
컴퓨터구조 시리즈에 올린 8~14번 게시글을 요약한 내용입니다.
[Chapter 4] The Processor
4.1 Introduction
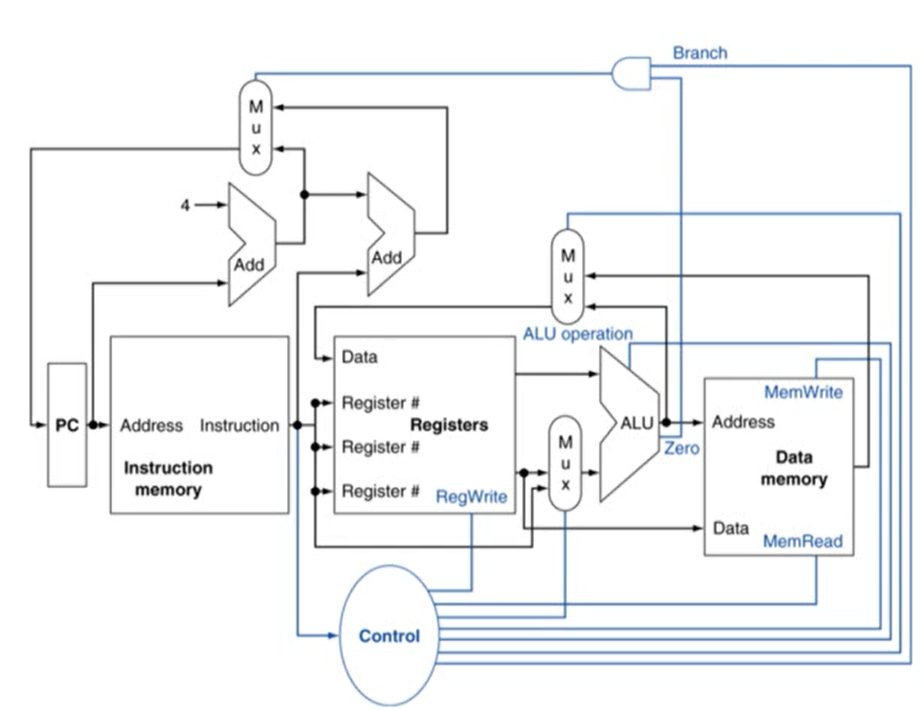
Instruction Execution
- fetch instruction: PC의 값을 참조해 instruction memory에 위치한 instruction을 읽어옴
- register number에 해당하는 register에 가서 register를 읽어옴
- ALU에서 산술 계산, load/store에서 메모리 주소 계산, branch에서 target address 계산
- load/store 명령어만 data memory에 접근
- data memory: instruction이 사용하는 data가 저장되어 있는 메모리
- PC에는 target address 또는 PC+4 값이 저장됨
4.4 A Simple Implementation Scheme
1. ALU(Arithmetic Logical Unit) Control
- load/store, branch, R-type(add, subtract, AND, OR) 연산시 사용
