이전 포스팅에 이어서 Spark의 분산 처리에 대해 작성하겠습니다.
📖 2. Partition 단위의 분산 처리 방식
Spark는 대용량 데이터를 병렬로 처리하기 위해
데이터를 Partition이라는 단위로 나누어 처리합니다.
Partition은 Spark의 성능과 분산 처리 효율을 좌우하는 중요한 요소입니다.
📃 Partition이란?
Partition은 단어 의미 그대로, 데이터를 논리적으로 나눈 조각입니다.
대용량 데이터를 한번에 처리하는 것은 너무나 무겁고 오랜 시간이 걸립니다.
Spark는 이를 해결하고자 데이터를 Partition이라는 단위로 나누어 처리하게 됩니다.
즉, Partition은 Spark의 분산 병렬 처리의 최소 단위로
하나의 Partition은 하나의 Task로 처리된다고 볼 수 있습니다.
그리고 중요한 점은 Partition은 실제 물리적인 블록으로 구성된 것이 아닌
논리적으로 나눈 처리 단위라는 것입니다.
실제 물리적인 블록으로 구분되어 저장되는 것은 HDFS Block입니다.
-
HDFS Block
- Hadoop의 물리적 저장 단위 (default : 128MB)
- 파일 저장 시 생성
-
Partition
- Spark의 논리적 처리 단위
- RDD 생성 시 생성
HDFS Block과 Partition의 크기는 서로 동일할 수도 다를 수도 있습니다. (조정 가능)
📃 데이터 로딩 시 Partition 분할
Spark에서 데이터를 처리하는 경우, 일반적으로 RDD를 생성하게 됩니다.
DataFrame은 RDD 기반에 Catalyst Optimizer + Schema가 더해진 형태기 때문에,
RDD에 포함하겠습니다.
이 RDD는 보통 textFile()을 통해 생성하게 됩니다.
rdd = sc.textFile("hdfs://path/to/file.txt")이 textFile()은 내부적으로 Hadoop의 Format을 사용하기 때문에
결과적으로 HadoopRDD를 생성합니다.
HadoopRDD가 생성될 때 입력 데이터를 Hadoop의 논리적 단위인 inputSplit으로 분할합니다.
별도의 설정을 하지 않았다면 단위는 HDFS Block의 크기와 동일하게 됩니다.
이 inputSplit 객체를 Wrapping하여 Spark에서 처리할 수 있도록 만든 것이 바로 Partition입니다.
정리하면, 데이터를 로딩하는 과정에서부터 Partition으로 나눠서 로딩을 하게 된다는 것이죠.
-> RDD 생성 시 Partition으로 분할 저장 된다.
📃 Transformation
그럼 이제 이 나눈 Partition들로 어떻게 데이터 처리가 이뤄지는 걸까요?
Transformation
먼저, Spark의 Transformation에 대해 설명하겠습니다.
Transformation이란, 기존의 RDD을 수정/추가를 하여 새로운 RDD를 만드는 과정을 의미합니다.
Lazy Evaluation
그런데 Spark의 Transformation은 특수한 전략을 가지고 있는데요.
바로 Lazy Evaluation입니다.
Lazy Evaluation은 작업을 명령했을 때,
즉시 실행되지 않고 DAG라는 논리적인 실행 계획을 만들어두고 대기합니다.
그렇게 기다리다 Action 연산이 호출되었을 때만 실제 연산이 실행되는 전략인 것이죠.
그렇게 함으로써 얻을 수 있는 장점들은
1. 불필요한 연산을 방지할 수 있고
2. 이 연산들을 한번에 묶어 최적화 하기 용이합니다. (Catalyst Optimizer)
그럼 이제 실제 Transformation 과정을 살펴보겠습니다.
Transformation 연산은 여러가지들이 있는데
이를 크게 두 가지 경우로 나눠볼 수 있습니다.
Shuffling 되는 경우와 되지 않은 경우
Narrow Transformation - Non-Shuffling
Narrow Transformation의 경우 Shuffling이 일어나지 않기 때문에
Partition의 구조가 변하지 않습니다.
map, filter 연산이 여기에 속합니다.
map은 레코드 별로 값을 변환하는 연산이고,
filter는 조건을 만족하는 레코드만 반환하는 연산이죠.
