_Language-Image Quality Evaluator (LIQE)
: Blind Image Quality Assessment via Vision-Language Correspondence: A Multitask Learning Perspective (CVPR2023)
github : https://github.com/zwx8981/LIQE
1. Table5. quality+distortion+scene 조합
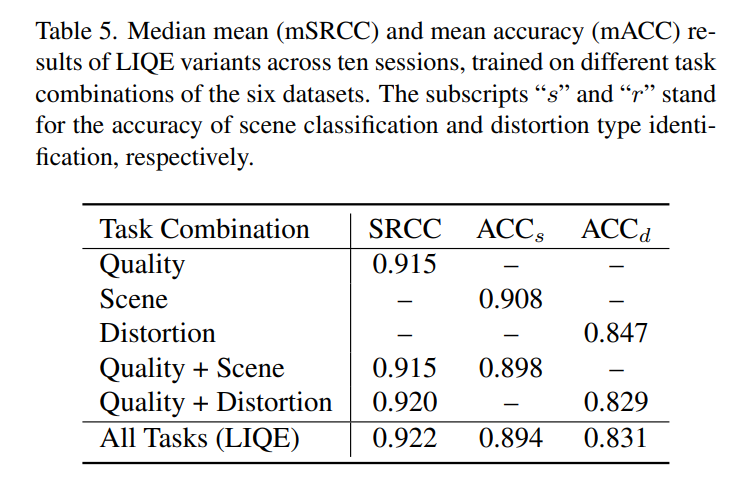
실습
데이터셋 : KonIQ-10k / BID / KADID-10k
1. KADID-10k
import torch
import numpy as np
import clip
from utils import _preprocess2
import random
from itertools import product
from PIL import Image, ImageFile
import os
import pandas as pd
import scipy.stats
import torch.nn.functional as F
import sys
sys.path.insert(0, 'C:/Users/IIPL02/Desktop/LIQE/LIQE')
from utils import _preprocess2
ImageFile.LOAD_TRUNCATED_IMAGES = True
# 다양한 왜곡, 장면, 품질 범주 정의
dists = ['jpeg2000 compression', 'jpeg compression', 'white noise', 'gaussian blur', 'fastfading', 'fnoise', 'contrast', 'lens', 'motion', 'diffusion', 'shifting',
'color quantization', 'oversaturation', 'desaturation', 'white with color', 'impulse', 'multiplicative',
'white noise with denoise', 'brighten', 'darken', 'shifting the mean', 'jitter', 'noneccentricity patch',
'pixelate', 'quantization', 'color blocking', 'sharpness', 'realistic blur', 'realistic noise',
'underexposure', 'overexposure', 'realistic contrast change', 'other realistic']
scenes = ['animal', 'cityscape', 'human', 'indoor', 'landscape', 'night', 'plant', 'still_life', 'others']
qualitys = ['bad', 'poor', 'fair', 'good', 'perfect']
preprocess2 = _preprocess2()
def do_batch(x, text):
batch_size = x.size(0)
num_patch = x.size(1)
x = x.view(-1, x.size(2), x.size(3), x.size(4))
logits_per_image, logits_per_text = model.forward(x, text)
logits_per_image = logits_per_image.view(batch_size, num_patch, -1)
logits_per_text = logits_per_text.view(-1, batch_size, num_patch)
logits_per_image = logits_per_image.mean(1)
logits_per_text = logits_per_text.mean(2)
logits_per_image = F.softmax(logits_per_image, dim=1)
return logits_per_image, logits_per_text
seed = 20200626
num_patch = 15
torch.manual_seed(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
model, preprocess = clip.load("ViT-B/32", device=device, jit=False)
ckpt = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/pt/LIQE.pt' # Load pre-trained LIQE weights
checkpoint = torch.load(ckpt)
model.load_state_dict(checkpoint)
joint_texts = torch.cat([clip.tokenize(f"a photo of a {c} with {d} artifacts, which is of {q} quality") for q, c, d
in product(qualitys, scenes, dists)]).to(device)
# KADID-10k 데이터셋의 이미지 파일 경로 설정
image_folder = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/IQA_Database/kadid10k/images/'
metadata_path = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/IQA_Database/kadid10k/kadid10k.csv'
# KADID-10k 메타데이터 로드
metadata = pd.read_csv(metadata_path)
image_files = metadata['dist_img'].tolist()
mos_scores = metadata['dmos'].tolist()
print('### Image loading and testing ###')
predicted_scene_quality_scores = []
predicted_distortion_quality_scores = []
quality_predictions = []
for img_file in image_files:
img_path = os.path.join(image_folder, img_file)
I = Image.open(img_path)
I = preprocess2(I)
I = I.unsqueeze(0)
n_channels = 3
kernel_h = 224
kernel_w = 224
if (I.size(2) >= 1024) | (I.size(3) >= 1024):
step = 48
else:
step = 32
I_patches = I.unfold(2, kernel_h, step).unfold(3, kernel_w, step).permute(2, 3, 0, 1, 4, 5).reshape(-1,
n_channels,
kernel_h,
kernel_w)
sel_step = I_patches.size(0) // num_patch
sel = torch.arange(0, num_patch) * sel_step
I_patches = I_patches[sel.long()].to(device)
print(f'Processing {img_file}...')