- opcode로부터 2bit ALUOp를 만들 수 있음
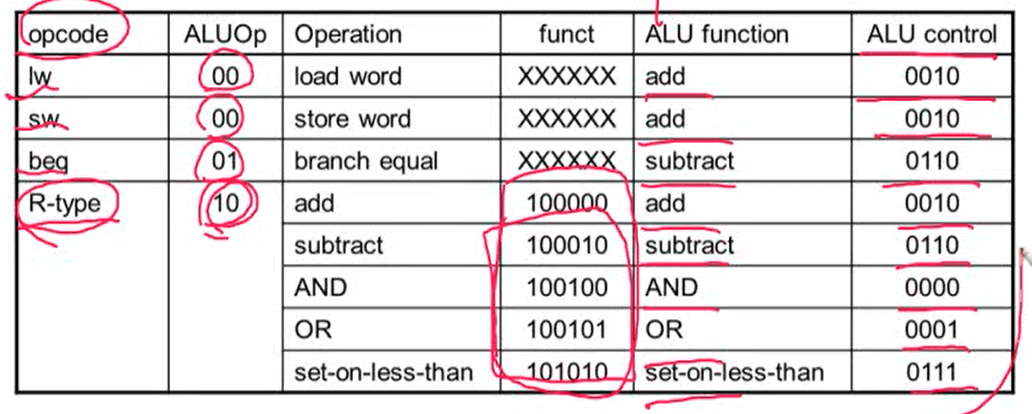
- 이런 테이블이 있는 경우, k-map을 사용해서 combination logic을 만들 수 있음
2. The Main Control Unit
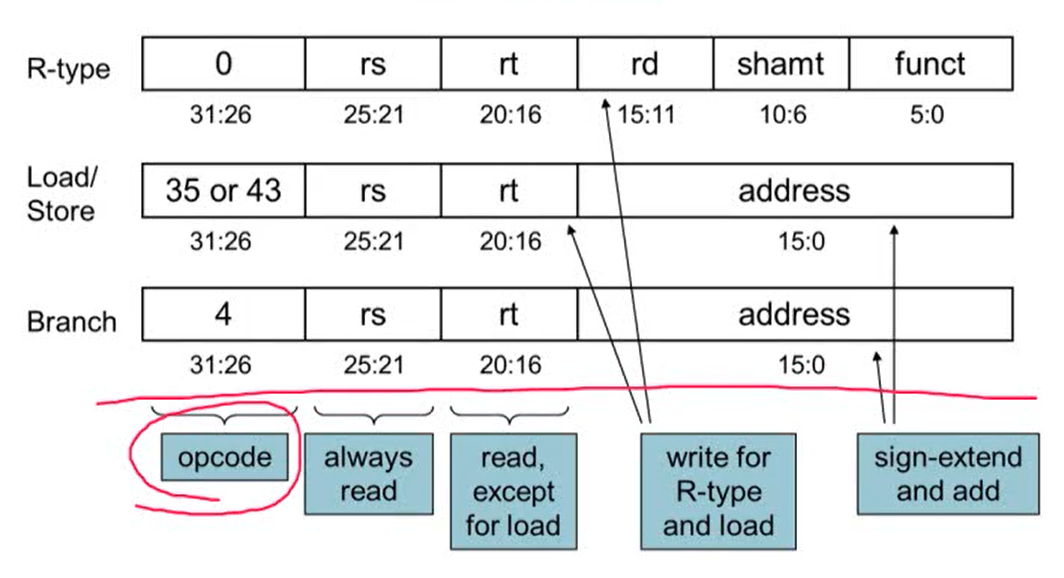
- instruction에 의해 control signal이 만들어짐
Datapath of Control
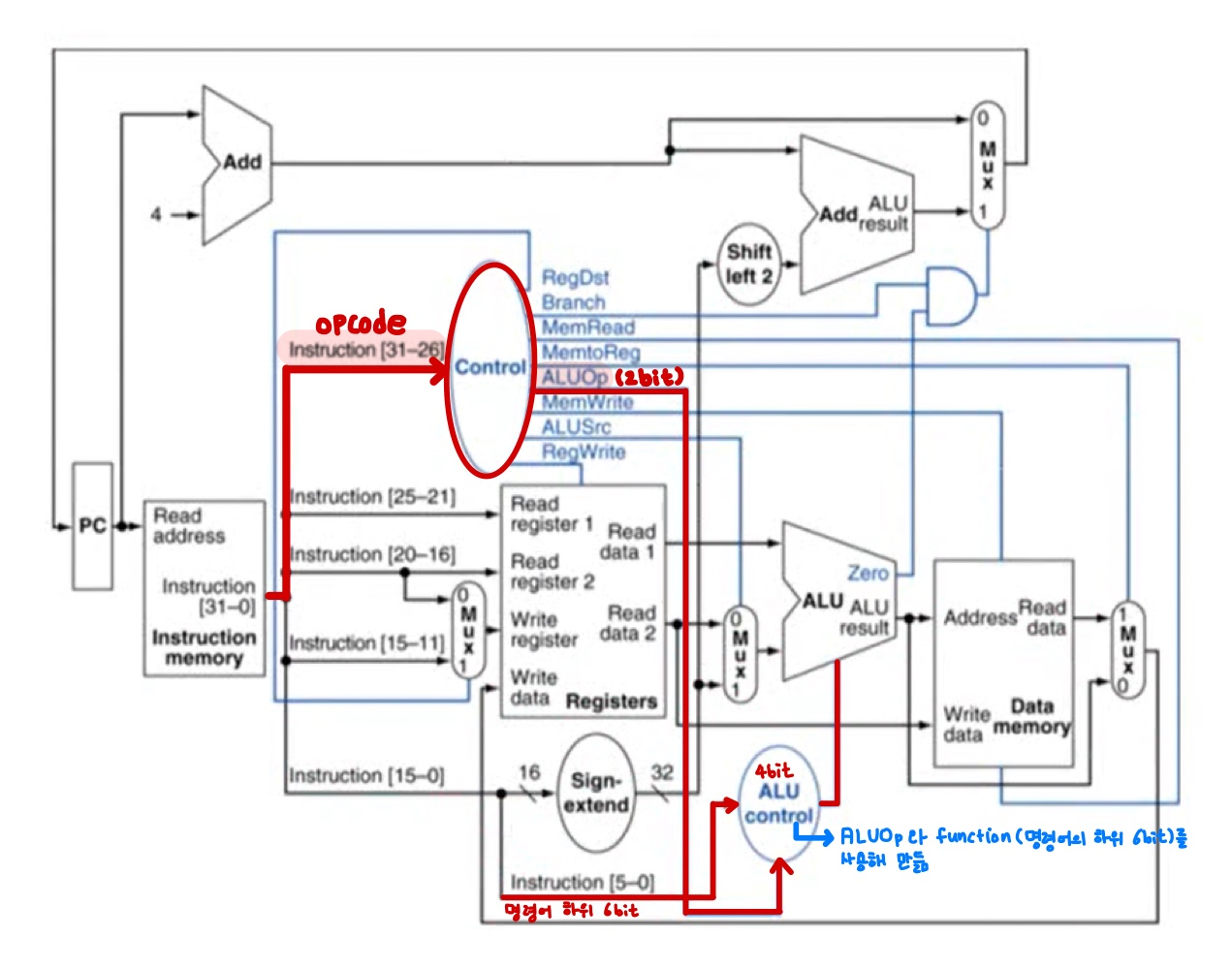
3. Performance Issues
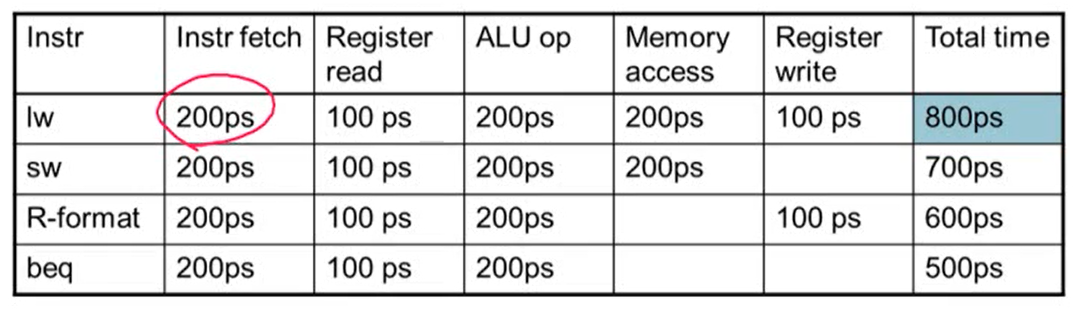
- 회로에서 가장 오래된 delay가 clock period를 결정
- MIPS 구현에서 가장 오래 걸리는 delay는 load instruction
- 이유: Instruction memory -> register file -> ALU -> data memory -> register file. 총 5단계가 필요하기 때문
- 각각의 명령어에 따라 다른 clock period를 사용하면 어떨까?