이러한 연산들의 공통점은 각 레코드에만 해당 연산을 적용할수가 있다는 것입니다.
그러므로 Partition을 합칠 필요 없이 각 Partition에서 별도로 처리가 가능합니다.
Partition 내의 데이터는 변환되었지만 Partition 구조 자체는 유지된다는 것이죠.
이러한 경우는 간단합니다.
단순히 Task 1개당 Partition 1개에 배치하여 병렬 처리를 수행하면 됩니다.
그렇게 생성된 새로운 RDD의 Partition 수는 동일하게 되겠죠.
rdd = sc.textFile("hdfs://path/to/file.txt") # 4 partitions
rdd2 = rdd.map(lambda x: x.upper()) # 여전히 4 partitionsWide Transformation - Shuffling
문제는 Shuffling되는 경우입니다.
Shuffling은 네트워크를 통해 데이터를 재분배하는 과정이라 할 수 있습니다.
repartition, coalesce, groupByKey, join 등이 여기에 속합니다.
일반적인 join 연산을 생각해보면 서로 다른 RDD-1, RDD-2를 특정 조건 하에 합쳐서
새로운 RDD-3를 만들어내게 됩니다.
이걸 Partition 입장에서 생각해보겠습니다.
RDD-1은 Partition A1, A2, A3를 보유하고 있고
RDD-2는 Partition B1, B2, B3를 보유하고 있다고 가정하면
A1은 B1, B2, B3와 비교 후 결합해야하고 A2, A3도 각각 B1, B2, B3와 비교해야합니다.
이렇게 Partition간의 데이터 이동이 발생하는 과정을 바로 Shuffling이라고 합니다.
Spark에서는 이 Shuffling을 두 가지 단계로 분할하여 처리합니다.
바로 Shuffle Write와 Shuffle Read입니다.
먼저, Wide Transformation은 내부적으로 반드시 key 기반의 데이터 재분배 작업이 필요합니다.
즉, Map을 통해 key-value 형태로 바꿔주는 작업이 선행되어야한다는 것이죠.
이렇게 key-value로 바꾼 다음에 Shuffle Write가 실행됩니다.
Shuffle Write란
Map Task가 계산한 key-value 데이터를 Partition 별로 나눠서, 로컬 디스크에 저장하는 단계입니다.
여기서 말하는 Partition은 초기 RDD 생성시 만들어진 기존의 Partition이 아니라,
Reduce 작업을 수행할 때 필요한 특정 기준으로 나누어진 새로운 Partition을 의미합니다.
( Reduce : 모든 요소를 하나의 값으로 축소하기 위해 사용자 정의 함수를 적용하는 과정 )
Shuffle Write 단계에서 이 새로운 Partition을 생성하는 것이 아닙니다.
그저 데이터를 새로운 Partition에 할당하기 쉽게 분류만 해서 저장하는 것이죠.
이 Partition에 대해서는 잘 와닿지 않을 수 있으니 잠시 후 예시를 통해 설명하겠습니다.
Shuffle Read란
Reduce Task가 필요한 Partition 데이터를 여러 Executor로부터 네트워크로 가져오는 단계
Reduce Task가 필요한 Partition 데이터에 대해 Join 연산을 예시로 들어서 설명하겠습니다.
id를 기준으로 join을 수행한다고 한다면,
데이터 상의 id의 종류가 여러 개가 존재하겠죠.
그 id의 종류를 가용 가능한 Task의 수 만큼 공평하게 나눌 것입니다.
그렇게 나눠진 id 집합들을 각각 새로운 Partition에 할당하는 것이죠.
예를 들어,
Partition 1에 id1, id3, id5가 할당되고
Partition 2에 id4, id6, id8이 할당되는 방식입니다.
나누는 방식에 대해서는
partition = hash(key) % numPartitions 이런 식으로 사용된다고 보시면 됩니다.
이렇게 나누어진 Partition이 바로 Shuffle Write에서 언급했던 새로운 Partition입니다.
