link: https://arxiv.org/pdf/1911.12423.pdf
NeurIPS 2020
Abstract
- 심층 신경망으로 multi task learning을 수행하는 일반적인 방법은 initial layer를 공유하고 adhoc point(임시 지점)에서 분기하는 수작업 방식이거나 additional feature sharing/fusion mechanism이 있는 별도의 task-specific network를 통해 수행됨
- 자원 효율성을 고려해 최고 인식 정확도를 달성하기 위해 어떤 작업에서 무엇을 공유할지 결정하는 AdaShare라는 adaptive sharing approach를 제안
- 주요 아이디어
- multi task network에서 주어진 task에 대해 어떤 layer를 실행할지 선택하는 task-specific policy를 통해 공유 패턴을 학습
- standard back-propagation을 사용하여 네트워크 가중치와 공동으로 task-specific policy를 효율적으로 최적화
1. Introduction
- MTL의 근본 과제는 여러 작업의 효율적인 학습을 위해 어떤 task 간에 어떤 param을 공유할지 결정하는 것
- 이전에는 shared initial layer로 구성된 수동 설계 architecture에 의존, 그 후 network의 임시 지점에서 동시에 분기됨(hard param sharing)
- 최근에는 deep multi-task learning에서 일련의 task별 network가 feature sharing/fusion과 함께 사용되어 보다 유연한 multi-task learning (soft param sharing)
- 그러나 모델의 크기가 작업 수에 비례하여 증가하기 때문에 계산/메모리 효율적이지 않음
- 본 논문에서는 최적의 MTL 알고리즘이 모든 작업에서 높은 정확도를 달성해야할 뿐만 아니라 task 수가 증가함에 따라 새로운 네트워크 param 수를 최대한 제한해야 한다고 주장
- AdaShare
- MTL에서 주어진 task에 대해 실행할 계층을 선택적으로 선택하는 task-specific policy를 통해 feature sharing pattern을 학습
- deep MTL에서 여러 task(어떤 task 간에 어떤 layer를 공유할지)에 걸쳐 feature sharing pattern을 적응적으로 결정하기 위한 새롭고 차별화 가능한 접근 방식
- Gumbel Softmax Sampling을 통해 standard backpropagation을 사용하여 네트워크 가중치와 공동으로 feature sharing pattern을 학습해 효율성 높힘
- task 간 효과적인 knoweldge 공유를 통해 compact한 MTL 네트워크 학습을 위한 두 가지 loss term과 optimization에 도움이 되는 커리큘럼 학습 전략 소개