- 현실 회로에서는 불가능
- (design principle 중) 가장 많이 사용하는 것을 빠르게 만들어주어야 하지만 clock은 가장 느린 것에 맞추기 때문에 이 규칙에 위배됨 => 성능을 향상시키기 위해 pipline을 사용
4.5 An Overview of Pipelining
Pipeline
- overlapping excution: 병렬성을 통해 성능을 향상시킴
1. MIPS Pipeline
- 5단계로 구성
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
2. Pipline Performance
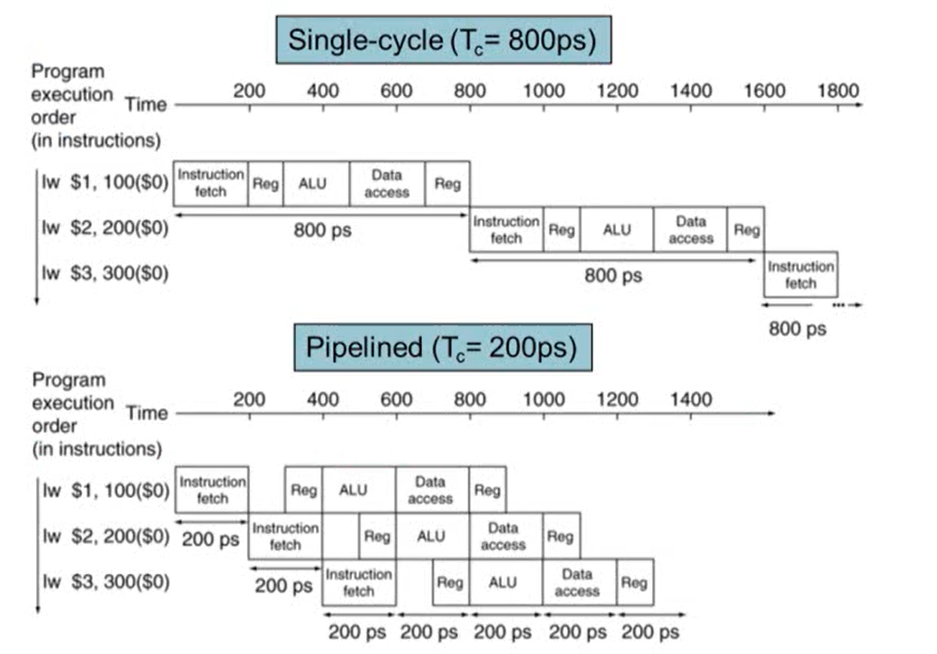
- Single-cycle의 경우 각 step의 시간을 모두 더한 시간 중 가장 긴 시간에 clock period가 맞춰짐
- 파이프라인은 각각의 step 중 가장 긴 시간에 clock period가 맞춰짐
Pipeline Speedup
- pipeline은 throughput이 증가하기 때문에 속도가 빨라짐. 즉 pipline을 사용하는 경우 성능 향상은 throughput 때문에 발생
3. Hazards
- Hazard: 다음 cycle에 다음 명령어를 시작하지 못하는 현상
- 매 cycle에 새로운 명령어를 수행해야하는데 그렇지 못한 상황을 의미
- Structure hazard
- 어떤 명령어를 실행하기 위해 하드웨어 resource가 필요한데 이미 하드웨어 resource가 사용되고 있어 해당되는 명령어를 실행하지 못하는 경우 발생
- Data hazard
- 어떤 명령어를 실행할 때 명령어에 필요한 데이터가 이전 명령어로부터 나오는데 이전 명령어의 실행이 종료될 때까지 기다려야할 경우 발생
- Control hazard
- 다음 사이클에 실행할 명령어가 이전 명령어의 결과에 의존하는 경우. 즉 control에 의존하는 경우 발생
4. Structure hazard
- 원인: resource 사용의 충돌에 의해 발생
- 해결방법: resource 추가
- 예시: MIPS pipeline에서 메모리가 하나라고 가정
- load/store의 경우 data를 가져오기 위해 메모리에 접근
- instruction fetch의 경우 명령어를 가져오기 위해 메모리에 접근
- load/store 명령어가 data를 가져오기 위해 메모리에 접근하는 동안에는 instruction fetch는 메모리에 접근할 수 없음. 하나의 메모리에 두 개가 동시에 access할 수 없음
- instruction fetch의 경우 load/store가 종료될 때까지 기다려야 함
- bubble이 발생
- stall: 기다려야하는 상황, bubble: 아무것도 하지 않는 상황
- 따라서 instruction fetch 앞의 명령어가 load/store 명령어인 경우 structure hazard 발생
- 해결 방법: instruction 메모리와 data 메모리를 분리
5. Data hazard
