
Mask R-CNN은 2017년 ICCV에 발표된 논문이다. Object Detection에 Segementation까지 가능하다.
논문 : Mask R-CNN
Mask R-CNN
Abstract
Mask R-CNN은 이미지 내에서 각 instance에 대한 segmentation mask를 생성한다. (Classification + Localization) (여기서 mask는 object detection의 box가 pixel 수준으로 정교해졌다고 생각하면 된다.)
Mask R-CNN은 Faster R-CNN에 mask branch를 더한 것이다. maks branch는 object의 mask를 예측하는 branch이다. Mask R-CNN은 5fps의 속도이며 human pose estimate에서도 사용된다. COCO 2016 challenge에서 1등을 차지했다고 한다.

1. Introduction
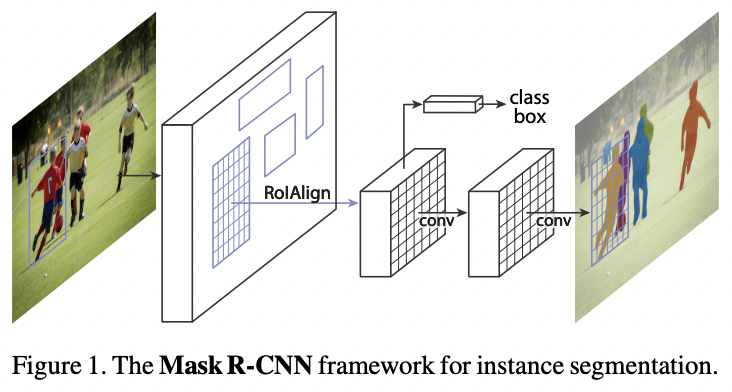
위 그림은 mask r-cnn 구조다.
Mask R_CNN은 instance segmentation을 하기 위한 모델이다. 이것을 위해서는 object detection과 segmentation을 동시에 해야하는데, Mask R-CNN은 기존의 Faster R-CNN을 object detection을 하도록 하고 각각의 RoI에 mask segmentation을 해주는 작은 FC 레이어를 추가했다.
 왼쪽이 Mask R-CNN의 목표이고 R-CNN은 오른쪽이다.
왼쪽이 Mask R-CNN의 목표이고 R-CNN은 오른쪽이다.
기존의 Faster R-CNN은 object detection을 위한 모델이었으므로 RoI pooling 과정에서 정확한 위치 정보를 담아내는 것은 그리 중요한 작업이 아니었다. 그래서 r-cnn의 RoI pooling에서 RoI가 소수점 좌표를 가지고 있을 경우에는 각 좌표를 반올림한 다음에 Pooling을 해주었다. 그런데 이렇게 하게 되면 Input imaged의 원본 위치 정보가 왜곡되게 된다. classification에서는 문제가 발생하지 않지만 픽셀 하나 하나로 detection을 하는 segmentation task에서는 문제가 발생한다. mask r-cnn에서는 이를 해결하기 위해 RoI pooling 대신에 RoI Align을 사용한다.

RoI에서 얻어내고자 하는 정보는 박스 안의 점이다. 위 사진에서 박스 한 칸이 1 픽셀을 의미한다면 점의 좌표는 정수가 아닌 실수가 된다. 그러나 이미지 데이터는 정수 좌표값만 가지고 있으므로 bilinear interpolation의 방법(화살표)으로 점의 값을 구하게 된다. (bilinear interpolation : 참고) 이 역할을 하는 것이 mask branch다. mask branch는 classification, bounding box regression branch와 독립적이며 small FCN(Fully Convolution Network)이다. 구현하기 쉽고 small하기 때문에 연산도 빠르다고 한다. 그리고 mask prediction과 class prediction을 분리했는데, 이로 인해서 mask prediction을 할 때 다른 클래스를 고려할 필요 없이 binary mask를 예측하면 되므로 성능이 향상되었다고 한다.
2. Related Work
R-CNN과 Instance Segmentation에 대해서 설명
3. Mask R-CNN
Mask R-CNN
-
mask r-cnn은 2 stage의 구조를 가짐
- stage 1 : RPN (Region proposal Network)
- stage 2 : Predict class, box offset, 각각의 RoI에 대한 binary mask
-
Loss Function
-
각각의 RoI에 대한 multi-task loss를 적용 (서로 독립적)
-
-
:
- 차원 (: class 개수, : 이미지 해상도)
- average binary cross-entropy loss 사용함.
-
Semantic Segmentation의 경우, 픽셀마다 class와 mask를 예측해야 하므로 계산량이 많은데, 본 연구에서는 class 예측과 mask 예측이 독립적으로 이루어지므로 연산량이 줄어든다.
