1. 파일 로딩 함수
판다스에서는 여러개의 파일 로딩 함수를 지원합니다.
그 중 제일 많이 사용하는 함수가 read_csv 입니다.
2. read_csv
1) 정의
csv 파일을 불러오기 위한 함수입니다.
csv는 Comma Separated Values 의 약자로, 콤마로 분리된 데이터 입니다.
하지만, read_csv는 sep를 콤마가 아닌 다른 값으로 지정하면 csv가 아닌 다른 파일도 로드할 수 있습니다.
2) parameters
주로 사용하는 값은 다음과 같습니다.
-
filepath - 읽을 파일의 경로
-
sep - 데이터 구분값, 기본값: ','
-
index_col - 칼럼의 값을 인덱스로 사용합니다.
-
parse_dates - 칼럼을 datetime으로 파싱
3) 반환값
반환값은 행과 열을 가지는 2차원의 자료형 DataFrame입니다.
3. 예시
1) 기본 사용
# 관례적으로 pd를 별칭으로 사용합니다.
import pandas as pd
# ./ 의미는 현재 파이썬 파일이 실행되고 있는 디렉토리
# ./titanic/train.csv 의미는 현재 디렉토리의 titanic 폴더안의 train.csv 파일
train = pd.read_csv("./titanic/train.csv")
# 상위 5개의 행 확인
train.head()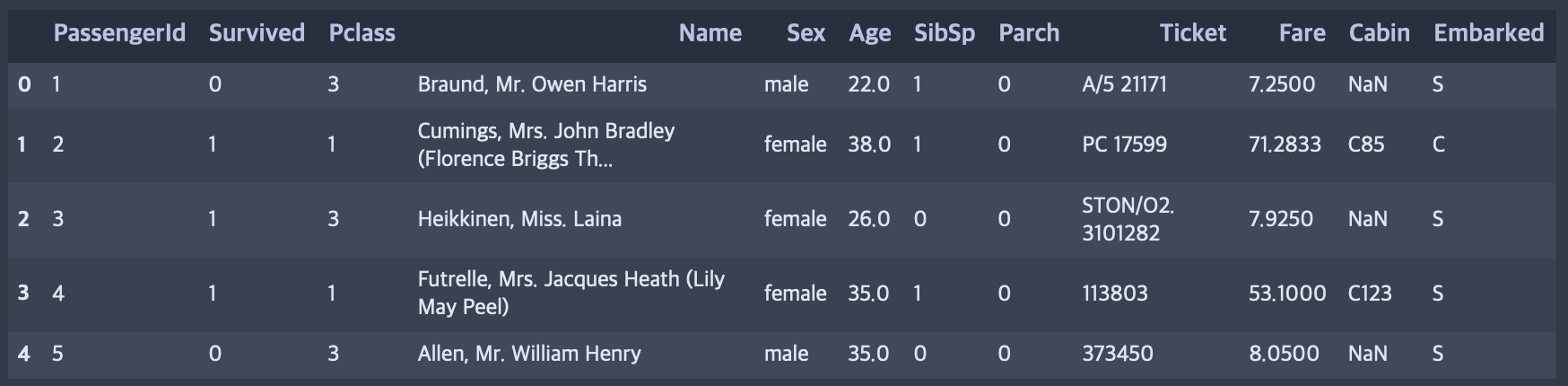
csv 파일의 첫번째 문자열이 칼럼으로 인식합니다.
데이터 프레임이 생성되는 순간 고유한 index를 가집니다.
2) index_col
파일을 로드할때 특정 칼럼을 인덱스로 지정합니다.
index_col을 사용하지 않고,
불러오고 나서 DataFrame의 set_index 함수로 인덱스를 지정할 수도 있습니다.
import pandas as pd
# PassengerId 를 인덱스로 지정해서 파일을 읽습니다.
train = pd.read_csv("./titanic/train.csv", index_col="PassengerId")
train.head()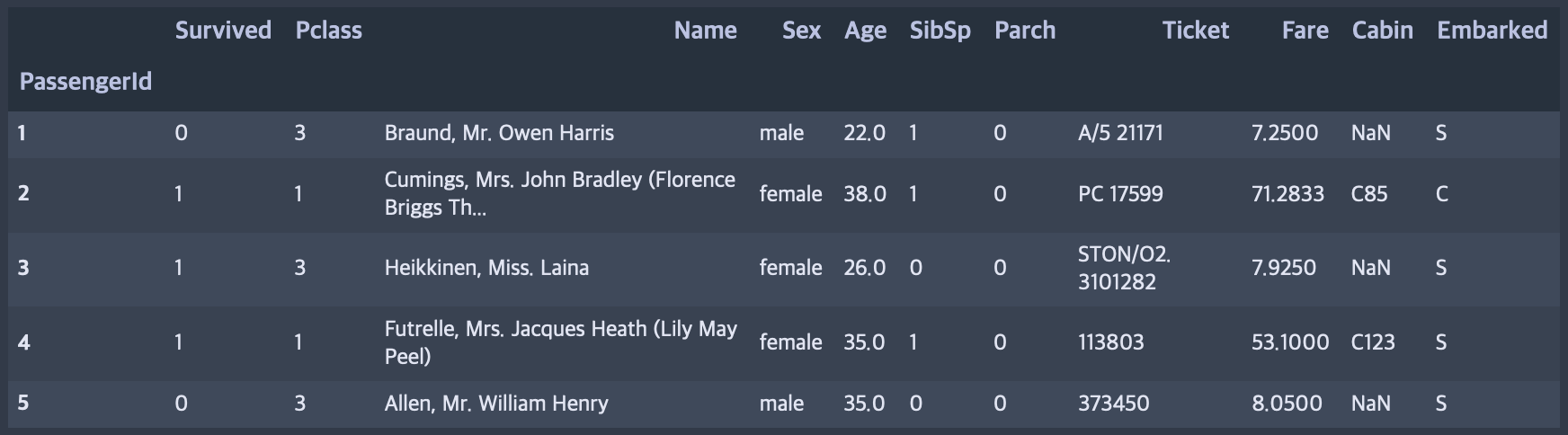
3) parse_date
파일을 로드할때 특정 칼럼을 datetime 자료형으로 파싱합니다.
