설정
spark interpreter 수정
spark_yarn interpreter 수정
- spark.jars : /skybluelee/spark3/mysql-connector-java-5.1.49.jar
- spark.jars.packages : org.apache.bahir:spark-streaming-twitter_2.12:2.4.0,org.apache.spark:spark-streaming-kafka-0-10_2.12:3.2.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1,com.google.code.gson:gson:2.8.5
spark.jars는 path를 지정하는 용도이고, spark.jars.pacakges는 트위터 정보 수집에 필요한 자료이다. maven project를 넣음
java bin 경로 추가
$ vi ~/.profile
export PATH=/skybluelee/jdk8/bin:$PATH
$ source ~/.profilezookeeper, kafka 실행
모든 worker에서(spark 계정(권한이 있는)에서 실행 sudo su - spark)
$ nohup /skybluelee/kafka_2.12-3.0.0/bin/zookeeper-server-start.sh /skybluelee/kafka_2.12-3.0.0/config/zookeeper.properties > /skybluelee/kafka_2.12-3.0.0/bin/nohup_zookeeper.out &
$ nohup /skybluelee/kafka_2.12-3.0.0/bin/kafka-server-start.sh /skybluelee/kafka_2.12-3.0.0/config/server.properties > /skybluelee/kafka_2.12-3.0.0/bin/nohup_kafka.out &콘솔 프로듀서 실행
tweet이란 topic이 이미 생성되어 있음
worker-01
$ /skybluelee/kafka_2.12-3.0.0/bin/kafka-console-producer.sh --broker-list spark-worker-01:9092,spark-worker-02:9092,spark-worker-03:9092 --topic tweet
>콘솔 컨슈머 실행
worker-02, worker-03
$ /skybluelee/kafka_2.12-3.0.0/bin/kafka-console-consumer.sh --bootstrap-server spark-worker-01:9092,spark-worker-02:9092,spark-worker-03:9092 --topic tweet
// 아무것도 뜨지 않음추가 확인
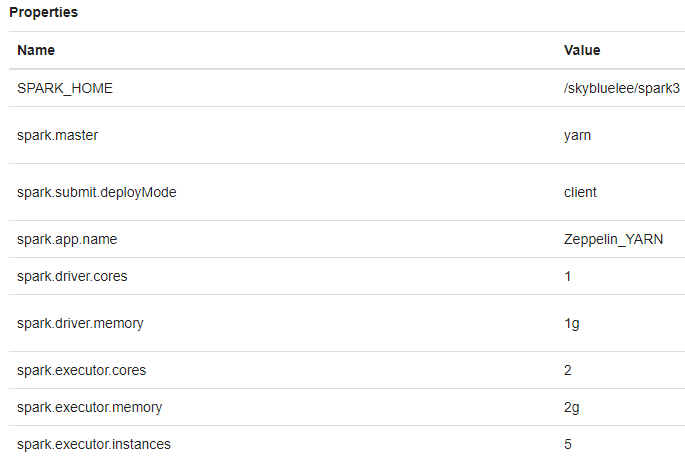
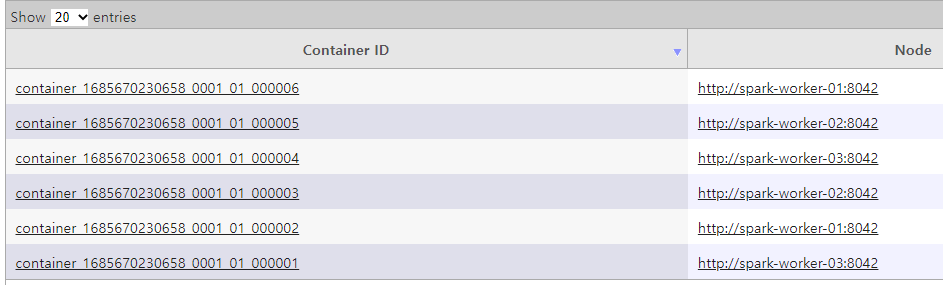
Yarn Resource Manager Web UI: http://spark-master-01:8188/ 에서 executer 5개 확인
kafka용 트위터 계정 생성
twitter developers
project -> app에서 token을 다운받음
spark code
//--직렬화.... => extends Serializable.... => java.io.NotSerializableException: Utils....
object Utils extends Serializable {
/**
* Get Twitter OAuthAuthorization....
*/
import twitter4j.auth.OAuthAuthorization
import twitter4j.conf.ConfigurationBuilder
def getAuth = {
//--트위터 계정 + 트위터 App (with Consumer Key and Access Token) 필요....
val Array(consumerKey, consumerSecret, accessToken, accessTokenSecret) = Array("", "", "", "")
val builder: ConfigurationBuilder = new ConfigurationBuilder()
builder.setOAuthConsumerKey(consumerKey);
builder.setOAuthConsumerSecret(consumerSecret);
builder.setOAuthAccessToken(accessToken);
builder.setOAuthAccessTokenSecret(accessTokenSecret);
Some(new OAuthAuthorization(builder.build()))
}
}import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.twitter.TwitterUtils
import com.google.gson.Gson
//--스트리밍 컨텍스트 생성....
val ssc = new StreamingContext(sc, Seconds(1))
//--트위터 스트림 생성....
val tweetInputDStream = TwitterUtils.createStream(ssc, Utils.getAuth)//--트위터 스트림 내용 출력....=> 디버깅용....
tweetInputDStream.foreachRDD((rdd, time) =>
rdd.foreach { status =>
println(s">>>> status (@ ${time.milliseconds}) : ${status}")
println(s">>>> status.getText (@ ${time.milliseconds}) : ${status.getText}")
}
)executer에서 실행됨. 값을 확인하기 위해서는 log파일을 뒤져보거나 application UI에서 확인해야 함.
//--트위터 Status 객체를 JSON 스트링으로 트랜스폼.... => 향후 Spark SQL로 분석하기 위해 로딩 및 쿼리가 용이한 JSON 형태로 변형....
val tweetStream = tweetInputDStream.mapPartitions(iter => {
var gson = new Gson()
iter.map(gson.toJson(_))
})status type의 객체를 Gson으로 바꿔주고, 다시 Json으로 변환
//--json 스트링을 Kafka로 Producing....
tweetStream.foreachRDD((rdd, time) => {
if (!rdd.isEmpty) { //--해당 스트림 배치 인터벌에 데이터가 있을 경우....
//--RDD 내용을 Kafka로 Producing....
rdd.foreachPartition((iter) => {
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
val brokers = "spark-worker-01:9092,spark-worker-02:9092,spark-worker-03:9092"
val topic = "tweet"
//--Kafka Producer 관련 정보 설정....
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
//--KafkaProducer 생성....
val producer = new KafkaProducer[String, String](props)
//--메시지 전송....
iter.foreach(tweet_json_str => {
val message = new ProducerRecord[String, String](topic, null, tweet_json_str)
producer.send(message)
})
})
}
})//--스트리밍 컨텍스트 시작 및 종료대기....
ssc.start()start 전까지는 아무것도 동작하지 않음
ssc.getState //--INITIALIZED, ACTIVE, STOPPED....
res5: org.apache.spark.streaming.StreamingContextState = ACTIVE