✏️ 오늘 학습한 내용
1. 데이터 파이프라인이란?
2. 데이터 파이프라인을 만들 때 고려할 점
3. 간단한 ETL 작성
4. Airflow 소개
5. Airflow 구성
🔎 데이터 파이프라인이란?
ETL
- ETL : Extract, Transform and Load
- Data Pipeline, ETL, Data Workflow, DAG
- ETL (Extract, Transform, and Load)
- Called DAG (Directed Acyclic Graph) in Airflow
Airflow의 Data Workflow는 DAG를 사용
( 태스크가 병렬로 순서에 맞게 실행됨 )
ELT
-
ETL vs ELT
-
ETL : 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스
- 보통 데이터 엔지니어들이 수행
-
ELT : 데이터 웨어하우스 내부 데이터를 조작해서 (추상화되고 요약된) 새로운 데이터를 만드는 프로세스
-
보통 데이터 분석가들이 수행
-
이 경우 데이터 레이크 위에서 이런 작업들이 벌어지기도 함
-
이런 프로세스 전용 기술들이 존재
( dbt가 가장 유명 : Analytics Engineering )- dbt: Data Build Tool (오픈소스)
-
-
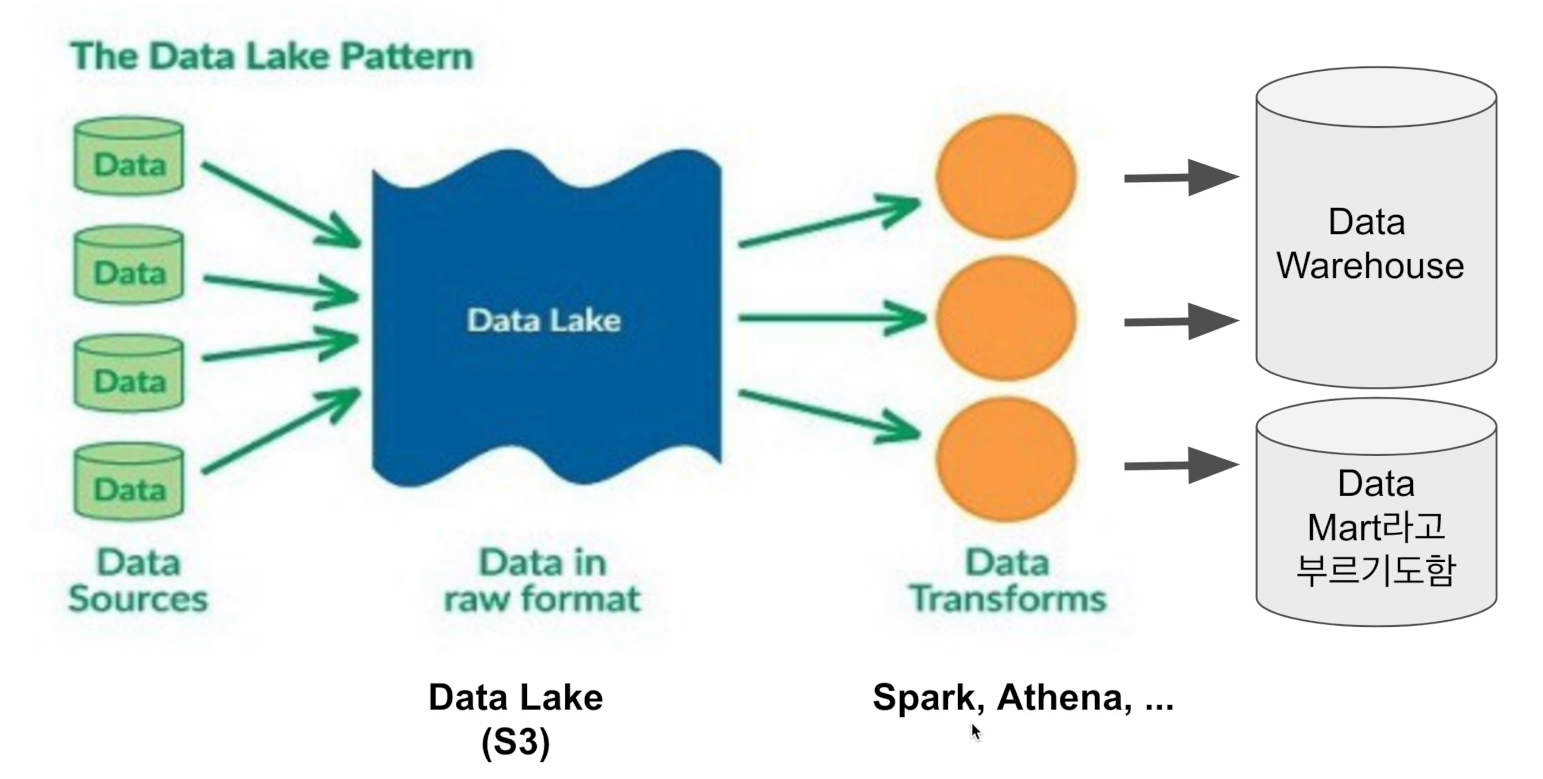
Data Lake vs (Data Warehouse)
-
데이터 레이크 (Data Lake)
- 구조화 데이터 + 비구조화 데이터
- 보존 기한이 없는 모든 데이터를 원래 형태 대로 보존하는 스토리지에 가까움
- 보통은 데이터 웨어하우스보다 몇배는 더 큰 스토리지
