프로젝트 주제 : [AWS Infra - Airflow] 자취를 시작하는 분들을 위한 원룸 추천 웹 서비스 제작
해당 프로젝트에서 Infra 역할을 맡아 Airflow를 위한 AWS Architecture를 설계하고 관련 서비스들을 구축해보았습니다.
분산 처리를 위해 CeleryExecutor를 도입한 과정과 그에 관한 설정 값들을 정리해보겠습니다.
AWS Architecture
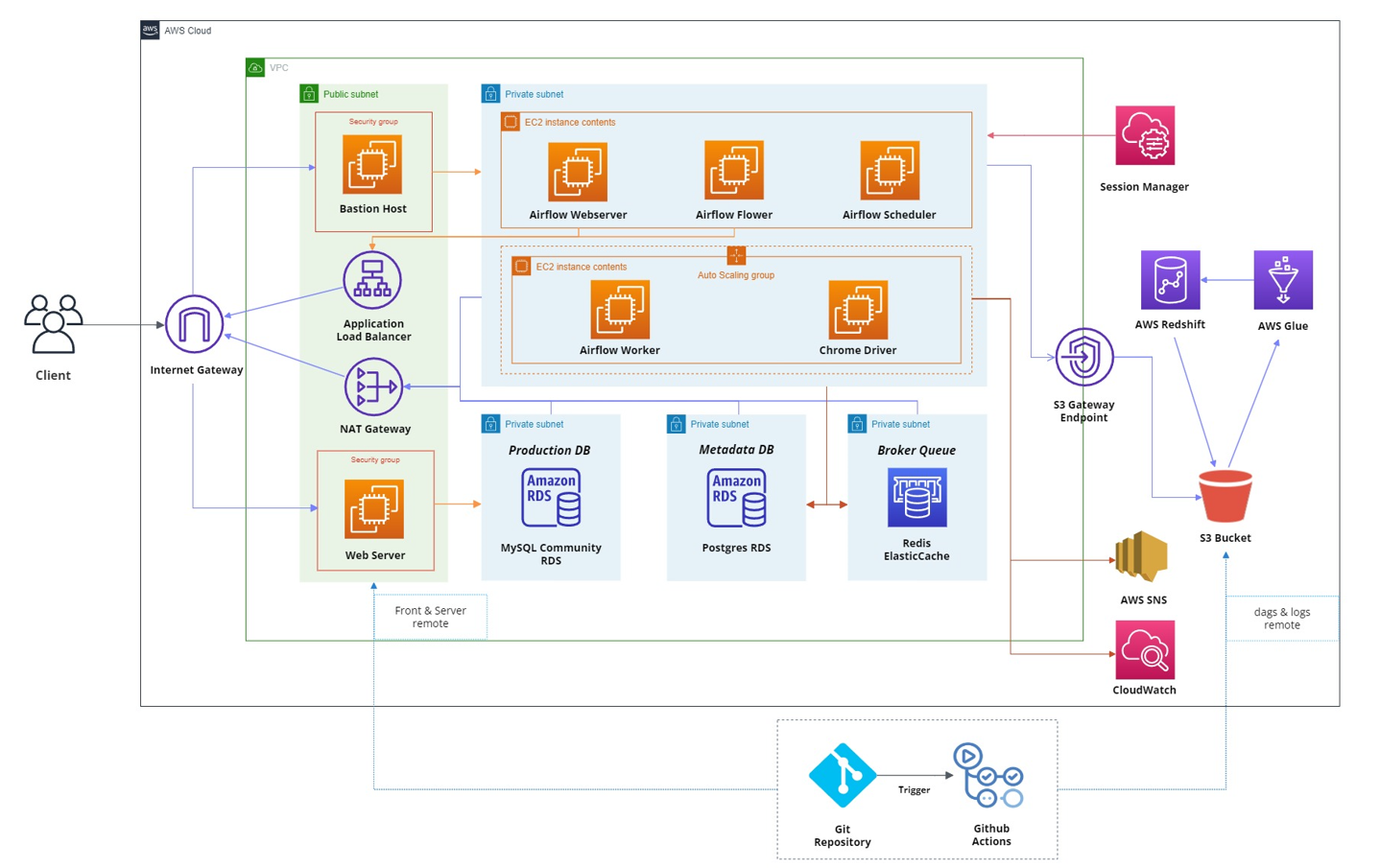
프로젝트를 진행하며 위와 같이 AWS Architecture를 구성해보았습니다.
EC2 내에서 Docker 기반으로 Airflow 환경을 구축하였고,
상단의 EC2 instance contents는 Docker Container들을 표현한 것입니다.
-
Airflow Webserver와 Flower
-
Airflow Webserver : 웹 기반 사용자 인터페이스를 제공하여,
DAGs의 workflow와 metadata를 관리하고 모니터링하는데 사용하였습니다. -
Airflow Flower : Celery용 웹 기반 모니터링 도구로,
Airflow에서 사용되는 워커의 상태와 작업을 관리하는데 사용하였습니다.
