
컴퓨터구조 시리즈에 올린 2~7번 게시글을 요약한 내용입니다.
[Chapter 1] Computer Abstractions and Technology
1.1 Introduction
1. 무어의 법칙
- 1965년 인텔 CEO인 골든 무어가 2년마다 하나의 칩에 들어가는 트랜지스터 수는 두 배씩 증가할 것이라 예언
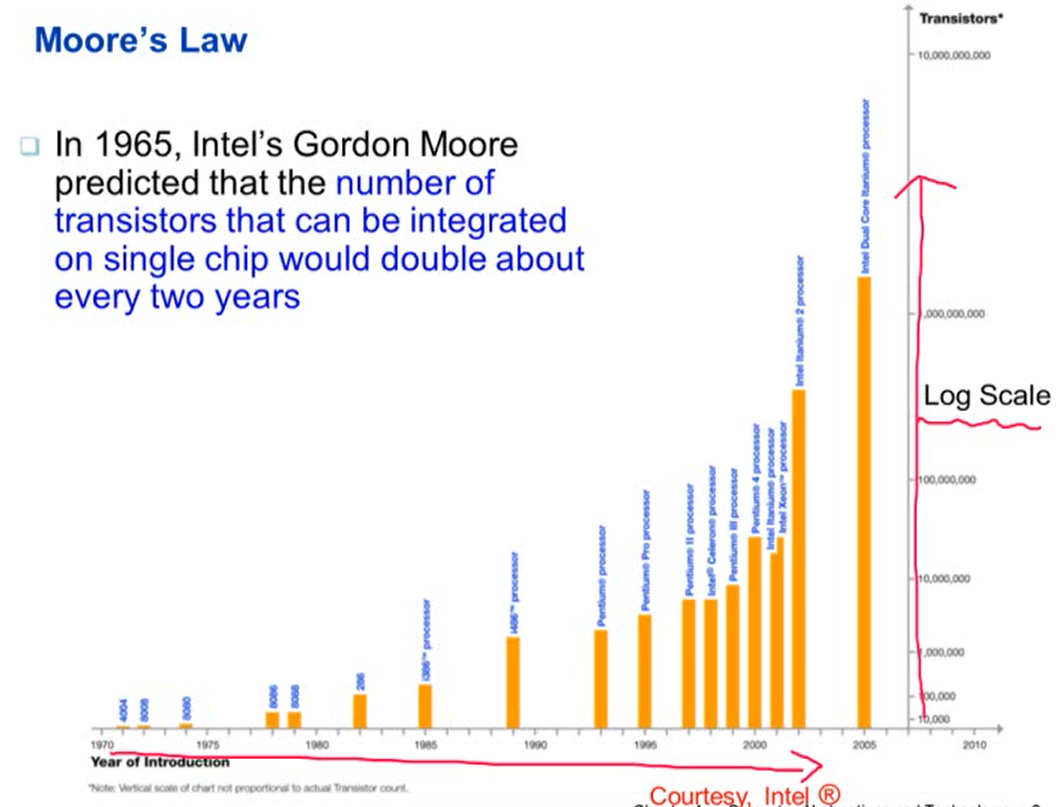
- 실제론 두 배보다 더 빠르게 증가
- 많은 트랜지스터가 들어가므로 다양한 어플리케이션 실행이 가능해짐
2. 기본 단위

3. Performance의 이해
- 알고리즘에서의 성능
- 오퍼레이션(추상화된 개념)의 수로 정의
- 오퍼레이션의 수가 적을수록 성능이 좋음
- 프로그래밍 언어, 컴파일러, 아키텍처에서의 성능
- 오퍼레이션 당 수행되는 인스트럭션(실제 CPU가 실행하는 명령어)의 수로 정의
- 프로세서와 메모리 시스템에서의 성능
- 얼마나 명령어들을 빠르게 수행할건가
- 단위 시간당 얼마나 많은 명령어들이 수행되는가
- I/O 시스템에서의 성능
- 단위 시간당 얼마나 많은 I/O operation이 수행되는가
1.4 Under the Covers
1. Inside the Processor (CPU)
- datapath: 데이터가 연산이 되는 경로
- control: 프로세서에 있는 다양한 컴포넌트들을 컨트롤
- cache memory: cpu 내부의 작고 아주 빠른 SRAM으로 구성된 캐시 메모리에 자주 사용하는 데이터를 저장해 빠르게 접근할 수 있도록 함
2. 저장공간
- 휘발성 메인 메모리
- ex) DRAM
- 전원이 꺼지면 저장된 데이터가 사라짐
- 비휘발성 메모리
- magnetic disk, Flash memory(SRAM), Optical disk(CDROM, DVD)
3. Abstractions (추상화)
- 아주 복잡한 문제를 풀 때 사용하면 효과적. 복잡한 문제를 단순화해 쉽게 풀 수 있도록 하는 기법
- 컴퓨터 구조에서 추상화의 대표적인 예가 Instruction set architecture(ISA)
- ISA는 하드웨어/소프트웨어 인터페이스
- 소프트웨어는 instruction으로 구성. 하드웨어는 instruction을 실행. 소프트웨어와 하드웨어는 instruction을 통해 데이터를 주고 받음
- Application binary interface(ABI)
- ISA와 밀접하게 관련되어 있음
- ISA와 시스템 소프트웨어의 인터페이스
1.6 Performance
1. Response Time and Throughput
1. Response Time
- operation을 할 때 얼마나 걸리는가
- 하나의 operation에 걸리는 시간
2. Throughput
- 단위 시간당 얼마나 많은 일을 할 수 있는가
- ex) 한 시간 동안 실행한 transactions의 수
3. 만약 기존 사용하던 CPU보다 더 빠른 CPU를 사용하려면
- 오래된 CPU를 새 CPU로 교체했을 때 response time과 throughput에 영향을 주는가?
- 영향을 줌. 더 빠른 CPU를 사용할 경우 response time이 줄어들고, response time이 줄어듦에 따라 단위 시간당 할 수 있는 연산의 수도 증가하므로 throughtput이 증가함
- CPU를 추가할 경우 response time과 throughput에 영향을 주는가?
- 하나의 코어에서 실행하는 시간은 줄어들지 않음. 즉, response time은 영향을 받지 않음. 하지만 throughput은 증가. 각각의 코어에서 서로 다른 일을 할 수 있기 때문에 단위 시간 당 한 일의 수가 많아짐.
- 일반적으로 response time이 감소할 경우 throughput은 증가. 하지만 throughput은 response time에 영향을 주지 않을 수도 있음
- 이제부터는 response time에 집중. 즉, 성능 측정 기준을 response time으로 함
2. Relative Performance
- Performance = 1 / Execution Time
- Performance와 Excution Time은 반비례 관계

- 수식의 값이 n일 경우 "는 보다 배 빠르다"라고 표현
- Performance와 Excution Time은 반비례 관계
3. Excution Time 측정
1. Elapsed time (걸린 시간)
- operation이 시작할 때부터 끝날 때까지 걸리는 시간
- processing, I/O, OS overhead, idle time(대기 시간)을 모두 포함한 시간
- 시스템 전체의 성능을 정의할 때 사용
2. CPU time
- 어떤 일을 처리할 때 CPU에서 걸리는 시간
- I/O 시간과 CPU가 다른 일을 할 때 걸리는 시간을 제외
- user CPU time(user 레벨에서 CPU를 사용할 때 걸리는 시간)과 system CPU time(작업을 수행하기 위해 운영체제에서 걸리는 시간)으로 나눠짐
- 프로그램에 따라 성능에 영향을 주는 요인이 다름
- 어떤 프로그램은 CPU에 영향을 받을 수 있고, 어떤 프로그램은 I/O에 영향을 받을 수 있음
4. CPU Clocking
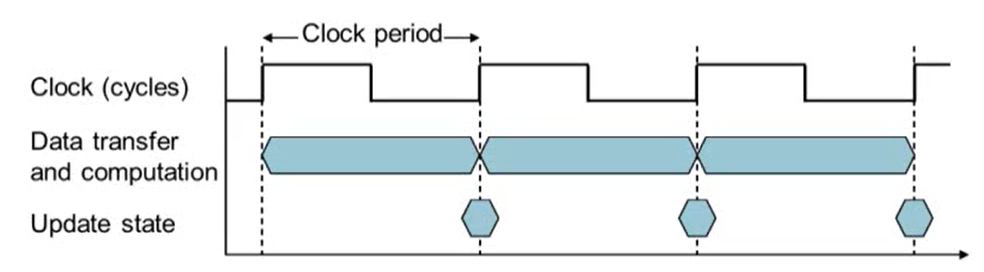
- Clock period: 하나의 clock cycle 동안 걸리는 시간 (단위: ps)
- Clock frequency(rate): 초당 몇 cycles이 존재하는가 (단위: Hz)
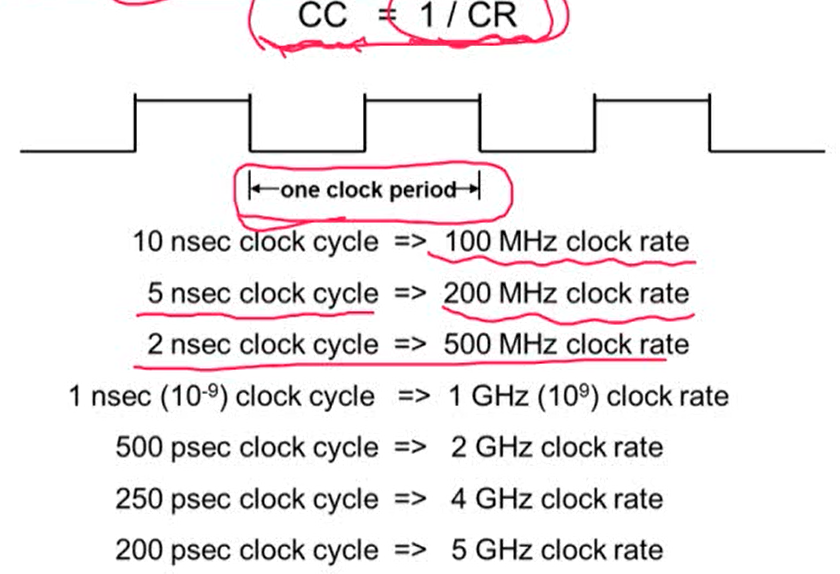
- Clock rate는 Clock cycle time(Clock period)와 반비례 관계
5. CPU Time