-
Mask Representation
- 각 RoI마다 FCN(Fully Convolution Network)을 적용하고 이로 인해 공간 정보를 잃어버리는 것 없이 x 크기의 mask를 예측 가능
- 즉 mask느 convolution 연산에 의해 공간적 정보 손실을 최소화할 수 있다
- 실험 결과 fc layer를 사용하는 것보다 파라미터의 수도 훨씬 줄고 정확도가 높게 나옴
- RoIAlign layer를 만든 이유는 mask 정보를 x 형태로 보존하기 위해서는 RoI feature가 요구되기 때문
RoIAlign
- RoIPooling
- RoIPool은 각 RoI에서 small feature map을 추출하기 위한 표준 연산
- RoIPool : 다른 사이즈의 Region Proposal이 들어와도, max pooling을 이용하여 output size를 동일하게 만듦 (Faster R-CNN에서 나오는 개념)
- RoIPool은 RoI를 feature map으로 quantization하게 되는 데, 이 과정에서 RoI와 추출된 feature 사이에 오정렬을 초래하며 픽셀 단위로 예측하는 mask에 큰 악영향을 끼침
- 이 단점을 해결하기 위해 추출한 feature를 input에 적절하게 정렬하는 RoIAlign layer를 제안했다.
- RoIPool은 각 RoI에서 small feature map을 추출하기 위한 표준 연산
- RoIAlign
- bilinear interpolation 연산을 사용하여 각 RoI bin의 샘플링된 4개의 위치에서 input feature의 정확한 값을 계산
- 그 후 결과를 max 또는 평균낸다.
- Faster R-CNN의 quantization은 사용되지 않음
- 4.2에서 RoIPool, RoIWarp, RoIAlign의 실험 결과 비교함
Network Architecture
- BackBone
- 이미지의 feature를 추출하기 위해 사용
- ResNet과 ResNeXt의 50, 101 layer과 FPN(Feature Pyramid Network)을 backbone으로 사용
- Head
- Bounding Box Recognition (Classification and Regression)과 Mask Prediction을 위해 사용됨
- Faster R-CNN의 Head(Classification and Regression)에 Mask branch를 추가
- backbone(ResNet, FPN)에 따라 Head의 구조가 달라짐
3.1 Implementation Details
-
Training
- 는 오직 positive RoI에 의해 정해진다. (GT와의 IOU가 0.5 이상인 것)
- 이미지의 크기는 800픽셀
- 미니 배치에 2장의 이미지 사용됨
- 각 이미지에는 N개의 샘플링된 RoI가 있음. (ResNet N = 64, FPN N = 256)
- GPU : 8개, mini batch : 16, epoch : 160,000, lr : 0.02, weight decay 0.0001, momentum 0.9
- ResNeXt만 mini batch 당 1장의 이미지, lr은 0.01
-
inference
- ResNet은 proposal 300, FPN은 100
- box prediction 후 NMS(Non-Maximum Suppression) 적용
- Mask Branch는 score 점수가 높은 상위 100개 box에서 적용됨. 이는 속도와 정확도 향상에 도움
- mask Branch는 각 RoI마다 K개의 Mask를 예측 (K : classification branch에서 예측된 class들)
4. Experiments: Instance Segmentation
AP, AP50, AP75, APS, APM, APL 6가지를 포함하는 COCO metrics를 통해 성능을 측정하였으며 AP는 mask IoU를 의미
4.1. Main Result
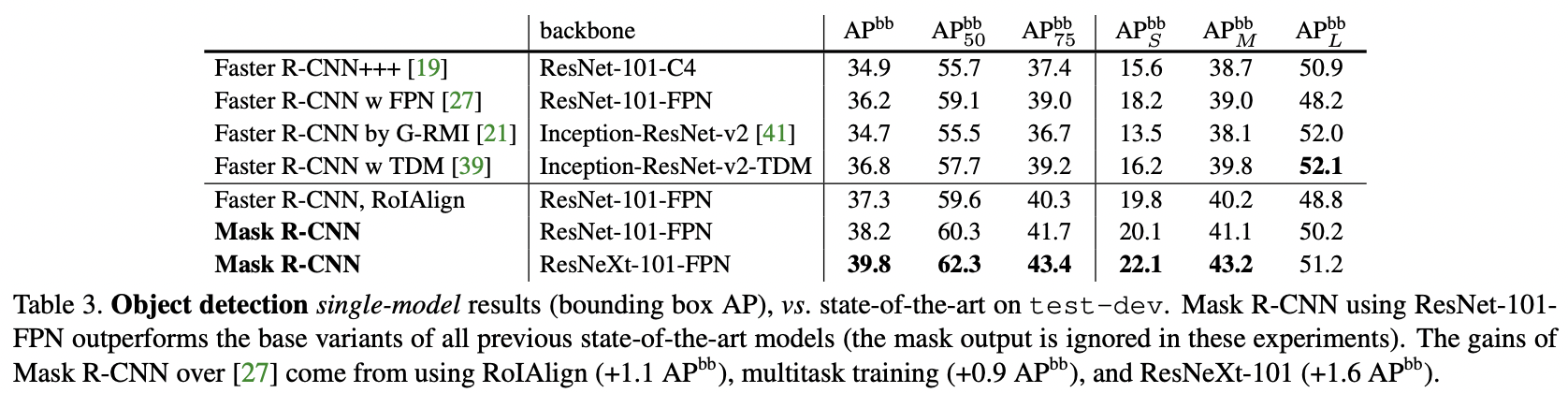
Mask R-CNN이 모든 기존의 SOTA 네트워크보다 뛰어난 성능을 보였다. ResNet-101-FPN을 BackBone으로 갖는 Mask R-CNN이 FCIS+++보다 우수한 성능을 보였다.