이 Webserver와 Flower를 ALB(Applicatin Load Balancer)로 배포하여,
허용된 사용자에 한해 SSH, SSM 없이 쉽게 접속할 수 있게 하였습니다. -
-
Bastion Host와 Session Manager 접속
-
Bastion Host : Private subnet에 위치한 Airflow 서버에는 보안을 위해 Bastion Host를 통하여 SSH 접속이 가능하게 하였습니다.
-
SSM(AWS Session Manager) : SSM도 사용하여 서버에 보안 키 없이 쉽게 접속할 수 있도록 하였습니다.
SSM를 통해 EC2 인스턴스에 대한 안전한 접속을 제공할 뿐 아니라 Lambda 함수를 통해 호출하여 인스턴스에 명령을 내리는데도 사용하였습니다.
-
-
Airflow Worker (Auto Scaling Group)
다수의 worker를 통한 Task를 분산 처리를 위해 Celery Executor를 사용하였습니다.EC2 - Auto Scaling Group을 통해 worker의 scale in/out이 자동으로 이뤄질 수 있도록 설정하였습니다.
-
Result Backend와 Message Broker (RDS, Elasticache)
Celery Executor를 사용하기 위해선 Local Executor와 달리 Result Backend와 Message Broker가 필요합니다.이를 위해 RDS와 Elasticache를 생성하여 Airflow와 연결해주었습니다.
-
WebServer와 Production RDS
Airflow와 무관한 웹 서비스용이니 제외하고 봐주시면 될 것 같습니다. -
Chrome Driver
Airflow 내에서 selenium이 크롬 드라이버를 통해 크롤링할 수 있도록
추가해준 Docker Container입니다.Airflow 내에서 selenium을 사용하기 위해선 살짝 복잡한 절차를 거쳐야하는데,
이 복잡한 절차를 간소화하고자, container 위에 크롬 드라이버를 띄워 포트포워딩을 통해 이를 연결하여 사용했습니다. -
AWS Redshift의 서브넷에 관한 설정
AWS Redshift는 보안을 위해 Private subnet에 위치시키는 것이 옳습니다.Airflow 시스템과 동일한 VPC 내에 집어 넣었어야했으나, 프로젝트 당시 Redshift의 보안성을 고려하지 못하고 Public에 위치시켜 진행을 했습니다.
따라서, 이 부분은 수정되야할 사항입니다.
VPC
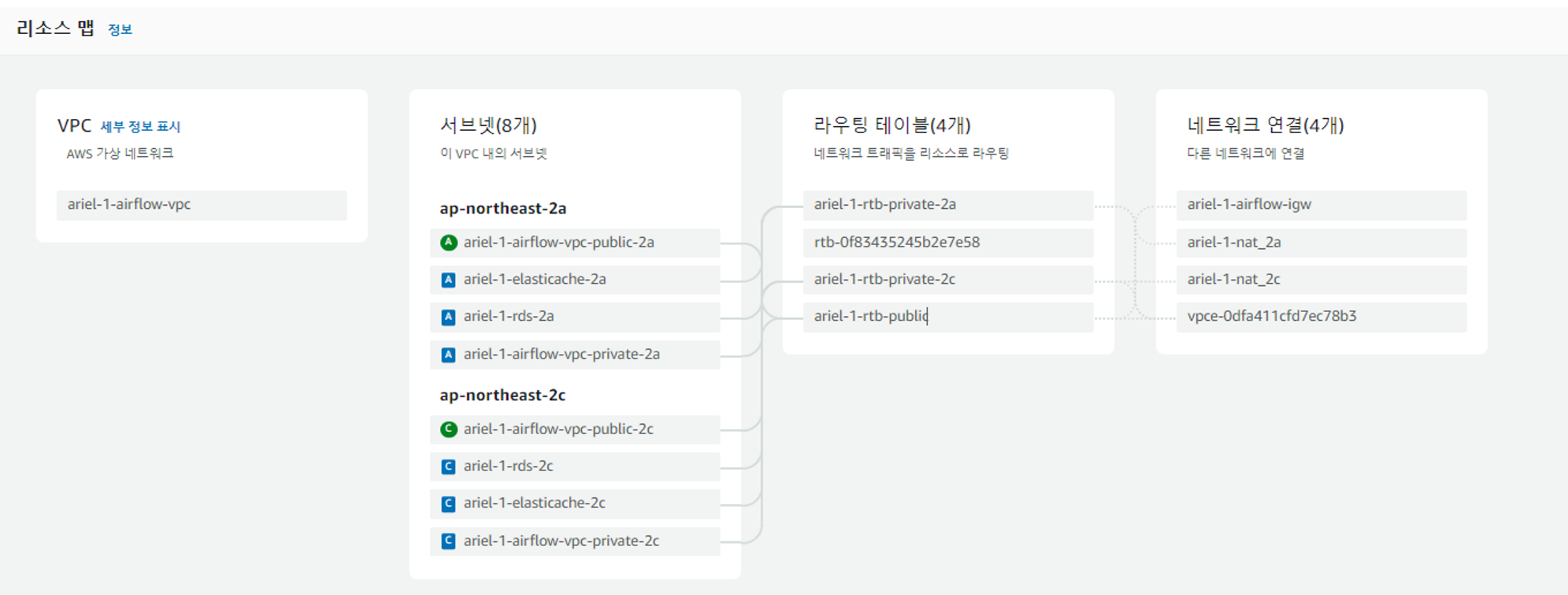
AWS VPC는 위와 같이 구성했습니다.
