1. 머신러닝이란?
1) 정의
머신러닝은 데이터를 학습하고, 스스로 규칙을 만들어내는 프로그램입니다.
- 데이터 : 사진, 영상, 엑셀
- 규칙: 자율주행, 사진 분류
프로그램이 데이터를 기반으로 스스로 규칙을 찾기 때문에 머신러닝 이라고 부릅니다.
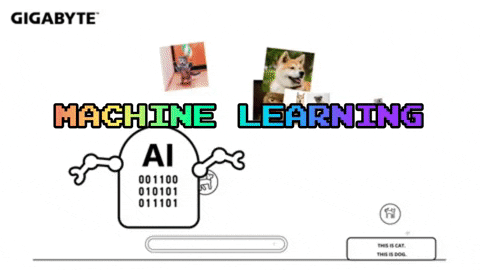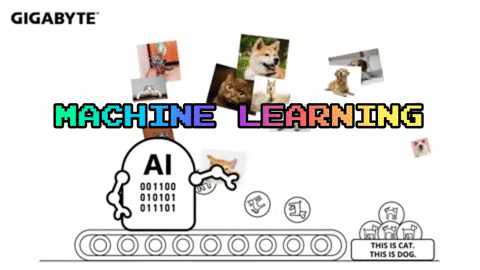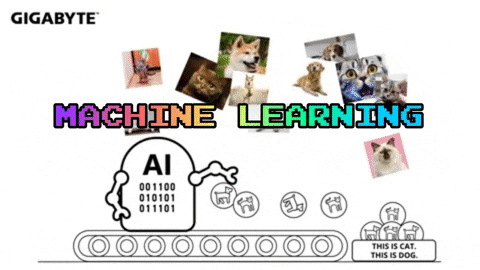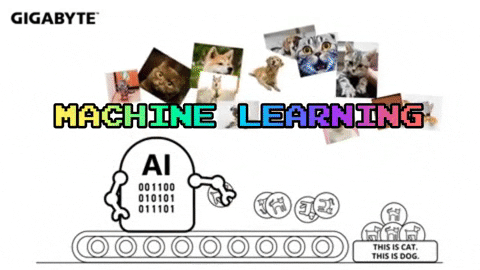
2) 근데 왜 요즘 머신러닝이 핫하냐구요?
인공지능은 크게 2개로 나눌 수 있습니다. rule-base, data-driven
rule-based는 이런 상황에서는 이렇게 움직여야해! 라고 개발자가 규칙을 전부 만들어주는 것입니다.
rule-based 단점은 이 세상에는 개발자가 하나씩 정해주기에는 정말 다양한 상황이 있다는 것 입니다.

이러한 이유로 데이터를 기반으로 스스로 규칙을 찾는 data-driven이 선호되고 있습니다.
3) 인공지능, 머신러닝, 딥러닝 뭐가 다른데요?
인공지능 > 머신러닝 > 딥러닝 순서로 포괄적인 개념입니다.
- 인공지능 - 사람의 지적 능력을 구현한 것을 전부 아우르는 단어, rule-based
- 머신러닝 - 데이터를 기반으로 스스로 규칙을 찾는 방법, data-driven
- 딥러닝 - 머신러닝의 한 종류, 인공 신경망을 사용하는 방법

4) Garbage in Garbage out

머신러닝의 문제 - 쓰레기가 들어가면 쓰레기가 나옵니다.
머신러닝은 데이터 기반이기 때문에 규칙을 아무리 잘 만든다고 해도 좋지 않은 데이터로 학습을 진행했다면, 좋지 않은 결과가 나옵니다.
좋지 않은 데이터란,
- 이상한 값 - 숫자가 있어야 하는데 문자가 들어있거나 값이 없음
- 편항된 데이터 - 강아지, 고양이 사진 분류를 해야하는데 고양이 사진이 99%
그런 이유로, 학습시키는 것 뿐만 아니라 좋은 데이터를 만드는 것도 중요합니다.
2. 지도학습, 비지도학습, 강화학습
학습하는 방법에 따라 크게 3가지 지도학습, 비지도학습, 강화학습으로 나눌 수 있습니다.
지도학습과 비지도학습의 차이는, 정답의 여부입니다.
지도학습은 정답이 있고, 비지도 학습은 정답이 없습니다.
1) 지도학습
지도 학습은 학습을 시키는 데이터에 정답을 함께 알려줍니다.
6장의 사진 데이터에 대해 절반은 고양이, 나머지는 강아지 라는 정답을 알려주고 학습시킵니다.
테스트 사진이 주어졌을 때 '고양이' 또는 '강아지'라고 입력에 대한 정답을 예측합니다.

