
판다스 특정 문자를 포함하는 행, 특정 조건에 해당하는 행 추출
먼저 다음과 같은 데이터 프레임이 있다.
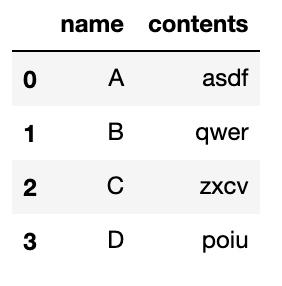
contents 칼럼은 문자열로 이루어져 있는데, 이 중 문자 'w'를 포함하는 행을 삭제하는 작업을 해보자.
for문을 돌려서 해볼 수도 있겠지만 데이터프레임 규모가 큰 경우 시간이 오래 걸린다. 굳이 for문으로 코딩하지 않더라도 코드 한 줄로 원하는 작업을 할 수 있다면 쓰지 않을 이유가 없다.
다음과 같이 코드를 입력하고
test_df = test_df[~test_df['contents'].str.contains('w')]test_df를 확인해보면 'w' 문자를 포함하는 행이 빠진 것을 알 수 있다.
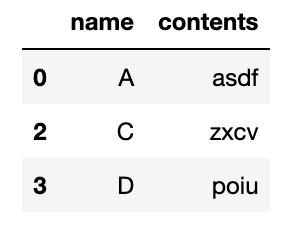
반대로 'w'를 포함하는 행을 찾으려면
test_df = test_df[test_df['contents'].str.contains('w')]이렇게 입력하면 된다.
판다스 데이터 프레임 인덱스 리셋
행을 추출하거나 제거하면서 달라진 인덱스는
test_df.reset_index(drop=True, inplace=True)이 코드를 통해 인덱스를 리셋해주면 된다.
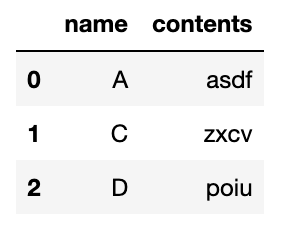
잘 작동하는 것을 확인할 수 있다. 굿
