TIL
1.자료구조/알고리즘 - 파이썬 (TIL 1)

자료구조 / 알고리즘 1
2.자료구조/알고리즘 - 파이썬 (TIL 2)
1. Linked List 2. Doubly Linked List 3. Stack
3.자료구조/알고리즘 - 파이썬 (TIL 3)
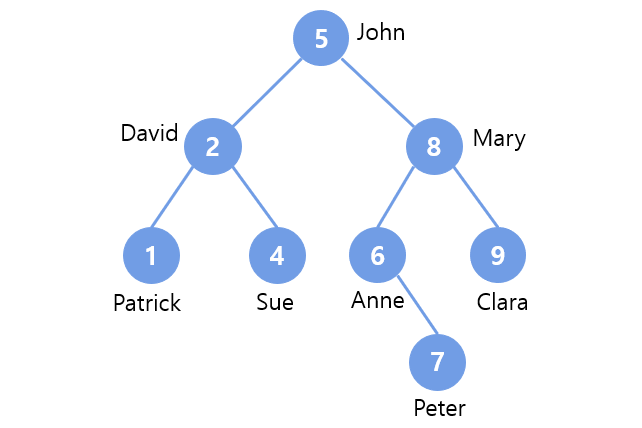
1. Queue 2. Circular Queue 3. Priority Queue 4. Binary Tree 5. Heap
4.자료구조/알고리즘 - 파이썬 (TIL 4)
1. Hash 2. Greedy
5.자료구조/알고리즘 - 파이썬 (TIL 5)
1. Heap 문제 2. DP 문제 3. DFS/BFS 문제
6.HTML 기본 (TIL 6)
HTML 기본 정리
7.Web Scraping 기초 (TIL 7)
1. HTTP 2. 웹페이지와 HTML 3. HTTP 통신 4. 웹 스크래핑, 크롤링 5. DOM
8.Web Scraping 기초 (TIL 8)
1. BeautifulSoup 2. 원하는 요소 찾기 3. 동적 웹 사이트
9.웹 브라우저 자동화 (TIL 9)
1. Selenium 2. Wait and Call 3. 이벤트 처리
10.스크래핑 결과 시각화 (TIL 10)
1. Seaborn 2. Scraping 시각화 3. WordCloud
11.Django를 사용해 API 서버 만들기 (TIL 11)
Django - 환경설정 - 관계형 데이터베이스 - Model 만들기 - 다양한 필드 활용 - 관리자 계정 생성 - Django Admin - 모델 등록 - Django Shell