- 성능을 향상시키기 위해서는
- clock cycles 수 감소
- clock rate 증가
- cycle 수와 clock rate는 트레이드 오프 관계
6. Instruction Count and CPI

- Instruction Count: 프로그램, ISA, 컴파일러에 의해 결정
- CPI: CPU 하드웨어가 어떻게 구성되어 있는지에 따라 결정
- 각각의 다른 instructions는 서로 다른 CPI를 요구
- 서로 다른 instructions이 섞여있을 경우 평균 CPI를 사용해야 함

- Computer A의 Clock rate: 4GHz, Computer B의 Clock rate: 2GHz
- Same ISA: Instruction Count의 값이 A, B가 서로 같음을 의미
- 성능은 Excution Time에 반비례. 컴퓨터 A가 컴퓨터 B보다 1.2배 빠름을 의미
7. CPI in More Detail
- 다른 instruction classes는 다른 cycles 수를 요구

- 평균 가중치 CPI: 여러 개의 instruction classes을 사용할 때 사용
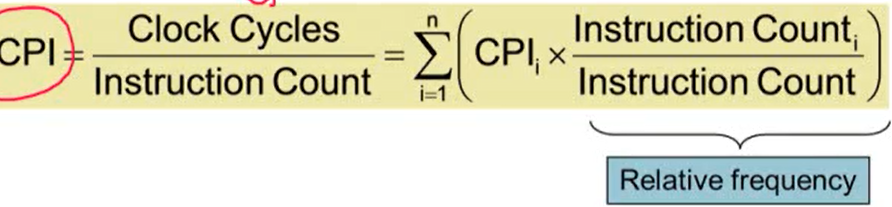
- 예시
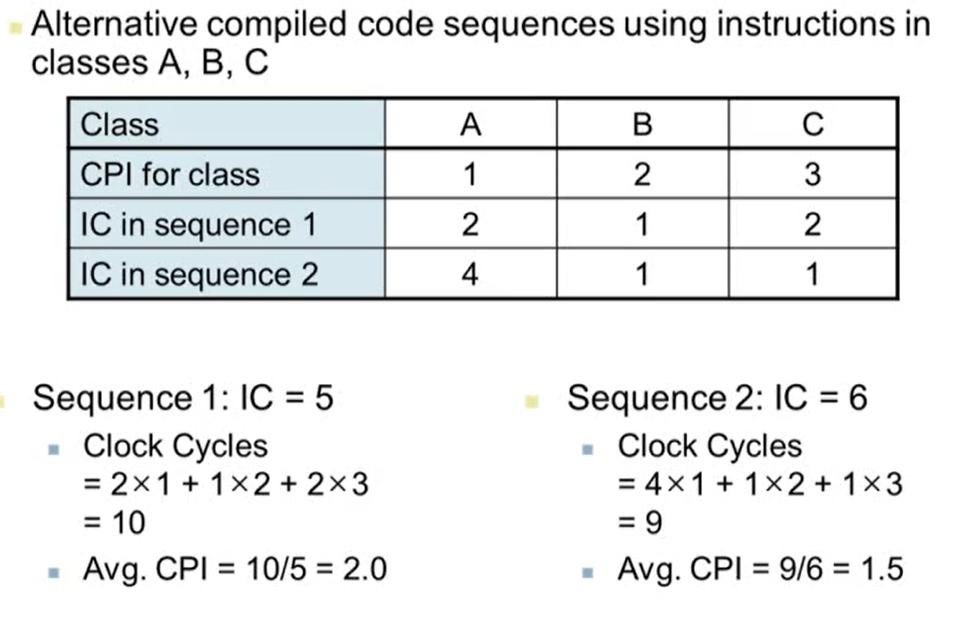
- IC: Instrcution Count
- Sequence 2가 Sequence 1보다 IC가 하나 더 많지만 Clock Cycles는 하나 작음. 즉, Sequence 2가 Sequence 1보다 실행 시간이 빠를 수 있음
- 하나의 instruction을 수행하는데 걸리는 CPI가 Sequence 1의 CPI보다 짧기 때문에 Sequence 2가 Sequence 1보다 삐르게 수행 가능
- 예시
1.8 The Sea Change: The Switch to Multiprocessors
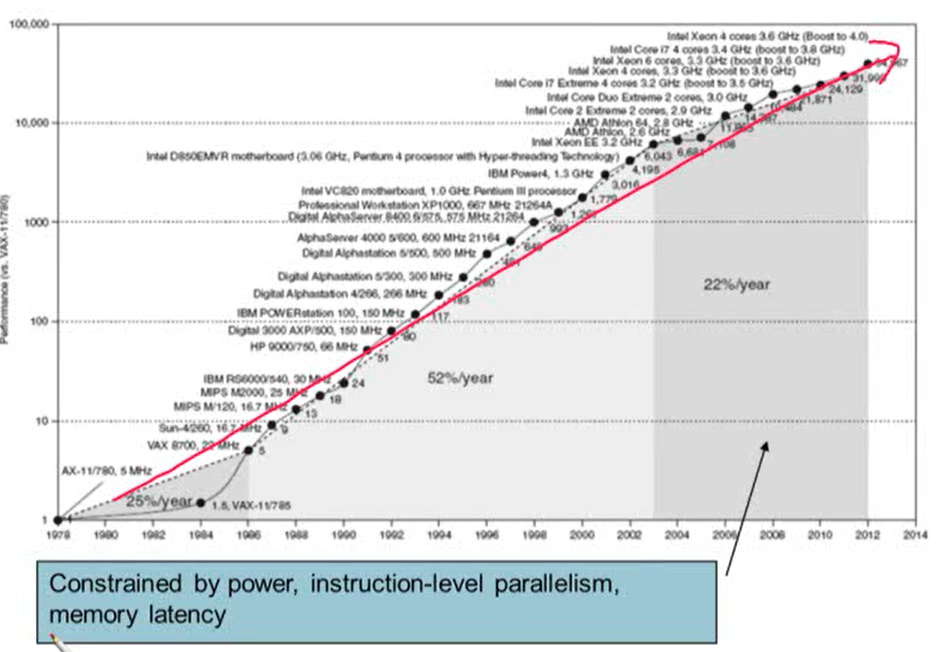
- power(전력), instruction-level parallelism, memory latency로 인해 싱글 코어일 때보다 성능 향상 퍼센트가 낮아짐
1. Multiprocessors
- Multicore microprocessors: 하나의 칩 안에 여러 프로세서를 넣음
- 멀티코어의 성능 향상을 위해서는 parallel programming을 사용해야 함
- parallel programming: 프로그래머가 하나하나 프로그램을 짜야 함
- 하나의 일을 여러 개로 나눴을 경우 나눠진 일들이 비슷한 load를 가져야 함
- parallel programming에서 발생하는 communication과 synchronization 문제를 줄여주어야 함
- parallel programming: 프로그래머가 하나하나 프로그램을 짜야 함
- 멀티코어에서의 성능 향상을 위해서는 parallel programming을 사용해야하는데 parallel programming을 사용하는 것 자체가 어렵기 때문에 유니 코어(싱글 코어)에 비해 성능 향상 속도가 낮을 수 밖에 없음
2. SPEC CPU Benchmark
- SPEC: Standard Performance Evaluation Corp
- CPU, I/O, Web 등의 성능을 측정해주는 benchmarks를 만드는 회사
- SPEC CPU Benchmark
- CPU의 성능을 측정하는 benchmark
- SPEC CPU 2006
- 여러 개의 프로그램을 실행해 실행한 프로그램의 총 실행 시간을 더함
- 아주 작은 I/O를 사용하므로 I/O 시간을 무시할 수 있고 CPU 성능을 측정하는데 집중
- 기존의 표준 성능으로 잡은 reference machine과 비교해 얼마나 성능이 향상되었는지 비교 가능
- 여러 개의 프로그램을 실행해 실행한 프로그램의 총 실행 시간을 더함
1.9 Concluding Remarks
1. Cost/performance is improving
- 무어의 법칙: 2년마다 하나의 칩에 들어가는 트랜지스터 수는 두 배씩 증가할 것
- 무어의 법칙에 의해 가격 대비 성능이 계속 향상되고 있음
2. Hierarchical layers of abstraction
- 추상화: 아주 복잡한 문제를 풀 때 사용하면 효과적. 복잡한 문제를 단순화해 쉽게 풀 수 있도록 하는 기법
3. Instuction set architecture
- 컴퓨터 구조에서의 abstraction은 ISA라고 할 수 있음
- ISA는 하드웨어와 소프트웨어의 인터페이스
- 하드웨어와 소프트웨어가 통신하는 방식이 instruction임
4. Excution Time
- 가장 좋은 성능 측정 방법
- Performance = 1 / Execution Time
5. Power is a limiting factor
- power 문제는 성능을 향상시키는데 제약이 됨
- 이 문제는 멀티코어 방식을 사용해 해결하려고 하고 멀티 코어에서는 parallelism을 사용해야만 성능 향상이 가능
1.10 Fallacies and Pitfalls
1. Pitfall: Amdahl's Law
- 컴퓨터의 한 부분의 성능을 향상 시키면 전체 performance의 성능 향상은 비례한다