- 원인: 명령어가 이전 명령어의 결과에 의존하는 경우 발생 (data dependency에 의해 발생)
- data dependency 종류: Read After Read, Write After Write, Read After Write, Write After Read
- Read After Write의 경우 data hazard 발생
- single cycle processor에서는 발생하지 않음
- 예시
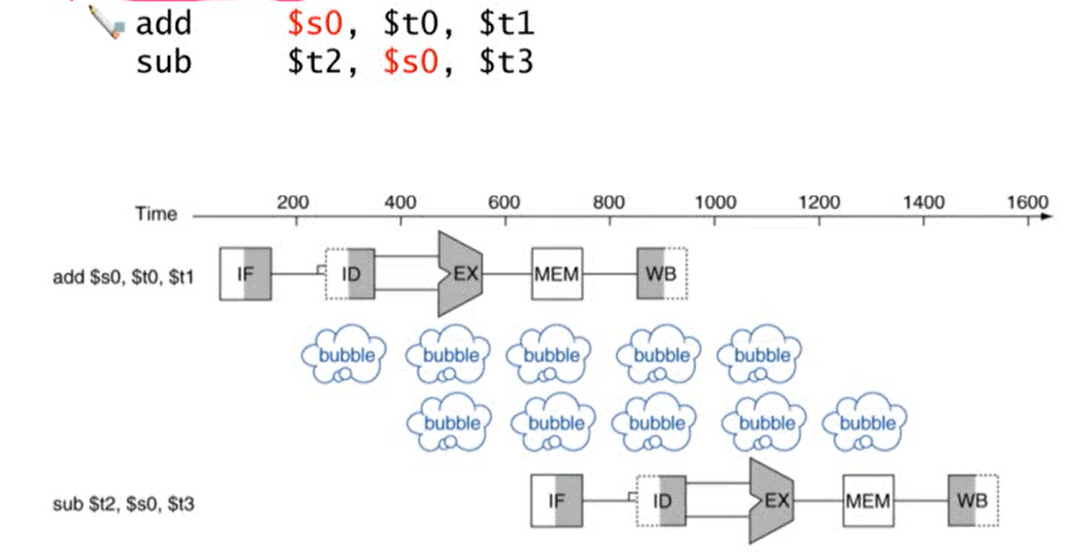
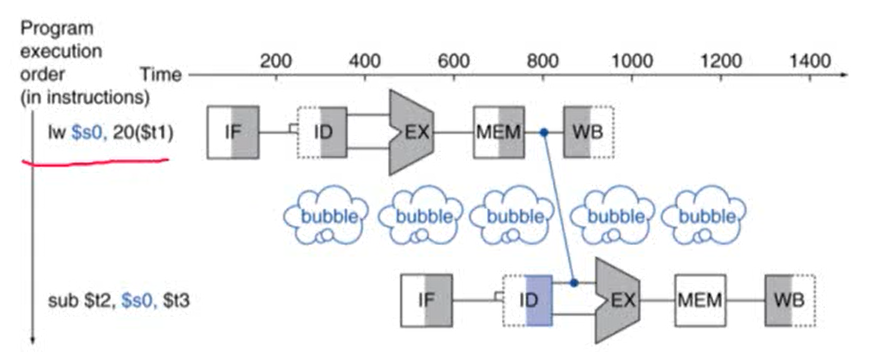
- 두 번째 명령어의 $s0는 앞의 명령어인 add의 결과에 의존
- add 명령어의 WB와 sub 명령어의 ID는 하나의 stage로 구성
- 두 cycle stall이 발생
- 해결 방법: Forwarding (Bypassing)
- 어떤 데이터의 값이 계산이 되면 그 결과를 바로 사용하는 것
- 레지스터에 값이 쓰여질 때까지 기다리지 않음
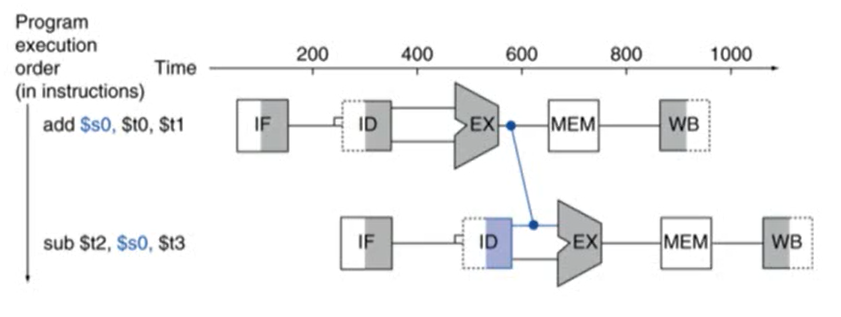
- 두 번째 명령어에서 $s0의 값은 ID stage에서 읽어오는데 이 때 레지스터에서 값을 읽어오는 것이 아니라 앞의 명령어에서 계산된 결과값을 바로 사용해 연산을 수행
- Forwarding을 사용하면 hazard가 발생하지 않음
Load-Use Data Hazard
- Forwarding으로도 해결 불가능한 data hazard
- 해결방법: Code Scheduling
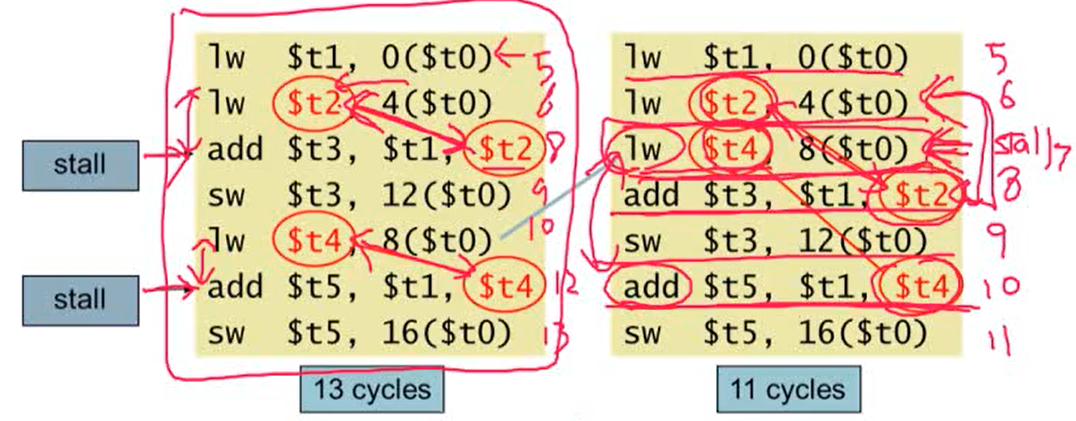
- load-use data hazard를 해결하기 위해 혹은 명령어를 빠르게 실행시키기 위해 명령어의 순서를 바꿔주는 것
6. Control Hazard
-
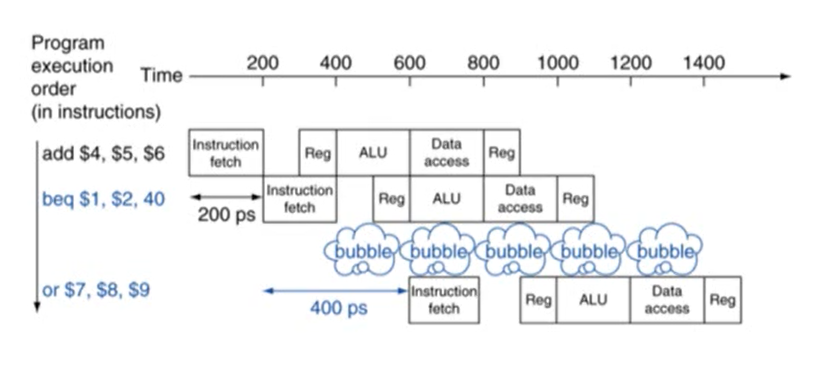
원인: branch 명령어에 의해 발생하는 hazard
- branch는 프로그램의 flow를 결정. 다음에 실행할 명령어는 branch의 결과에 의해 결정됨
- pipline에서 다음에 실행할 명령어를 정확히 fetch할 수 없음. branch의 ID stage에서 다음 명령어를 fetch해야하기 때문
-
MIPS pipeline에서는
- 레지스터를 비교하고 target address 계산하는 것을 pipeline에서 더 일찍 수행하도록 수정해야함
- 이 과정을 ID stage에서 할 수 있도록 하드웨어를 추가해줌
- 따라서 MIPS pipeline에서는 ID stage에서 branch의 결과를 알 수 있게됨
-
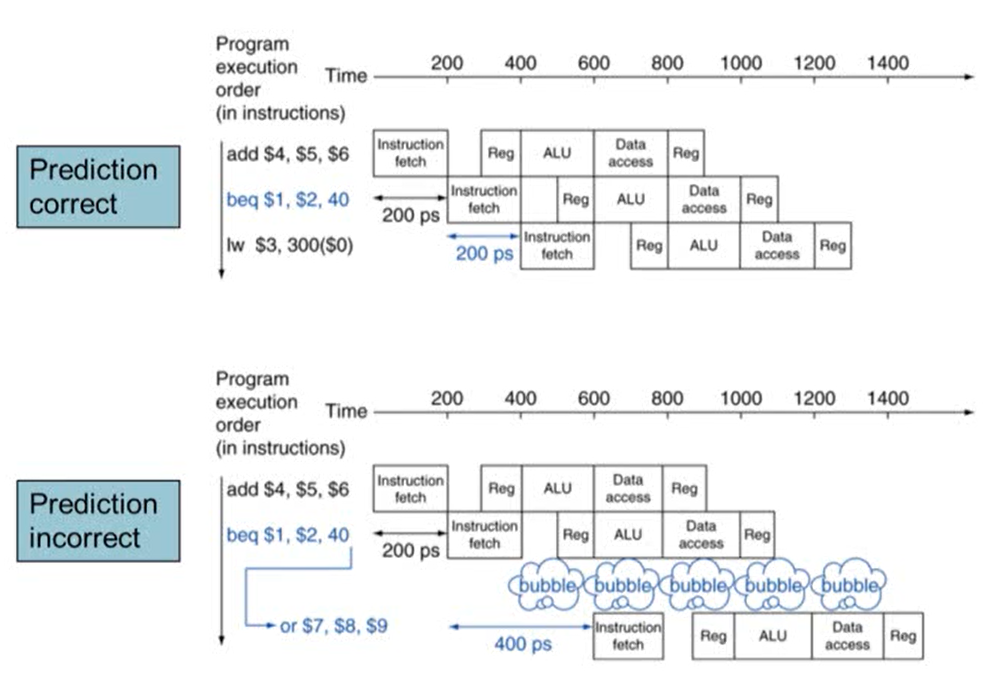
해결방법: Branch Prediction
- branch의 결과를 예측해 다음에 실행할 명령어를 미리 실행
- 최근 processor에는 pipline stage가 많음. 많을수록 성능 향상이 되기 때문. 하지만 longer pipline일수록 branch의 결과 늦게 알기 때문에 여러 stall이 발생