-
데이터 웨어하우스 (Data Warehouse)
-
보존 기한이 있는 구조화된 데이터를 저장하고 처리하는 스토리지
-
보통 BI 툴들 (룩커, 테블로, 수퍼셋, ...)은 데이터 웨어하우스를 백엔드로 사용함
-
이 떄 다양한 데이터 파이프라인의 스케줄러와 관리 툴이 필요! (워크플로 관리 도구)
-> Airflow!
Data Pipeline의 정의
-
데이터를 소스로부터 목적지로 복사하는 작업
-
이 작업은 보통 코딩 혹은 SQL을 통해 이뤄짐
( 여기서 코딩은 파이썬 혹은 스칼라, 자바 ) -
대부분의 경우 목적지는 데이터 웨어하우스가 됨
-
-
데이터 목적지의 예:
- 데이터 웨어하우스, 캐시 시스템(Redis), 프로덕션 데이터베이스, NoSQL, S3, ...
Data Pipeline의 종류
Raw Data ETL Jobs
- 외부와 내부 데이터 소스에서 데이터를 읽음
( 많은 경우 API를 사용) - 적당한 데이터 포맷으로 변환 후
( 데이터의 크기가 커지면 Spark등이 필요 ) - 데이터 웨어하우스로 로드
이 작업을 보통 데이터 엔지니어가 진행
Summary/Report Jobs (ELT)
-
DW(혹은 DL)로부터 데이터를 읽어 다시 DW에 쓰는 ETL
-
Raw Data를 읽어서 일종의 리포트 형태나 Summary 형태의 테이블을 다시 만드는 용도
-
특수한 형태로는 AB 테스트 결과를 분석하는 데이터 파이프라인도 존재
요약 테이블의 경우 SQL(CTAS를 통해)만으로 만들고 이는 데이터 분석가가 하는 것이 일반적입니다.
데이터 엔지니어 관점에서는 어떻게 데이터 분석가들이 편하게 할 수 있는 환경을 만들어주느냐가 관건!