- T_affected: 한 부분의 향상시킨 후의 성능
- T_unaffected: 성능을 향상시키지 않았을 때의 성능
- improvement factor: 성능을 향상시킨 한 부분
- 시스템의 한 컴포넌트 성능을 향상시키면 전체 시스템의 성능 향상은 그 컴포넌트가 시스템의 얼마만큼을 차지하는지의 비율에 비례한만큼만 향상됨
- 어떤 시스템의 성능을 향상시키기 위해서는 그 시스템에서 가장 많은 portion을 차지하는 컴포넌트를 가장 빠르게 만드는 것이 전체 시스템 성능을 향상시킬 수 있는 방법
2. Pitfall: MIPS as a Performace Metric
- MIPS: Millions of Instructions Per Second (시간당 몇 백만개의 instructions을 실행하는가)
- MIPS를 Performance Metric으로 사용했지만 MIPS를 Performance Metric으로 사용할 경우 오해를 불러올 수 있음
- 컴퓨터마다 ISA가 다르기 때문
- 명령어마다 복잡성이 다르기 때문

- MIPS는 CPI에 의해 좌우됨. 하지만 CPI는 프로그램과 CPU에 의해 달라질 수 있음. 따라서 성능 측정 단위로 사용하기 어려움
- 정확한 성능 측정을 위해서는 앞에 나온 SPEC CPU Benchmark를 사용하는 것이 좋음
공식 암기
- performance = 1/Execution Time
- CPU Time = Instruction Count X CPI X Clock Cycle Time
[Chapter 2] Instructions: Language of the Computer
2.1 Instruction
1. Instruction Set
- 컴퓨터에서 사용되는 명령어들의 집합
- 서로 다른 컴퓨터는 서로 다른 instruction set을 가짐. 하지만 대부분의 경우 많은 부분을 공유
2. Instruction Set Architecture (ISA)
- Architecture라고도 함
- 하드웨어와 가장 low level의 소프트웨어(ex. 시스템 소프트웨어, 운영체제) 간의 인터페이스
- ISA를 사용해 필요한 정보를 instruction에 담아 CPU에 주면 하드웨어는 instruction을 실행
- instruction의 종류, 레지스터, 메모리, I/O 정보가 포함되어 있음
- ISA를 사용하면 똑같은 소프트웨어를 실행할 때 성능과 비용에 따라 다른 implementation이 가능. 같은 소프트웨어를 여러 개의 CPU에서 실행할 수 있음
- Application Binary Interface(ABI): ISA와 운영체제의 인터페이스를 합친 것
- user 관점에서 아주 중요. ABI가 같다는 것은 어떤 프로그램이 특정 컴퓨터에서 실행될 때 이 프로그램은 실행되고 있는 컴퓨터와 ABI가 같은 다른 컴퓨터에서 실행시킬 수 있음
- 실제 모든 연산은 레지스터에서 이루어짐
2.3 Operands of the Computer Hardware
1. Register Operands
- 산술 연산은 레지스터를 사용
- MIPS는 32 X 32-bit 레지스터 파일을 가짐
- 레지스터에서 자주 사용하는 데이터들을 로딩해서 사용
- 32bit 데이터(4byte 데이터)를 'word'라고 부름
- Assembler names
- t로 시작하는 레지스터(temporary values를 저장해서 사용하는 레지스터)와 s로 시작하는 레지스터(사용하는 변수에 매핑되는 레지스터)가 존재
2. Byte Addresses
- 대부분의 컴퓨터에서는 메모리를 바이트 단위로 지정할 수 있음. 비트 단위로 access
- Alignment restriction: 32bit 프로세스의 경우 메모리 단위는 word 단위로 맞춰짐. 32비트씩 access 한다는 것은 기본 access 단위가 word라는 것
- Endian: data를 word 안에 어떤 방법으로 저장할 것인가
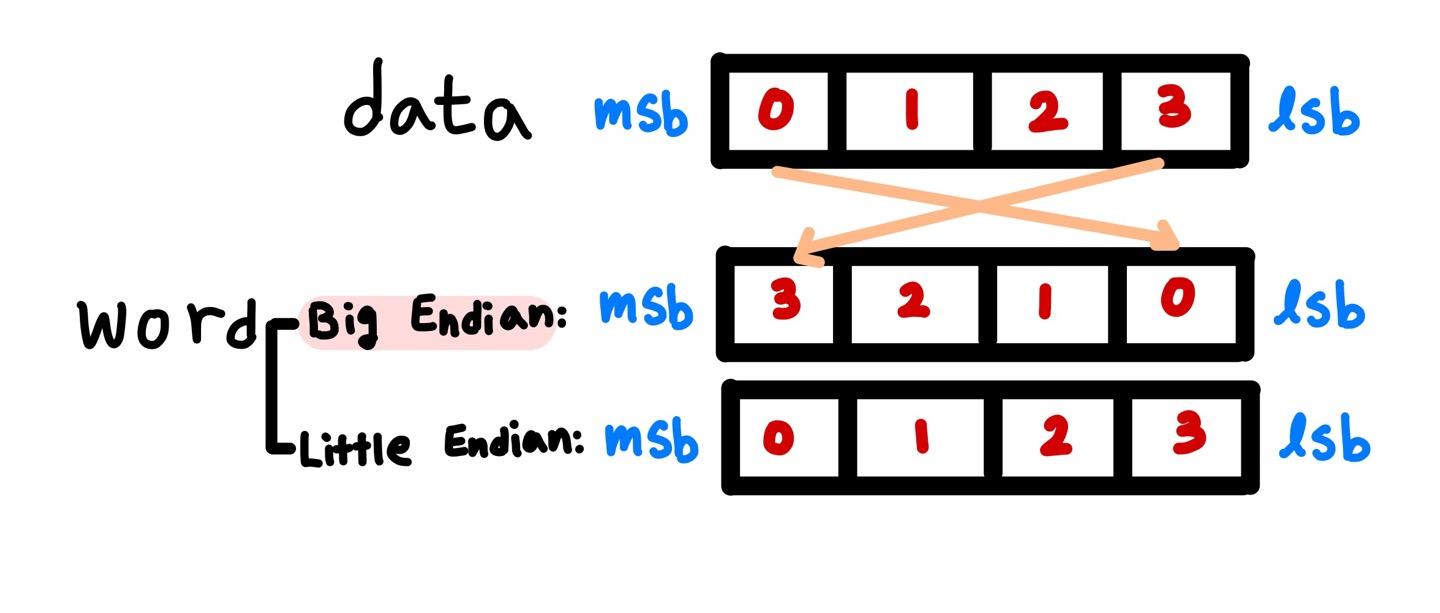
- Big Endian: leftmost byte를 word address로. 어떤 숫자의 큰 값을 가장 끝에 놓겠다는 것을 의미. 저장되어있는 데이터를 뒤집어서 저장하는 방식