또한, 정답을 알고 있기 때문에 지도학습의 모델을 반드시 성능을 평가할 수 있습니다.
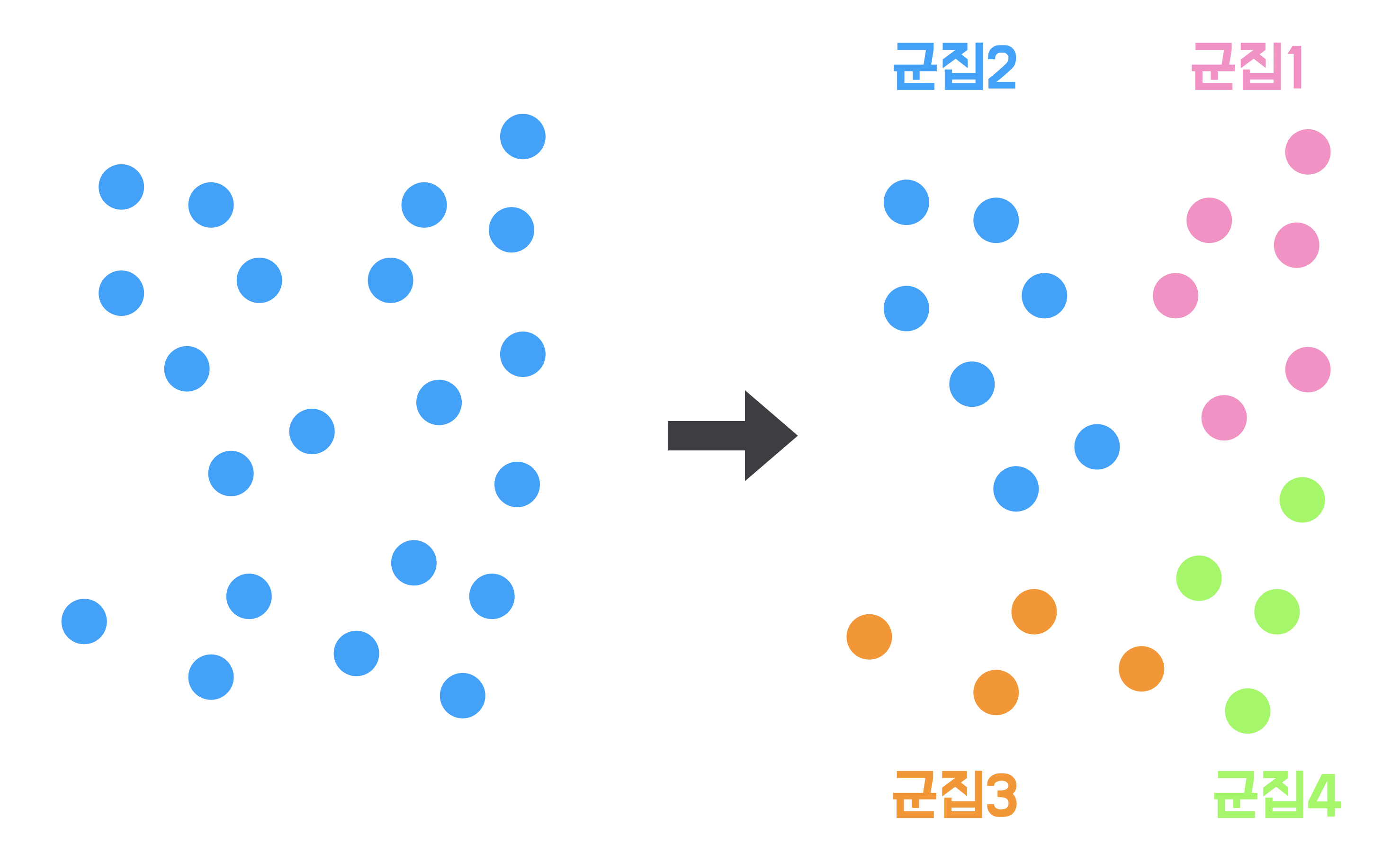
2) 비지도학습
비지도 학습은 학습 데이터에 정답이 없습니다. 그렇기 때문에 모델의 성능 또한 평가하지 않습니다.
점들이 있을 때 4개의 군집으로 나눌 수 있을것 같다. 라는 특성을 분석하는데 사용합니다.
3) 강화학습
행동에 대한 보상을 최대화하는 방법으로 학습하는 방법입니다.
3. 분류, 회귀
지도학습은 예측하는 값의 종류에 따라 분류, 회귀로 나눌 수 있습니다.
분류 - 예측하는 값이 문자형(범주형)
회귀 - 예측하는 값이 숫자형(연속형)
1) 분류 (classification)
분류는 고양이, 강아지와 같이 문자형 값을 예측하는 방법입니다.