12.Django를 사용해 API 서버 만들기 (TIL 12)
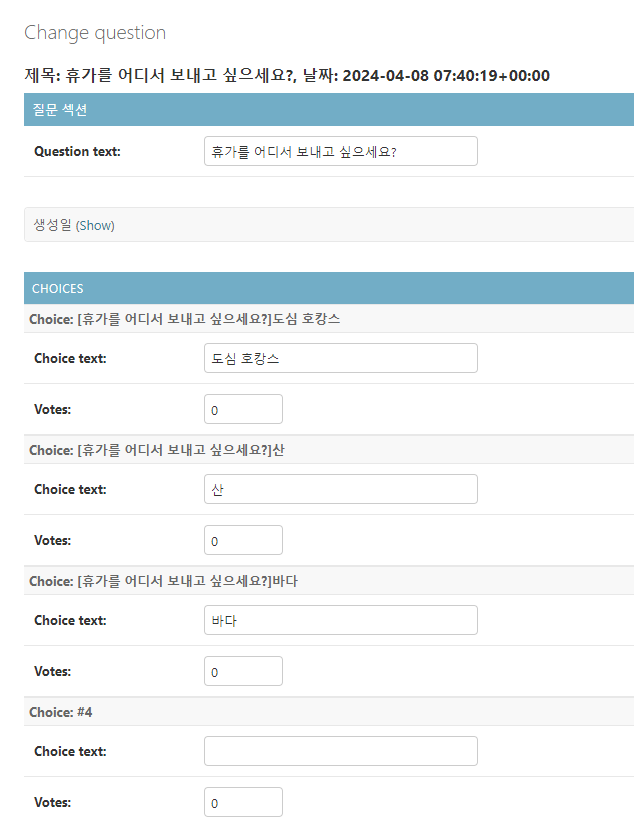
✏️ 오늘 학습한 내용 > 1. Views와 Templates 2. Forms와 Customizing
13.Django를 사용해 API 서버 만들기 (TIL 13)
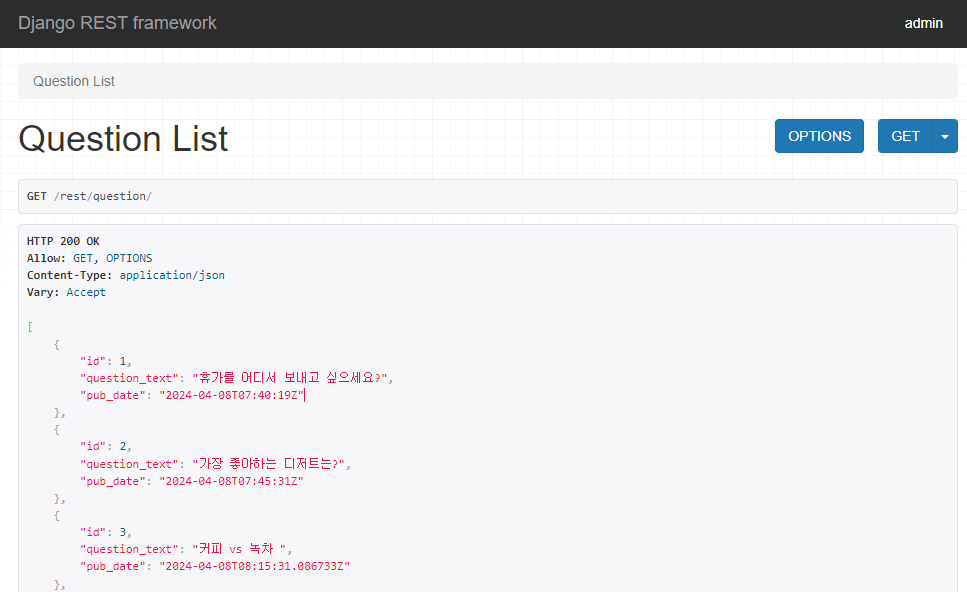
Serializer와 Views - ModelSerializer - HTTP Request Method - GET, POST, PUT, DELETE - Class 기반의 Views - Mixin - Generic API View
14.Django를 사용해 API 서버 만들기 (TIL 14)
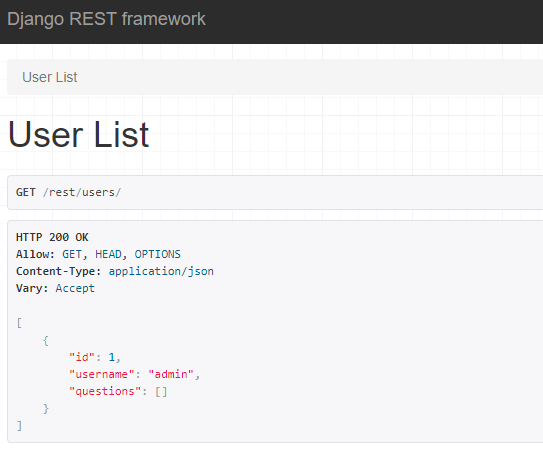
Users와 Authentication - User 추가 - User 관리 - Form을 사용하여 User 생성 ( 회원 가입 ) - User 권한 관리 - perform_create() - POSTMAN
15.Django를 사용해 API 서버 만들기 (TIL 15)
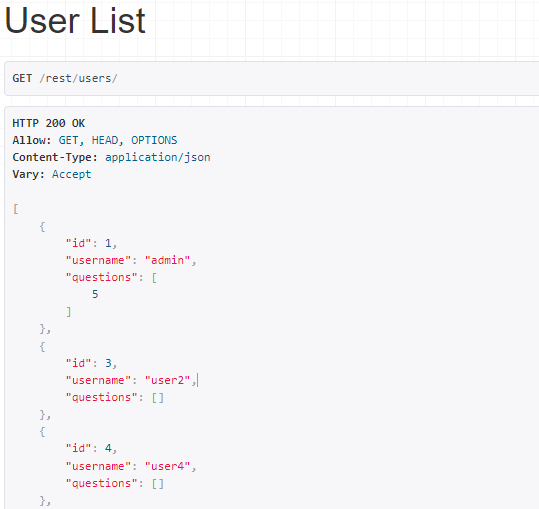
1. Users와 Authentication 2. Votes와 Testing
16.SQL과 데이터베이스 (TIL 16)
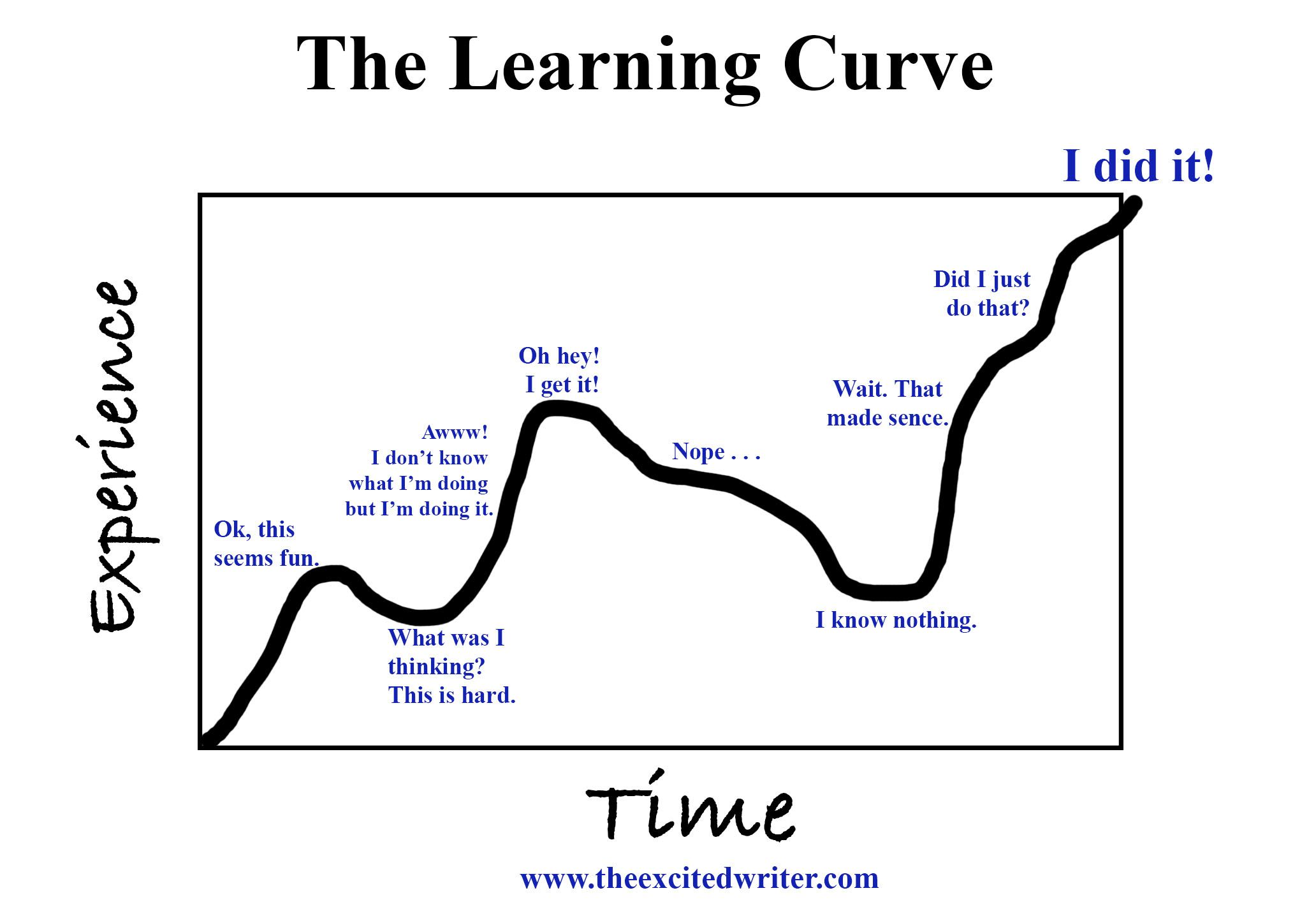
1. 배움에 관하여 2. 관계형 데이터베이스 3. SQL 4. 데이터 웨어하우스 5. Cloud와 AWS
17.SQL을 이용한 데이터 분석 - Redshift (TIL 17)