- Little Endian: rightmost byte를 word address로. 어떤 숫자의 작은 값을 가장 끝에 놓겠다는 것을 의미. 저장되있는 데이터를 그대로 저장하는 방식
- Big Endian: leftmost byte를 word address로. 어떤 숫자의 큰 값을 가장 끝에 놓겠다는 것을 의미. 저장되어있는 데이터를 뒤집어서 저장하는 방식
3. Memory Operands
- Array, structures, dynamic data 등을 메모리에 저장
- To apply arithmetic operations
- 메모리에서 레지스터로 데이터 로딩(load)
- 연산의 결과를 레지스터에서 메모리로 적재(store)
- 메모리는 byte 단위로 access. 각각의 주소는 8-bit byte로 구성
- 메모리는 word 단위로 조정됨. 주소는 반드시 4의 배수로 구성
- MIPS는 Big Endian 방식을 사용
Memory Operand Example 1
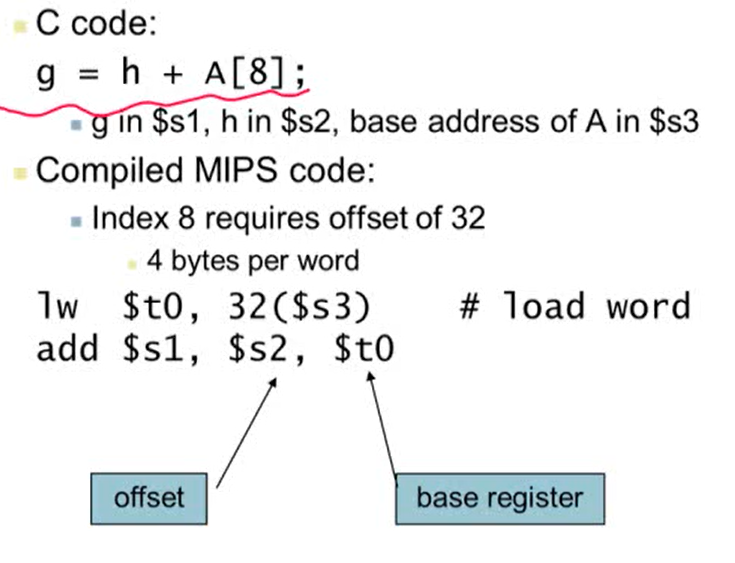
- A: int형
- load word: 메모리로부터 데이터를 로딩
- 32($3): $3의 값(A의 시작 주소)에 32를 더한 메모리 주소
- lw $t0, 32($3): 메모리에서 32($3)에 있는 값을 가져와 $t0에 저장
4. Registers vs Memory
- 레지스터는 메모리보다 access하는 시간이 더 빠름
- Load-Store Architecture: 메모리의 데이터를 연산하고 싶은 경우 로딩을 해서 레지스터로 데이터를 가져온 후 연산을 하고 다시 메모리에 저장
- MIPS는 Load-Store Architecture. MIPS 프로세서는 명령어가 직접 메모리에 access해서 연산하지 못함
- 컴파일러는 register를 효율적으로 사용해야 함
- 메모리에 access하는 횟수가 줄어듦
- register optimization(레지스터를 최대한 활용하는 것)은 컴퓨터 아키텍처에서 중요한 주제!
Register 정리
- 메인 메모리에 access하는 것보다 훨씬 빠름
- 레지스터를 사용할 경우 컴파일러는 연산을 하는데 훨씬 더 수월해짐
- 코드의 집적도가 향상됨. 집적도가 높다는 것은 같은 일을 수행할 때 instruction이 적다는 의미. 즉, 코드의 길이가 짧아짐
5. MIPS Register File
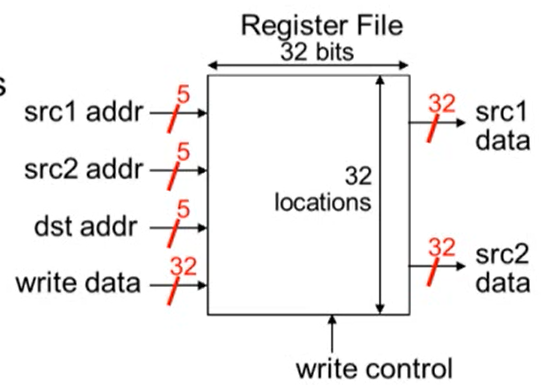
- 32bit의 레지스터를 가짐. 두 개의 read 포트와 하나의 write 포트를 가짐
- 읽기 주소: src1 addr, src2 addr
- 저장 공간은 5bit이면 충분 ()
- 쓰기 주소: dst addr
- 쓸 데이터: write data
6. MIPS Register Convention
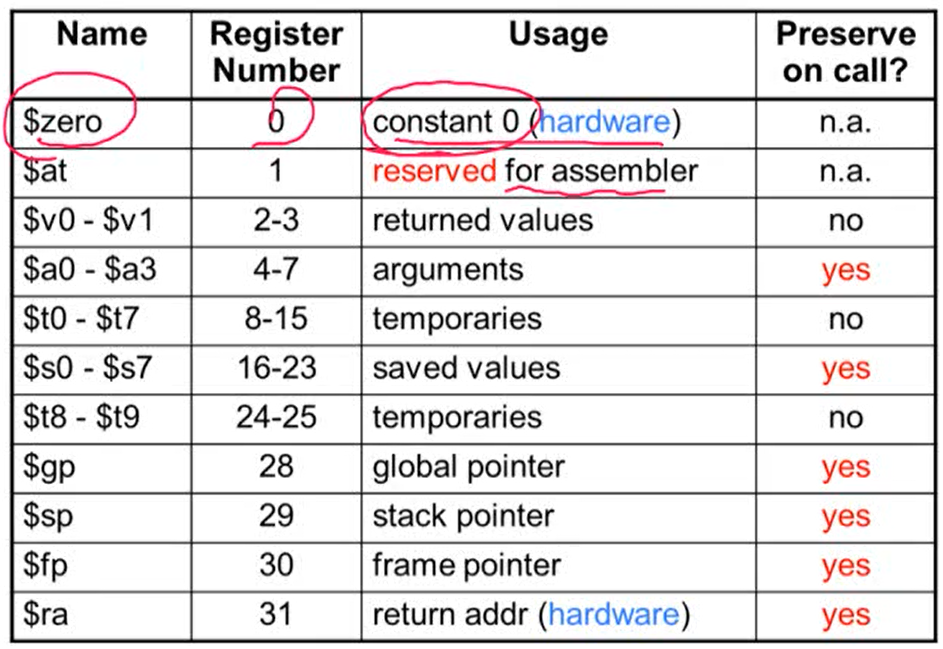
- $zero: 하드웨어. 읽기만 가능하고 쓰기는 불가능. 항상 값이 0
- MIPS에서 유용하게 사용
- 레지스터 값을 복사하고 싶은 경우: add $t2, $s1, $zero
- $at: 프로그래머는 사용하지 않고 어셈블러만 사용
- $a: function call할 때 사용
- $v: return 값을 저장할 때 사용
7. Immediate Operands
- 하나의 값이 상수 값을 가지는 경우
- ex) addi $s3, $s3, 4 => $s3 = $s3 + 4
- 뺄셈의 경우 지원하지 않음
2.4 Signed and Unsigned Numbers
1. 컴퓨터의 숫자 사용 방식
- unsigned binary integer, 부호가 있는 integer의 경우 2의 보수 사용
2. 명령어에서의 숫자 사용 방식
- 모든 명령어는 binary로 표현
- MIPS 명령어는 32비트로 표현 (opcode: operation code의 수가 적음)
1. MIPS R-format Instructions

- op: operation code
- rs: source register, rt: target register, rd: destination register
- shamt: shift amount
- funct: function code (ex. 더하기, 빼기 ..)
- 예시

- shift 연산은 수행되지 않으므로 shamt 값은 0
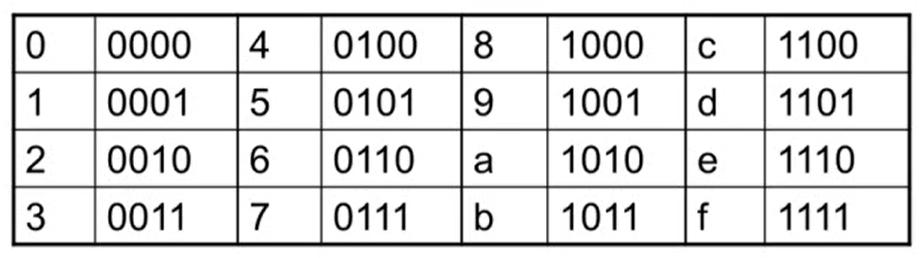
2. Hexdecimal (16진수)
- 사람이 이해하기 위해 16진수로 표현하는 경우가 많음
- 16진수는 4bit씩 표현. 16진수로 표현할 때 앞에 0x를 붙임
3. MIPS I-format Instructions
- I: Immediate를 의미
- Immediate arithmetic 또는 load/store 연산할 때 사용

- rt: destination 또는 source 레지스터 값
- constant 범위: (-2^15) ~ (2^15 -1)
- address: rs 레지스터 값이 더해지는 offset
2.6 Logical Operations
1. 논리 연산
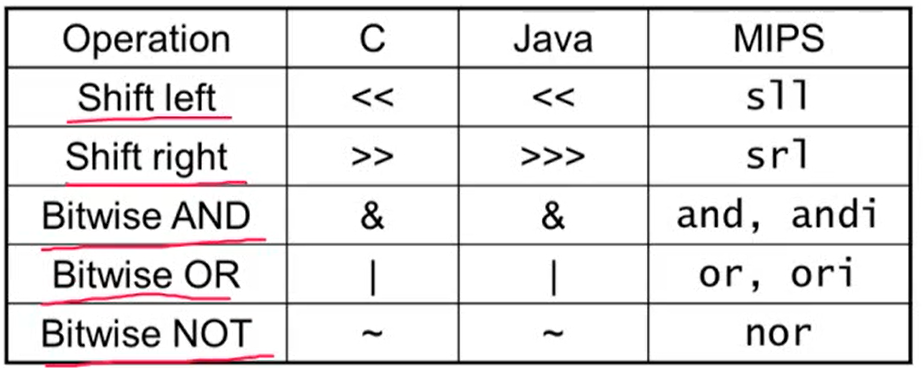
- Bitwise: 비트 단위로 연산을 수행
- 한 비트에서 특정 비트의 값을 추출하거나 추가하는데 유용하게 사용
1. Shift Operations