2. Related Work
multi-task learning
- 초기에는 shallow classification model을 사용해 작업 간 feature sharing을 연구
- deep neural network에서 hidden layer의 hard/soft param 공유
- convolutional filter grouping, greedy optimization based on task affinity measures로 multi branch network 구조를 학습하려고 시도한 방법 몇 가지 불과
- soft param sharing: cross-stitch, sluice, NDDR 등
Neural Architecture Search
- network architecture의 설계를 자동화하는 것이 목표, reinforcement learning, evolutionary computation, gradient-based optimization 등의 전략 사용하여 연구됨
Adaptive Computation
- computational efficiency 향상 목표로 신경망에서 정보를 동적으로 route하기 위해 제안됨
- BlockDrop: ResNet이 상대적으로 얕은 네트워크의 앙상블처럼 행동한다는 사실 이용해 추론하는 동안 샘플당 어떤 레이어를 실행할지 동적으로 선택하는 학습을 통해 추론 시간 단축
- Routing networks: RL에 의해 훈련된 재귀적 정책 네트워크 사용해 비선형 함수를 적응적으로 선택하기 위해 제안
- 전이학습에서 SoptTune: fine-tuning 되거나 pre-trained layer 통해 적응적으로 정보를 route
3. Proposed Method
- 어떤 layer에서 어떤 task를 공유해야할까?를 결정하는 adaptive feature sharing mechanism
Approach Overview
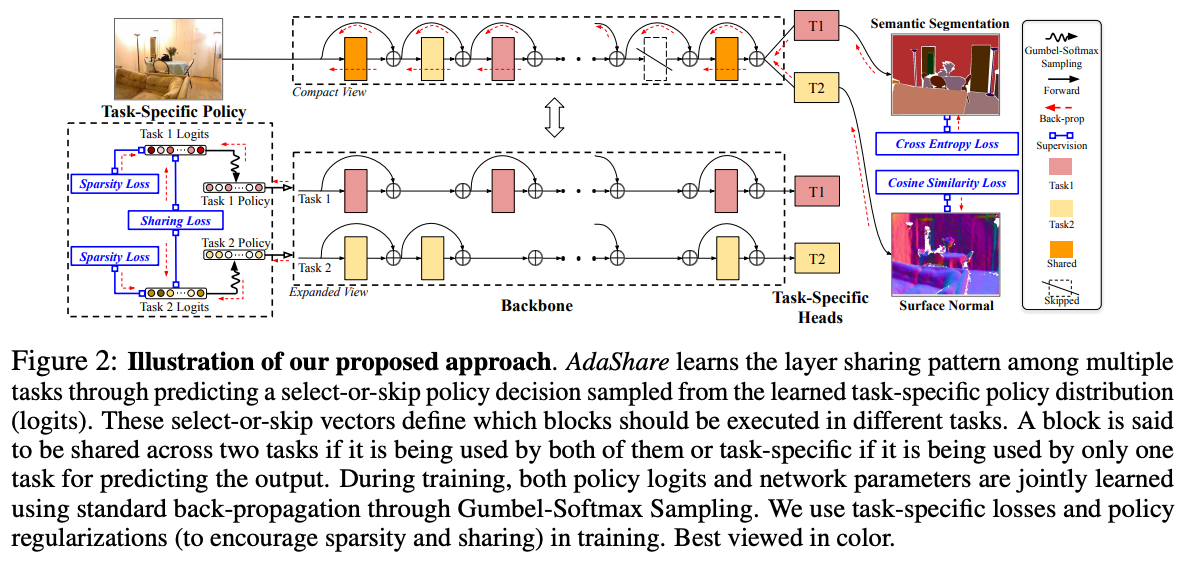
- 일반적으로 task 를 해결할 때 심층 신경망의 l-th layer를 실행하도록 선택할지/생략할지 결정하는 각 layer에 대한 binary random variable (a.k.a policy)를 찾아 task 집합 에 대해 최고의 성능 산출
- shorcut connection은 layer 제거를 탄력적으로 만들어 도움이 됨. 본 논문에서는 개의 residual blocks와 함께 ResNet을 사용하는 것을 고려
- Residual block은 두 task 모두에서 사용되는 경우 task에 걸쳐 공유되거나 출력 예측을 위해 한 task에만 사용되는 경우 task별로 공유된다고 함
- 이러한 방식으로 모든 block과 task()의 선택 또는 선택 정책은 주어진 작업 집합 에 대한 adaptive feature sharing mechanism을 결정