- stall을 줄이기 위해 branch의 결과를 예측. 결과 예측이 틀릴 경우 stall이 발생하지만, 맞을 경우 stall이 발생하지 않음
- Static branch prediction
- branch prediction의 결과가 고정되어 있음 (ex. if, loop: 항상 taken or not taken으로 예측)
- 정확도가 떨어질 수 있음
- Dynamic branch prediction
- 기존 branch의 결과를 활용. 최근 branch의 결과 history를 기록해 그 결과를 활용해서 branch의 결과를 prediction
- 잘못 예측했을 경우, 제대로 된 명령어를 fetch하고 history를 update
- 최신 processor의 경우 dynamic branch prediction을 사용
5. Pipeline 정리
- pipeline: instruction throughput를 증가시켜 성능을 향상시킴
- 여러 개의 명령어를 동시에 실행. 각각의 명령어의 실행시간은 같음
- Subject to hazards: Structure, data, control
- ISA는 pipline 구현의 복잡도에 영향을. ISA가 간단할수록 pipline 구현이 쉬워짐
4.7 Data Hazards: Forwarding vs Stalling
1. Detecting the Need to Forward
Data hazard가 발생하는 경우
- EX stage가 끝난 후에 forwarding를 통해 data hazard를 해결
- EX/MEM의 destination register number == ID/EX의 source register number
- EX/MEM의 destination register number == ID/EX의 target register number
- MEM stage가 끝난 후에 forwarding를 통해 data hazard를 해결
- MEM/WB의 destination register number == ID/EX의 source register number
- MEM/WB의 destination register number == ID/EX의 target register number
2. Double Data Hazard
- 두 번째 명령어의 $1값은 첫 번째 명령어에 따라 결정되고 세 번째 명령어의 $1은 두 번째 명령어에 따라 결정됨
- 두 구간에서 hazard가 발생
- 가장 최근의 값을 사용. 즉 첫 번째 명령어에서 세 번째 명령어로 forwarding이 발생하면 안되고 두 번째 명령어에서 세 번째 명령어로 forwarding이 발생해야 함
- EX stage에서만 forwarding이 발생하도록 하는 것. 이렇게 하기 위해서는 EX stage에서는 hazard가 발생하지 않아야만 MEM의 hazard를 해결하기 위해 forwarding을 수행
3. Load-Use Data Hazard
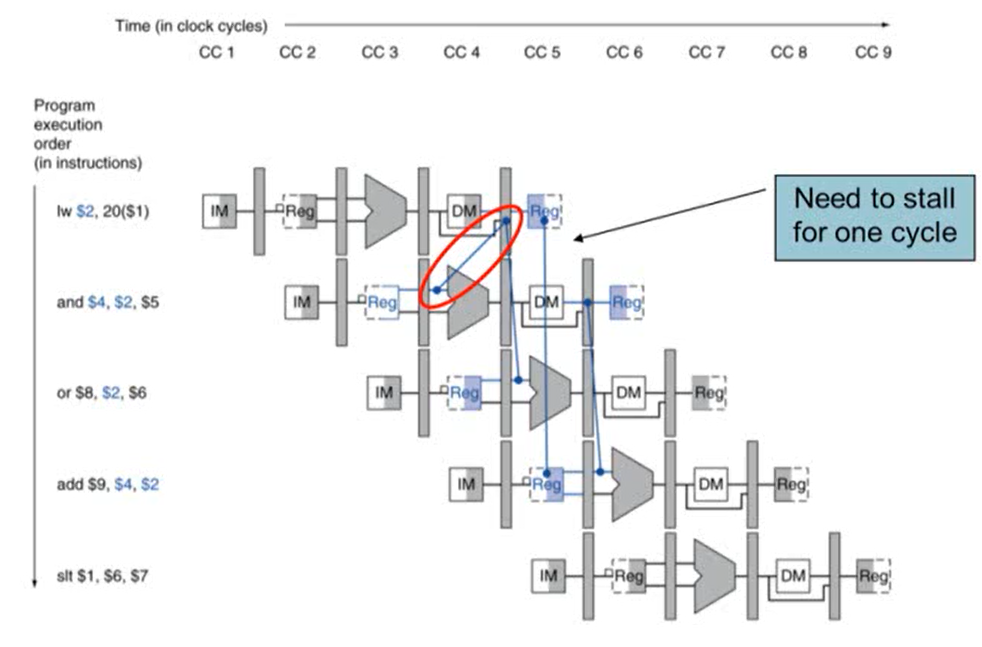