- shamt: shift 연산을 몇 번 할 것인가
- shift left logical: 왼쪽으로 shift한 후 빈자리는 0으로 채움 (sll, 만큼 곱한 효과)
- shift right logical: 오른쪽으로 shift한 후 빈자리는 0으로 채움 (srl, 만큼 나눈 효과) => unsigned에서만 가능
2. AND Operation
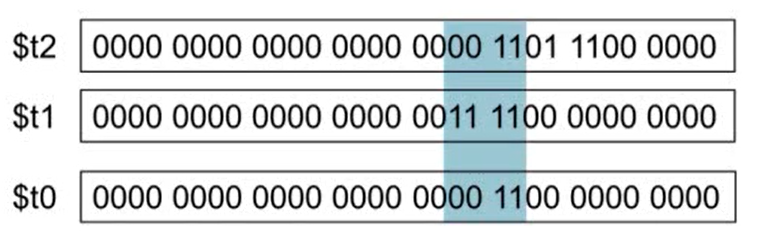
- 두 값이 모두 1이어야 1
- 특정 비트 값을 추출할 때 사용
3. OR Operation
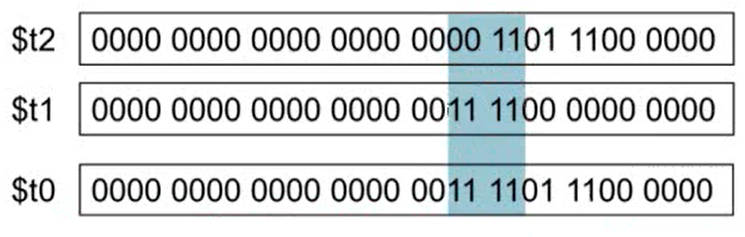
- 두 값 중 하나라도 1이면 1
- 특정 비트의 값을 1로 세팅할 때 사용
4. NOT Operation
- 0을 1로, 1을 0으로 변환
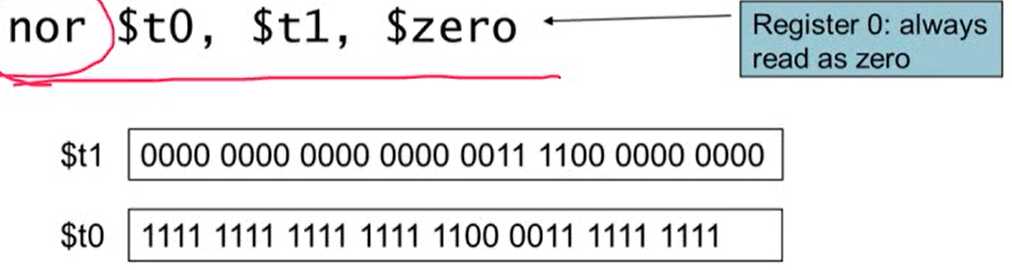
- MIPS는 NOT operand를 가지고 있지 않음. nor operand(3개의 operand를 사용)를 사용해 not을 구현
- $zero의 레지스터 값은 모두 0이므로 $t1의 레지스터 값을 반대로 바꿔줌
2.7 Instructions for Making Decisions
1. Conditional Operations
- Branch: 어떤 조건이 true일 경우 labeled instruction으로 가고 false일 경우 다음 instruction 수행

Compiling If Statements
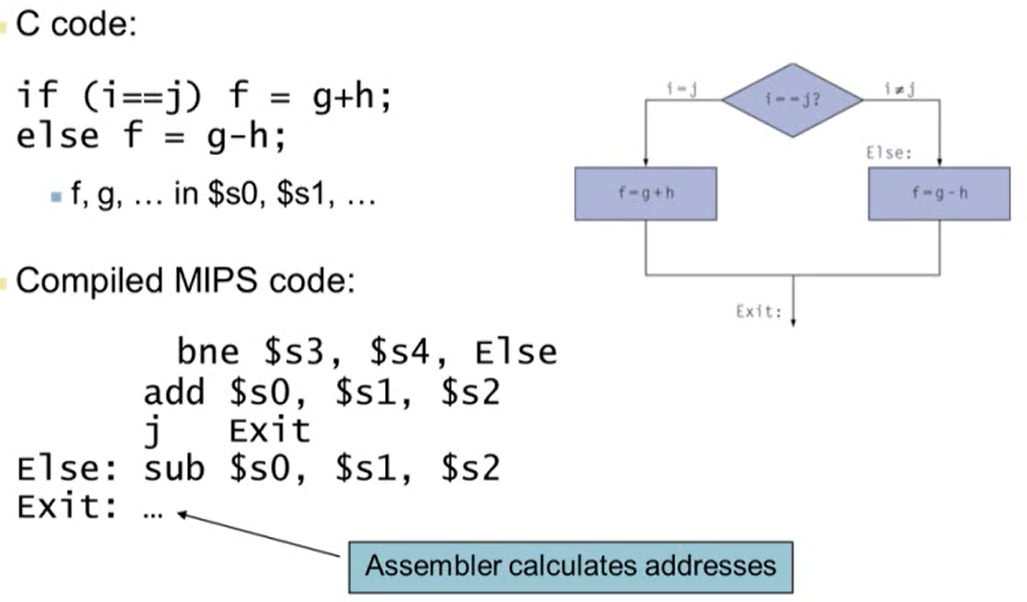
Compiling Loop Statements

- sll $t1, $s3, 2: $s3를 2비트만큼 왼쪽으로 이동
- $s3의 값에 4를 곱한 것과 같은 효과
- save는 integer array. 하나의 integer는 4byte.
- save[i]의 값을 찾기 위해서는 인덱스에 4를 곱한 후 더해주어야하기 때문에 위 연산을 수행
- add $t1, $t1, $s6: save의 주소의 시작값인 $s6과 $t1을 더해주면 save[i]의 주소값이 나옴
- lw t1): $t1에서 4바이트만큼 읽어서 $t0에 저장
- bne $t0, $s5, Exit: $t0, $s5가 같지 않으면 Exit. 같으면 addi 명령 수행
2. Basic Blocks
- 아래 두 조건을 만족시키는 연속된 명령어들의 집합
- 중간에 brach 관련 명령어가 없어야 함. 마지막 명령어에는 가능
- 중간에 branch target(labeled instructions)이 없어야 함. 시작 명령어는 가능
- 컴파일러는 basic blocks를 찾아 빨리 실행하는 역할
- 프로세서는 basic blocks 실행을 가속화시켜주는 역할
3. More Conditional Operations
- 어떤 조건이 true이면 1, false이면 0

