
arXiv 2017
link: https://arxiv.org/pdf/1706.05098.pdf
1. Introduction
- 머신러닝 작업 시: 하나의 모델 훈련 / 복수의 모델 훈련 후 앙상블 → 이후 fine tuning
- 어지간하면 위 방법으로 목표 성능 도달 가능하지만 해당 모델의 도움이 되었을 수도 있는 연관된 데이터 활용 어려움
- 문제 해결 위해 Multi Task Learning (MTL) 연구됨
2. Motivation
3. Two MTL methods for Deep Learning
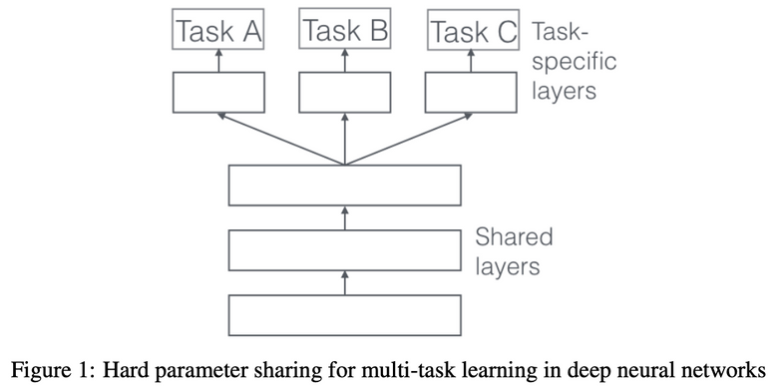
3.1 Hard Parameter Sharing
- 가장 흔히 사용됨
- Hidden Layer 공유하고 task별로 일부 개별적인 layer 가지는 형태 → overfitting 방지
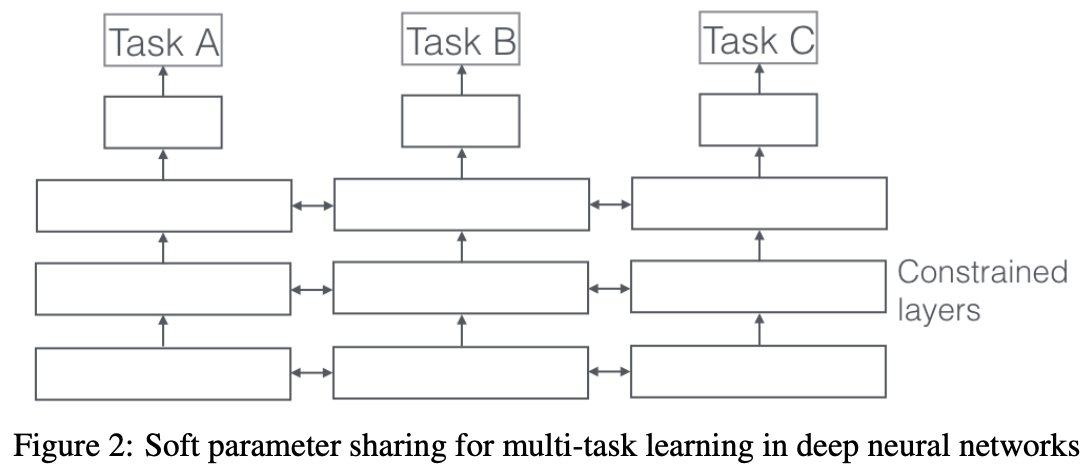
3.2 Soft parameter sharing
- 각각의 task별로 별도의 layer 가지고 있음
- 각각의 레이어 비슷해질 수 있도록 L2 Distance를 사용
4. Why does MTL work?
4.1 Implicit data augmentation
- 딥러닝은 high dimension data를 딥러닝을 통해 low dimension에서 representation하는 것에 목적이 있음
- 특정한 데이터 셋에 종속적으로 모델을 훈련하는 것보다 다양한 데이터를 활용하여 더 범용적인 representation을 만들어낼 수 있으면 overfitting 회피 가능
4.2 Attention focusing
- task가 매우 지저분하거나 데이터 제한적인 경우 모델이 관련있는 것과 관련없는 것을 구분하기 쉽지 않음
- MTL은 모델에 관련있는 것과 없는 것을 구분하기 위한 추가적인 정보를 제공할 것
4.3 Eavesdropping
- 어떤 feature G가 있을 때 Task A에서 이러한 feature를 학습하기 어려운데 task B에서는 학습하기 용이하다고 하자
- 이 문제를 해결하기 가장 쉬운 방법은 task B를 통해서 feature G를 학습하기에 중요한 포인트를 전달받아 Task A를 훈련하는 것