with torch.no_grad():
logits_per_image, _ = do_batch(I_patches.unsqueeze(0), joint_texts)
logits_per_image = logits_per_image.view(-1, len(qualitys), len(scenes), len(dists))
logits_quality = logits_per_image.sum(3).sum(2)
similarity_scene = logits_per_image.sum(3).sum(1)
similarity_distortion = logits_per_image.sum(1).sum(1)
# Quality prediction
quality_prediction = (logits_quality * torch.arange(1, 6, device=device).float()).sum(dim=1)
quality_predictions.append(quality_prediction.cpu().item())
# 정규화된 Scene + Quality prediction
norm_similarity_scene = (similarity_scene - similarity_scene.min()) / (similarity_scene.max() - similarity_scene.min())
scene_quality_prediction = quality_prediction * (1 + 0.1 * norm_similarity_scene.mean(dim=1))
# 정규화된 Distortion + Quality prediction
norm_similarity_distortion = (similarity_distortion - similarity_distortion.min()) / (similarity_distortion.max() - similarity_distortion.min())
distortion_quality_prediction = quality_prediction * (1 + 0.1 * norm_similarity_distortion.mean(dim=1))
predicted_scene_quality_scores.append(scene_quality_prediction.cpu().item())
predicted_distortion_quality_scores.append(distortion_quality_prediction.cpu().item())
# SRCC computation
srcc_quality = scipy.stats.spearmanr(quality_predictions, mos_scores)[0]
srcc_scene_quality = scipy.stats.spearmanr(predicted_scene_quality_scores, mos_scores)[0]
srcc_distortion_quality = scipy.stats.spearmanr(predicted_distortion_quality_scores, mos_scores)[0]
# Quality + Scene + Distortion combined prediction
combined_quality_scene_distortion_scores = [(q + 0.1 * s + 0.1 * d) for q, s, d in zip(quality_predictions, predicted_scene_quality_scores, predicted_distortion_quality_scores)]
srcc_combined = scipy.stats.spearmanr(combined_quality_scene_distortion_scores, mos_scores)[0]
print(f"### SRCC (Quality): {srcc_quality:.4f} ###")
print(f"### SRCC (Scene + Quality): {srcc_scene_quality:.4f} ###")
print(f"### SRCC (Distortion + Quality): {srcc_distortion_quality:.4f} ###")
print(f"### SRCC (Quality + Scene + Distortion): {srcc_combined:.4f} ###")
결과
| Task Combination | SRCC |
|---|---|
| Quality | 0.9532 |
| Scene + Quality | 0.9519 |
| Distortion + Quality | 0.9512 |
| Distortion + Quality + Scene | 0.9530 |
2. BID
import torch
import numpy as np
import clip
import random
from itertools import product
from PIL import Image, ImageFile
import os
import pandas as pd
import scipy.stats
import torch.nn.functional as F
import sys
sys.path.insert(0, 'C:/Users/IIPL02/Desktop/LIQE/LIQE')
from utils import _preprocess2
ImageFile.LOAD_TRUNCATED_IMAGES = True
# 왜곡, 장면, 품질 범주 정의
dists = ['jpeg2000 compression', 'jpeg compression', 'white noise', 'gaussian blur', 'fastfading', 'fnoise',
'contrast', 'lens', 'motion', 'diffusion', 'shifting', 'color quantization', 'oversaturation',
'desaturation', 'white with color', 'impulse', 'multiplicative', 'white noise with denoise',