FCIS와 Mask R-CNN 결과의 비교

4.2. Ablation Experiments
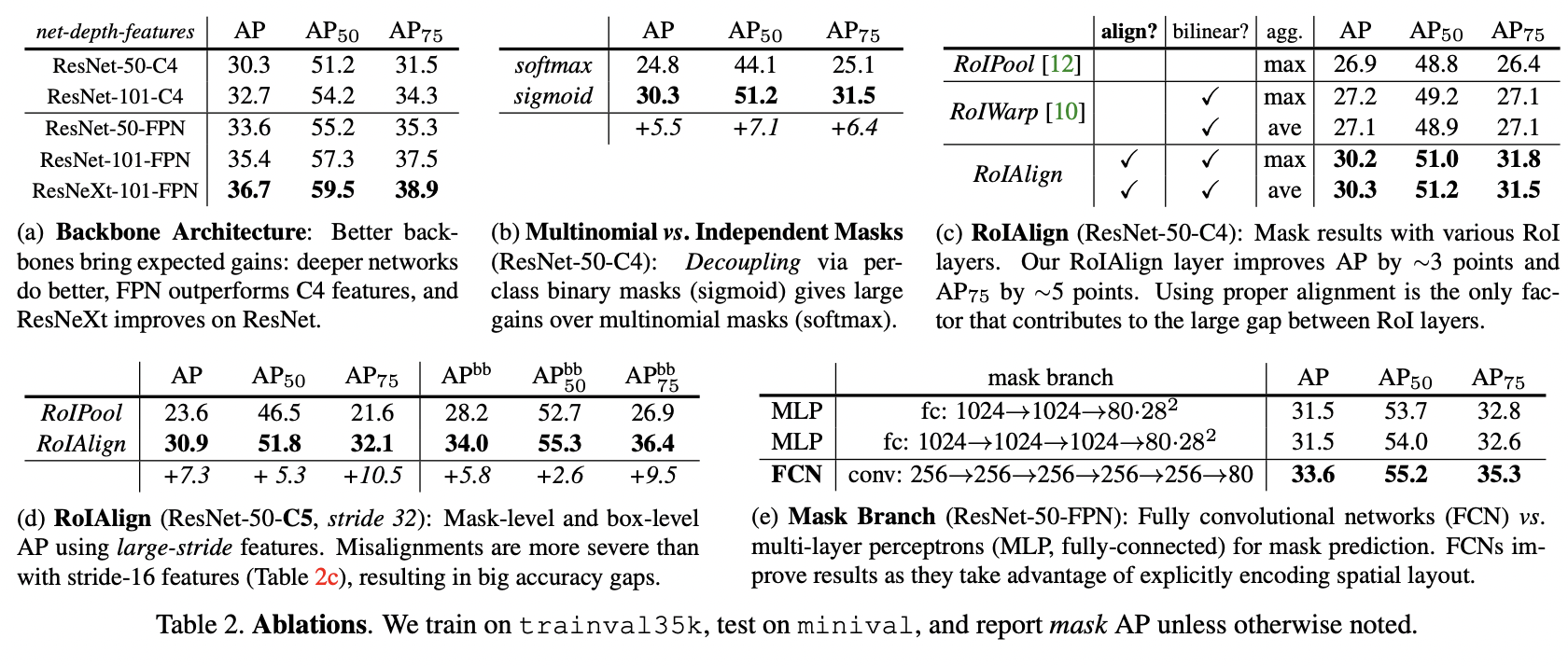
(a) : 네트워크의 깊이가 깊을수록 좋은 성능
(b) : mask branch를 분리한 sigmoid가 좋은 성능
(c)(d) : RoIAlign이 더 좋은 성능
(e) : Mask Branch에 MLP를 사용하는 것보다 FCN을 사용하는 것이 더 좋은 성능
4.3. Bounding Box Detection Result
4.4. Timing
- Inference
- Nvidia Tesla M40 GPU에서 이미지 1개당 195ms 소요
- Training
- ResNet-50-FPN backbone, COCO trainval135k로 학습 시 32시간 소요
- ResNet-101-FPN은 44시간 소요
5. Conclusion
Mask R-CNN은 Faster R-CNN에 간단하게 작은 FCN을 추가해주어 다양한 computer vision tasks를 가능하게 했다.
참고자료
논문
Official Code
CMD님의 티스토리
To make me better 블로그
Lunabot87님의 티스토리