Redshift & SQL - AWS Console을 통한 Redshift launch - 관계형 데이터베이스 예제 - Redshift 중심의 SQL (DDL, DML) 소개 - GoogleColab을 통한 실습
18.SQL을 이용한 데이터 분석 - Redshift (TIL 18)
1. Group by와 AGGREGATE 함수 2. CTAS와 CTE
19.SQL을 이용한 데이터 분석 - Redshift (TIL 19)
1. JOIN 2. SQL
20.SQL을 이용한 데이터 분석 - Redshift (TIL 20)
1. 트랜잭션 2. SQL 고급 문법
21.AWS 클라우드 (TIL 21)
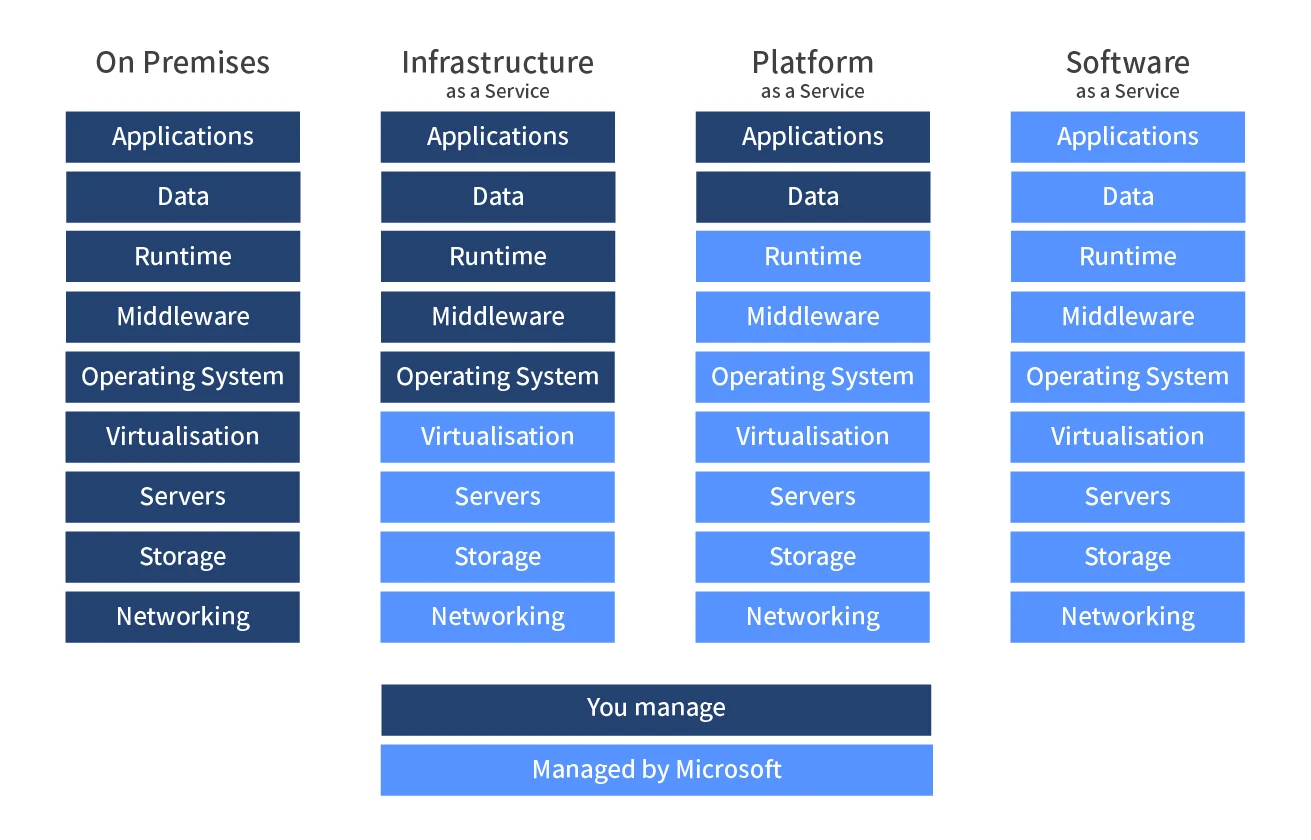
1. AWS란? 2. 클라우드 컴퓨팅이란? 3. AWS 기본용어 4. EC2 5. EC2 생성해보기 6. Elastic Beanstalk
22.AWS 클라우드 (TIL 22)
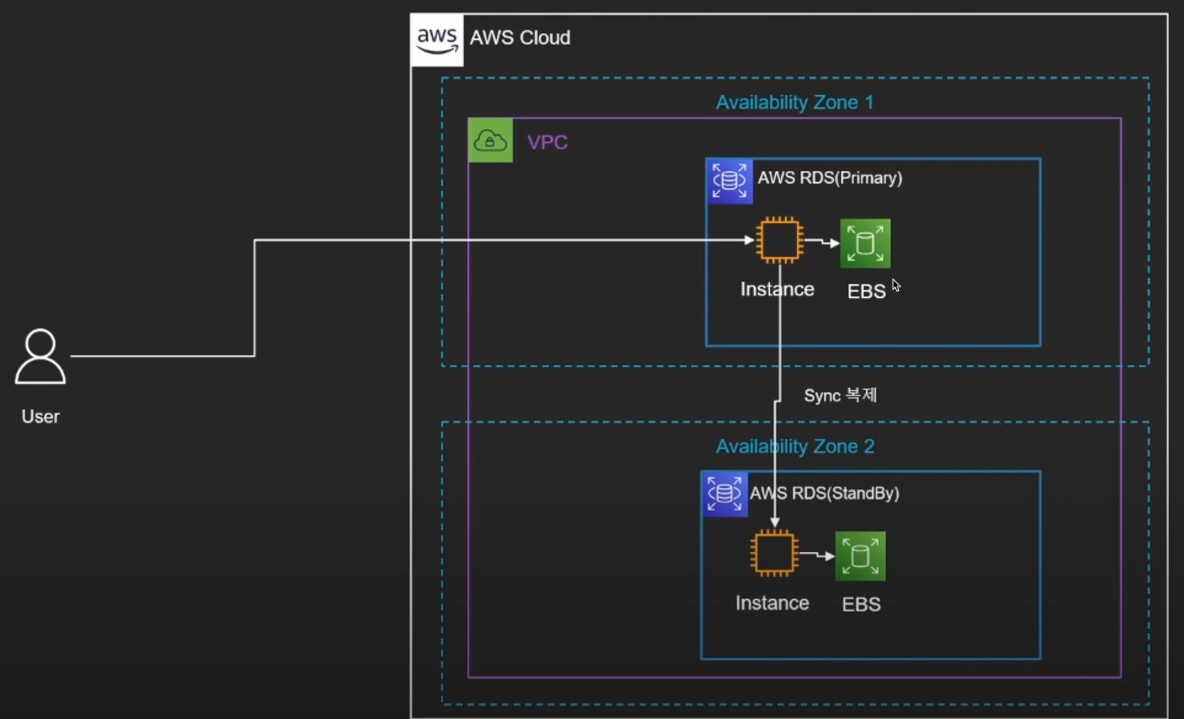
DB - RDS - DocumentDB - DynamoDB Network - Route53 - Certification Manager - CloudFront - Elastic Load Balancing (ELB) - Virtual Private Cloud(VPC)
23.AWS 클라우드 (TIL 23)
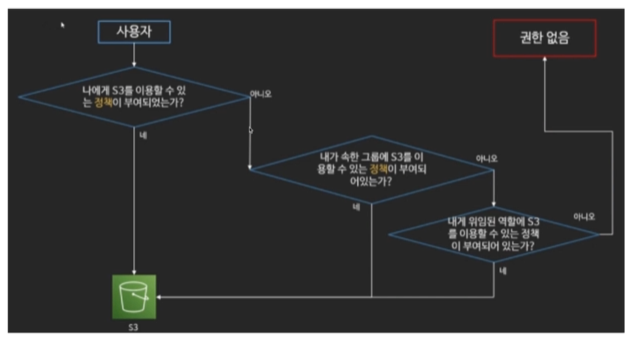
1. IAM 2. S3 3. CI/CD
24.AWS 클라우드 실습 (TIL 24)
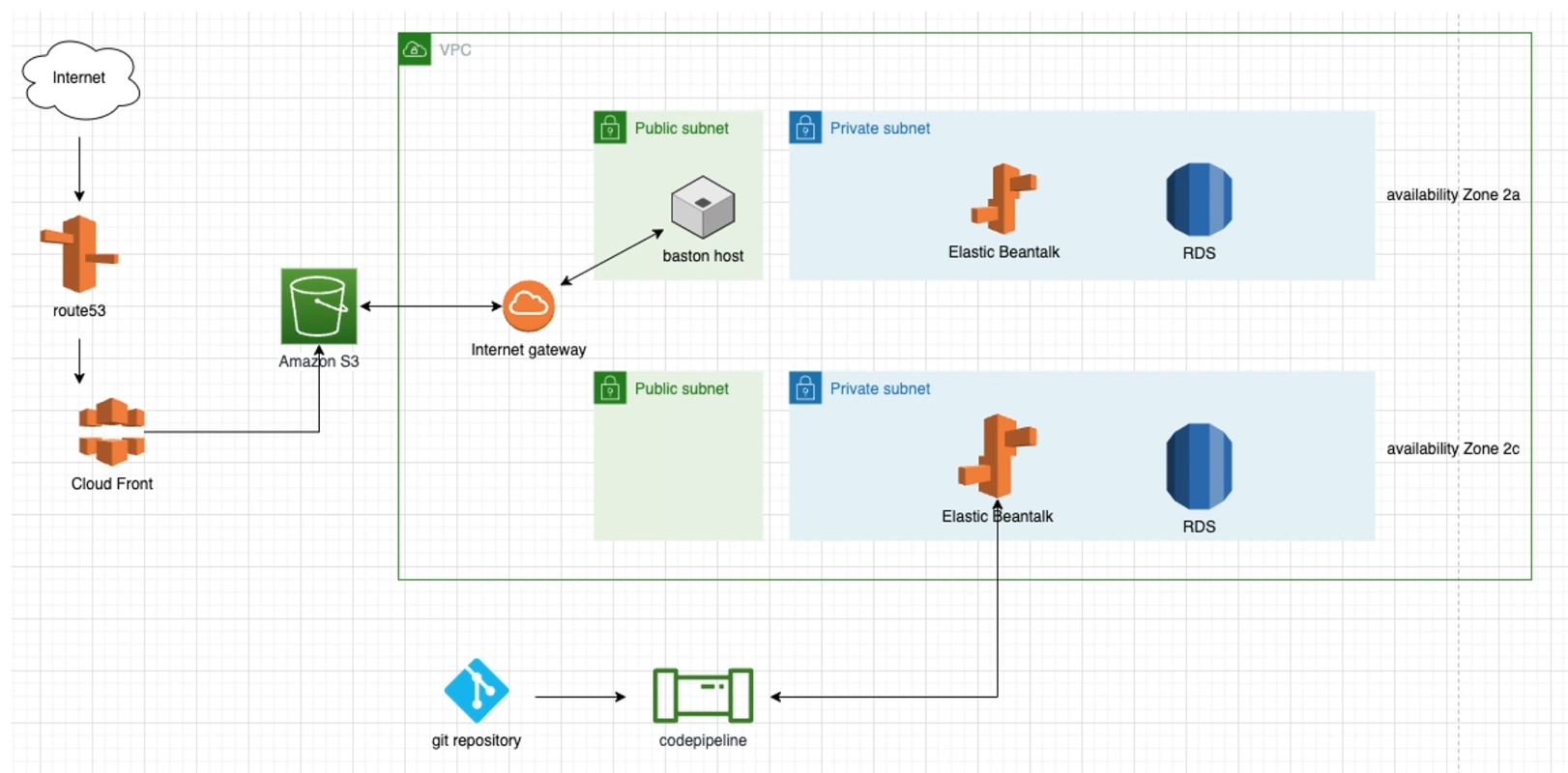