- 첫 번째 cycle의 MEM stage가 끝난 후에야 $s2를 사용할 수 있는데, 두 번째 cycle에서 EX stage에서 $s2 변수가 필요하기 때문에 1 cycle stall이 발생
- ID stage에서 check
- ID stage의 ALU operand register number는 IF/ID.RegisterRs, IF/ID.RegisterRt에 의해 주어짐
- Load-Use data hazard가 발생하는 경우
- ID/IE.MemRead가 true이고
- ID/IE의 target register와 IF/ID의 source register가 같거나
- ID/IE의 target register와 IF/ID의 target register가 같은 경우
- Load-Use data hazard가 발생하는 경우 bubble를 추가해 stall을 발생시킴
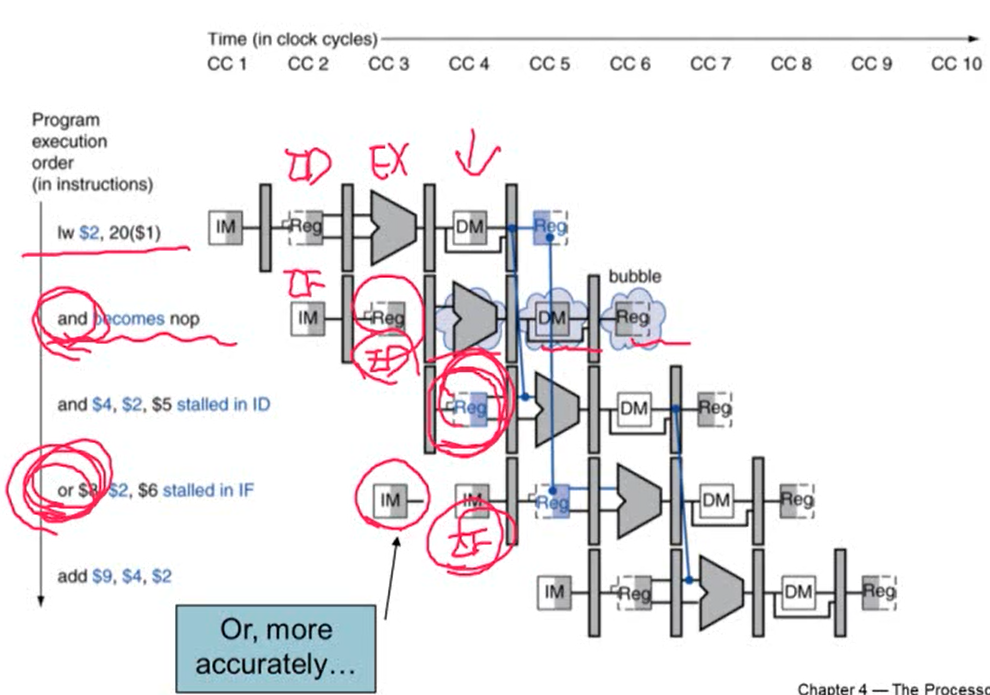
4. How to Stall the Pipeline
- ID/EX register에 0 값을 추가. EX, MEM, WB가 모두 no-operation하게 됨
- PC 값과 IF/ID register 값이 update되면 안됨
- 해당 instruction의 decode를 다시 진행
- 다음 instruction fetch를 다시 진행
- 1 cycle stall 동안 lw 명령어를 위해 MEM stage에서 데이터를 읽는 것은 허용해야 함. 허용해줘야 다음 EX stage로 진행될 수 있기 때문
1. Stall/Bubble in the Pipeline
2. Stalls and Performance
- stall은 기본적으로 성능을 저하시키지만 정확한 결과를 얻기 위해서는 반드시 필요
- 따라서 hazard와 stall을 없애기 위해 코드의 순서를 바꾸는 과정이 필요하기 때문에 컴파일러는 pipeline structure를 정확히 알고 있어야 함
4.8 Control Hazards
1. Branch Harzard
- branch의 결과가 MEM stage에서 나오면 파이프라인에 의해 실행된 다음 명령어들은 잘못된 명령어를 실행한 것. MEM stage 후에 제대로 된 명령어를 수행하게 됨
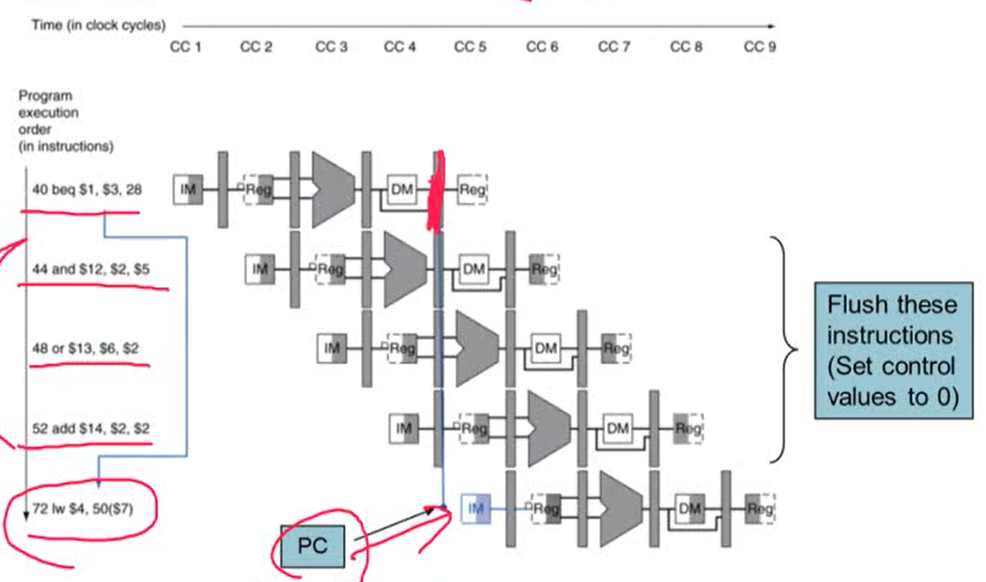
- 잘못된 명령어를 없애기 위해서는 이 명령어들을 flush 해줌
- flush: control values의 값을 0으로 만들어주는 것을 의미
Reducing Branch Delay
- 하드웨어를 추가해 branch의 결과를 ID stage에서 알 수 있도록 함
- Target address adder와 Register comparator를 ID stage에 추가하면 branch의 결과를 ID stage에서 알 수 있음
2. Data Hazards for Branches
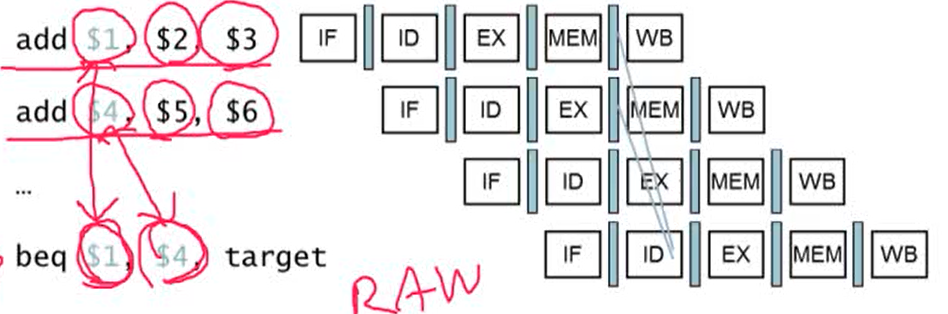
