서 한계가 있다. 본 논문에
2.Deep contextualized word representations(ELMo) 논문 리뷰

본 논문 : https://arxiv.org/abs/1802.05365ELMo는 2018년에 제안된 새로운 워드 임베딩 방법론입니다. ELMo라는 이름은 세서미 스트리트라는 미국 인형극의 케릭터 이름이기도 한데, 뒤에서 배우게 되는 BERT나 최근 마이크로소프
3.Attention Is All You Need(Transformer) 논문 리뷰
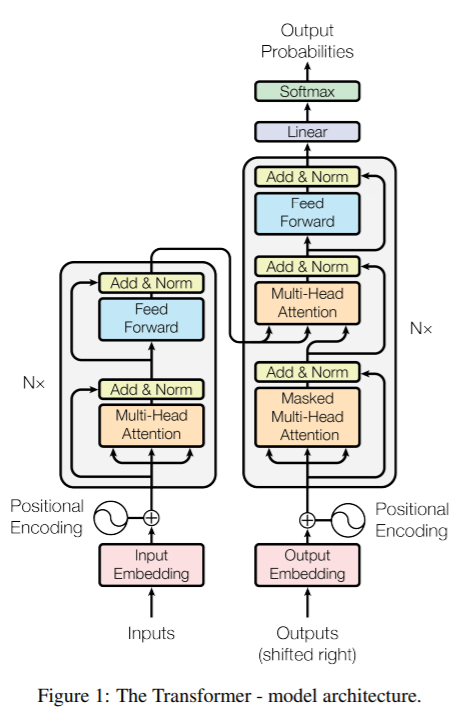
Transformer 논문 : https://arxiv.org/abs/1706.03762RNN, LSTM, Gated RNN이 sequence modeling에서 많이 사용됨.(1) Recurrent modelsymbol position에 따라서 계산token
4.Improving Language Understanding by Generative Pre-Training(GPT1) 논문 리뷰
.png)
대부분의 딥러닝 모델은 labeled된 데이터를 바탕으로 지도학습을 하는데, 이는 레이블이 지정되지 않은 데이터(unlabeled data)보다 훨씬 적은 수이기 때문에 unlabeled data의 언어 정보를 활용한다면 훈련에 필요한 시간과 비용을 절약할 수 있다.