- slt $t0, $s1, $s2: $s1의 값이 $s2보다 작으면 $t0 값은 1
- bne $t0, $zero, L: $t0의 값이 1일 경우 $zero와 값이 다르므로 L을 실행
2.8 Supporting Procedures in Computer Hardware
1. 함수(function, procedure)의 실행 단계
용어 정리
- caller: 함수를 부르는 것
- callee: 불려지는 함수
실행 단계
- caller가 callee가 접근할 수 있는 곳에 argument를 가져다 놓음
- $a0 - $a3: argument를 저장하는데 사용되는 네 개의 register
- caller가 callee에게 컨트롤을 넘겨줌
- callee가 필요한 메모리 공간을 할당받음
- callee가 해야할 일을 수행
- callee가 일을 마친 후 caller가 접근할 수 있는 위치에 return 값을 저장
- $v0 - $v1: return value를 저장하기 위해 사용되는 두 개의 register
- callee가 caller에게 컨트롤을 넘겨줌
- callee가 caller에게 컨트롤을 넘길 때 return address를 알고있어야 함
- $ra: return address를 저장하는데 사용되는 register
2. Local Data on the Stack
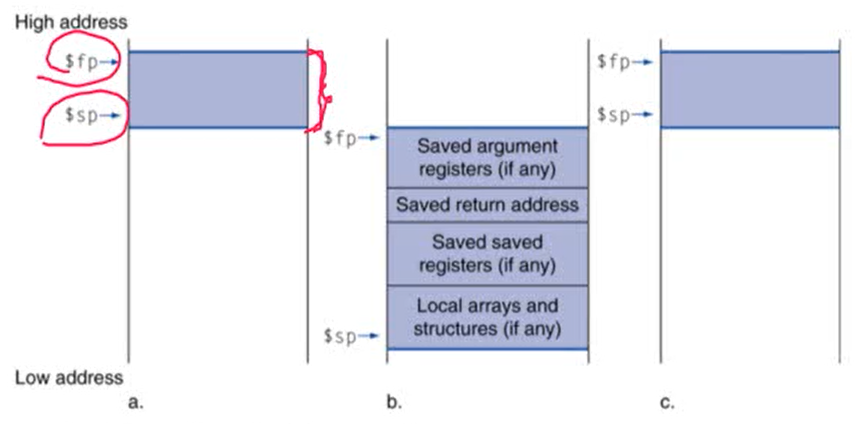
- 보라색 상자: activation record(procedure frame). 하나의 함수를 부를 때마다 activation record가 할당됨. b에 나와있는 값들을 저장
- $sp: stack pointer, 스택의 시작 위치
- $fp: frame pointer, 현재의 activation record의 시작 위치. 끝 위치를 가리키는 것이 $sp
3. Procedure Call Instructions
1. Procedure call: jump and link
jal ProcedureLabel: ProcedureLabel의 다음 명령어 주소를 $ra에 저장한 후 ProcedureLabel로 jump
2. Procedure return: jump register
jr $ra: $ra의 값을 program counter(PC, 현재 실행하고 있는 명령어의 메모리 주소 값을 가지고 있는 레지스터)에 복사해 프로그램이 $ra로 jump
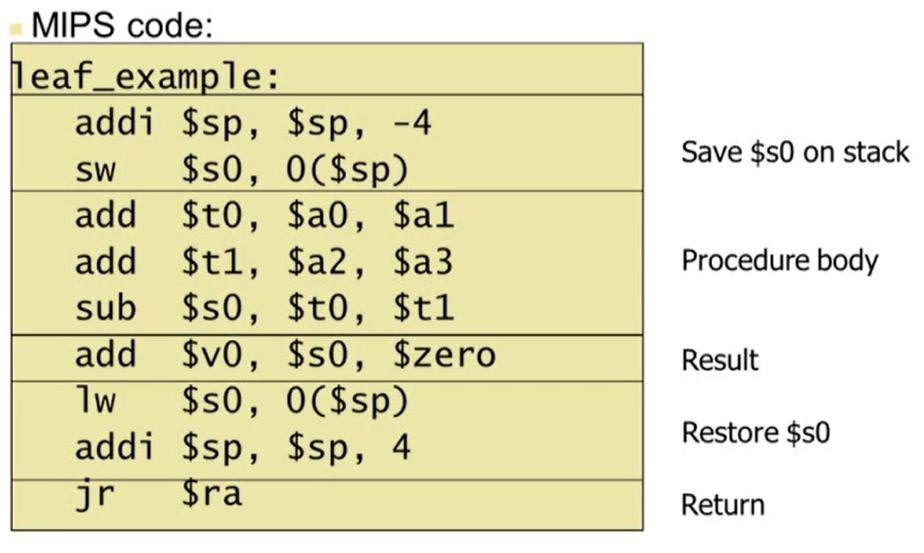
Leaf Procedure Example
- Leaf Procedure: 함수 내에서 다른 함수를 부르지 않는 것

- f는 로컬 변수이므로 $s0에 저장되어 있다고 가정
3. Non-Leaf Procedure
- 함수 내에서 다른 함수를 호출
- 함수 내에서 다른 함수를 호출할 경우 caller가 가지고 있던 return address의 값을 다른 곳에 저장해야함. 또한 호출한 함수의 argument 값을 stack에 저장해야함
- callee에서 caller로 온 후에 stack에 저장된 값을 복원해야 함
4. 메모리 구조
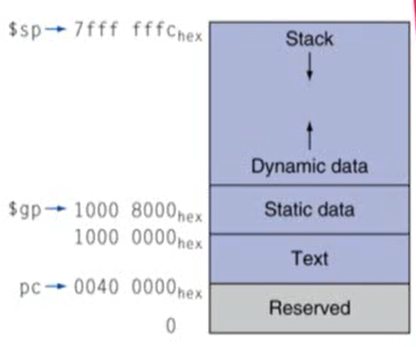
- Text: 프로그램 명령어 저장
- Static data: global variables(전역 변수), static 변수 저장
- $gp: Static data 부분의 중간을 가리켜 Static data에 접근하기 훨씬 수월하게 만듦
- Dynamic data(heap): C언어의 malloc, Java에서의 new를 사용할 경우 할당됨
- Stack: activation record가 할당되는 부분
- heap은 위쪽 방향으로 증가, Stack은 아래쪽 방향으로 증가
2.10 MIPS Addressing for 32-Bit Immediates and Addresses
1. Adressing
1. Branch Addressing
- branch는 특정 타켓 address로 가게됨

- PC-relative addressing
- Target address = PC + offset X 4
- PC는 현재 명령어가 수행되고 있으면 다음에 수행될 명령어의 주소를 가지고 있기 때문에 이미 4만큼 증가되어 있음. 따라서 Target address를 계산할 때에 고려해줘야함
- PC-relative addressing
2. Jump Addressing

- Target address = PC의 상위 4bit(31~28bit) + (address X 4)
- Example
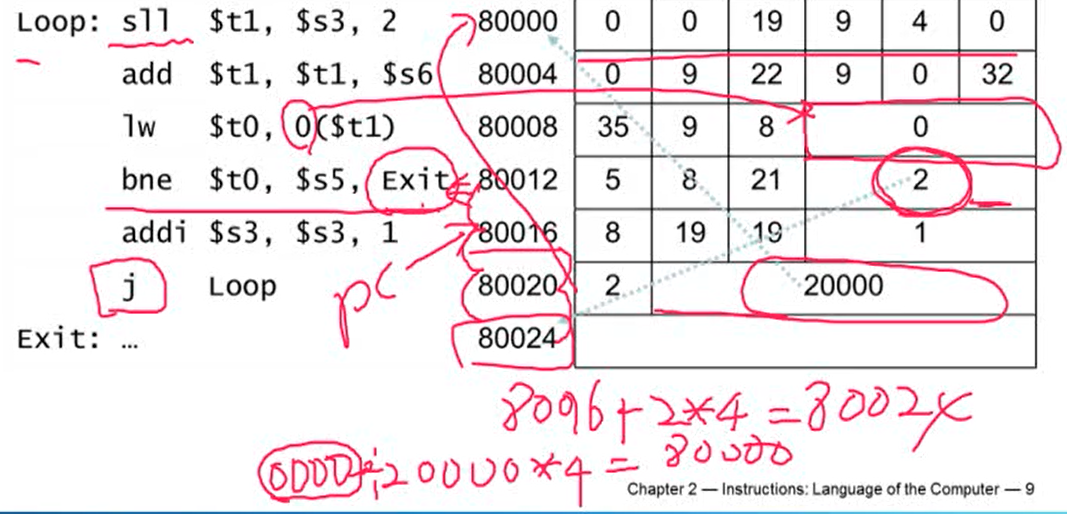
2. Branching Far Away
- branch의 경우 16bit offset 값을 넘어가는 경우가 있음. branch target이 너무 멀리 있어 16bit offset으로 커버가 안되는 경우 어셈블러는 명령어를 아래처럼 바꿔 씀