- comparison register가 두 번째 혹은 3번째 앞의 ALU instruction의 destination이라면 forwarding를 통해 data hazard를 해결 가능
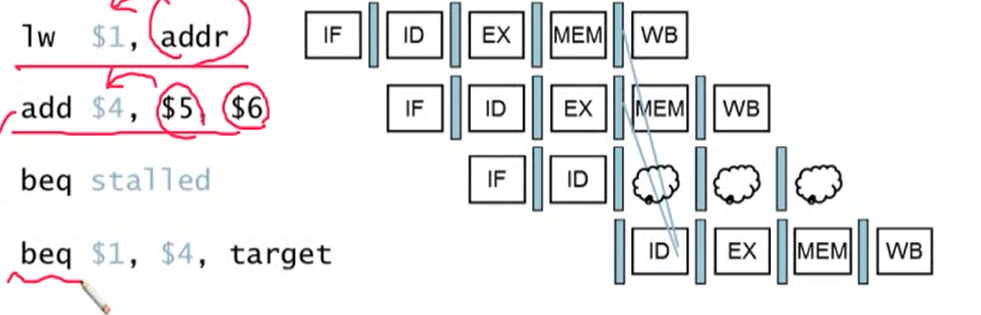
- comparison register가 바로 전의 ALU instruction의 destination이거나 두 번째 앞의 load instruction의 destination인 경우 1 stall cycel이 필요
- add 명령어의 결과는 EX stage가 끝난 후에, load 명령어의 결과를 MEM stage가 끝난 후에 나옴
- branch 명령어의 경우 ID stage에서 comparison 결과를 알 수 있음. ID stage에서 branch 결과와 branch target address가 계산이 됨
- lw, add의 결과를 branch의 ID stage에서는 사용할 수 없기 때문에 1 cycle stall이 발생
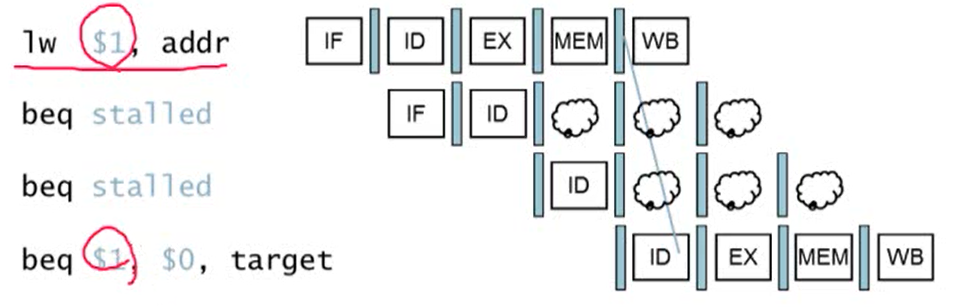
- comparison register가 바로 앞의 load instruction의 destination인 경우 2 cycle stall이 발생
3. Dynamic Branch Prediction
- branch prediction buffer(branch history table): 기존의 branch 결과를 활용하기 때문에 이전의 branch 결과를 저장해주는 buffer가 필요
- index는 최근의 branch instruction addresses로 구성. 값으로 branch의 결과(taken/not taken)를 저장
- branch 명령어를 실행하면
- table를 확인한 후 이번 결과를 예측
- 예측한 결과에 따라 해당하는 명령어를 fetch해서 실행
- prediction 결과가 맞으면 계속 실행, 틀리면 pipeline을 flush하고 제대로 된 명령어를 실행
4.9 Exceptions
Exceptions and Interrupts
- exception: CPU 내부에서 발생하는 예상하지 못한 event (ex. overflow, systemcall ... )
- interrupt: 외부 장치에서 발생하는 예상하지 못한 event
- trap(software interrupt): 어떤 명령어를 사용할 경우 명령어가 interrupt를 발생시킴
- interrupt는 일반적으로 외부 장치에서 발생하지만 소프트웨어에서 발생하는 interrupt를 trap이라고 함
- syscall를 구현하는데 사용
- exception과 interrupt를 처리할 때 성능이 떨어질 수 밖에 없음
1. Handing Exceptions
- MIPS에서는 CP0(System Control Coprocessor)에서 exception를 관리
- exception이 발생하면
- 현재의 PC를 EPC(Exception Program Counter)에 저장
- Cause register에 exception 발생 원인을 저장