AWS 클라우드 실습 - SpringBoot 구성 - VPC 구성 - EC2 구성 - Elastic Beanstalk 구성 - 콘솔 접속 - RDS 구성 - S3 구성 - CI/CD 구성
25.AWS 클라우드 (TIL 25)
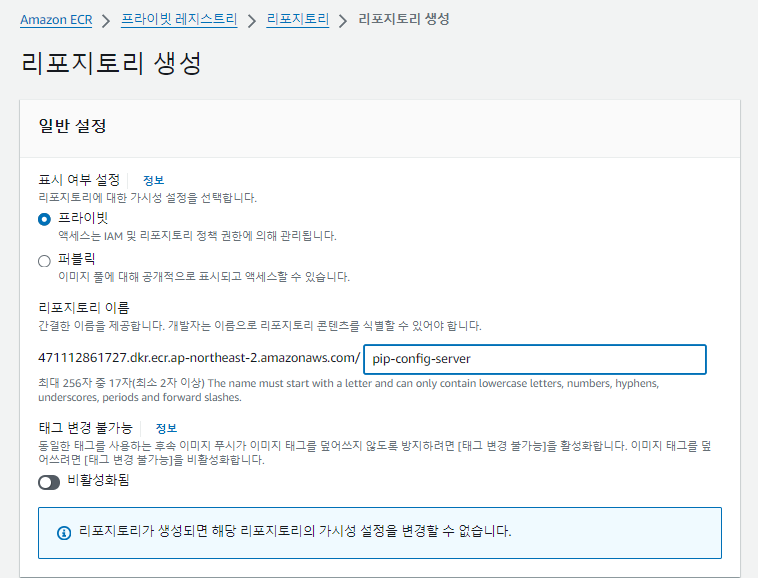
1. AWS CLI 2. Docker 3. ECS/ECR 4. Lambda 5. ApiGateway 6. CloudWatch 7. DevOps 8. MLOps
26.데이터 웨어하우스 관리와 고급 SQL, BI 대시보드 (TIL 26)

1. 데이터 팀의 역할 2. 데이터 조직의 구성원 3. 데이터 웨어하우스와 데이터 레이크, ETL/ELT 4. 데이터 웨어하우스 옵션들 5. 데이터 스택 트랜드
27.Redshift 실습 (TIL 27)
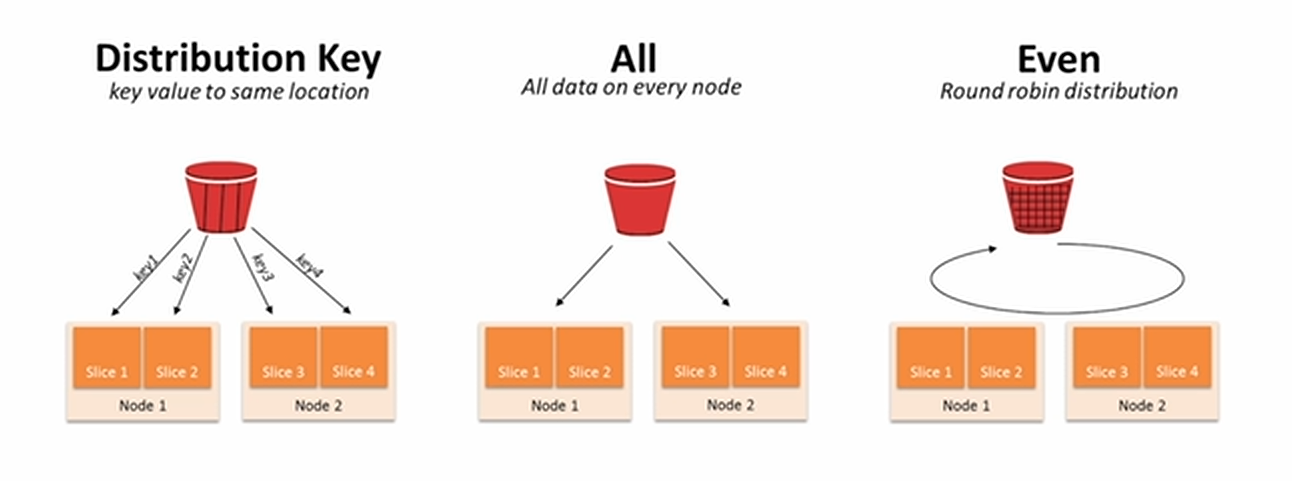
1. Redshift 특징 2. Redshift Serverless 연결 및 실습
28.Redshift 고급 기능 실습 (TIL 28)
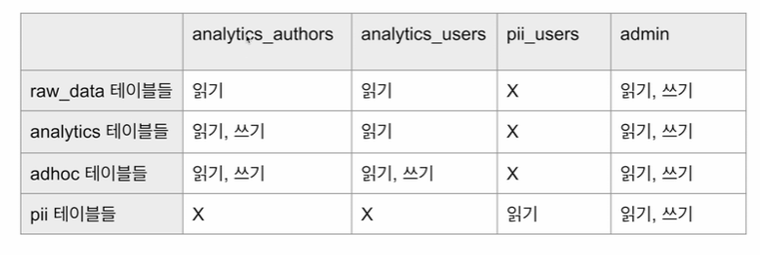
1. Redshift 권한과 보안 2. Redshift 백업과 테이블 복구 3. Redshift 관련 기타 서비스 4. Redshift Spectrum 사용 5. Redshift ML 사용 6. Redshift 중지/제거
29.Snowflake 운영과 관리 (TIL 29)
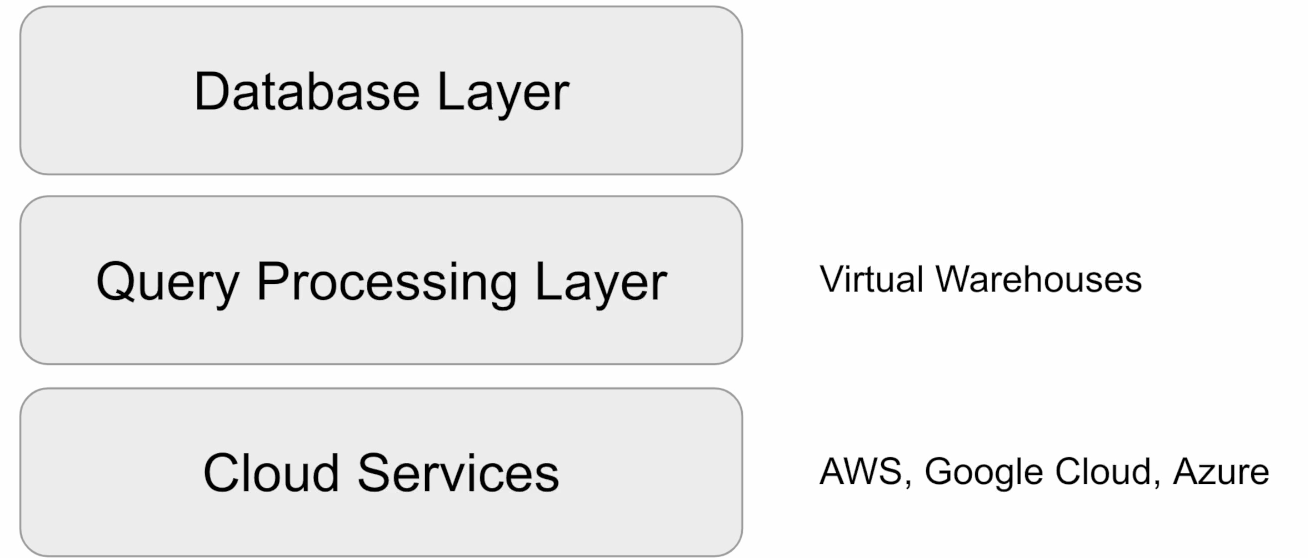