이렇게 나뉘어진 Partition이 어떻게 사용되느냐 하면,
Reduce Task1이 Partition1을 담당한다고 생각해보겠습니다.
Partition1에는 id1, id3, id5가 할당되어있죠.
Shuffle Write에서 key가 id1, id3, id5인 데이터들을
Partition1이라고 분류하여 저장해둔 상태입니다.
Partition1에 해당되는 데이터들을 네트워크 통신을 통해 모두 모아 메모리에 로딩합니다.
각 Reduce Task가 이와 동일한 방식으로 수행합니다.
그러면 새로운 모든 Partition이 완성이 될 것입니다.
여기까지가 바로 Shuffle Read입니다.
그리고 이후에 Partition들에 각각 Reduce 연산 수행하여
최종 결과를 내고 출력하는 것이죠.
📃 예시 - Shuffle Hash Join의 경우
PySpark, RDD, Equi Join, Shuffle Hash Join 상황을 예시로 하여
Partition을 통해 Shuffling 과정이 어떻게 분산 처리되는지
총 정리를 해보겠습니다.
from pyspark.sql import SparkSession
# SparkSession 생성
spark = SparkSession.builder \
.appName("Shuffle_Hash_Join") \
.getOrCreate()
# 데이터 정의 (id는 0~8, id=4에 데이터가 집중됨)
data_a = [
{"id": 0, "name": "TOM"}, {"id": 1, "name": "LISA"}, {"id": 2, "name": "JUNE"}, {"id": 3, "name": "ERIC"},
{"id": 4, "name": "KIM"}, {"id": 4, "name": "LEE"}, {"id": 4, "name": "PARK"},
{"id": 4, "name": "CHOI"}, {"id": 4, "name": "JEONG"}, {"id": 4, "name": "YOON"},
{"id": 5, "name": "AMY"}, {"id": 6, "name": "PAUL"}
]
data_b = [
{"id": 0, "item": "BOX"}, {"id": 2, "item": "NOTE"}, {"id": 3, "item": "PEN"},
{"id": 4, "item": "BOOK"}, {"id": 4, "item": "FOLDER"}, {"id": 4, "item": "BINDER"}, {"id": 4, "item": "CASE"},
{"id": 5, "item": "BAG"}, {"id": 7, "item": "CUP"}, {"id": 8, "item": "MOUSE"}
]
# RDD 생성 - Partition 4개
rdd_a = spark.sparkContext.parallelize(data_a,4)
rdd_b = spark.sparkContext.parallelize(data_b,4)
# Key-Value 형태로 변환
rdd_a_kv = rdd_a.map(lambda x: (x["id"], x["name"])) # (id, name)
rdd_b_kv = rdd_b.map(lambda x: (x["id"], x["item"])) # (id, item)
# Join 실행
rdd_joined = rdd_a_kv.join(rdd_b_kv)각 Worker는 하나의 Executor를 가지고 있고 Worker가 2개인 상황을 가정해보겠습니다.
DAG Scheduler에 의해 Stage가 생성되고
Stage 0에서 RDD A를,
Stage 1에서 RDD B를,
Stage 2에서 Reduce를 순차적으로 처리할 것입니다.
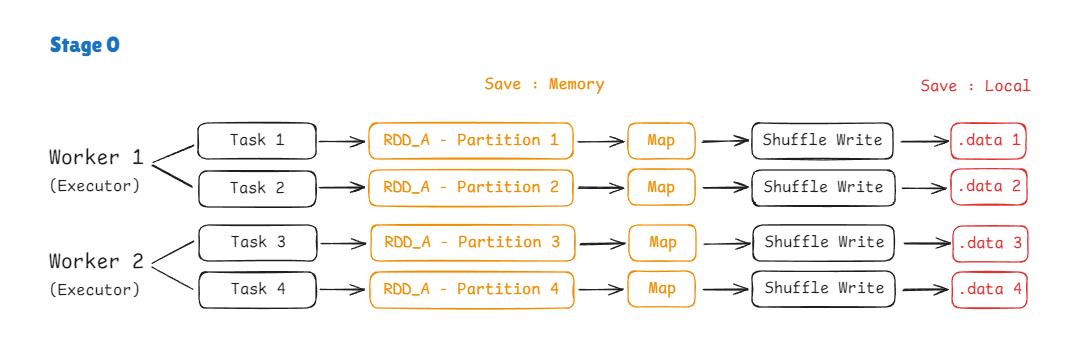
Task 분배 및 Partition 생성
RDD 생성 시 Partition의 수를 4개로 지정했으니
Task도 동일하게 4개가 만들어질 것이고
Worker가 2개이니 2개씩 나눠서 병렬로 수행됩니다.