'brighten', 'darken', 'shifting the mean', 'jitter', 'noneccentricity patch', 'pixelate',
'quantization', 'color blocking', 'sharpness', 'realistic blur', 'realistic noise', 'underexposure',
'overexposure', 'realistic contrast change', 'other realistic']
scenes = ['animal', 'cityscape', 'human', 'indoor', 'landscape', 'night', 'plant', 'still_life', 'others']
qualitys = ['bad', 'poor', 'fair', 'good', 'perfect']
preprocess2 = _preprocess2()
# 배치 처리를 위한 함수 정의
def do_batch(x, text):
batch_size = x.size(0)
num_patch = x.size(1)
x = x.view(-1, x.size(2), x.size(3), x.size(4))
# 이미지와 텍스트의 로짓(logit)을 계산
logits_per_image, logits_per_text = model.forward(x, text)
# 로짓을 원래 배치와 패치 크기로 복원
logits_per_image = logits_per_image.view(batch_size, num_patch, -1)
logits_per_text = logits_per_text.view(-1, batch_size, num_patch)
# 이미지 로짓 평균을 계산
logits_per_image = logits_per_image.mean(1)
logits_per_text = logits_per_text.mean(2)
# 소프트맥스를 적용하여 정규화
logits_per_image = F.softmax(logits_per_image, dim=1)
return logits_per_image, logits_per_text
# 랜덤 시드 설정
seed = 20200626 # 실행할 때마다 일관된 결과
num_patch = 15 # 하나를 몇 개의 패치로 나눌지
torch.manual_seed(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
# 사전 학습된 CLIP 모델 불러오기
model, preprocess = clip.load("ViT-B/32", device=device, jit=False)
ckpt = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/pt/LIQE.pt' # 사전 학습된 LIQE 모델 가중치 불러오기
checkpoint = torch.load(ckpt)
model.load_state_dict(checkpoint)
# 모델에 사용할 텍스트 데이터 생성 (quality, scene, distortion 조합)
joint_texts = torch.cat([clip.tokenize(f"a photo of a {c} with {d} artifacts, which is of {q} quality") for q, c, d
in product(qualitys, scenes, dists)]).to(device)
# BID 데이터셋 경로 설정
image_folder = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/IQA_Database/BID/ImageDatabase/'
metadata_path = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/IQA_Database/BID/DatabaseGrades.csv'
# 메타데이터 로드 (이미지 파일 목록과 주관적 점수(MOS) 불러오기)
metadata = pd.read_csv(metadata_path)
image_files = [f"DatabaseImage{str(int(num)).zfill(4)}.JPG" for num in metadata['Image Number'].tolist()]
mos_scores = metadata['Average Subjective Grade'].tolist()
print('### Image loading and testing ###')
# 예측 값 저장을 위한 리스트 초기화
quality_predictions = []
predicted_scene_quality_scores = []
predicted_distortion_quality_scores = []
predicted_combined_scores = [] # Quality + Scene + Distortion 결합 예측 값을 저장
# 데이터셋의 각 이미지를 처리
for img_file in image_files:
img_path = os.path.join(image_folder, img_file)
I = Image.open(img_path)
I = preprocess2(I)
I = I.unsqueeze(0)
n_channels = 3
kernel_h = 224
kernel_w = 224
# 이미지 패치 추출
step = 48 if (I.size(2) >= 1024) | (I.size(3) >= 1024) else 32
I_patches = I.unfold(2, kernel_h, step).unfold(3, kernel_w, step).permute(2, 3, 0, 1, 4, 5).reshape(-1, n_channels, kernel_h, kernel_w)
sel_step = I_patches.size(0) // num_patch
sel = torch.arange(0, num_patch) * sel_step
I_patches = I_patches[sel.long()].to(device)
print(f'Processing {img_file}...')