4.4 Representation bias
- 하나의 task 뿐만 아니라 다른 task에서도 선호되는 representation을 만들 수 있도록 bias를 줄 수 있음
- 이를 통해 모델의 generalization 달성
4.5 Regularization
- MTL은 regularizer → 귀납적인 bias를 제공 ⇒ overfitting의 위험 등을 감소시킴
5. MTL in non-neural models
- MTL은 linear models, kernel methods, Bayesian algorithms에도 사용됨
- 두 가지 메인 아이디어
- norm 정규화를 통해 enforce sparsity across tasks
- task 사이의 관계 모델링
5.1 Block-sparse regularization
- 일반적인 딥러닝 모델 → 행렬 각 원소에 대해 정규화 수행하여 희소성 억제함
- block-sparse regularization은 가중치 블록 전체에 대한 sparse를 유지하려고 시도 → 모델이 특정 작업 수행하는 데 필요한 중요한 특성을 더 강조할 수 있음
- 모델이 작업 간 공유되는 정보 활용하면서도 작업별로 효과적으로 가중치 할당할 수 있도록 도움 → 학습 속도 및 모델의 일반화 성능 향상
5.2 Learning task relationships
- 작업 간 relation 활용하는 방법 중 하나는 한 작업에서 학습한 지식을 다른 작업으로 전이하는 것임. 이를 통해 데이터가 제한적인 작업에서도 모델의 성능 향상 가능
- shared representations: 모든 task에서 공통으로 사용되는 중요한 특성이나 representation을 학습하여 모델의 일반화 성능을 향상
6. Recent work on MTL for Deep Learning
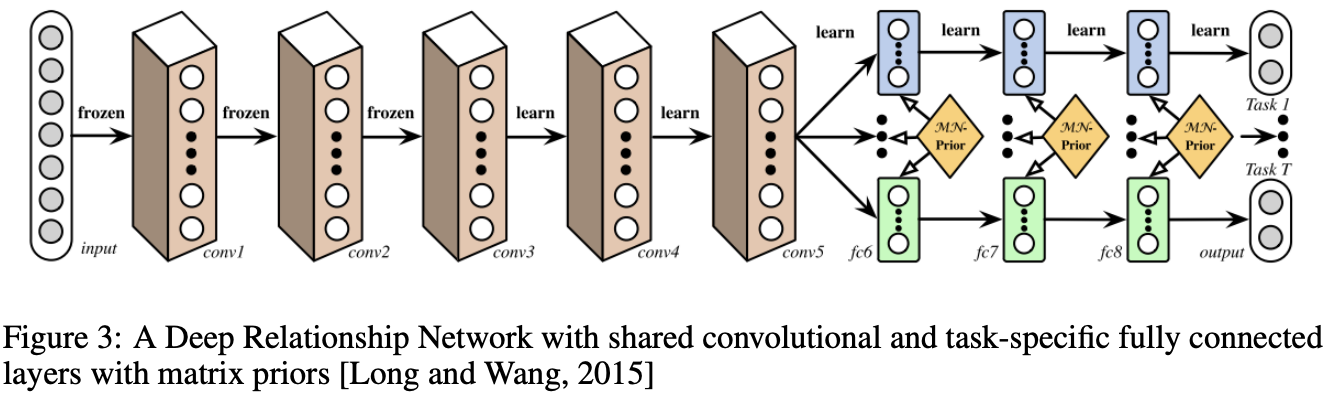
6.1 Deep Relationship Networks
- CV에서 MTL은 task-specific fully-connected layer를 학습하면서 convolutional layer를 공유
- 이것을 deep relationship network를 통해 발전시킴
