Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under ZeroShot Pedestrian Identity Setting
by Jian Jia, Houjing Huang, Xiaotang Chen, Kaiqi Huang
요약
보행자 속성 인식에 관한 논문이다.
보행자 속성 인식의 특징을 정의하고, 데이터셋을 분할 탐색 알고리즘을 통해 재구성한 뒤, 네 가지 모델을 평가하는 과정을 보여주고 있다.
INTRODUCTION
용어정의
Pedestrian Attribute Recognition
보행자 속성 인식.
보행자를 보고 저 사람이 여자인지 남자인지, 가방을 매고 있는지 아닌지 등등을 판단하여 속성을 부여하는 작업을 말한다.
여기서 보행자란 CCTV의 시점을 생각하면 된다.
놀랍게도 대충의 나이와 대머리인지(..)까지 구분할 수 있다.
Zero-Shot?
일단 제목을 이해하는 데에서부터 문제가 있었다. Zero-Shot이 무엇인가?
AI가 기존의 데이터 셋을 통해 학습되지 않은 부분을 생성하는 것을 말한다.
예를 들어 디즈니 풍의 그림을 학습한 AI가 지브리 풍의 그림을 그리는 것이 제로샷이다. 훨씬 적은 데이터를 필요로 한다는 특징이 있다.
논문의 목적
이 논문의 목적은 총 세 가지다.
- Pedestrian attribute recognition을 정의하는 것
- 기존 데이터 셋의 한계를 드러내는 것
- 실제 환경 속 다양한 recognition performance를 공정하게 평가하기 위한 baseline method를 제공하는 것
아무래도 저자들은 기준의 불명확함에 대해 불만이 많았나보다. 그것이 데이터셋이건 성능 평가건 간에.. 이것들을 명확히 하겠다는 게 앞으로 읽을 논문의 주요 목표이다.
공정한 성능평가 또한 이 논문의 목적 중 하나인데, 보행자 인식 성능이 과대평가되는 문제가 존재했다.
첫 번째는 test set과 training set 속 유사한 보행자의 존재, 두 번째는 네트워크 성능에 따른 격차가 그 문제였다.
아래와 같이 다섯 인물은 거의 같은 수준이다. 이것을 판별한 것이 곧 성공이라고 보기는 어렵다.

왜 '보행자' 인식인가?

보행자 인식은 인물 인식과 무엇이 다른가? 생각해보면 보행자=인간이기 때문에 일반 인물인식과 크게 다를바 없어보인다. 보행자 인식은 왜 정의되어야 하는가?
이에 대한 해답을 저자들은 위의 사진과 같이 제시했다. 인물의 일부가 나오고 주로 고해상도인 일반 인물 사진과는 달리 보행자 속성 인식이 대상으로 하는 사진은 주로 저해상도의 전신 사진이다.
아무래도 CCTV의 범위가 주로 매우 넓기 때문에 고의로 피해가지 않는 이상 전신이 나올 수 밖에 없다.
RELATED WORK
Pedestrian Attribute Datasets
APiS: 최초의 데이터셋. 3661개 이미지.
그 후에도 뭐가 많긴 한데 일단 주류로 사용되는 건 아래 세 가지.
PETA: 1만 9천개 이미지. 61 바이너리, 4개 multi-class attributes.
RAP1:4만개 이상의 샘플. 쇼핑몰의 26개 비디오 카메라로 촬영.
PA100K: 가장 큰 데이터셋
Pedestrian Attribute Methods
두 가지 방법이 있다.
human parsing이나 human key point 등의 정보를 보조적으로 활용하는 방법과 오로지 속성 레이블만을 활용하는 방법.
PROBLEM DEFINITION
Definition
보행자 속성 인식이란 하나의 이미지에 여러 개의 속성 레이블을 할당하는 작업.
test set와 training set는 겹치지 않는 제로샷 설정이며 이는 수식으로 아래와 같다.
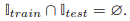
즉 한 집단의 보행자에 대한 이미지를 다른 집단의 보행자 이미지로 잘 일반화시키는 것이 보행자 속성 인식의 본질이다.
Task Comparison (유사 개념)
인간 속성 인식과 개인 재식별이 있다. 다만 인물인식과 보행자 속성인식의 차이는 이미 위에서 다룬 바 있다. (왜 보행자 인식인가? 참조)
그렇다면 개인 재식별과는 어떤 차이가 있을까?
개인 재식별 속성 인식(ReID)과 보행자 속성 인식 간의 차이
위에 제시되었던 것과 동일한 사진이다. 여기 한 사람에 대한 다섯 가지 사진 중 둘은 안경이 보이고, 셋은 뒤통수가 보인다.
ReID의 경우, identity-level annotation를 기본으로 하기 때문에 다섯 가지 사진의 차이를 파악하지 못한다. 다섯 개 사진 모두 ID 0068일 뿐이다.
다만 보행자 속성 인식은 instance-level annotation으로, 사진을 두 분류의 label로 구분한다.
DATASETS
Flaws in existing datasets (기존 데이터셋의 결함)
기존 데이터셋의 경우,
1. 초당 촬영되는 프레임 수가 많아 이미지가 다 비슷함.
2. 한 보행자의 이미지들이 랜덤하게 training set와 test set에 배정(비슷한 이미지 그룹 생성)
다만, PA-100K는 이 문제를 해결하기 위해 한 보행자의 모든 이미지를 한 세트에 배당.
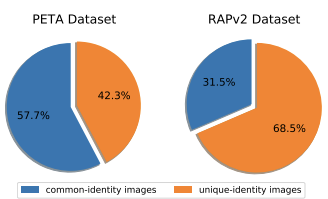
common-identity images: 테스트 세트 속 이미지와 동일한 신원/유사한 이미지가 훈련 세트 안에 존재하는 이미지
위의 표와 같이 unique-identity images의 비율은 적다.
결론. PETA, RAP1 및 RAP2의 테스트 세트가 모델의 성능, 즉 일반화 능력을 과대평가하는 경향이 있다.
Splitting Criterion (기준 제안)