여기서의 Partition은 Local에 저장되는 것이 아니라 메모리 상에 로딩되어 있는 상태입니다.
Map
Shuffling 작업은 데이터를 다른 Partition으로 이동시켜야합니다.
이때, 어느 Partition으로 보낼 지 계산이 필요하기 때문에 Key 기반의 데이터 재분배 작업이 필수적입니다.
따라서, 각 Partition에 Map을 적용하여 데이터를 key-value 형태로 만듭니다.
ex) [(0, "TOM"), (1, "LISA"), (2, "JUNE"), (3, "ERIC")]
Shuffle Write
이제 Shuffle Write 작업입니다.
Join_key가 id로 지정되어 있으니, id를 기준으로 데이터 재분배를 위한 Partition 구분을 진행합니다.
HashPartitioner를 통해 각 key가 어느 Partition으로 이동될 지 계산합니다.
Partition을 총 4개로 설정했으므로,
partition(key) = hash(key) % 4
가정을 하여 아래와 같이 설정됐다고 하겠습니다.
| Key(id) | Hash | New Partition |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 4 | 0 |
| 2 | 9 | 1 |
| 3 | 2 | 2 |
| 4 | 6 | 2 |
| 5 | 8 | 0 |
| 6 | 3 | 3 |
| 7 | 7 | 3 |
| 8 | 5 | 1 |
위 표 대로 Partition에 할당된 key를 표현하면 아래와 같습니다.
| New Partition | Key(id) |
|---|---|
| 0 | 1, 5 |
| 1 | 0, 2, 8 |
| 2 | 3, 4 |
| 3 | 6, 7 |
자 그러면 Partition 구분이 어떻게 이뤄지는지 살펴보겠습니다.
Task 1이 담당하고 있는 기존 Partition 1을 예시로 만들어보겠습니다.
Partition 1 = [(0, "TOM"), (1, "LISA"), (2, "JUNE") 이라고 했을 때
TOM과 JUNE은 id가 0,2이므로 New Partition 1에 속합니다.
LISA는 id가 1이므로 New Partition 0에 속합니다.
이걸 표현하면 이렇게 되겠죠.
데이터가 이동해야 할 Partition이 아래와 같이 구분이 됩니다.
{
partition_0: [
(1, "LISA")
],
partition_1: [
(0, "TOM"),
(2, "JUNE")
],
partition_2: [],
partition_3: []
}그럼 이걸 어떻게 저장할 것이냐 하면,
.data파일과 .index파일을 만들것입니다.
.data 파일은 네트워크 전송을 위해 위 내용을 직렬화,
Serailizer에 의해 압축된 바이너리 형태로 변환할 것입니다.
이 직렬화 된 내용은 연속적이기 때문에,
특정 파티션의 데이터만 읽기 위해선 partition이 구분되는 위치에 대한 정보가 필요합니다.
이러한 정보, partion 0이 어디에서 시작되고 크기가 얼마인지를
.index 파일을 통해 저장합니다.
그러면 .data, .index를 통해 원하는 특정 파티션만의 데이터를 읽어들일 수 있겠죠.
이 .data와 .index는 각 Worker의 Local에 저장이 됩니다.
경로는 <SPARK_LOCAL_DIRS>/blockmgr-*/shuffle_*/...이고
worker에 task가 2개씩 존재하므로 파일은 이런 식으로 저장됩니다.
# worker 1' local
shuffle_rdd_a_1.index
shuffle_rdd_a_1.data
shuffle_rdd_a_2.index
shuffle_rdd_a_2.data# worker 2's local
shuffle_rdd_a_3.index
shuffle_rdd_a_3.data
shuffle_rdd_a_4.index
shuffle_rdd_a_4.data그리고 이 파일들은 Block Manager에 의해 관리됩니다.
