본 글을 이화여자대학교 송종우 교수님의 러닝패킷: 통계의 기초 강의를 정리한 것입니다.
러닝패킷: 통계의 기초
1. 자료의 두가지 형태
1) 범주형 자료
명목 / 순서 변수 차이점 - 순서 변수에는 순위 개념이 존재한다.
-
명목 변수
순위 개념이 있다.
ex) 성별 (남, 여), 지역 (서울, 광주, 부산) -
순서 변수
순서가 개념이 없다.
ex) 자동차 크기(소형, 중형, 대형), 계층(상, 중, 하)
2) 양적 자료
수치를 숫자로 나타낼 수 있는 자료
-
연속 자료
무한개의 다른 값을 가진다.
ex) 키, 몸무게, 온도 -
이산 자료
유한개의 다른 값을 가진다.
ex) 고장 횟수, 가족 구성원의 수
2. 범주형 자료의 요약
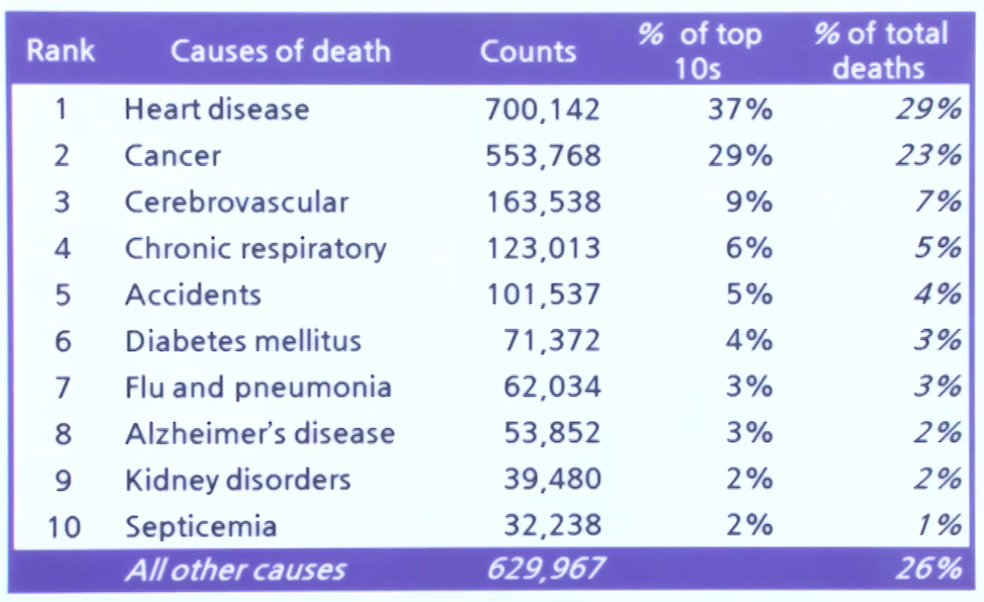
1) 도수 분포표
각각의 자료가 얼마 있는지 보여줍니다.
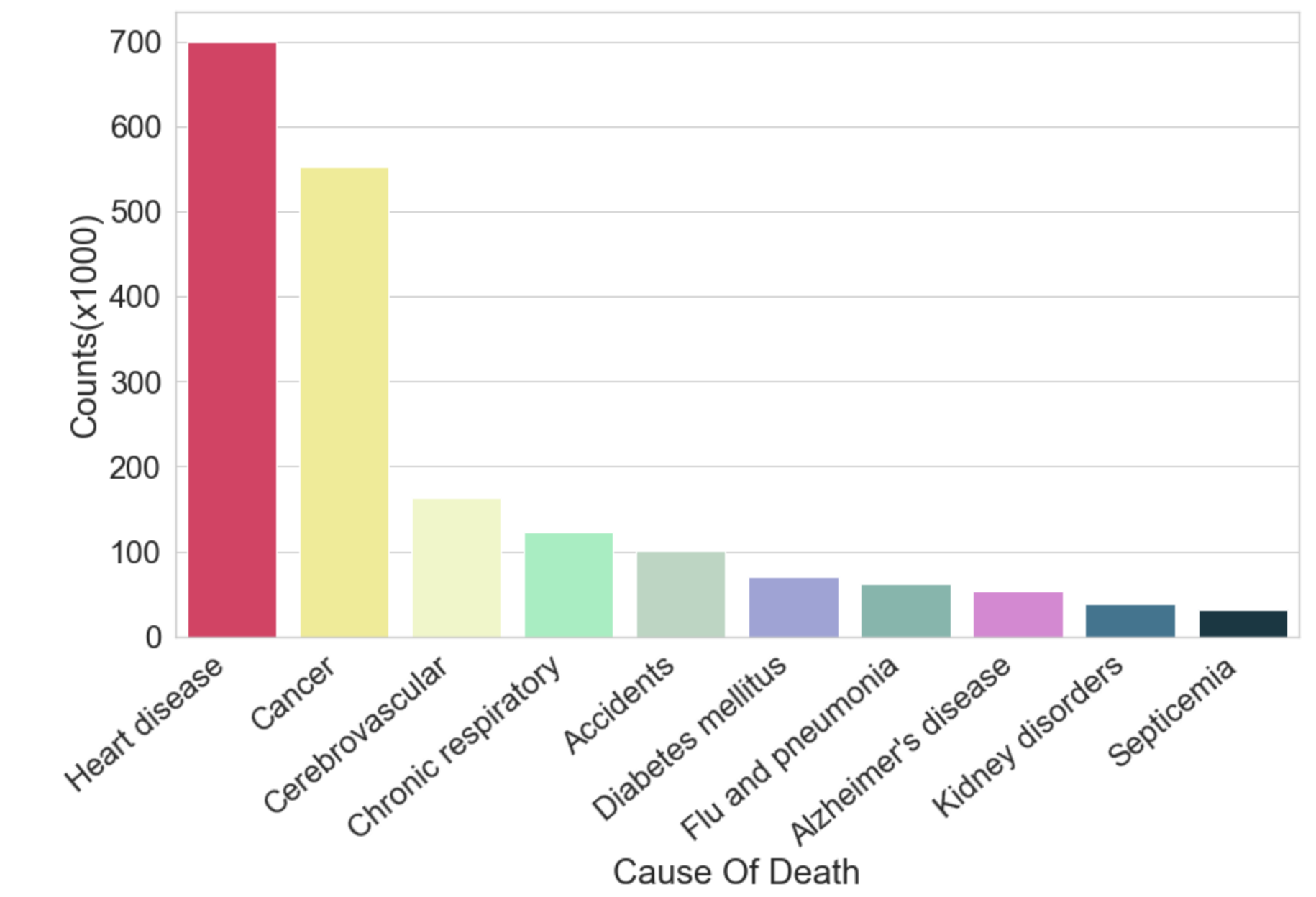