- U에 대한 potential configurations의 수가 block 및 task의 수에 따라 기하급수적으로 증가하는 이므로 MTL에서 최적의 feature sharing pattern을 얻기 위해 U를 수동으로 찾는 것은 어려움
- 따라서 Gumble-Softmax Sampling을 통해 standard back-propagation을 통해 네트워크 매개변수 W와 공동으로 U를 최적화
Learning a Task-Specific Policy
- 설계된 loss func에서 standard back-propagation을 통해 selector-or-skip 정책 U와 네트워크 가중치 W를 공동으로 학습
- 각각의 select-or-skip 정책 는 이산적이고 미분 불가능이므로 직접 optim 어려움 ⇒ 해결 이해 Gumbel-Softmax Sampling 채택
Gumble-Softmax Sampling
-
discrete distribution의 원래 non-differentiable sample을 해당 Gumbel-Softmax distribution의 미분할 수 있는 sample로 대체할 수 있는 간단하고 효과적인 방법
-
를 최적화하려는 binary random variable 의 distribution vector
-
여기서 logit 는 l-th block이 task 에서 실행하도록 선택될 확률
-
task 에서 l-th block에 대해 select-or-skip decision 를 직접 sampling하는 대신, 다음과 같이 생성
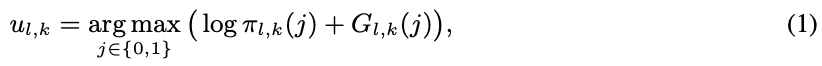
- 는 균일한 i.i.d distribution Unif(0, 1)에서 샘플링된 를 갖는 standard Gumble distribution임
- 미분할 수 없는 arg max 연산을 제거하기 위해 Gumble Softmax trick은 를 one-hot-encoding에서 연속적인 로 변환하는 reparameterization trick이라는 방법을 사용해 이루어짐

- 과 는 softmax의 temperature를 나타내며 >0인 경우 Gumble-Softmax distribution 가 smooth해지며 그럴 때 (또는 )를 gradient descent로 직접 최적화 가능
- 이후 모든 에 대해 모든 discrete policy 를 동시에 최적화
- 이 policy distribution 학습 후, 학습된 policy distribution p(U)에서 sampling하여 task-specific decision U를 얻음
Loss Functions
- Gumble-Softmax Sampling을 하게 되면 gradient가 흐를 수 있게 되는데, 이를 통해 logit 를 update할 수 있게 됨
- 이러한 update를 위해 사용하는 loss term
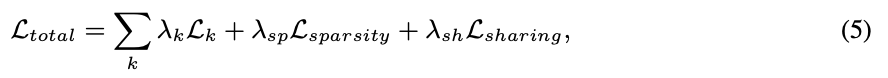