눈물이 나기 시작했다.
한 줄씩 해석해보면,
1) 전체 set는 training set와 validation set, test set의 합집합이고, 셋의 비율은 3:1:1이다.
2) 각각의 set들의 교집합은 공집합, 즉 겹치지 않는다. (제로샷 설정)
3) 뭔소리지
4) validation set와 test set 사이의 샘플 개수 차이 제어
5) validation set와 test set 사이의 속성 분포 차이 제어
1, 3, 4는 효과적이고 믿을만한 validation set 제공을 위함
Existing Datasets and Proposed Datasets (기존 vs 제안 데이터셋 비교)

위의 그래프는 PETA 데이터셋의 테스트 셋 속 common과 unique한 이미지들 간의 성능 차이를 나타낸다.
common한 이미지, 즉 training과의 유사 이미지는 성능이 높게 측정되는 반면, unique 이미지는 성능이 낮게 측정되었다.
이것은 이미지 세트의 유사성에 따라 같은 모델의 성능이 다르게 평가될 수 있다는 것으로 평가의 불명확함을 반증한다.
저자들이 유효하지 않다고 주장하는 RAPv2 또한 같은 양상을 보인다.
그렇기 때문에 저자들은 위에 나온 두 데이터셋을 기반으로 하는 PETAzs와 RAPzs를 새로 제안하고 있다.
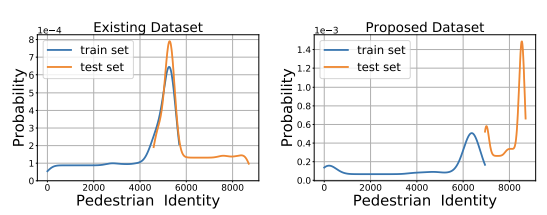
위의 그래프는 PETAzs가 PETA와 달리 test set과 training set 간 ID(동일 인물)가 완전히 분리되었음을 나타낸다. (=두 세트 사이에 같은 인물이 존재하지 않는다.)
PETAzs를 만들기 위해서는 다음과 같은 분할 탐색 알고리즘이 필요하다.