2) 막대 그래프
각 범주가 하나의 막대로 표현됩니다.
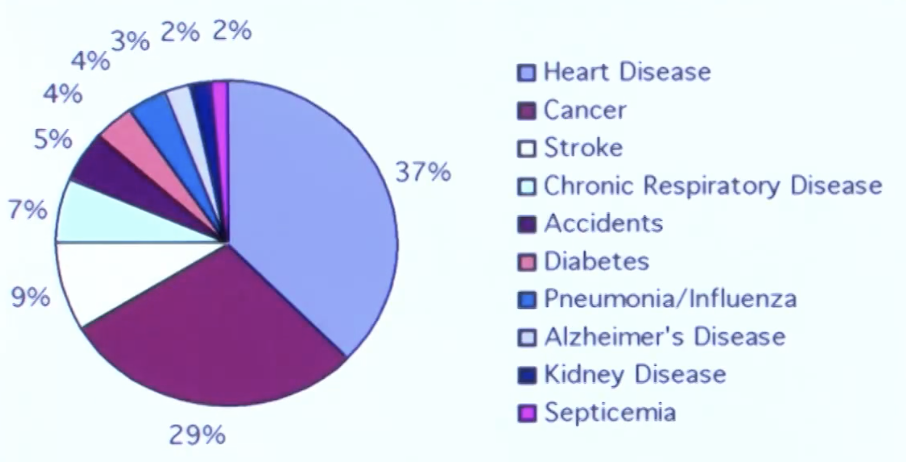
3) 파이 차트
각 범주는 파이의 한 조각으로 표현됩니다.
보통 퍼센트를 사용하여 총합이 100이 되도록 합니다.
3. 양적 자료의 요약
1) 그래프적 요약
전체적인 분포와 패턴을 확인합니다.
또, 그 패턴으로 부터 벗어난 극단적 관측치(outliers)을 살펴봅니다.
ex) 점도표, 줄기잎 그림, 히스토그램, 상자 그림, 선 그래프
2) 수치적 요약
-
대표값
산술평균 (mean), 중앙값 (median), 최빈값 (mode) -
산포도
범위, 사분위 범위 (IQR), 표준편차
4. 양적 자료 요약의 예시
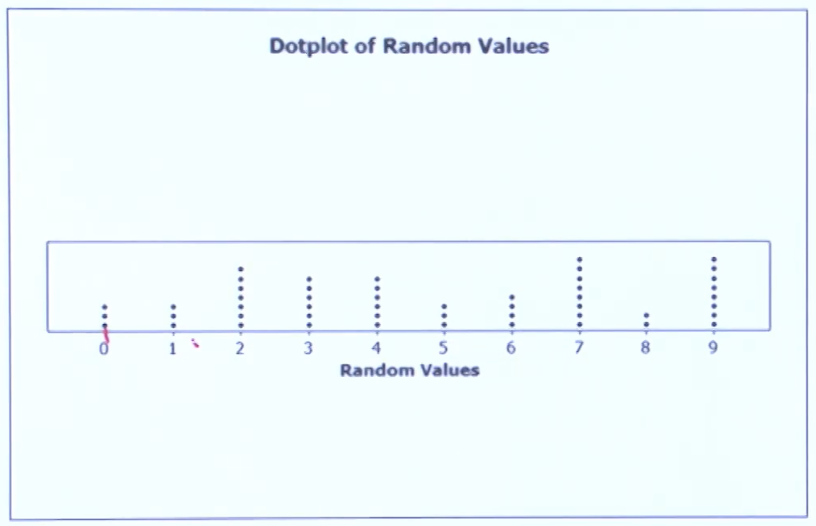
1) 점도표
점의 개수로 자료가 몇개 있는지를 나타냅니다.
