spark
1.Spark의 분산 처리 방식 1-1
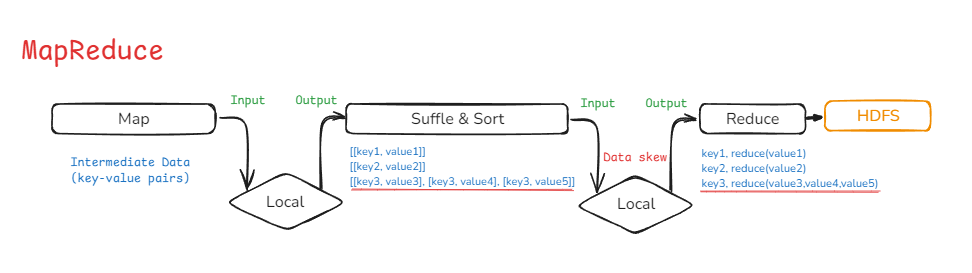
기존 Hadoop의 분산 처리 방식이였던 MapReduce는 디스크 기반으로,데이터의 중간 과정을 로컬디스크에 저장하기 때문에 I/O 오버헤드가 지속적으로 발생했습니다.MapReduce의 대체제로 나온 Spark는 In-memory 기반으로 I/O 오버헤드도 상당히 줄
2025년 4월 4일
2.Spark의 Client, Cluster Mode
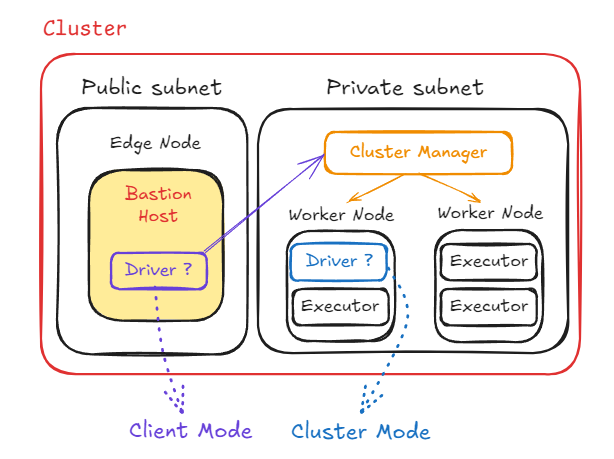
Driver가 어디에서 실행되느냐에 따라 Client Mode / Cluster Mode로 나뉘게됩니다.일반적으로 spark-submit 명령를 통해 Cluster Mode를 선택할 수 있습니다.Local 환경에서 Spark Shell을 통해 Application을 실
2025년 4월 5일
3.Spark의 Driver 파헤치기

Client Mode와 Cluster Mode를 정리하다보니 Driver에 대해 궁금한 점들이 생겼습니다. Driver는 누가 실행시키고 Cluster Manager에게 어떤 것을 전달하는 걸까요? spark-submit 명령에 따른 실행 흐름을 따라가보며 Driv
2025년 5월 23일
4.Spark의 분산 처리 방식 1-2
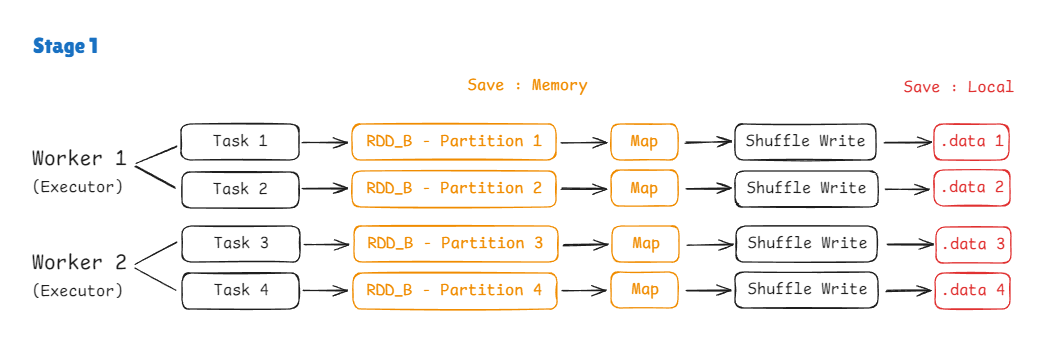
2. Partition 단위의 분산 처리 방식 Spark는 대용량 데이터를 병렬로 처리하기 위해 데이터를 `Partition`이라는 단위로 나누어 처리합니다.
2025년 5월 26일