5.XLNet: Generalized Autogressive Pretraining for Language Understanding
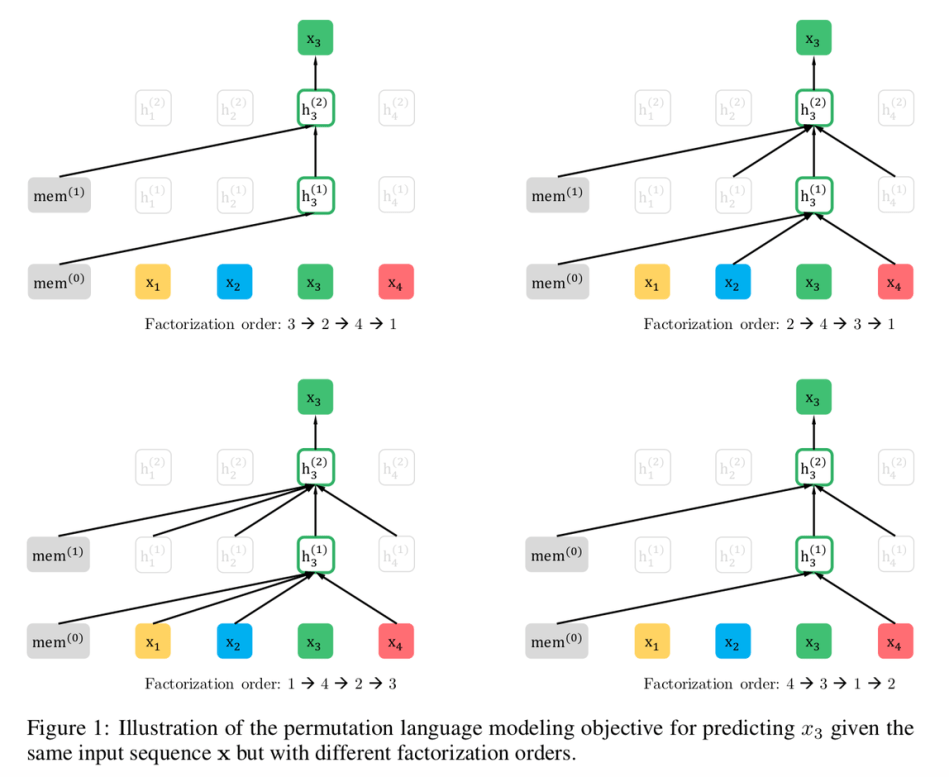
논문 링크 : https://arxiv.org/abs/1906.08237AR(AutoRegressive) language model앞의 token을 이용해 문장의 확률 분포를 알아냄순방향(forward)든 역방향(backward)든 단방향 contextbidi
6.Multi-Task Deep Neural Networks for Natural Language Understanding(MT-DNN)
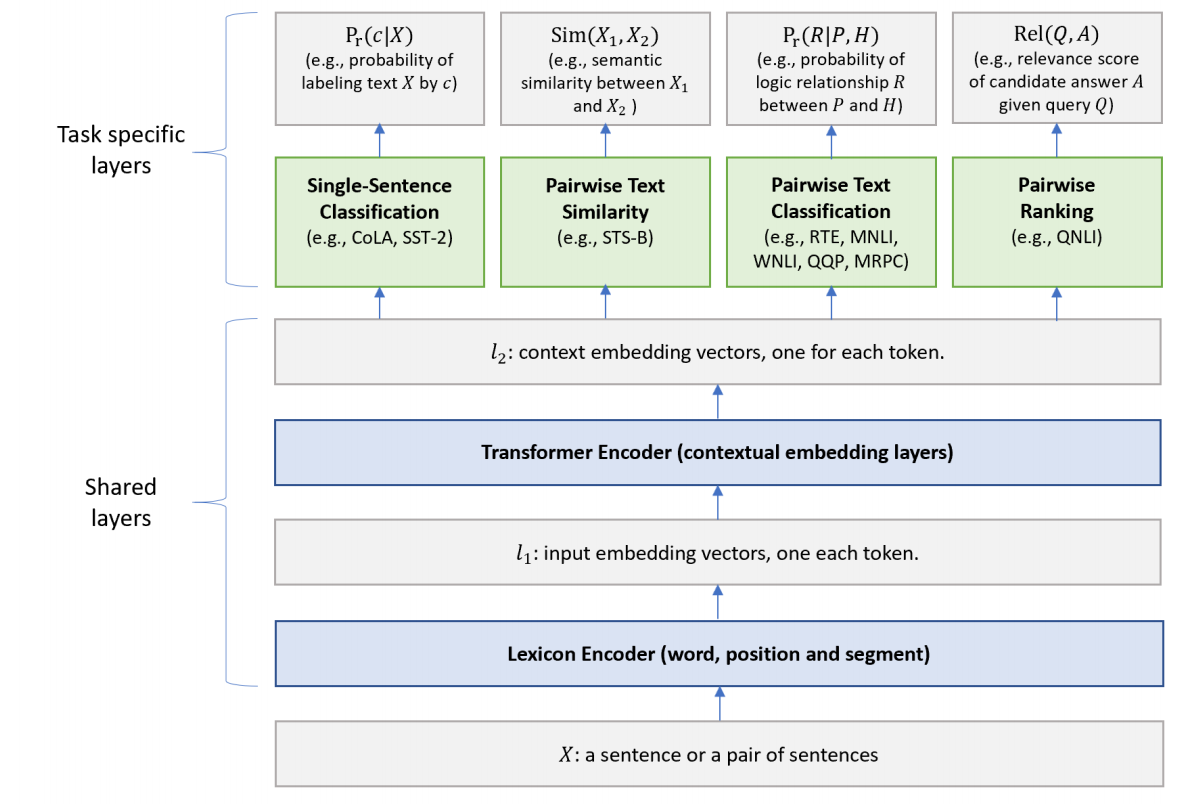
논문 : https://arxiv.org/pdf/1901.11504.pdfMT-DNN은 BERT에 Multi-task learning(GLUE TASK 9개 활용)을 수행하여 성능 개선한 모델다양한 Task의 Supervised Dataset을 모두 사용하여
7.GAN(Generative Adversarial Network)
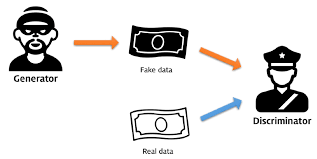