- 공유된 task specific layer에 더하여 fully connected layer 전에 matrix priors를 배치(노란색) ⇒ Bayesian model처럼 모델이 task간의 관계를 학습하도록 함
6.2 Fully-Adaptive Feature Sharing
- bottom-up approach: thin network에서 시작해 학습시 비슷한 task의 grouping을 촉진하는 기준을 가지고 넓혀감
- but 이 greedy method는 globally optimal한 모델을 찾아내지 못함

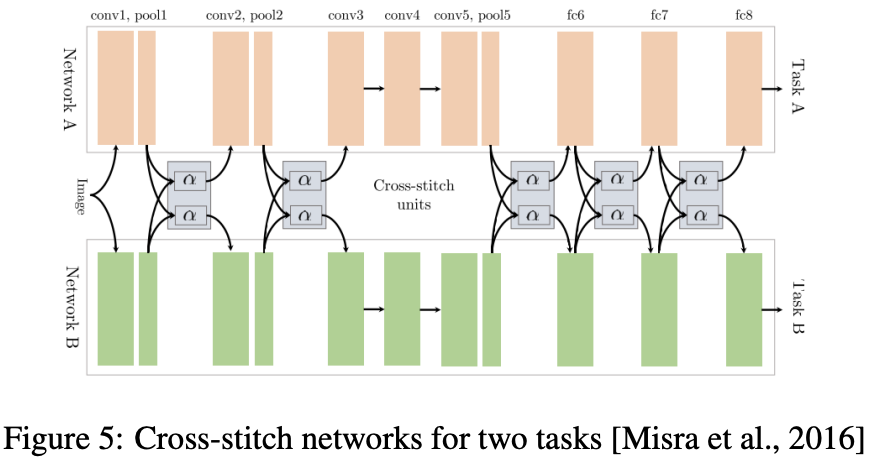
6.3 Cross-stitch Networks
- soft parameter sharing과 같은 두 개의 분리된 모델
- pooling과 fully-connected layer 이후에 cross-stitch units를 배치
6.4 Low supervision
- 대조적으로 NLP에선 최근에 MTL을 위해 더 나은 task hierarchies 구조를 찾고 있음
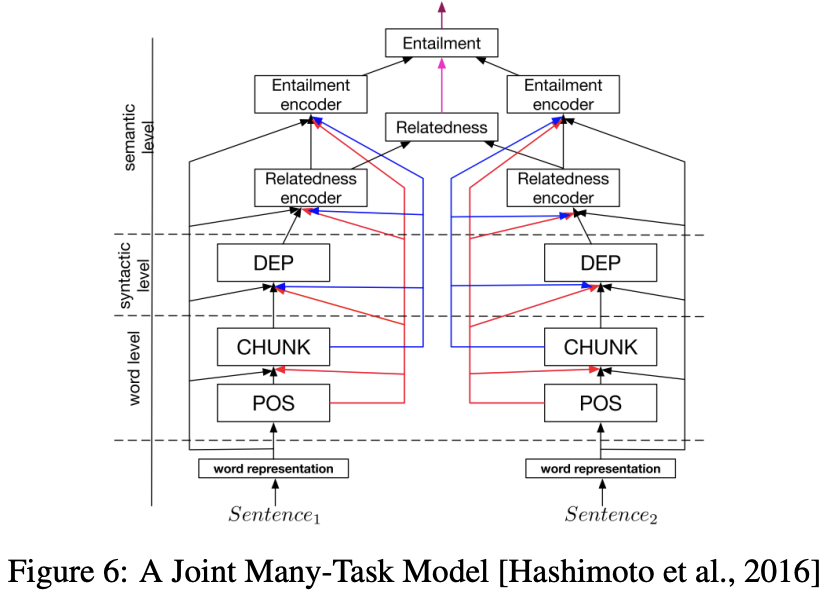
6.5 A Joint Many-Task Model
- 몇 개의 NLP 모델로 구성된 hierarchical architecture
6.6 Weighting losses with uncertainty
- sharing 구조를 학습하는 대신 각 task의 불확실성 고려하여 orthogonal한 독립적인 approach를 가짐
- task 독립적인 불확실성을 가지고 gaussian likelihood를 최대화하는 multi task loss func를 통해 각 task의 weight를 조정

6.7 Tensor factorisation for MTL
- tensor factorisation을 통해 행렬 인수분해 접근법 중 일부를 일반화하여 model param을 모든 layer에 대해 공유하고 task-specific param으로 분할
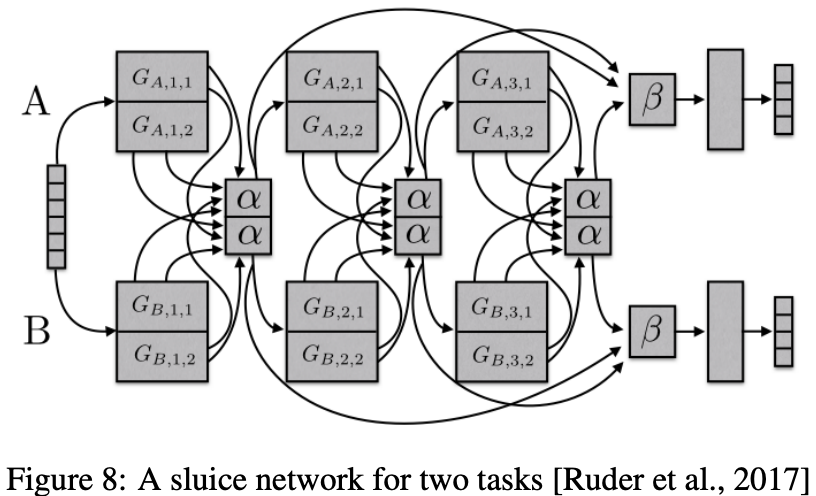
6.8 Sluice Networks
- deep learning 베이스의 MTL approach를 일반화하는 모델(다양한 기법 복합적으로)