2) 회귀
회귀는 숫자형 값을 예측하는 방법입니다.

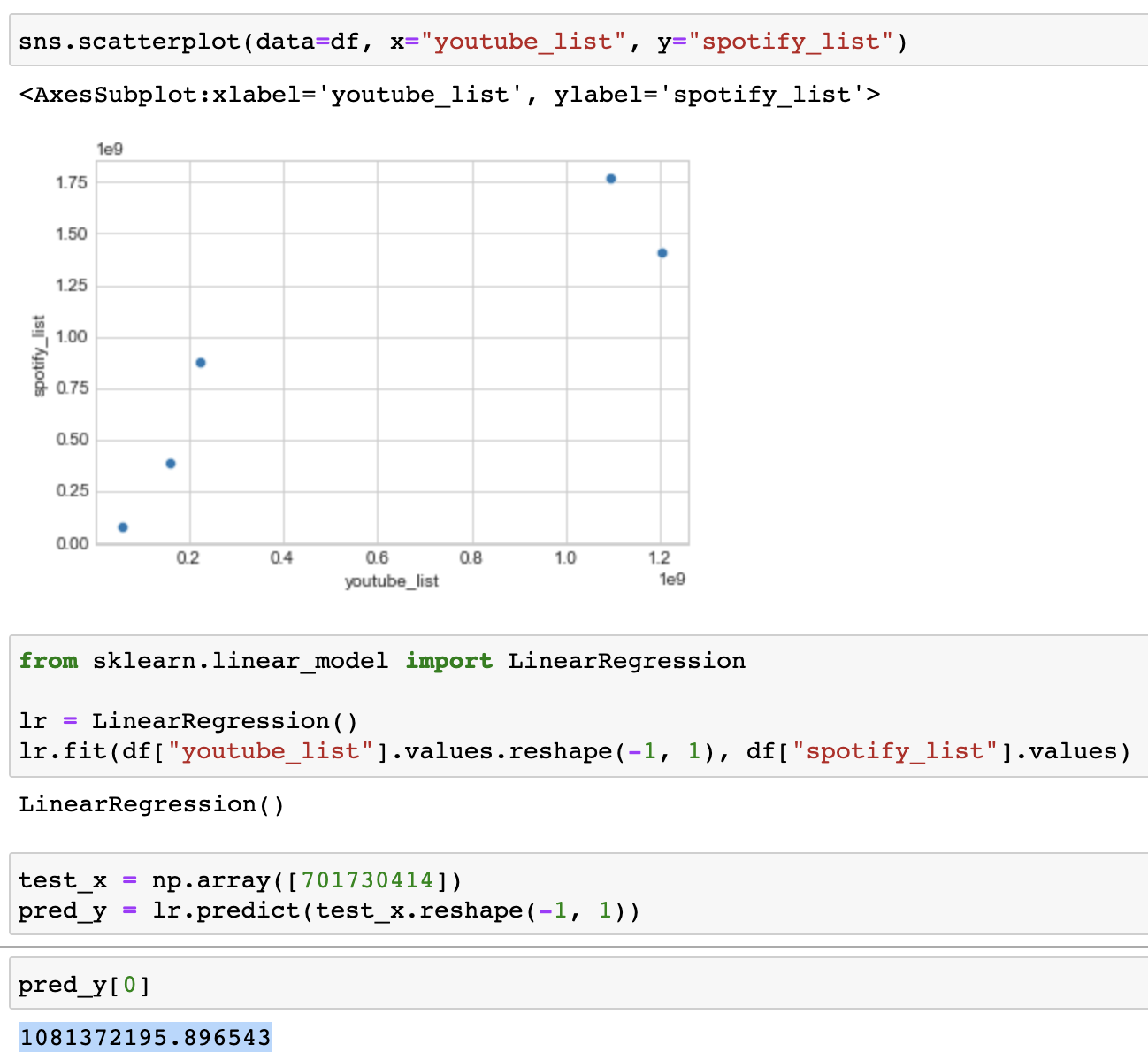
두 서비스의 재생수에 대해 선형관계가 있다고 가정하고

유튜브의 조회수를 이용해서 When the party's