1. Snowflake 특징 2. Snowflake 무료 시험판 3. Snowflake 실습을 위한 환경 설정 4. Snowflake 사용자 권한 설정 5. Snowflake 기타 기능과 사용 중단 기능
30.다양한 대시보드 옵션 (TIL 30)
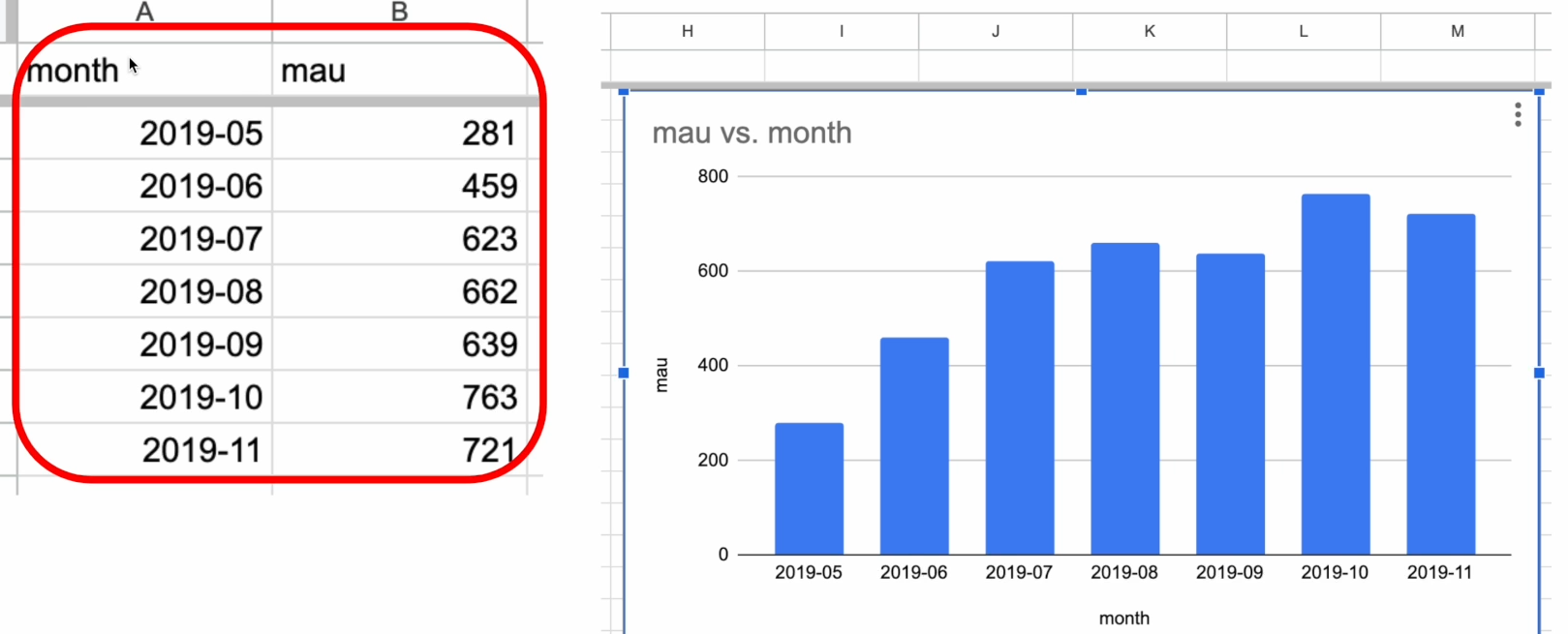
1. 다양한 시각화 툴 2. Superset 3. 대시보드 제작 예시 4. Superset 설치 5. Redshift 설정 및 차트 생성
31.데이터 파이프라인과 Airflow (TIL 31)
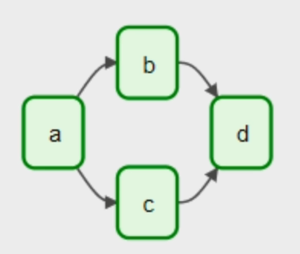
1. 데이터 파이프라인이란? 2. 데이터 파이프라인을 만들 때 고려할 점 3. 간단한 ETL 작성 4. Airflow 소개 5. Airflow 구성
32.Airflow 프로그래밍 기본 세팅 (TIL 32)
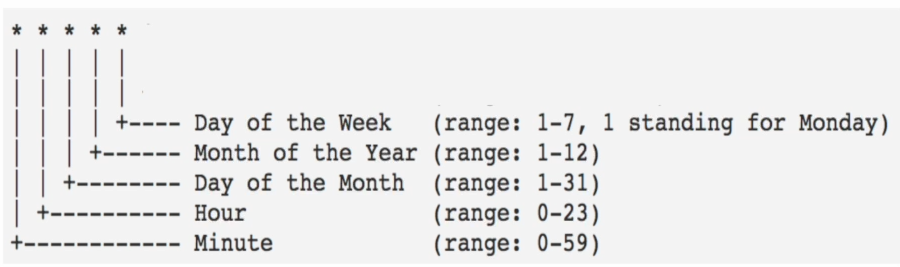
1. Airflow 설치 2. Airflow 기본 프로그램 실행
33.Airflow DAG 작성 (TIL 33)
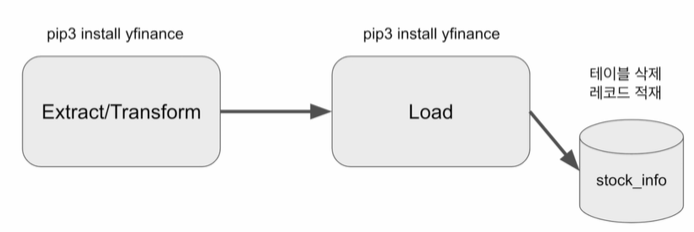
1. Airflow DAG 작성 2. 예제 프로그램 Airflow로 포팅
34.Airflow 날씨 정보DAG 구현 및 Backfill (TIL 34)
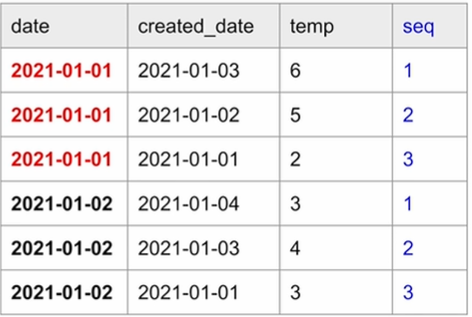
1. Open Weather DAG 구현 2. Backfill과 Airflow
35.Airflow DAG 구현 - OLTP 복사와 ELT (TIL 35)
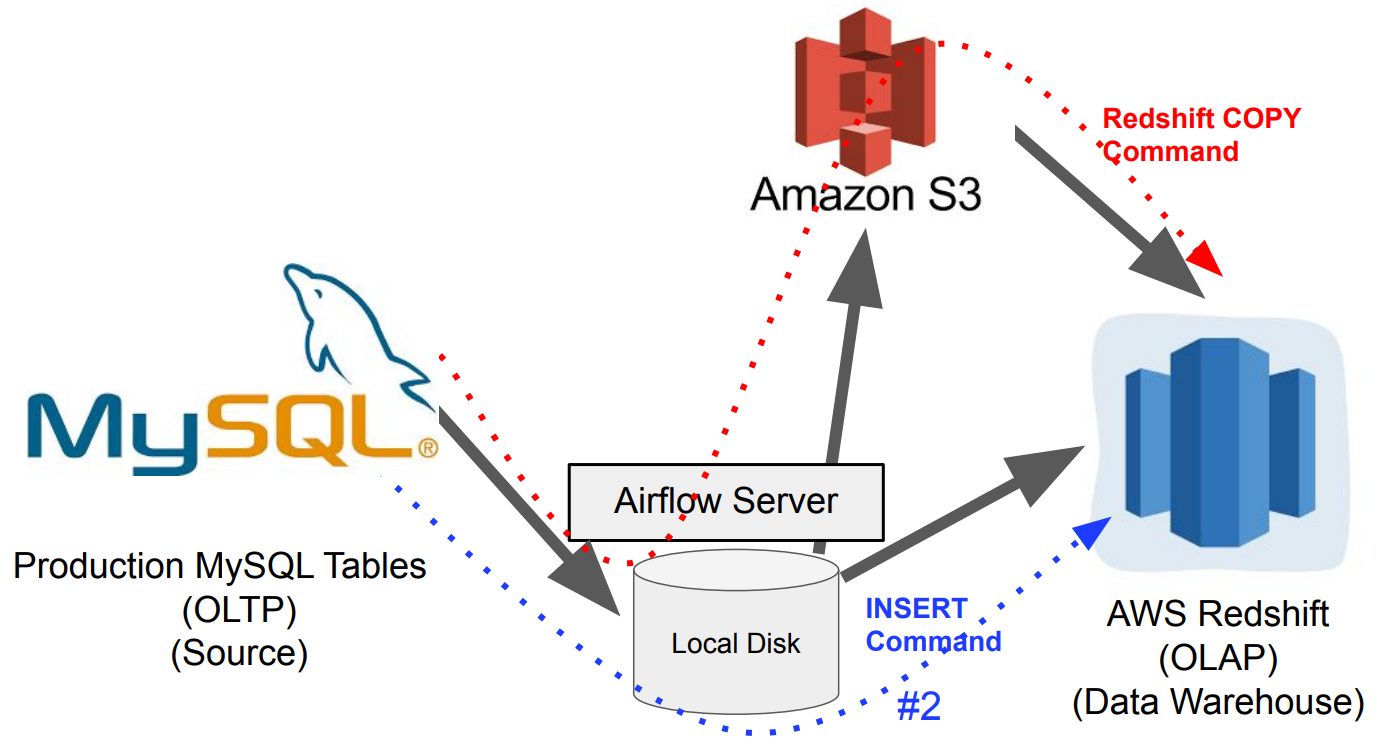