-> Analytics Engineer (DBT)
Production Data Jobs
- DW로부터 데이터를 읽어 다른 Storage(많은 경우 프로덕션 환경)로 쓰는 ETL
a. Summary 정보가 프로덕션 환경에서 성능 이유로 필요한 경우
b. 머신러닝 모델에서 feature들을 미리 계산해두는 경우
- 일반적인 타겟 스토리지
a. NoSQL (Cassandra/HBase/DynamoDB)
b. MySQL과 같은 관계형 데이터베이스 (OLTP)
c. Redis/Memcache와 같은 캐시
d. ElasticSearch와 같은 검색엔진
문제 상황
많은 사람들이 액세스를 하는 페이지가 있다면,
사람들이 얼마나 이 페이지를 보고 있는지 views_count 정보를 실시간으로 띄워주는 것 자체는 문제가 없습니다.그러나 Join을 하고 Group by를 해서 여러 계산까지해서 보여주려한다면, Production DB에 부하가 걸리기 시작해서, 앞단의 Cache 마저 풀리는 순간, 큰 부하가 걸리게 됩니다.
해결법 : JOIN하고 GROUP BY한 내용이 꼭 실시간으로 보여줄 필요는 없는 것이니까 한 시간에 한번 씩과 같이 특정 주기마다 계산을 해서 푸쉬를 진행
🔎 데이터 파이프라인을 만들 때 고려할 점
이상과 현실간의 괴리
-
이상 혹은 환상
- 내가 만든 데이터 파이프라인은 문제 없이 동작할 것이다.
- 내가 만든 데이터 파이프라인을 관리하는 것은 어렵지 않을 것이다.
-
현실
-
데이터 파이프라인은 많은 이유로 실패
-
버그
-
데이터 소스상의 이슈
-
데이터 파이프라인들간의 의존도에 대한 이해도가 부족
-
-
데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
-
데이터 소스간의 의존도가 생기면서 이는 더 복잡해짐
(데이터 파이프라인 간 의존성이 생김) -
ex) 마케팅 채널 정보가 업데이트가 안된다면 마케팅 관련 다른 모든 정보들이 갱신되지 않음
-
More tables needs to be managed
(source of truth, search cost, ...)
-
-
Best Practice
Full Refresh / Incremental update
데이터를 데이터 소스에서 웨어하우스로 복사해오는 상황을 가정
-
가능하면 데이터가 작을 경우, 매번 통채로 복사해서 테이블을 만들기
( Full Refresh )이 방법이 좋은 이유,
과거 데이터가 잘못된 것이 있는 경우에도
매번 다시 읽어오기 때문에 별다른 문제가 없음하지만, 소스에 있는 데이터가 커질수록 이 방법은 불가능해짐
Full Refresh가 불가능해지면,
Incremental update를 진행.Incremental update :
소스에 있는 데이터를 전부 읽어서 적재하는 것이 아니라,
변경되는 내용만 읽어와서 적재하는 것.효율성이 증가하지만, 오퍼레이션이 훨씬 복잡해짐
-
Incremental update만이 가능하다면,
대상 데이터 소스가 갖춰야할 몇 가지 조건이 있음-
데이터 소스가 프로덕션 데이터베이스 테이블인 경우 아래 필드가 필요
- created (업데이트 관점에서는 필요 X)
- modified
- deleted
-
데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있음
-
판단 기준
이 데이터를 Full Refresh를 했을 때 걸리는 시간을 고려했을 때, 충분히 짧으면 Full Refresh를 선택하고 아니라면 Incremental update를 진행
멱등성 (Idempotency)
-
멱등성(Idempotency)을 보장하는 것이 중요!!
-
멱등성이란?
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함!
- ex) 중복 데이터가 생기면 안됨
- 중요한 포인트는 critical point들이 모두 one atomic action(원자성)으로 실행되어야 한다는 점
- SQL의 transaction이 꼭 필요한 기술!
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함!
Backfill
-
실패한 데이터 파이프라인의 재실행이 쉬워야함
-
과거 데이터를 다시 채우는 과정(Backfill)이 쉬워야 함!
-
Airflow는 이 부분(특히 Backfill)에 강점을 갖고 있음
Full Refresh의 경우 복구가 단순합니다.