Block Manager는 이 파일의 특정 Partition을 요청할 경우,
이를 전송해주는 역할을 수행합니다.
여기까지가 Shuffle Write 과정입니다.
Stage 1도 RDD_B를 대상으로 할 뿐 이와 동일하게 진행됩니다.
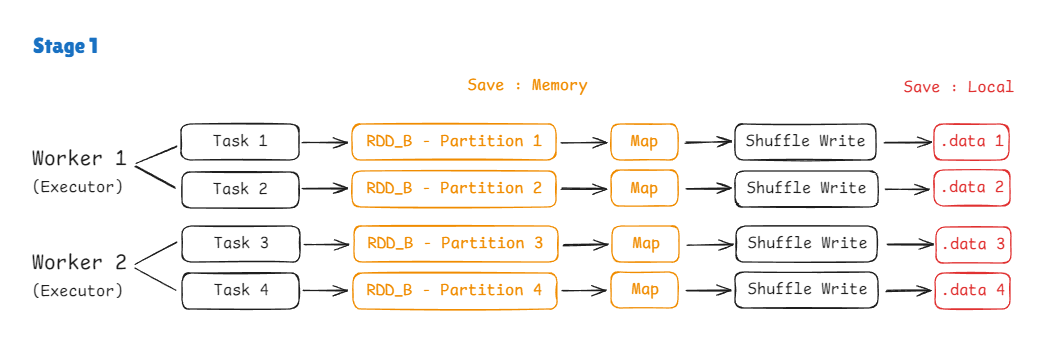
위 그림과 같이 .data와 index를 제외한 나머지는 전부 메모리 상에 로딩될 뿐 디스크(Local)에 저장되지 않습니다.
( 단, 메모리가 초과되는 경우 Spill 작업을 통해 디스크에 저장됩니다. )
Shuffle Read
이제 Shuffle Read입니다.
.data로부터 Partition 별 데이터를 읽어와 데이터 재분배를 실시합니다.
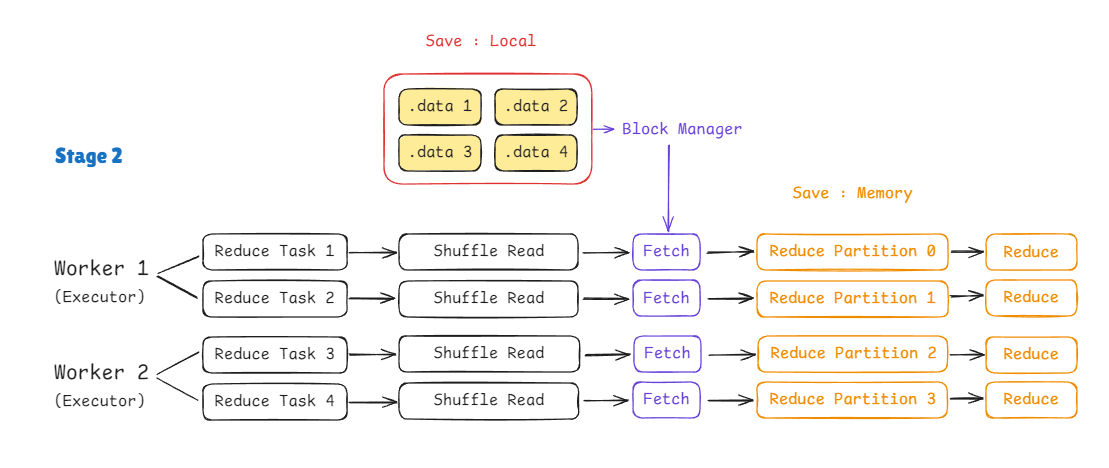
먼저, Shuffle Write에서 생성한 .data, .index 파일들로부터 Partition 별 데이터를 받아야겠죠.
이때, 별도의 전송 Task를 만들지 않아도 Block Manager를 통해서 각 Worker에 존재하는 Partition 별 데이터를 요청할 수 있습니다.