- branch 명령어 대신 jump 명령어 사용. jump 명령어는 26bit를 커버하기 때문에 훨씬 멀리 있는 곳까지 jump 가능
3. Addressing Mode Summary
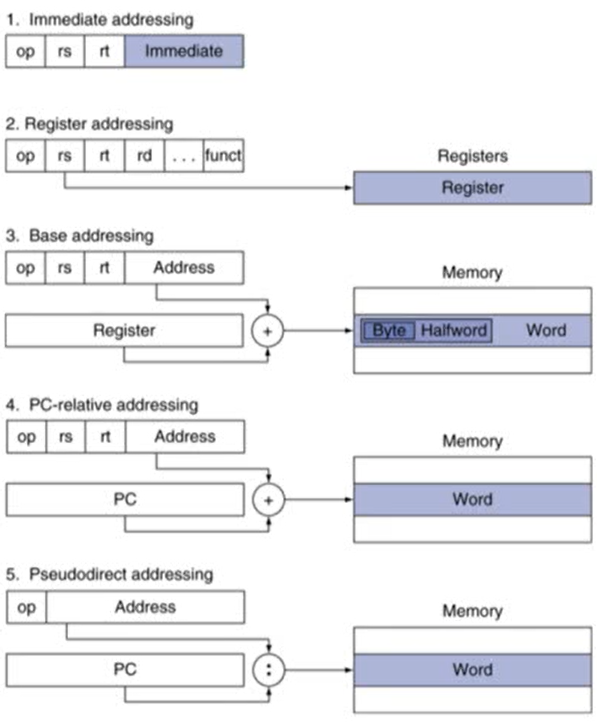
1. Immediate addressing
- 상수를 사용하는 경우
- ex) addi
2. Register addressing
- R-type
3. Base addressing
- load/store와 관련된 명령어
4. PC-relative addressing
- branch 명령어
5. Pseudodirect addressing
- jump 명령어
2.12 Translating and Starting a Program
Translation and Startup
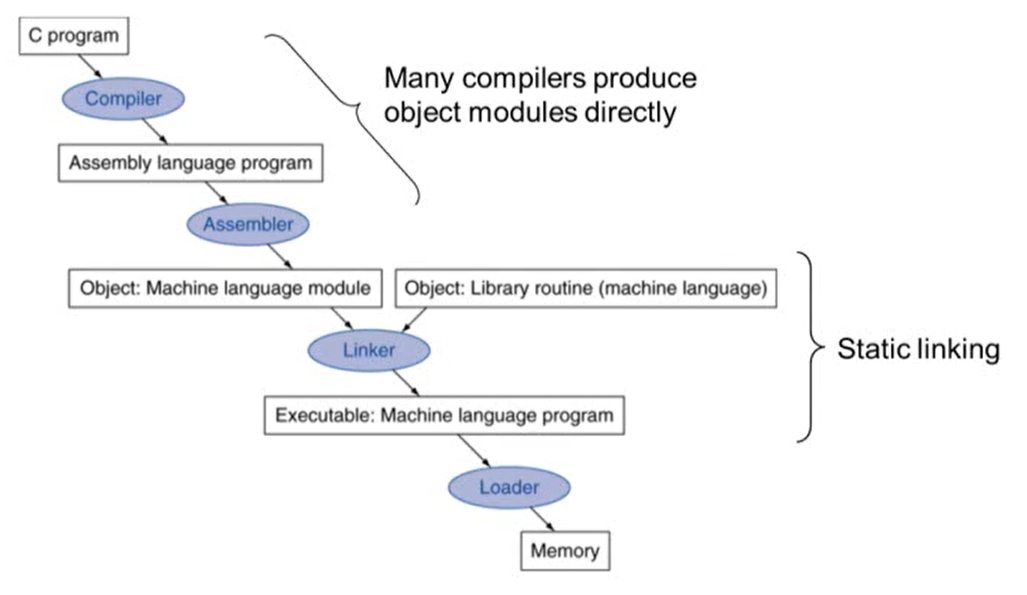
- Linker: 작성한 프로그래밍 언어와 library를 합쳐 실행 파일을 만들어줌
- loader: 프로그램이 실행되기 위해서는 저장장치에서 memory로 올라와야하는데 이 과정을 load라고 함. loader는 작성한 프로그램을 memory로 올려줌
- Static linking: 작성한 프로그램 안으로 library가 들어오는 것. 반대되는 개념이 Dynamic linking
Assembler Pseudoinstructions
- MIPS에서는 사용 불가능하지만 어셈블러에서 사용할 수 있는 가짜 명령어
- 어셈블러가 MIPS의 실제 명령어로 자동으로 바꿔줌

- move, blt 명령어는 실제 MIPS 명령어에는 존재하지 않지만 어셈블러에서는 사용 가능
- $at이라는 어셈블러만 사용할 수 있는 명령어를 사용해 실제 명령어로 바꿔줌
1. Producing an Object Module
- 어셈블러가 프로그램을 machine instructions으로 변환해주는 것
- 변환할 때 object module은 아래 정보를 가지고 있음
- Header: object module에 대한 내용
- Text segment: 변환된 명령어
- Static data segment: 전역 변수등이 저장
- Relocation info: 프로그램이 로딩될 때 의존하는 절대적인 주소에 대한 contents
- Symbol table: 코드에서 사용하는 global variable, 함수에 대한 정보
- Debug info: 디버깅을 위한 소스코드 정보가 포함
2. Linking Object Module
- 실행 파일로 만들기 위한 과정
- segments 병합
- 서로 다른 object module에서 사용한 labels를 해결
- location-dependent 정보와 함수를 위치에 맞춰줌
- 가상 메모리는 같은 공간을 사용하기 때문에 location dependencies 정보는 필요 없게 됨. 가상 메모리에 존재하는 절대 주소를 사용
3. Loading a Program
- 실행 파일을 디스크에서 메모리로 load
- 실행 과정
- header를 읽어 segment의 크기를 결정
- 가상 주소 공간(virtual address space) 생성
- text와 data를 생성한 공간에 올림
- stack을 위한 argument를 세팅
- 레지스터 초기화
- 시작 루트로 jump (C언어의 경우 main). 끝나면 exit를 호출
4. Dynamic Linking
- library를 link/load하는 과정을 library가 호출된 경우에만 수행
- Static Linking의 경우 호출 여부 상관없이 모든 library를 link/load함
- 실제 사용되는 library의 정보만 가져오기 때문에 실행 파일의 크기가 커지는 것을 방지할 수 있음
- 함수 관련 코드가 실행 파일에 저장되는 것이 아니라 dynamic linking 파일에 별도로 존재하기 때문에 새로운 버전의 library가 나올 경우 실행 파일을 새롤 만들 필요없이 dynamic linking 파일을 업데이트만 해주면 됨
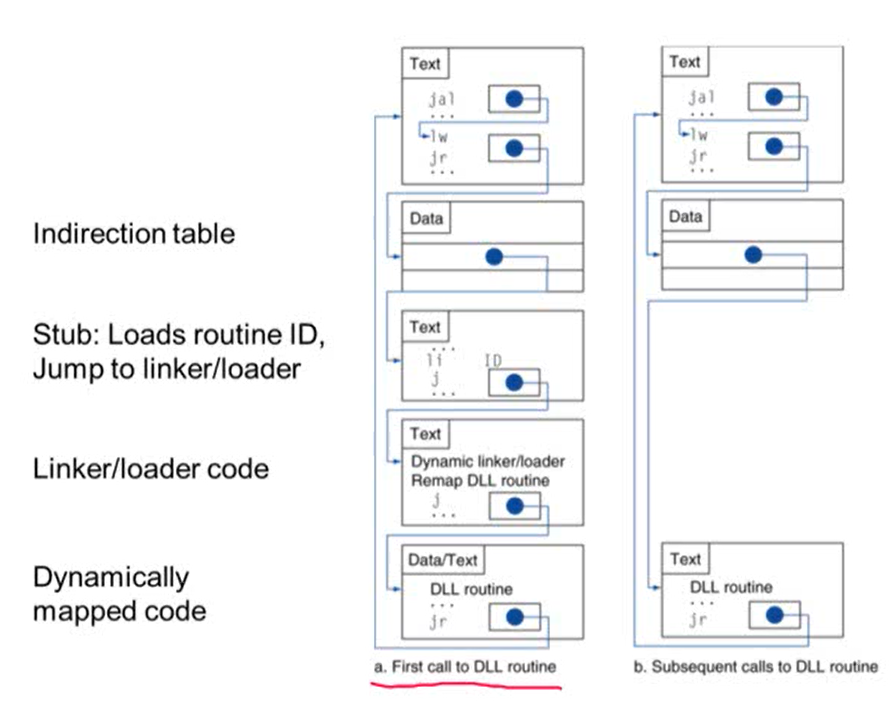
- 장점: 실행 파일의 크기가 커지는 것을 막을 수 있음. 새로운 버전의 라이브러리를 생성하더라도 실행 파일을 다시 컴파일하지 않아도 됨
- 단점: static linking에 비해 성능이 떨어질 수 있음
2.14 Arrays versus Pointers
1. Arrays vs Pointers
- array를 사용할 경우 항상 array의 인덱스를 계산하기 위해 인텍스에 element size를 곱해주는 연산 + 곱한 값에 array base address를 더해주는 연산이 필요
- pointer를 사용할 경우 바로 memory adress로 접근 가능. index를 계산하는 과정이 필요없게 됨
- pointer를 사용하는 것이 성능이 더 향상될 수 있음
Example: Clearing and Array