Bastion host 용도로 사용할 EC2를 Public subnet에 위치시켰고,
그 외 서비스들은 Private subnet에 위치시켰습니다.
Private subnet의 NAT gateway를 가용영역 별로 위치시키기 위해
라우팅 테이블에서부터 a와 c로 나누어서 분리하여 생성했습니다.
RDS - Postgres ( Airflow Metadata DB )
Airflow에는 두 가지 종류의 Relational Metadata DB가 있습니다.
airflow.config를 기준으로,
SQL_ALCHEMY_CONN과RESULT_BACKEND가 이에 해당합니다.
SQL_ALCHEMY_CONN은 Airflow webserver에서 지정한 variables, connections 등과 같은 기본적인 Airflow 시스템에 꼭 필요한 메타데이터들을 저장하는 데이터베이스입니다.
RESULT_BACKEND는 Celery Executor에서 사용하는 Metadata DB로 Task들의 상태 정보를 기록하여 다수의 Worker 간의 충돌 없이 분산 처리를 가능하게 합니다.
저의 경우, SQL_ALCHEMY_CONN과 RESULT_BACKEND 모두 동일하게 외부 DB인 Amazon RDS - PostgresSQL로 설정하여 관리해주었습니다.
엔진 유형으로 PostgreSQL,
클래스는 db.t3.small,
VPC와 서브넷은 위에서 생성한 VPC대로 선택해주었습니다.
또한, Airflow 시스템을 세팅할 Private subnet의 EC2와 연결해주었습니다.
ElastiCache - Redis (Message Broker)
Message Broker로 Redis를 선택한 이유
Message Broker로는 주로 redis, kafka, rabbitMQ가 사용됩니다.
-
RabbitMQ
큰 메시지를 전달하는 경우에 유리 -
Redis
In-Memory Cache 기반으로 빠르게 메시지를 전달 가능 -
Kafka
대용량 스트리밍 데이터를 전달하는데 유리
제가 사용할 Message Broker의 역할은 수행해야할 Task들을 받아서
다수의 Worker들이 가져갈 수 있도록 중간 역할을 해주는 것입니다.
이 Task의 크기가 크지 않을 뿐더러, Task의 수가 아주 많지도 않고 스트리밍이라고 보기도 어렵습니다.
이러한 점들을 생각했을 때, Redis가 가장 적절해보였습니다.
또한, AWS를 지원받는 입장에서 사용 가능한 서비스들의 목록이 한정되어있어
RabbitMQ와 Kafka를 사용하려면 EC2 내에서 구축을 해야하는 상황이였습니다.
구축에 드는 시간과 비용을 생각해봐도 이는 비효율적인 방법이기에,
ElastiCache에서 지원하는 Redis를 이용하는 것이 가장 간편하고 현실적이라 생각했습니다.
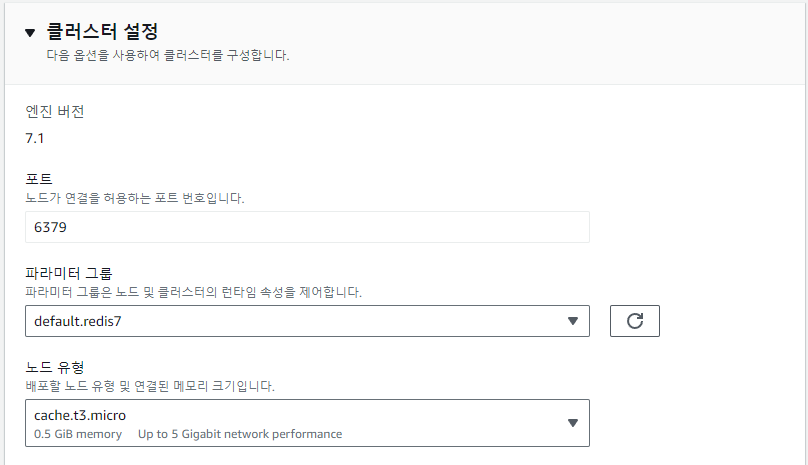
ElasticCache 생성
ElastiCache 생성 옵션으로는 서버리스가 아닌 자체 캐시 설계로,
노드 유형은 cache.t3.micro,
엔진은 Redis,
VPC와 서브넷은 위에서 생성한 VPC 대로 설정해주었습니다.
EC2