over 의 Spotify 스트리밍 수를 예측해보면
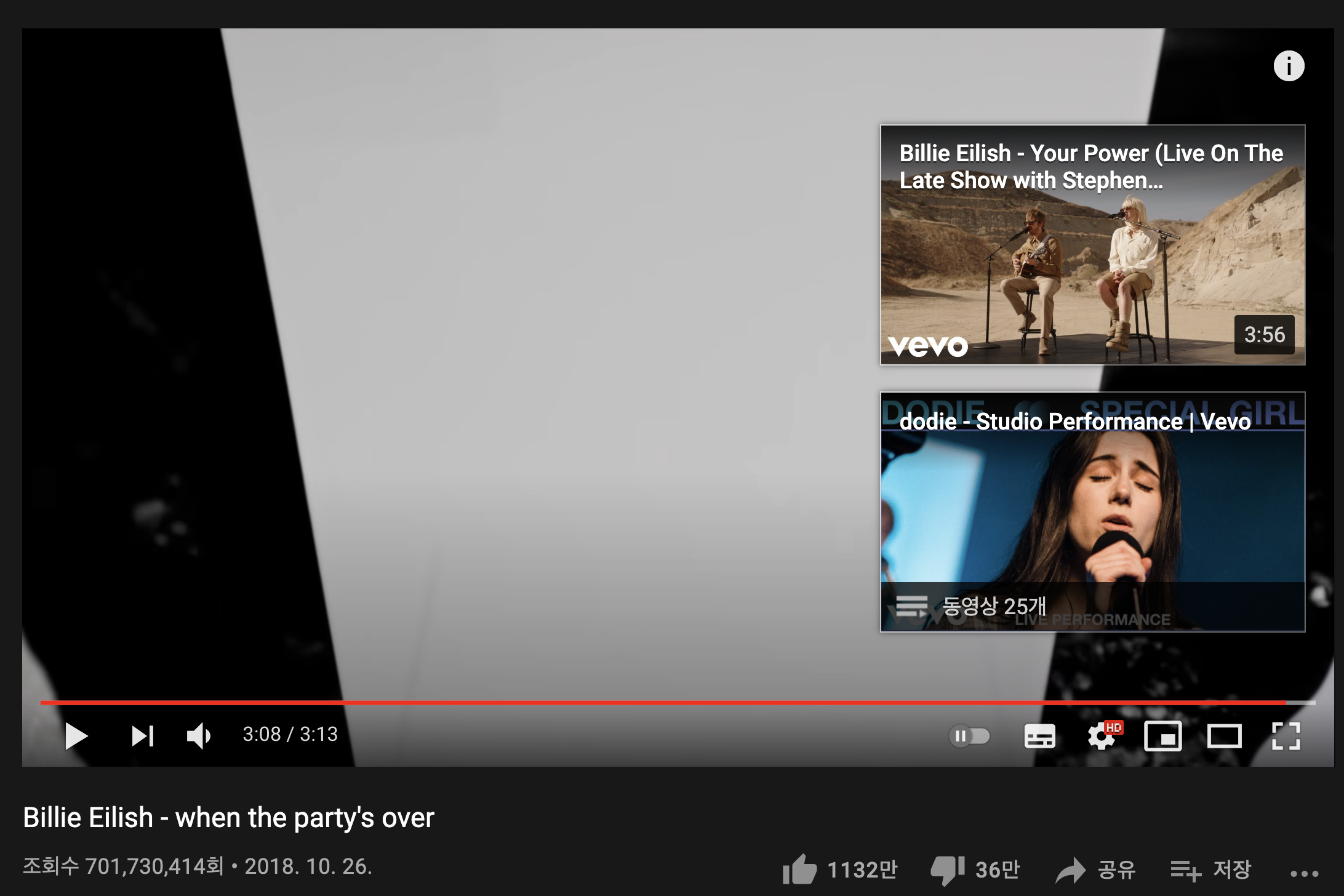
1,081,372,195 (약 1억 8백만이 나오고)
직접 확인해보니 1,151,241,612 (약 1억 천오백만) 입니다.