- array의 모든 값을 0으로 초기화해줌. 왼쪽 코드는 array, 오른쪽 코드는 pointer를 사용
- array를 사용할 경우 loop 안의 명령어 개수는 6개, pointer를 사용할 경우 loop 안의 명령어 개수는 4개로 구성
- loop의 반복이 많은 경우 pointer로 구현하는 것이 더 높은 성능을 보임
2. Comparison of Array vs Pointer
- 컴파일러는 포인터를 사용하는 것과 같은 비슷한 효과를 줄 수 있음
- Induction variable elimination: 인덱스 사용하는 것을 없애줌
- 컴파일러를 사용해 array 방식으로 프로그램을 구성하면 훨씬 이해하기 쉽고 버그가 생길 확률이 줄어듦
- pointer을 사용할 경우 버그가 생길 확률이 높기 때문에 일반적으로 프로그램을 구성할 때는 array를 사용하는 것을 권장
2.17 Real Stuff: x86 Instructions
Implementing IA-32
- MIPS: Reduced Instruction set(RISC)
- Intel의 아키텍쳐: Complex instruction set(CISC)
- implementation이 까다롭고 높은 성능을 보이기 어려움
- 해결 방법
- 하드웨어가 하나의 명령어를 간단한 suboperaions(microoperations)으로 나눔. 하나의 명령어가 여러 개의 명령어로 나눠지게 됨
- Microengine은 microoperation을 실행하는데 이 때 Microengine이 RISC와 유사해 성능을 낼 수 있었음
- 겉으로는 CISC이지만 내부적으로는 RISC
- Intel은 구조적으로는 MIPS에 비해 안 좋은 구조를 가지지만, 내부적으로는 MIPS와 같은 RISC 아키텍쳐를 따르기 때문에 CISC 명령어를 microoperations으로 나눠주는 오버헤드를 제외하면 내부적인 성능은 비슷
2.19 Fallacies and Pitfalls
1. Fallacies
-
Powerful instruction(하나의 명령어가 여러 개의 일을 한 번에 처리하는 것)을 사용하면 높은 성능을 보여줄 것
- 이유: 명령어의 수가 줄기 때문
- 실제로는 복잡한 명령어는 구현하기 어렵기 때문에 컴파일러는 powerful instruction보다 간단한 명령어 여러 개를 사용해서 만든 코드가 더 높은 성능을 보임
-
어셈블리 코드를 사용하면 높은 성능을 보여줌
- 실제로 높은 성능을 보일 순 있지만 최근의 컴파일러는 C언어로 작성한 코드도 어셈블리어로 작성한 코드와 유사한 성능을 보여줌
- 어셈블리 코드를 사용할 경우 line 수가 증가하기 때문에 더 많은 에러가 발생할 수 있고 생산성이 떨어짐. 따라서 특수한 경우(ex. 임베디드)를 제외하고는 high-level language를 사용하는 것이 좋음
-
Backward compatibility(예전 것이 새로운 환경에서도 지원이 되는 것)을 지원한다는 것이 instruction set이 바뀌지 않는다는 것을 의미
- instruction set이 바뀌지 않는다는 것을 의미하는 것은 아님
- instruction set는 계속 변경되지만 예전에 지원한 instruction이 현재에도 지원되기 때문에 backward compatibility를 보장
2. Pitfalls
-
Sequential words는 sequential addresses가 아님
- word의 크기는 4byte이므로 주소가 1이 아닌 4씩 증가
-
procedure 내에서 전역 변수를 가리키는 포인터를 사용했을 때 포인터가 함수가 끝난 후면 포인터가 가리키는 메모리 주소는 유효한 메모리 주소가 아니게 됨
- stack에서 pop될 때 포인터는 유효한 메모리 주소를 가리키지 않음
- 함수 내에서 정의한 포인터는 함수 내부에서만 사용해야 함
2.20 Concluding Remarks
1. Design principles
- Simplicity favors regularity
- 규칙성을 주면 구현할 때 훨씬 수월
- 간단하게 만들어야 낮은 가격으로 높은 성능이 가능
- Smaller is faster
- 작을수록 더 빠르다
- 메모리의 크기 등이 작을수록 더 빠름
- 참조) 메인 메모리는 millions of locations으로 구성. 레지스터는 32X32-bit로 구성되어 있으므로 메인 메모리에 접근하는 시간보다 레지스터에 접근하는 시간이 더 빠름
- Make the common case fasst
- 자주 사용하는 case를 빠르게 만들어라
- Immediate Operands를 지원하므로 상수값을 바로 사용할 수 있음
- Immediate Operands는 instruction을 load하는 수를 줄여줌
- Good design demands good compromises
- 서로 다른 두 가지를 하나로 만들어라
- Immediate arithmetic 과 load/store 연산은 별개의 operation이지만 I-format Instructions으로 두 개의 operation을 커버할 수 있음
- Instruction의 복잡성이 낮아지고 포맷이 단순해져 고성능을 얻을 수 있음
2. MIPS: typical of RISC ISAs
- cf) x86: typical of CISC
- MIPS는 benchmark 프로그램
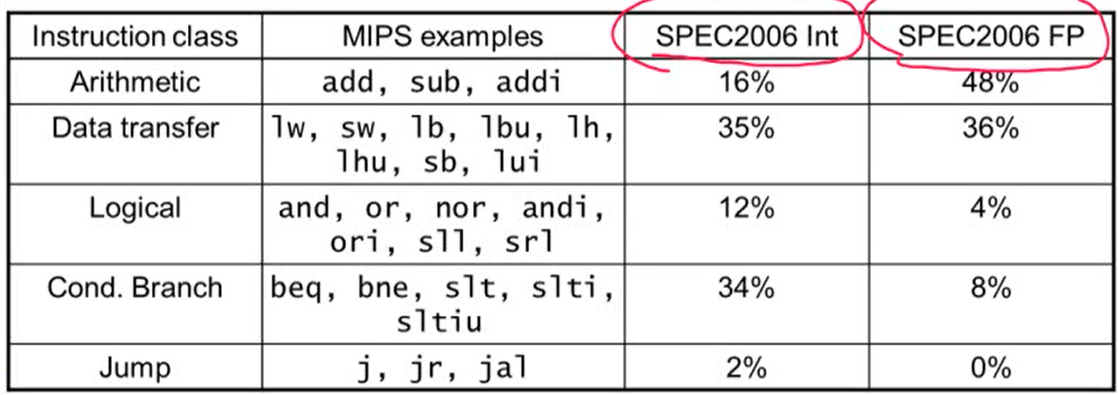
- Consider making the common case fast
- Integer의 경우 Data transfer과 Condition Branch를 빠르게 하는 것이 중요
- Floating point의 경우 Arithmetic과 Data transfer를 빠르게 하는 것이 중요
- Consider making the common case fast
[Chapter 3] Arithmetic for Computers
3.2 Addition and Subtraction
Integer Addition and Subtraction
1. Integer Addition
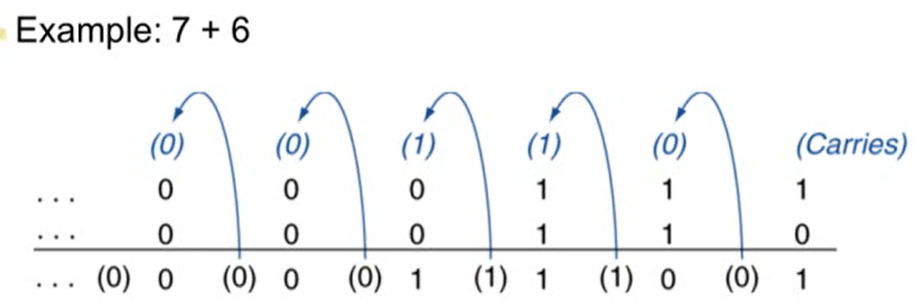
- Overflow: 어떤 값이 범위를 벗어나는 경우 발생
- positive와 negative를 더할 경우 overflow는 절대 발생하지 않음
- 두 개의 positive를 더하거나 두 개의 negative를 더하는 경우 overflow가 발생 가능
- 두 개의 positive를 더한 결과 sign bit이 1인 경우(음수인 경우) overflow 발생
- 두 개의 negative를 더한 결과 sign bit이 0인 경우(양수인 경우) overflow 발생
2. Integer Subtraction

- 두 개의 positive와 두 개의 negative의 subtraction에서는 overflow가 발생하지 않음
- negative에서 positive를 빼는 경우 sign bit이 0이 되면 overflow 발생
- positive에서 negative를 빼는 경우 sign bit이 1이 되면 overflow 발생
3. Dealing with Overflow
- C언어의 경우 overflow를 무시
- MIPS의 addu, addui, subu 명령어의 경우 overflow 무시
- Ada, Fortran의 경우 exception을 발생
- MIPS의 add, addi, sub 명령어의 경우 overflow가 발생하면 예외 처리
- 예외 처리 방법은 4장에서 다룸
3.5 Floating Point
1. IEEE Floating-Point Format

- S: sign bit. 0이면 양수, 1이면 음수
- 1+Fraction: significand(X 앞의 숫자). float에서는 정수 부분이 항상 1이므로 소수점 아래 숫자만 저장하면 됨. 이 때 소수점 아래 숫자를 fraction이라고 부름
- significand 범위: 1 이상 2 미만
- Bias: Single일 경우 127, Double일 경우 1203
- Exponent를 저장할 때는 실제 exponent 값에 bias를 더한 값을 저장하기 때문에 값을 구할 때는 bias 값을 빼준 후 계산
2. Floating-Point
1. Relative Precision
- Single: 6자리의 10진수 표현 가능
- Double: 16자리의 10진수 표현 가능

2. Infinities and NaNs
- Infinities: Exponent = 111...1, Fraction = 000...0일 경우
- NaNs: Exponent = 111...1, Fracion이 000...0이 아닌 경우
3. Floating-Point Addition

- Integer보다 연산이 복잡해 하나의 clock cycle로 연산을 수행하기에는 오래 걸림. 이럴 경우 다른 모든 명령어의 수행이 늦어지기 때문에 일반적으로 여러 cycle를 사용
- 이 단점을 보완하기 위해 pipline(병렬)로 처리. 하나의 명령어는 여러 cycle에서 실행되지만 throughput을 높여 여러 개의 명령어가 동시에 실행되기 때문에 단위 시간당 float-point adder를 할 수 있는 명령어의 개수는 증가
4. Floating-Point Arithmetic Hardware
- Addition, subtraction, multiplication, division, squareroot를 지원
- FP와 Integer의 변환도 지원해줌
- 연산들은 여러 사이클을 통해 수행되며 파이프라인을 사용해 성능을 향상시킬 수 있음
2~7번 게시물 요약 끝!!!
좀 더 자세한 내용과 예시를 보고 싶다면 컴퓨터구조 시리즈를 확인하세요!