-> 재실행하면 복구가 됩니다.Incremental update의 경우,
특정 날짜의 Incremental update가 실패했다고 가정하면 그 날짜만큼의 데이터가 비어있게 됩니다. 그런데 데이터 소스가 변경이 되었다면 일일히 COPY를 해야합니다. 이러한 과정을 Backfill이라고 부릅니다.-> 이 Backfill이 필요한 상황이 상당히 많이 발생하지만 사용하기가 힘듭니다.
그렇기에 Airflow를 사람들이 많이 사용하는 이유중 하나입니다.
문서화
-
데이터 파이프라인의 입력과 출력을 명확히 하고 문서화
-
비즈니스 오너 명시 : 누가 이 데이터를 요청했는지 기록으로 남겨야 함!
-
태크니컬 오너 명시 : 코드를 작성하고 코드를 유지보수하는 데이터 엔지니어 중 한 사람
-
이게 나중에 데이터 카탈로그로 들어가, 데이터 디스커버리에 사용 가능함!
- 데이터 리니지가 중요해짐
-> 이걸 이해하지 못하면 온갖 종류의 사고 발생
( ex) 의존성에 의해 발생하는 문제 )
- 데이터 리니지가 중요해짐
-
파이프라인이 한 두개면 상관 없지만 점점 늘어날수록 관련 데이터에 대한 정의를 기억할 수 없기 때문에 문서화는 꼭 필요합니다!
주기적인 데이터 삭제
- 주기적으로 쓸모없는 데이터들을 삭제
파이프라인의 출력이 누구에 의해 소모가 되고 있는지를 데이터 디스커버리 툴을 통해 확인합니다.
지난 1년간 사용이 되지 않은 테이블이 뭐가 있냐를 찾아서 삭제할 테이블을 정합니다.
테이블을 정한 후 각 테이블이 어느 데이터 파이프라인에서 만들어지는지 확인해서 그 데이터 파이프라인을 제거할 수 있습니다.
사고 리포트 작성
데이터 파이프라인이 실패하는 것은 시간 문제이지 막을 수 있는 것이 아닙니다.
올바른 자세는 실패를 하지않으려고 하는 것이 아니라 실패를 당연히 여기고 그 이유를 잘 살펴보는 것입니다. ( 일종의 사고 보고서 )
-
데이터 파이프라인 사고시 마다 사고 리포트(post-mortem) 쓰기
-
목적은 동일한 혹은 아주 비슷한 사고가 또 발생하는 것을 막기 위함
-
사고 원인(root-cause)을 이해하고 이를 방지하기 위한 액션 아이템들의 실행이 중요해짐
-
기술 부채의 정도를 이야기해주는 바로미터
Post-mortem을 얼마나 자주 쓰느냐, Post-mortem에서 밝힌 사고의 정도가 얼마나 심하냐? 이것의 트랜드를 보면 기술 부채가 심해지고 있는지 아닌지 확인할 수 있습니다.
-
리포트만 작성하는 게 목적이 아니고,
리포트에서 나온 문제점을 해결을 함으로써 재발을 막는 것에 집중해야함.Management에 support가 없이는 이를 수행하기 힘들 수 있습니다.
중요한 데이터 파이프라인 입출력 체크
중요한 데이터 파이프라인이라면 입력의 상태가 어떤지 체크하고, 출력이 믿을만한지 체크하는 코드를 작성해야합니다.
( 코드의 경우 Unit-Test를 진행하는 것을 데이터에서도 똑같이 진행, 일종의 Data-Unit-Test )
-
간단하게, 입력 레코드의 수와 출력 레코드의 수가 몇 개인지 체크하는 것부터 시작
-
Summary 테이블을 만들어내고 Primary key uniqueness가 보장되는지 체크하는 것이 필요
-
중복 레코드 체크
-
Data 대상 Unit-Test
🔎 간단한 ETL 작성
Extract, Transform, Load
- Extract :
- 데이터를 데이터 소스에서 읽어내는 과정.
( 보통 API 호출 )
- 데이터를 데이터 소스에서 읽어내는 과정.