GAN 논문 링크(https://www.notion.so/GAN-Generative-Adversarial-Network-8cb52d98f6e646bb9653a4a05be07a0c이산확률분포 : 확률변수 X의 개수를 정확히 셀 수 있을 때 (Ex. 주사위)연속확
8.StyleGAN(A Style-Based Generator Architecture for Generative Adversarial Networks)
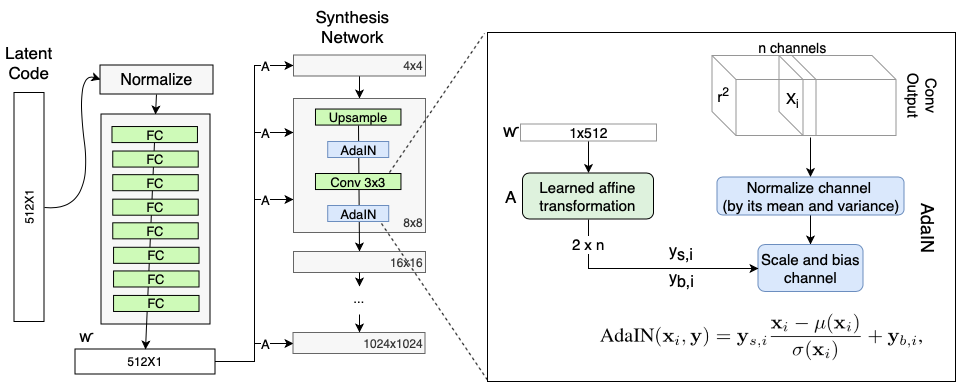
논문 링크 styleGAN : 고화질 이미지 생성에 적합한 아키텍쳐 제안 PGGAN 베이스라인 아키텍처의 성능을 향상시킴 style transfer에서 아이디어를 얻음 Discriminator와 loss function은 수정하지 x Disentanglement 특
9.StyleGAN2(Analyzing and Improving the Image Quality of StyleGAN)
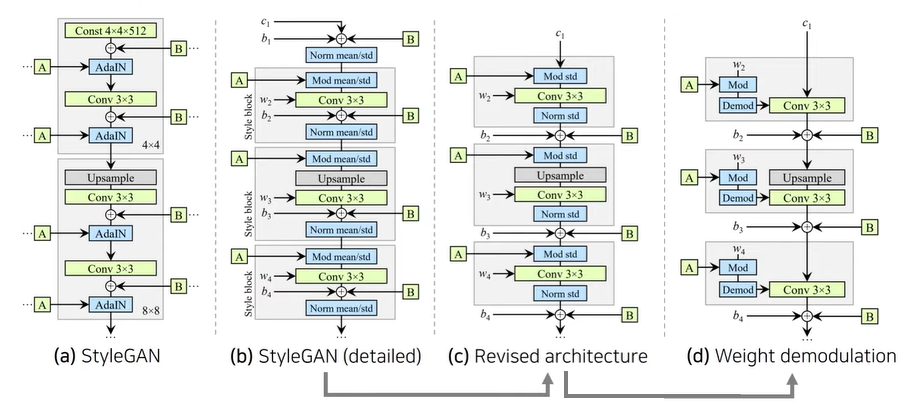
논문 링크성능 개선 : 기존의 StyleGAN보다 더 높은 품질의 이미지를 생성하고, 이미지를 부드럽게 변경할 수 있다.기존 아키텍처의 blob-like artifact와 phase artifact 문제 해결inversion(=역함수, 반대로 이미지를 넣어서 laten