1. MySQL 테이블을 Redshift로 복사 2. Airflow의 Backfill 실행 3. Airflow와 데이터 파이프라인 정리
36.Docker와 Container (TIL 36)
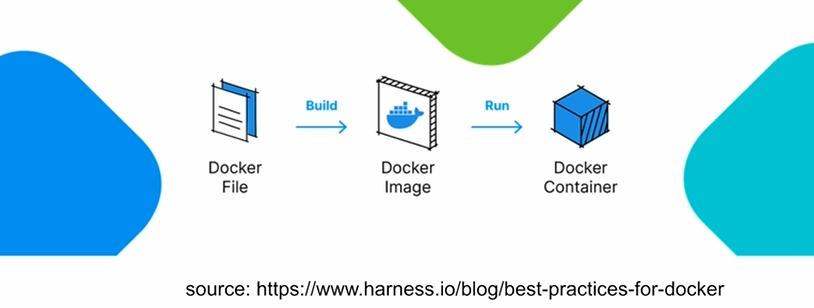
1. Airflow 운영 상의 어려움 2. Docker 소개 3. Virtual Machines vs. Docker 4. Docker 프로그램 개발 프로세스 5. Docker로 프로그램 제작 6. Container로 우분투 실행 7. Root 계정으로 MySQL 실행
37.Docker를 통한 Hangman 서비스 CI/CD 구축 (TIL 37)
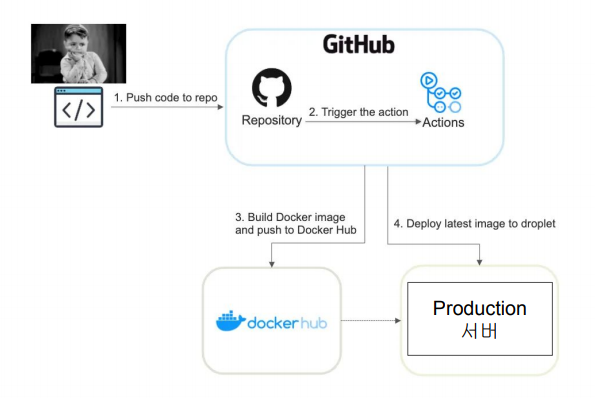
1. Hangman 서비스 2. CI/CD와 Github Actions 3. Github Actions 사용 - Python Application - Docker Image
38.Docker Compose (TIL 38)
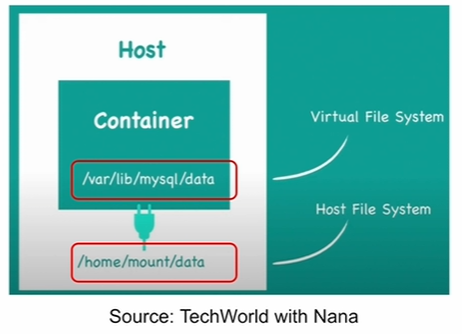
1. Docker Volume이란? 2. .dockerignore란? 3. 다수의 Container로 구성된 소프트웨어 실행 4. Voting application의 docker-compose.yml 개선 5. Airflow의 docker-compose.yml 살펴보기
39.Docker와 K8s (TIL 39)
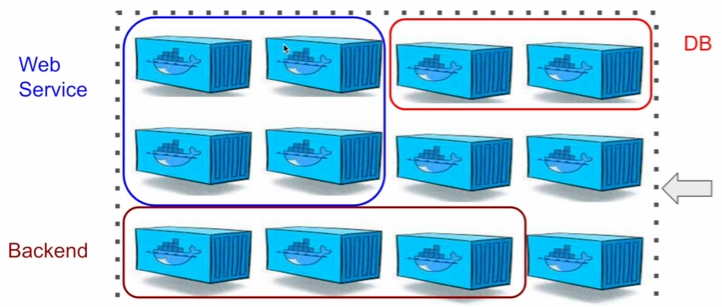