4-18: 제로샷 검증.
7, 9: validation set와 test set 간의 이미지와 ID 수의 차이를 임계값을 통해 제한한다. (왜 하는거지?)
23: 각 집단의 속성분포의 차이가 임계값 Tattr 이하로, 골고루 속성이 분포되었는지 검증 후 return한다.
이 과정을 총 5번 반복하면 5개의 제로샷 데이터셋을 얻을 수 있다. 다섯 개 데이터 셋 간의 유의미한 차이가 존재하지 않았으므로, 저자들은 그 중 하나씩을 PETAzs, RAPzs로 채택했다.
METHODS
Task Formulation and Baseline Method
무슨 말인지 모르겠당
대충 기준모델 (모델이 유효한지 검증하는 최저선) 설정 중
Evaluated Methods (평가 방법)
채택된 메소드는 총 네 가지로, MsVAA, VAC, ALM, JLAC가 그것이다.
앞의 RELATED WORKS-Pedestrian Attribute Methods에서 다루었던 두 가지 종류 중 오로지 속성 레이블만을 활용하는 메소드만 채택했으며, 이는 기존 데이터세트를 평가하기 위한 본 논문의 특성 상 보조 도구를 사용하는 것이 목적에서 벗어나기 때문이다.
네 가지 메소드에 대한 소개가 원문에 나와있으나, 별로 안 중요해보여서 그냥 넘어간다.
EXPERIMENTS
구현 세부 정보와 기존 데이터셋(PETA)과 제안 데이터셋(PETAzs)의 차이가 작성된 섹션이다.
1) baseline 모델 성능 비교 2) 기존 데이터셋과 제안 데이터셋 비교 3) 다양한 요인에 대한 Ablation study(인과관계 파악) 진행
Datasets and Evaluation Metrics
사용되는 데이터셋은 총 여섯 개로, PETA, RAP1, RAP2, PA100K의 네 가지 기존 데이터셋과 앞에서 새로이 제안한 PETAzs와 RAPzs, 이렇게 총 여섯 가지이다.
이 중 뒤의 세 가지, 즉 PA100K, PETAzs와 RAPzs만이 보행자 ID를 고려하여 데이터를 분할한 제로샷 데이터셋이다.
본 연구는 또한 균형적으로 분포하는 속성들만을 채택했다.
그 이후
이해를 못했지만 암튼 정리해보면,
Implementation Details
: 실험 조건에 대한 상세 설명. PyTorch 사용, end-to-end training (파이프라인 네트워크 없이 실험) 등
Comparison of our baseline method with those in state-ofthe-art methods
: 우리 baseline이 더 낫다. 최첨단 메소드는 베이스라인 확립이 어렵다. JLAC 빼고 성능 향상을 보였다.
Comparison of our baseline method with state-of-the-art
methods on existing datasets
: 기존 데이터셋 간의 비교. 각각의 모델에서의 결과가 작성되었으며, PETA와 RAP1은 데이터 과적합(데이터가 너무 많아서 정확도가 떨어짐)이 일어나기 쉽기 때문에 데이터 증가에 PA100K보다 더 민감하다.
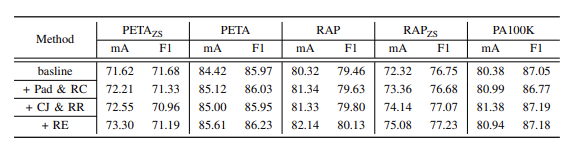
Performance comparison between existing datasets and proposed datasets
1) 새로 만든 기준인 PETAzs, RAPzs가 측정한 성능이 PETA, RAP에 비해 현저히 낮다. (세트 중복 때문에 발생한 일반화 능력 과대평가 제거)
2) PETAzs와 PETA간의 차이가 RAPzs와 RAP 간의 차이보다 크다.
3) 메소드 간 성능 차이 측정의 폭에 대하여, 새로 제안된(zs) 기준이 더 넓은 폭을 가진다. 이는 메소드 간의 차이를 더 뚜렷하게 보여주고 있다는 것을 반증한다.
결론. 새로 제안된 기준이 generalization과 실제 상황 적용의 평가에 있어서 더 적합하다.
이 뒤에는 절제연구애 대한 단락인데 스킵
CONCLUSION
이 논문은 보행자 속성 인식의 정의, 데이터 세트 및 최신 방법에서 보행자 속성 인식의 개발을 검토했다.
보행자 속성 인식이란 인물 전신 저화질 사진을 주요 대상으로 하며, 사용자 ID가 아닌 사용자의 속성을 파악하고, 트레이닝 케이스 외의 처음 보는 인물의 속성도 파악(일반화)할 수 있어야 한다.
이 기준에 따르면 기존 데이터 세트 PETA, RAP1 및 RAP2의 경우 알고리즘 성능이 과대 평가되어 일반화 능력을 제대로 반영할 수 없다. 따라서 이들은 기존 데이터셋을 분할 탐색 알고리즘을 통해 가공하여 제로샷 설정을 지킨 PETAzs, RAPzs를 제안했다.
이 제안된 데이터셋과 기존 데이터셋의 성능을 비교하기 위한 baseline을 작성한 후 제안된 데이터셋이 더 엄격하고 우수하다는 것을 발견했다. 여기에 더하여 과적합의 영향 또한 줄일 수 있고, 다양한 메소드의 장단점이 직관적으로 드러난다는 결론을 도출했다.
글을 대체 이렇게 써도 되는 건가 싶지만, 아무튼 끝!! 다음으로 YOLOv7-Pose에 대한 논문 두 개를 읽을 거다.