- Transform :
- 필요하다면 그 원본 데이터의 포맷을 원하는 형태로 변경시키는 과정. 굳이 변환할 필요는 없음
- Load :
- 최종적으로 Data Warehouse에 테이블로 집어넣는 과정
ETL 작성 개요
-
웹 상에 존재하는 이름 성별 CSV파일을 Redshift에 있는 테이블로 복사
( S3 CSV 파일 -> Redshift에 있는 테이블 ) -
Google Colab을 통해 진행
-
멱등성을 보장해야함!
코드 작성
- Redshift에 테이블 생성
CSV 파일에 있는 데이터를 받기 위한 테이블을 생성
CREATE TABLE skqltldnjf77.name_gender (
name varchar(32) primary key,
gender varchar(8)
);- Redshift와 연결해주는 함수 생성
import psycopg2
# Redshift connection 함수
# 본인 Redshift의 host, ID/PW 등을 입력
def get_Redshift_connection():
host = "..."
redshift_user = "..."
redshift_pass = "..."
port = 5439
dbname = "dev"
conn = psycopg2.connect("dbname={dbname} user={user} host={host} password={password} port={port}".format(
dbname=dbname,
user=redshift_user,
password=redshift_pass,
host=host,
port=port
))
conn.set_session(autocommit=True)
return conn.cursor()- ETL 함수 정의
import requests
def extract(url):
# requests라는 모듈의 get함수를 사용하여 내용을 읽어옴
f = requests.get(url)
# 읽어온 내용을 문자 그대로 return (아무런 parsing 없이)
return (f.text)
# extract에서 읽어온 문자열을 받아서
# name과 gender를 갖는 리스트로 리턴
def transform(text):
# 줄바꿈 제거
lines = text.strip().split("\n")
records = []
for l in lines:
# ","를 기준으로 분리하여 저장
(name, gender) = l.split(",")
records.append([name, gender])
return records
def load(records):
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection() # Redshift와 연결
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
# insert into를 사용해 하나씩 적재
sql = "INSERT INTO skqltldnjf77.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)- ETL 함수 실행
# S3에 있는 csv파일을 링크로 연결
link = "https://s3_bucket_name.s3-us-west-2.amazonaws.com/name_gender.csv"
# extract함수로 읽어오기
data = extract(link)
# transform
lines = transform(data)
# load를 통한 적재
load(lines)-
문제점
- "name" - "gender"라는 헤더가 마치 Record인 것처럼 적재가 되어있음
( 첫 레코드를 무시하게 수정 ) - 멱등성이 깨지고 있음
( 다시 ETL을 재실행하면 타겟 테이블의 내용이 동일해야하는데 중복이 계속 발생 )
- "name" - "gender"라는 헤더가 마치 Record인 것처럼 적재가 되어있음
-
문제에 따른 수정
def transform(text):
lines = text.strip().split("\n")
records = []
# 헤더를 제거하기 위해 [1:]로 시작
for l in lines[1:]:
(name, gender) = l.split(",") # l = "skqltldnjf77,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
return records
def load(records):
"""
records = [
[ "skqltldnjf77", "M" ],
[ "Claire", "F" ],
...
]
"""
cur = get_Redshift_connection()
# BEGIN, END를 통한 트랜잭션을 구성
# 성공했을 때만 반영이 되게끔 만들어
# 데이터의 정합성을 보장
try :
cur.execute("BEGIN;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
cur.execute("DELETE FROM skqltldnjf77.name_gender;")
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = "INSERT INTO skqltldnjf77.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)
cur.execute("COMMIT;") # END와 동일
except (Exception, psycopg2.DatabaseError) as error:
print(error)
# 실패시 ROLLBACK
# BEGIN 전의 상태로 돌아감.
cur.execute("ROLLBACK;")