1. Docker 정리 2. 서버 관리의 어려움 3. Container Orchestration 4. K8s 소개 5. K8s 아키텍처 6. K8s/Docker 사용 예시
40.Airflow - ELT 작성과 Slack 연동 (TIL 40)
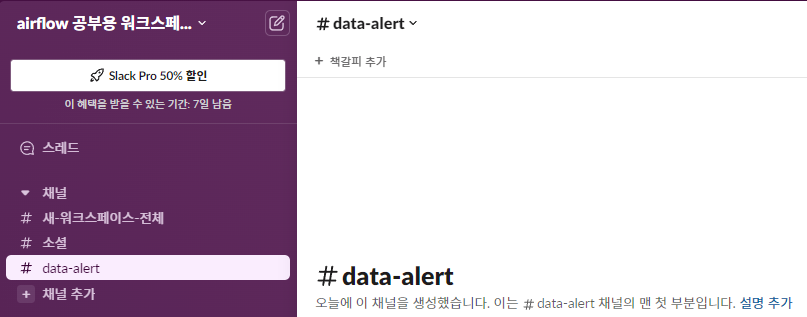
1. Airflow Docker 환경 재설정 2. Summary 테이블 구현 3. Slack 연동
41.Airflow - Google Sheet 연동 (TIL 41)
1. Google sheets -> Redshift table 2. Redshift select -> Google sheets 3. Airflow 모니터링
42.Airflow - Dag Dependencies (TIL 42)
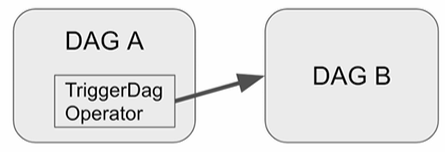
1. Dag Dependencies 2. Sensor & Extra Dag Dependencies 3. Task Grouping
43.Airflow 운영과 대안 (TIL 43)
1. 프로덕션 사용을 위한 Airflow 환경 설정 2. Airflow 로그 파일 삭제 3. Airflow 메타데이터 백업 4. Airflow 대안
44.빅데이터와 분산 처리 시스템(TIL 45)
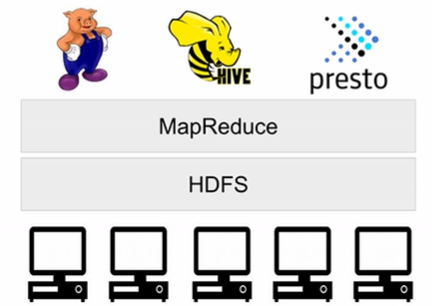
1. 빅데이터의 정의 2. 빅데이터 처리가 갖는 특징 3. 하둡(Hadoop) 4. YARN 동작 방식 5. 맵리듀스 프로그래밍 6. 하둡 설치 7. Spark 8. Spark 프로그램 실행 옵션
45.Spark DataFrame(TIL 46)