- 어떤 layer에 네트워크가 입력 sequence의 best representation을 가지는지
- 어떤 layer, subspace가 share되어야 하는지
6.9 What should I share in my model?
- MTL에서 대부분의 approach는 어디에서 task가 drawn되어야 하는지에 초점을 맞춤 → sharing에는 유용하지만 항상 그렇진 x
- MTL을 위한 robust 모델을 발전시키기 위해서는 관련없거나 loosely하게 관련있는 task를 다뤄야 함
- 하나 이상의 loss func를 optim하고 있으면 MTL을 하는 것과 같음
- 모델이 task에 대한 지식을 같은 parameter로 compress하도록 제한하기보다는 MTL처럼 task들이 서로 interact하도록 하는 것이 효율적
7. Auxiliary tasks
- 어떻게 최적의 auxiliary task를 찾을 수 있을까
7.1 Related task
- MTL에서 related task를 파악하기 위한 중요한 예(메인/보조)
- 자율주행 자동차의 조향 방향 예측 / 도로의 다양한 특성 예측하는 작업
- 얼굴 랜드마크 감지 / 머리 포즈 추정 및 얼굴 속성 추론
- 쿼리 분류 및 웹 검색 공동 학습
- 영상에서 클래스 및 객체의 좌표 공동 예측
- text-to-speech에서 음소 지속 시간과 빈도를 공동 예측
7.2 Adversarial
- related task에 대한 labeled data는 자주 이용할 수 없게 됨 but 얻고자 하는 것의 반대의 task에 접근 가능
- training error를 최대화하는 경우 adversarial task는 입력의 domain을 예측하는 것
7.3 Hints
- auxiliary task를 이용하는 것은 힌트 사용과 같음
- NLP
- 입력 문장의 감정 분석을 위한 보조 작업: 긍정 또는 부정 감정 단어를 포함하는지 예측 등
7.4 Focusing attention
- auxiliary task는 network가 무시하고 있는 이미지의 부분에 대해 집중하게 함
7.5 Quantization smoothing
- 많은 task들은 training 목표가 quantized 되어 있음 ⇒ 이 경우 less quantized auxiliary task들을 사용하는 게 더 유용할 것
7.6 Predicting inputs
- input으로는 실용적이지 않은 feature도 있음 → input보단 output으로 사용
7.7 Using the future to predict the present
- 예측 이후 이용 가능한 feature 만들어질 수 있음
- 이 경우 모델 training 중에 additional knowledge로서 auxiliary task로 이용 가능
7.8 Representation learning
- MTL에서 auxiliary task의 objective는 모델이 main task에 대해 공유되거나 도움되는 representation을 학습할 수 있도록 하는 것
- autoencoder objective는 auxiliary task로 사용될 수 있음
7.9 What auxiliary tasks are helpful?
- auxiliary task를 찾는 것은 assumption임. main task 예측에 도움이 되어야하며 관련있어야 함
- similar/related를 구별하기 위한 좋은 개념 아직 없음
- similar: 같은 feature 사용
- related: common optimal hypothesis를 공유
- 어떤 task가 선호되어야하는지 알기 위해 task similarity에 대한 notion 필요
8. Conclusion
- MTL의 역사와 최근 연구 살펴봄
- what to share에 대한 학습의 발전은 유망
- task에 대한 이해
- 유사성, 관계, 계층은 제한적이어서 MTL의 generalization 능력에 대한 이해를 가지기 위해 노력해야 함