# 에러의 발생을 알리기 위해
# exception을 위로 전파하는 raise를 사용.
raise트랜잭션 구현 방법
-
두 가지 종류의 트랜잭션이 존재
- 레코드 변경/삭제/추가를 바로 반영하는지 여부
- autocommit이라는 파라미터로 조절가능
-
autocommit=True
- 기본적으로 모든 SQL statement가 바로 물리 테이블에 커밋됨
- 이를 바꾸고 싶다면 BEGIN;END; 혹은 BEGIN;COMMIT을 사용 (혹은 ROLLBACK)
-
autocommit=False
- 기본적으로 모든 SQL statement가 커밋되지 않음. 즉 모두 스테이징 상태로 존재
- 커넥션 객체의 .commit()과 .rollback()함수로 커밋할지 말지 결정
-
auto commit을 사용할 것인지 말지?
-> 개인이나 팀의 선택 -
Python의 경우 try/catch와 같이 사용하는 것이 일반적
try/catch로 에러가 나면 rollback을 명시적으로 실행하나,
에러가 발생하지 않으면 commit을 실행함. -
주의사항
exception 구문에
raise를 하지 않는 경우 에러가 감춰지기에 에러가 발생한지 모른 채로 계속해서 작업이 수행되지 않을 수 있음.그렇기에 명시적으로 exception 구문 마지막에
raise를 사용해서
에러를 위로 전파하는 것이 좋음.
🔎 Airflow 소개
-
Airflow는 파이썬으로 작성된 데이터 파이프라인 (ETL) Framework
- Airbnb에서 시작한 아파치 오픈소스 프로젝트
- 가장 많이 사용되는 데이터 파이프라인 관리/작성 프레임워크
-
데이터 파이프라인 스케줄링 지원
- 정해진 시간에 ETL 실행 혹은 한 ETL의 실행이 끝나면 다음 ETL 실행
- 웹 UI를 제공하기도 함
-
데이터 파이프라인(ETL) 작성을 쉽게 만들어주는 역할도 해줌
-
다양한 데이터 소스와 데이터 웨어하우스를 쉽게 통합해주는 모듈 제공
https://airflow.apache.org/docs/ -
데이터 파이프라인 관리 관련 다양한 기능을 제공 (특히, Backfill)
-
-
Airflow에서는 데이터 파이프라인을 DAG(Directed Acyclic Graph)라고 부름
- 하나의 DAG는 하나 이상의 태스크로 구성
-
Airflow 버전 선택 방법 :
- 큰 회사에서 사용하는 버전이 무엇인지 확인
https://cloud.google.com/composer/docs/concepts/versioning/composer-versions
- 큰 회사에서 사용하는 버전이 무엇인지 확인
🔎 Airflow 구성
Airflow를 아키텍쳐 관점에서 봤을 때, 어떤 컴포넌트들을 갖고 있는지?
DAG가 점점 늘어나면 Airflow의 용량이 늘어나기 시작 -> 어떤 스케일링 방식을 사용해야할지?
Airflow - 5개의 컴포넌트로 구성
-
웹 서버 (Web Server)
-
스케줄러 (Scheduler)
-
워커 (Worker)
( 주어진 파이프라인의 태스크들을 실행해주는 역할 ) -
메타 데이터 데이터베이스
( Sqlite가 기본 설치되어있음 ) -
큐 (다수서버 구성인 경우에 사용됨)
큐에 태스크를 집어넣고,
놀고 있는 Worker가 생기면 큐에 있는 태스크를 읽어다가 실행.서버가 한개인 경우에도 큐를 사용하기도 함.