- : 각 task가 갖는 고유의 loss term(classification-cross entropy)

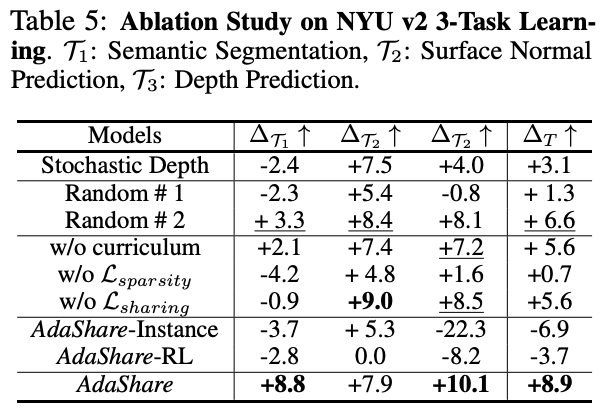
- Sparsity Regularization term인 는 logit 를 minimize하여 model을 compact하게 해주는 효과

- Sharing loss term은 에서 같은 간의 격차를 줄여 모두 task-specific한 block만 남지 않게함
- 맨 뒤 block부터 가중치를 낮게 부여하여 앞으로 갈수록 높게 부여하는 형식으로 앞 block은 최대한 sharing을 하고, 뒤 block에서 task-specific하게 구성되도록 함
Training Strategy
- for better convergence, policy 학습에 좋은 starting point를 제공하기 위해 hard-param sharing
- 초기 훈련 단계에서 전체 decision space를 최적화하는 대신 decision space를 점진적으로 확대하고 쉬운 것에서 어려운 것으로 set of learning tasks를 형성
- policy distribution param이 완전히 훈련된 후, 새로운 네트워크를 형성하고 전체 훈련 set을 사용하여 최적화하기 위해 최선의 policy에서 select-or-skip decision, 즉 feature sharing pattern을 샘플링
Parameter Complexity
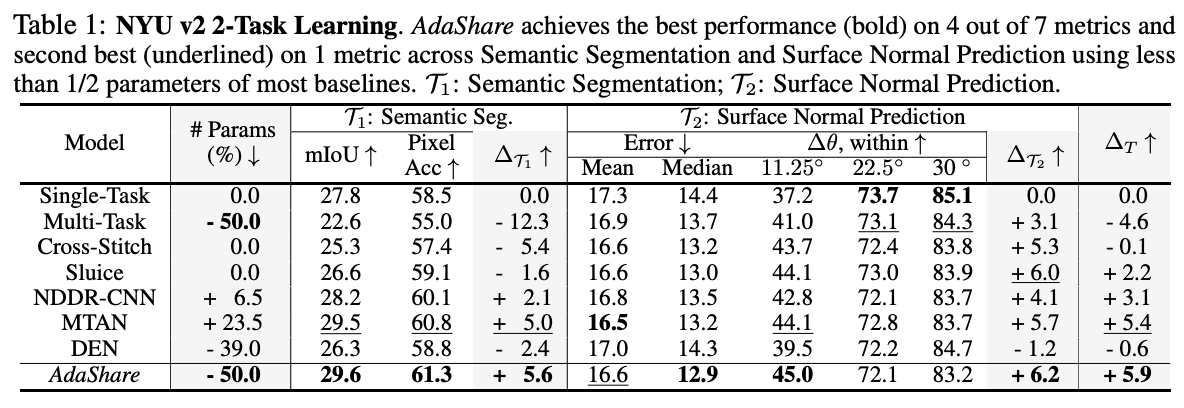
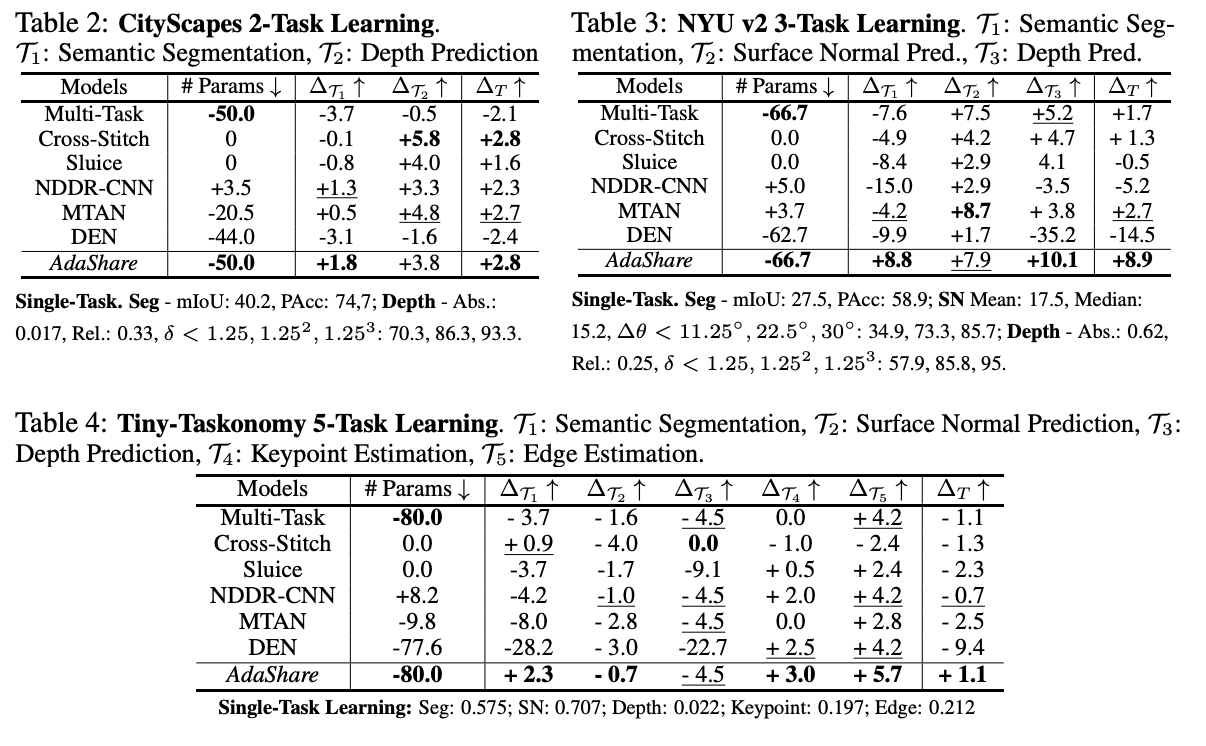
- Adashare는 최근의 deep multi-task learning 방법에 비해 상당히 낮은 매개 변수 수를 가지고 있음(2 task 학습 동안 약 50% 낮음)
4. Experiment

5. Conclusion
- MTL에 대한 feature sharing 전략을 적응적으로 결정하기 위한 접근 방식 제시
- negative transfer 현상을 회피하고 positive transfer를 보강하여 MTL에 있어서 network의 parameter 수를 유지하면서 성능을 끌어올림
- RL을 적용할 경우, search space가 커지는 현상을 Gumbel Softmax Sampling을 통해서 optimization problem으로 변환하였고, 이를 통해 computational resource를 절약할 수 있는 방법을 제시
- standard back-propagation을 사용해 feature sharing policy와 network weight를 함께 학습하며 중요한 param을 추가하지 않고 학습
- 여러 task에 걸쳐 최상의 성능을 달성하며 훨씬 적은 param을 가진 간결한 multi task network 학습하기 위한 두 가지 자원 관리 정규화 기법 소개