parse_date을 사용하지 않고,
불러오고 나서 pandas의 to_datetime 함수로 파싱할 수 있습니다.
import pandas as pd
# datetime 칼럼을 datetime 자료형으로 파싱합니다.
train = pd.read_csv("./bike/train.csv", parse_dates=["datetime"])
train.head()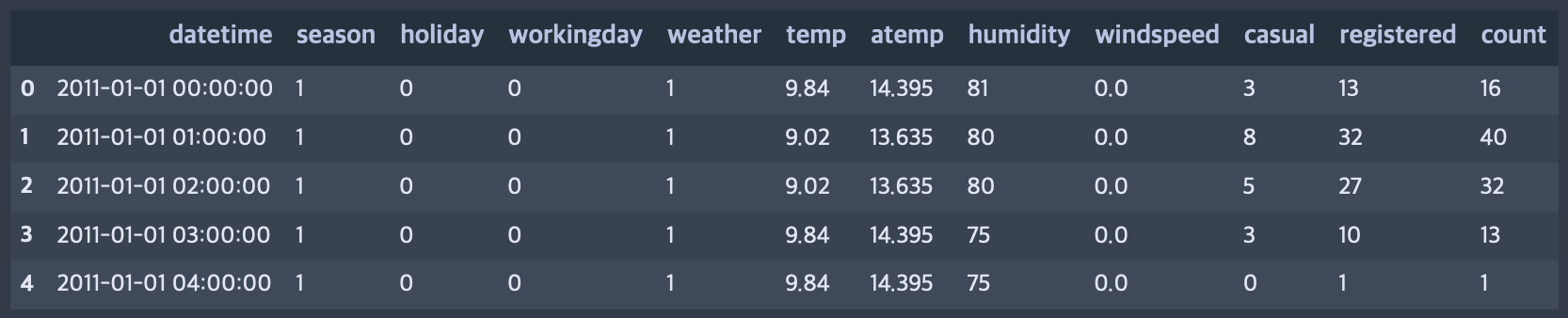
# info 함수는 총 데이터의 건수, 데이터 타입, null 건수를 알려줍니다.
train.info()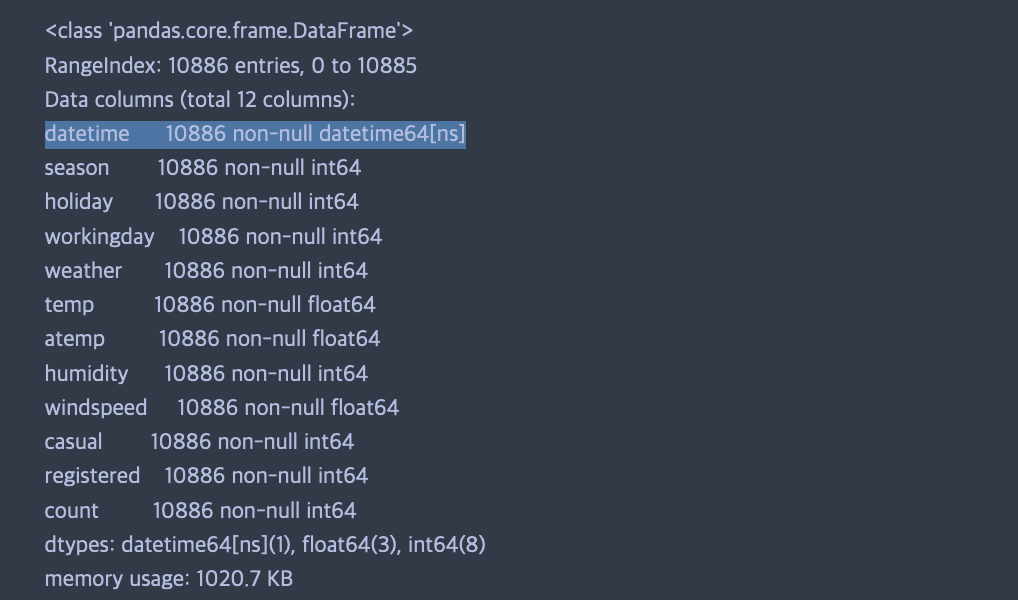

callmeskye