2) 줄기-잎 그림
실제 자료의 수치를 그대로 사용 -> 정보의 손실이 없음
모든 값이 양수, 데이터 양이 많지 않을 때 좋음
그리는 방법 -> 첫자리에 10의 자리 수를 적고, 하나씩 1의 자리를 적는다.

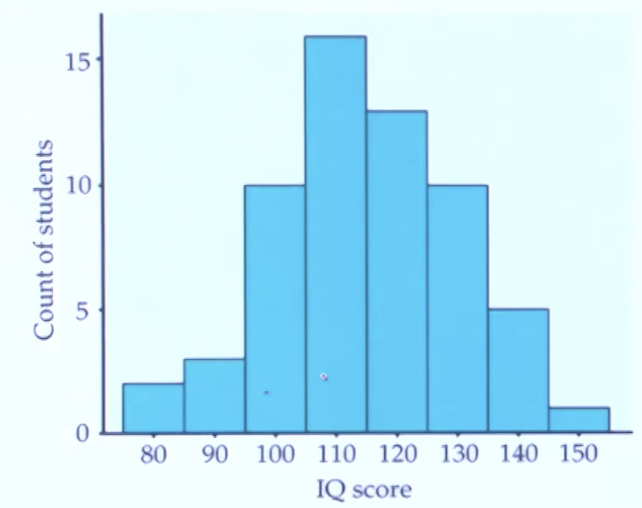
3) 히스토그램
자료를 몇개의 구간으로 나누고, 각 구간에 들어가는 관측치의 빈도 또는 상대빈도 만을 나타낸다.
히스토그램 막대의 크기는 구간의 빈도에 비례한다.
데이터 양이 적은 경우 좋다.
ex) 학생들의 아이큐를 나타낸 히스토그램
4) 선 그래프
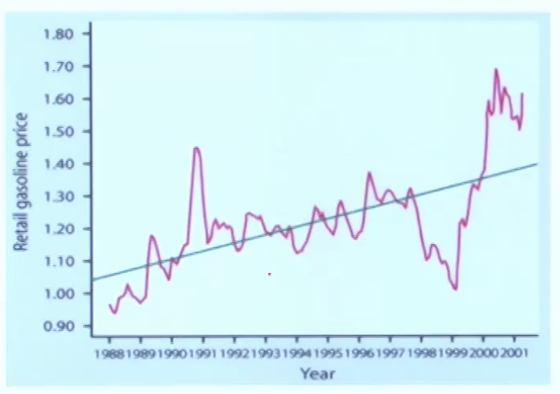
시계열 자료인 경우 x축을 시간으로 한 time plot 에서 추세 변동과 계절 변동등을 찾을 수 있음
- 추세 변동 ( 트렌드 )
장기 적인 추세 변화
ex) 아래 그래프에서 오르내림이 있지만, 시간이 감에 따라 전체적으로 올라가는 경향이 있다.
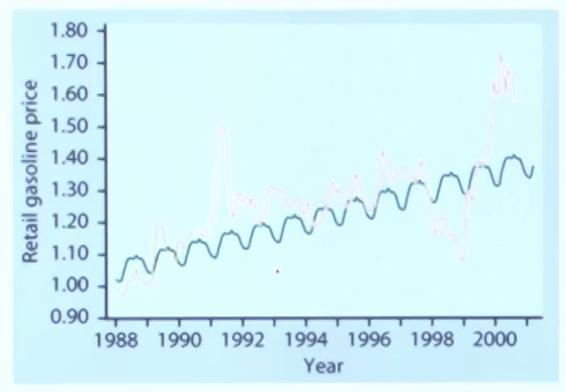
- 계절 변동
계절에 순환하며 나타나는 변동
ex) 여름철 휴가로 휘발유 가격이 올라가고, 겨울철 상대적으로 적은 휴가로 휘발유 가격이 내려간다.

자료정말 깔끔하게 이해가 쏙쏙되요! 정말 핵심만 잘 정리한 것 같아요!!👍👍👍
그런데 법주형데이터에 명목변수가 순위개념이"있다"라고 써있는데, 혹시 잘못된건 아닌가요?
제가배운것과 달라 질문드려요..!