Block Manager를 통해 지정된 id 별로 데이터를 Fetch합니다.
그리고 역직렬화를 통해 key-value 형태로 되돌립니다.
| Reduce Partition | Key(id) |
|---|---|
| 0 | 1, 5 |
| 1 | 0, 2, 8 |
| 2 | 3, 4 |
| 3 | 6, 7 |
그럼 위 표에 의해서 Partition 별 데이터가 아래처럼 분포될 것입니다.
reduce_partitions = {
0: {
1: (["LISA"], []),
5: (["AMY"], ["BAG"])
},
1: {
0: (["TOM"], ["BOX"]),
2: (["JUNE"], ["NOTE"]),
8: ([], ["MOUSE"])
},
2: {
3: (["ERIC"], ["PEN"]),
4: (["KIM", "LEE", "PARK", "CHOI", "JEONG", "YOON"],
["BOOK", "FOLDER", "BINDER", "CASE"])
},
3: {
6: (["PAUL"], []),
7: ([], ["CUP"])
}
}이렇게 Reduce Partition을 생성하면,
여기까지가 바로 Shuffle Read입니다.
그런데 여기서 데이터 분포를 살펴보면 문제가 보일 것입니다.
Reduce Partition 2에 데이터가 몰려있습니다.
분명 HashPartitioner를 통해 id를 균등하게 나눴는데
데이터가 몰려있는 현상이 발생했습니다.
특정 id(id=4)에 데이터가 집중되어 있었기 때문에 id를 균등하게 나눴음에도 데이터 자체를 균등하게 나누지 못한 것이죠.
이를 바로 Data Skew 라고 합니다.
Data Skew란, 분산 처리 시스템에서 특정 키(key)에 데이터가 비정상적으로 몰려 있어 작업이 불균형하게 처리되는 현상을 말합니다.
Data Skew가 발생하면 데이터가 한쪽에 몰려있기 때문에,
분산 처리의 효율이 상당히 떨어지게 됩니다.
이는 Spark에서 가장 치명적인 성능 저하의 주범이기 때문에 조기 탐지와 대응이 매우 중요합니다.
이를 방지하는 방법 중 하나는 Broadcast Join이 있는데 예전 포스팅에도 언급하기도 했으니 넘어가도록 하겠습니다.
이 Data Skew는 Shuffle Read의 Repartition 작업에서 발생합니다.
Reduce
마지막 작업은 Reduce(=Join) 작업을 수행하는 것이죠.
각 Reduce Partition의 RDD A와 RDD B 데이터를 key(=id)를 기준으로 통합시킵니다.
최종 결과는 아래와 같습니다.
{
Reduce Partition 0: {
5: [('AMY', 'BAG')]
},
Reduce Partition 1: {
0: [('TOM', 'BOX')],
2: [('JUNE', 'NOTE')],
},
Reduce Partition 2: {
3: [('ERIC', 'PEN')],
4: [
('KIM', 'BOOK'), ('KIM', 'FOLDER'), ('KIM', 'BINDER'), ('KIM', 'CASE'),
('LEE', 'BOOK'), ('LEE', 'FOLDER'), ('LEE', 'BINDER'), ('LEE', 'CASE'),
('PARK', 'BOOK'), ('PARK', 'FOLDER'), ('PARK', 'BINDER'), ('PARK', 'CASE'),
('CHOI', 'BOOK'), ('CHOI', 'FOLDER'), ('CHOI', 'BINDER'), ('CHOI', 'CASE'),
('JEONG', 'BOOK'), ('JEONG', 'FOLDER'), ('JEONG', 'BINDER'), ('JEONG', 'CASE'),
('YOON', 'BOOK'), ('YOON', 'FOLDER'), ('YOON', 'BINDER'), ('YOON', 'CASE')
]
},
Reduce Partition 3: {
# join X
}
}
이렇게 지금까지 Shuffling 과정을 통해 Partition이 분산 처리에 어떻게 사용되는지 살펴보았습니다.
다음에는 DataFrame의 Catalyst Optimizer를 통한 최적화 방법을 알아보겠습니다.
Reference