-> 정리하면, 태스크들이 다수의 워커로 분산이되서 처리가 되려면
매개체가 필요한데 그것이 바로 큐
Airflow 구성
- 스케줄러 :
- DAG들을 워커들에게 배정하는 역할을 수행
정확하게는, DAG를 스케줄링하는 것이 아니라, DAG 안의 태스크를 스케줄링하는 것
- DAG들을 워커들에게 배정하는 역할을 수행
-
웹 UI:
- 스케줄러와 DAG의 실행 상황을 시각화
-
워커:
- 실제로 DAG를 실행하는 역할을 수행
-
스케줄러와 각 DAG의 실행결과는 별도 DB에 저장됨
Airflow 구조 - 서버 한대
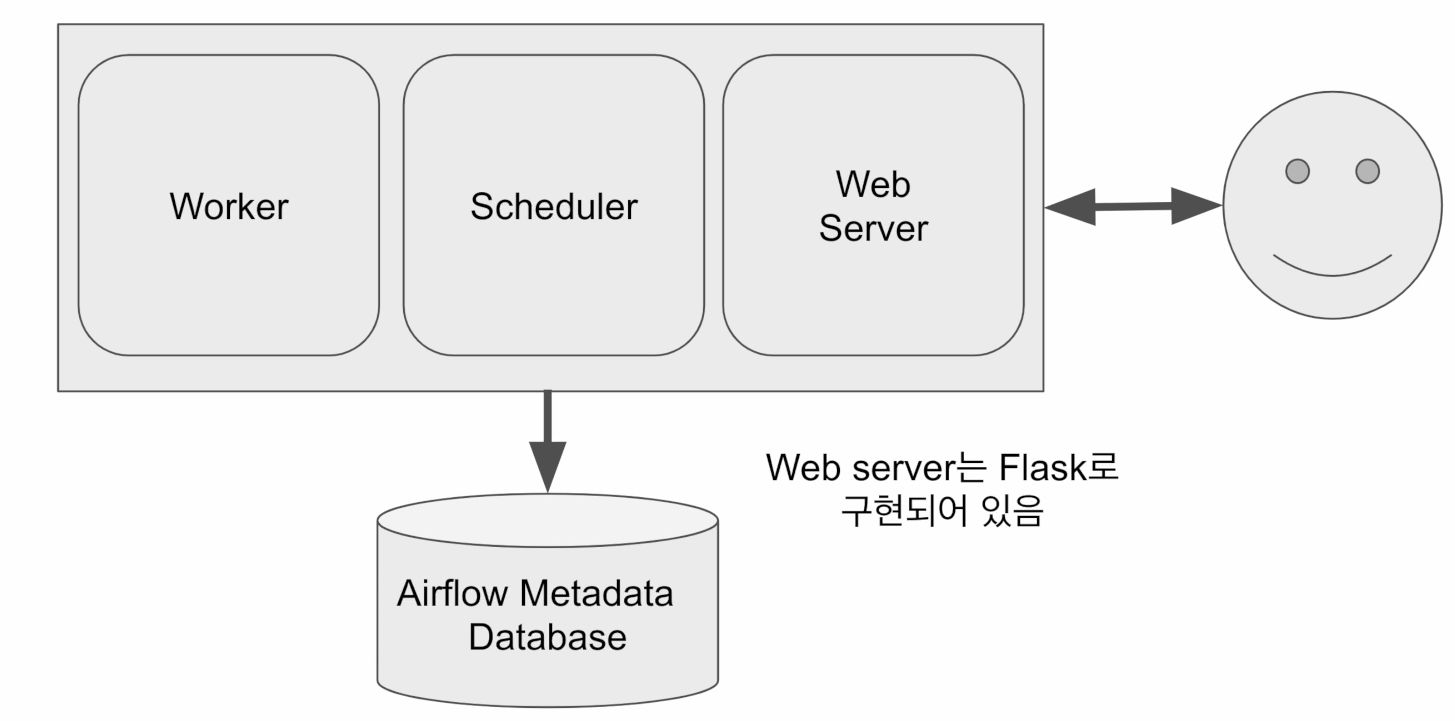
워커의 수 : 최대, 서버가 보유한 CPU 수 만큼 가능
Airflow Metadata Database : 실행 상황이 별도로 저장되는 DB
CPU 수의 제한으로 인해 동시에 실행할 수 있는 태스크의 수가 제약이 있음
데이터 파이프라인의 수가 늘어나게되면서 서버 한대로는 부족하게됨.