# 모델 예측 (로짓 계산)
with torch.no_grad():
logits_per_image, _ = do_batch(I_patches.unsqueeze(0), joint_texts)
logits_per_image = logits_per_image.view(-1, len(qualitys), len(scenes), len(dists))
# 품질 예측 값 계산
logits_quality = logits_per_image.sum(3).sum(2)
similarity_scene = logits_per_image.sum(3).sum(1)
similarity_distortion = logits_per_image.sum(1).sum(1)
quality_prediction = (logits_quality * torch.arange(1, 6, device=device)).sum(dim=1)
# 각 예측 값에 정규화 적용
norm_similarity_scene = (similarity_scene - similarity_scene.min()) / (similarity_scene.max() - similarity_scene.min())
norm_similarity_distortion = (similarity_distortion - similarity_distortion.min()) / (similarity_distortion.max() - similarity_distortion.min())
# Scene과 Distortion 예측을 Quality에 반영
scene_quality_prediction = quality_prediction * (1 + 0.25 * norm_similarity_scene.mean(dim=1)) # 가중치 조정
distortion_quality_prediction = quality_prediction * (1 + 0.25 * norm_similarity_distortion.mean(dim=1)) # 가중치 조정
# 가중합을 통해 최종 예측값 계산
combined_prediction = quality_prediction + 0.4 * scene_quality_prediction + 0.4 * distortion_quality_prediction
quality_predictions.append(quality_prediction.cpu().item())
predicted_scene_quality_scores.append(scene_quality_prediction.cpu().item())
predicted_distortion_quality_scores.append(distortion_quality_prediction.cpu().item())
predicted_combined_scores.append(combined_prediction.cpu().item())
# SRCC (순위 상관계수) 계산
srcc_quality = scipy.stats.spearmanr(quality_predictions, mos_scores)[0]
srcc_scene_quality = scipy.stats.spearmanr(predicted_scene_quality_scores, mos_scores)[0]
srcc_distortion_quality = scipy.stats.spearmanr(predicted_distortion_quality_scores, mos_scores)[0]
srcc_combined = scipy.stats.spearmanr(predicted_combined_scores, mos_scores)[0]
print(f"### SRCC (Quality): {srcc_quality:.4f} ###")
print(f"### SRCC (Scene + Quality): {srcc_scene_quality:.4f} ###")
print(f"### SRCC (Distortion + Quality): {srcc_distortion_quality:.4f} ###")
print(f"### SRCC (Quality + Scene + Distortion): {srcc_combined:.4f} ###")
# Scene와 Distortion을 Quality에 반영: predicted_scene_quality_scores와 predicted_distortion_quality_scores는 q * (1 + 0.25 * s) 및 q * (1 + 0.25 * d)로 계산됩니다.
# 최종 결합 예측 계산: combined_quality_scene_distortion_scores는 Quality에 Scene과 Distortion 예측을 각각 0.4의 가중치로 더하여 계산합니다.결과
| Task Combination | SRCC |
|---|---|
| Quality | 0.9520 |
| Scene + Quality | 0.9506 |
| Distortion + Quality | 0.9513 |
| Distortion + Quality + Scene | 0.9519 |
3. KonIQ-10k
import torch
import numpy as np
import clip
from utils import _preprocess2
import random
from itertools import product
from PIL import Image, ImageFile
import os
import pandas as pd
import scipy.stats
import torch.nn.functional as F
import sys
sys.path.insert(0, 'C:/Users/IIPL02/Desktop/LIQE/LIQE')
from utils import _preprocess2
ImageFile.LOAD_TRUNCATED_IMAGES = True
# Distortion, Scene, Quality 속성 정의
dists = ['jpeg2000 compression', 'jpeg compression', 'white noise', 'gaussian blur', 'fastfading', 'fnoise',
'contrast', 'lens', 'motion', 'diffusion', 'shifting', 'color quantization', 'oversaturation',
'desaturation', 'white with color', 'impulse', 'multiplicative', 'white noise with denoise', 'brighten',
'darken', 'shifting the mean', 'jitter', 'noneccentricity patch', 'pixelate', 'quantization',
'color blocking', 'sharpness', 'realistic blur', 'realistic noise', 'underexposure', 'overexposure',
'realistic contrast change', 'other realistic']
scenes = ['animal', 'cityscape', 'human', 'indoor', 'landscape', 'night', 'plant', 'still_life', 'others']
qualitys = ['bad', 'poor', 'fair', 'good', 'perfect']
preprocess2 = _preprocess2()
def do_batch(x, text):
batch_size = x.size(0)
num_patch = x.size(1)
x = x.view(-1, x.size(2), x.size(3), x.size(4))
logits_per_image, logits_per_text = model.forward(x, text)
logits_per_image = logits_per_image.view(batch_size, num_patch, -1)
logits_per_text = logits_per_text.view(-1, batch_size, num_patch)
logits_per_image = logits_per_image.mean(1)
logits_per_text = logits_per_text.mean(2)
# Softmax 적용을 통해 정규화
logits_per_image = F.softmax(logits_per_image, dim=1)