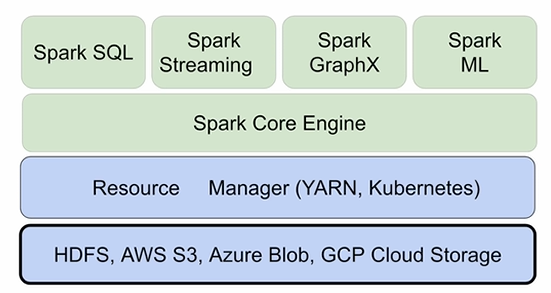
1. Spark 데이터 처리 2. Spark 데이터 구조 3. Spark 프로그램 4. Spark 개발 환경
46.SparkSQL (TIL 47)
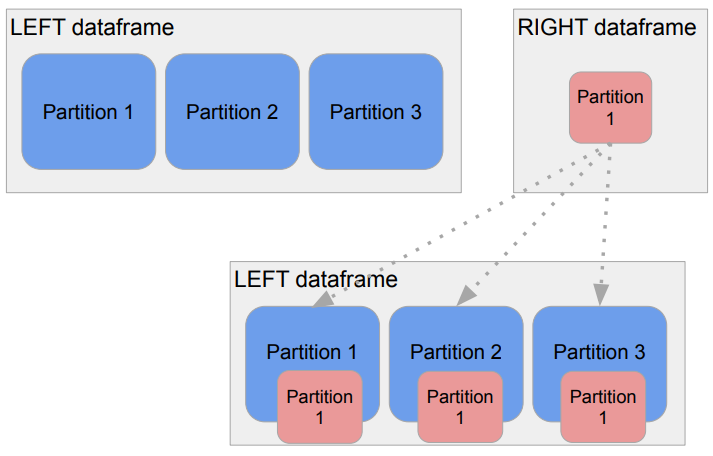
1. Spark SQL 2. JOIN, UDF 3. Hive 메타스토어 사용하기 4. 유닛 테스트
47.DBT (TIL 44)
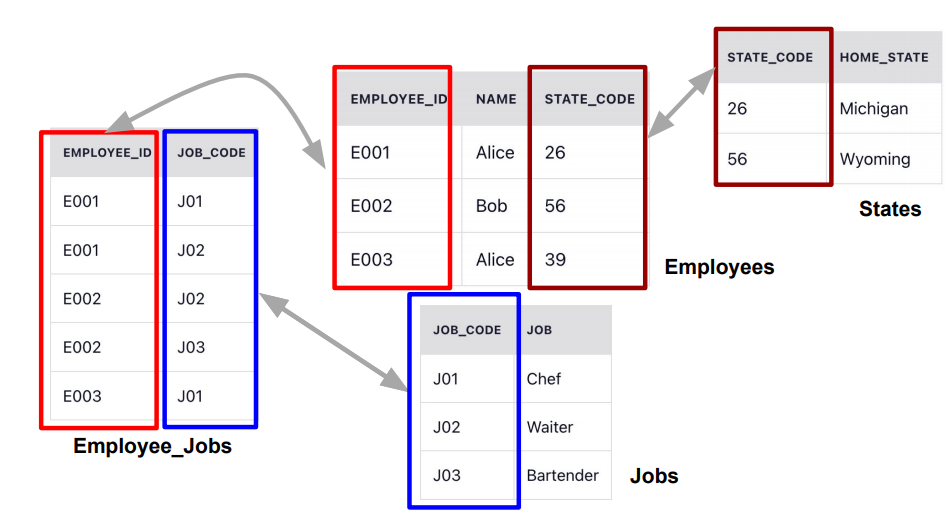
1. Database Normalization 2. DBT
48.Spark 내부 동작 (TIL 48)

1. Spark 파일 포맷 2. Execution Plan 3. Bucketing과 File System
49.Spark ML (TIL 49)
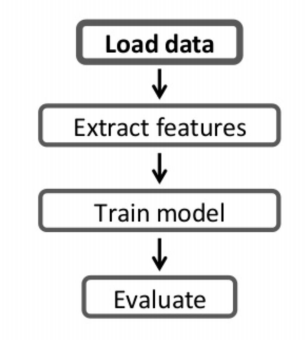
1. Spark ML이란? 2. Spark ML 피쳐 변환 3. Spark ML Pipeline
50.실시간 데이터 처리(TIL 50)

1. 데이터 실시간 처리 2. 실시간 데이터 종류와 사용 사례 3.실시간 데이터 처리 챌린지
51.Kafka (TIL 51)
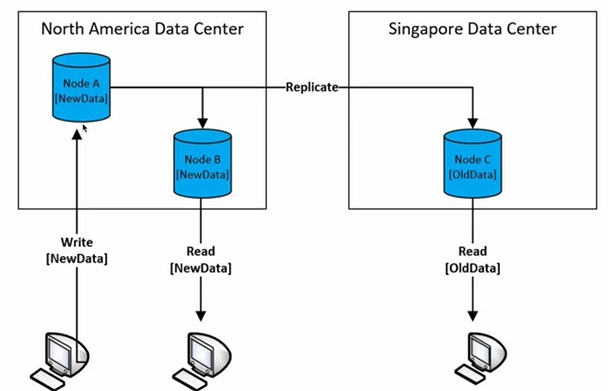
1. Kafka란 2. Kafka 아키텍처
52.Kafka Connect, Schema Registry (TIL 52)
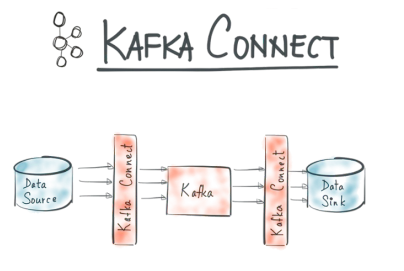
1. Kafka Connect란 2. Kafka Schema Registry