스케일링을 할 때는,
워커를 별도의 서버에 세팅하고,
워커가 있는 서버의 수를 늘리는 형태로 증대
- 스케일 업 (더 좋은 사양의 서버 사용)
- 스케일 아웃 (서버 추가) -> 워커 용도로만 서버 증설
Airflow 구조 - 다수 서버
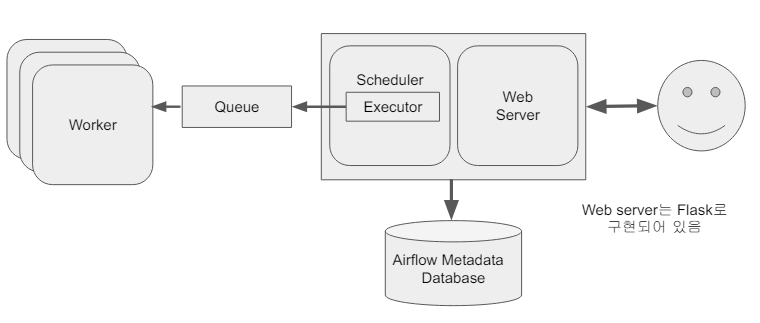
다수의 워커 서버가 있고 이 통신을 Queue를 통해서 진행.
Scheduler가 Task를 바로 워커에 넘기는게 아니라 Executor를 통해서 워커에 넘김.
Executor가 무엇이냐에 따라 Queue를 사용하기도 사용하지 않기도 함.
다수의 서버 : 워커 전용으로 서버들을 할당.
Airflow 구조 정리

브라우저에서 사람들이 Airflow의 Web UI로 액세스 -> Webserver로 통신
Airflow에 Python으로 작성한 데이터 파이프라인 코드를 DAG Directory에 위치시킴.
( 이를 Airflow가 주기적으로 Parsing )그 실행 상황, 결과를 주기적으로 Metadata DB에 저장을 하고
지정된 시간마다 Scheduler가 Executor를 통해 Task를 워커에 부여
- Executor의 종류
- Sequential Executor
( Default, 제약이 많음 ) - Local Executor
( 보통은 Local Executor를 많이 사용 ) - Celery Executor
- Kubernetes Executor
- CeleryKubernetes Executor
- Dask Executor
- Sequential Executor
Airflow 개발의 장단점
-
장점
- 데이터 파이프라인을 세밀하게 제어 가능
- 다양한 데이터 소스와 데이터 웨어하우스를 지원
- 백필(Backfill)이 쉬움!
-
단점
-
배우기가 쉽지 않음
-
상대적으로 개발환경을 구성하기가 쉽지 않음
-
직접 운영이 쉽지 않음.
( 클라우드 버전 사용이 선호됨 )- GCP provides "Cloud Composer"
- AWS provides "Managed Workflows for Apache Airflow"
- Azure provides "Data Factory Managed Airflow"
-
결과적으로 클라우드가 더 경제적.
DAG란 무엇인가?
-
Directed Acyclic Graph의 줄임말
-
Airflow에서 ETL을 부르는 명칭
-
DAG는 태스크로 구성됨
-
태스크란?
-
Airflow의 오퍼레이터(Operator)로 만들어짐
-
오퍼레이터를 하나 만들면 하나의 태스크가 만들어짐.
( 수행하는 태스크에 맞게 오퍼레이터를 생성 ) -
Airflow에서 이미 다양한 종류의 오퍼레이터를 제공
-
경우에 맞게 사용 오퍼레이터를 결정하거나 필요하다면 직접 개발
-
e.g.) Redshift writing, Postgres query, S3 Read/Write, Hive query, Spark job, shell script
-
DAG는 태스크의 집합,
태스크는 Operator로 구현.Airflow를 코딩한다는 것은?
DAG Instance를 생성하고 DAG에 대한 이름, 스케줄러 등을 지정하고,그 DAG를 구성하는 다양한 태스크들이 무엇인지 Operator 형태로 구현.