return logits_per_image, logits_per_text
seed = 20200626
num_patch = 15
torch.manual_seed(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
model, preprocess = clip.load("ViT-B/32", device=device, jit=False)
ckpt = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/pt/LIQE.pt' # LIQE 사전 학습된 가중치 불러오기
checkpoint = torch.load(ckpt)
model.load_state_dict(checkpoint)
joint_texts = torch.cat([clip.tokenize(f"a photo of a {c} with {d} artifacts, which is of {q} quality") for q, c, d
in product(qualitys, scenes, dists)]).to(device)
# KonIQ-10k 데이터셋의 이미지 파일 경로 설정
koniq10k_path = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/IQA_Database/koniq-10k/1024x768/'
metadata_path = 'C:/Users/IIPL02/Desktop/LIQE/LIQE/IQA_Database/koniq-10k/meta_info_KonIQ10kDataset.csv'
# KonIQ-10k 메타데이터 로드
metadata = pd.read_csv(metadata_path)
image_files = metadata['image_name'].tolist()
mos_scores = metadata['MOS'].tolist()
predicted_quality_scores = []
predicted_scene_scores = []
predicted_distortion_scores = []
print('### Image loading and testing ###')
for i, img_file in enumerate(image_files):
img_path = os.path.join(koniq10k_path, img_file)
I = Image.open(img_path)
I = preprocess2(I)
I = I.unsqueeze(0)
n_channels = 3
kernel_h = 224
kernel_w = 224
if (I.size(2) >= 1024) | (I.size(3) >= 1024):
step = 48
else:
step = 32
I_patches = I.unfold(2, kernel_h, step).unfold(3, kernel_w, step).permute(2, 3, 0, 1, 4, 5).reshape(-1,
n_channels,
kernel_h,
kernel_w)
sel_step = I_patches.size(0) // num_patch
sel = torch.zeros(num_patch)
for j in range(num_patch):
sel[j] = sel_step * j
sel = sel.long()
I_patches = I_patches[sel, ...]
I_patches = I_patches.to(device)
print(f'Processing {img_file}...')
with torch.no_grad():
logits_per_image, _ = do_batch(I_patches.unsqueeze(0), joint_texts)
logits_per_image = logits_per_image.view(-1, len(qualitys), len(scenes), len(dists))
# Quality prediction
logits_quality = logits_per_image.sum(3).sum(2)
quality_prediction = (logits_quality * torch.arange(1, len(qualitys) + 1, device=device).float()).sum(dim=1)
predicted_quality_scores.append(quality_prediction.cpu().item())
# Scene prediction
scene_prediction = logits_per_image.sum(3).argmax(dim=2).float().mean(dim=1)
predicted_scene_scores.append(scene_prediction.cpu().item())
# Distortion prediction
distortion_prediction = logits_per_image.sum(2).argmax(dim=2).float().mean(dim=1)
predicted_distortion_scores.append(distortion_prediction.cpu().item())
# SRCC 계산
srcc_quality = scipy.stats.spearmanr(predicted_quality_scores, mos_scores)[0]
# 예측 값 정규화
predicted_scene_scores = [(s - min(predicted_scene_scores)) / (max(predicted_scene_scores) - min(predicted_scene_scores)) for s in predicted_scene_scores]
predicted_distortion_scores = [(d - min(predicted_distortion_scores)) / (max(predicted_distortion_scores) - min(predicted_distortion_scores)) for d in predicted_distortion_scores]
# 품질, 장면, 왜곡 예측값을 가중 합하여 결합 예측값 계산
combined_quality_scene_scores = [(q + 0.5 * s) for q, s in zip(predicted_quality_scores, predicted_scene_scores)]
combined_quality_distortion_scores = [(q + 0.5 * d) for q, d in zip(predicted_quality_scores, predicted_distortion_scores)]
combined_quality_scene_distortion_scores = [(q + 0.25 * s + 0.25 * d) for q, s, d in zip(predicted_quality_scores, predicted_scene_scores, predicted_distortion_scores)]
# SRCC 계산
srcc_quality_scene = scipy.stats.spearmanr(combined_quality_scene_scores, mos_scores)[0]
srcc_quality_distortion = scipy.stats.spearmanr(combined_quality_distortion_scores, mos_scores)[0]
srcc_quality_scene_distortion = scipy.stats.spearmanr(combined_quality_scene_distortion_scores, mos_scores)[0]
print(f"### SRCC (Quality): {srcc_quality:.4f} ###")
print(f"### SRCC (Quality + Scene): {srcc_quality_scene:.4f} ###")
print(f"### SRCC (Quality + Distortion): {srcc_quality_distortion:.4f} ###")
print(f"### SRCC (Quality + Scene + Distortion): {srcc_quality_scene_distortion:.4f} ###")
print('### Testing Complete ###')
결과
| Task Combination | SRCC |
|---|---|
| Quality | 0.9326 |
| Scene + Quality | 0.9221 |
| Distortion + Quality | 0.9272 |
| Distortion + Quality + Scene | 0.9267 |

그래도 해야지