- 미리 지정한 메모리 주소(exception를 처리하기 위한 handler 주소가 저장되어 있음)로 jump
- exception 종류 상관없이 같은 메모리 주소로 jump
- Vectored Interrupts: handler 주소가 원인에 따라 다르게 정해짐
- 장점: jump된 메모리 주소에 따라 exception의 종류를 알 수 있음
- jump된 메모리 주소에서 바로 interrupt를 처리하는 경우와 메모리 주소에서 실제 handler로 한 번 더 이동한 후 interrupt를 처리하는 경우가 있음
Handler Actions
- 발생 원인을 파악하고 해당되는 handler로 jump
- cause register를 읽어서 왜 interrupt가 발생했는지 파악해야 함
- interrupt를 처리한 후 명령어를 다시 시작할 수 있으면 EPC를 사용해 원래 명령어로 돌아감
- 명령어를 다시 시작할 수 없는 경우 프로그램을 종료하고 에러 메시지를 저장
2. Exceptions in a Pipeline
Exception Properties
- Restartable exception
- pipeline를 flush하고 원래의 명령어로 돌아감
- EPC에 저장된 PC 값을 활용해서 다시 복원
- EPC에는 PC + 4의 값이 저장되어 있기 때문에 다시 PC에 값을 저장할 때는 4를 빼준 후 저장해줘야 함
3. Multiple Exceptions
- pipeline의 경우 한 번에 여러 명령어가 실행되기 때문에 exception도 여러 개가 발생할 수 있음
- 처리해주는 가장 간단한 방법은 pipeline의 가장 끝부분에 많이 실행된 명령어대로 처리하는 것
- 그 명령어 이전의 명령어는 모두 flush
- precise exception: 어떤 명령어를 먼저 처리할 것인지 규정되어 있는 것
- pipeline이 복잡한 경우
- 한 cycle마다 여러 명령어를 실행
- 실행 결과가 명령어 실행 순서와 바뀌는 경우 precise exception를 처리하기 힘듦
Imprecise Exception
- pipeline를 멈추고 현재 상태를 저장
- handler가 어떤 명령어에서 exception이 발생했는지 파악하고 어떤 명령어를 complete하고 flush할지 결정
- 하드웨어는 단순하지만 handler software는 복잡함
- 최신 cpu에서는 제공되지 않음
4.10 Parallelism via Instrcutions
1. ILP
- Instruction-Level Parallelism: 여러 개의 명령어를 병렬적으로 실행하는 것
- ILP를 증가하기 위해서는
- pipeline stage를 증가시키면 됨
- 각각의 stage마다 하는 일이 적어지면 clock cycle이 짧아져 성능이 향상됨
- 여러 개의 명령어를 동시에 실행 (issue: instruction fetch 과정)
- 여러 개의 파이프라인을 만듦
- 각 cycle마다 실행하는 명령어가 여러 개가 될 수 있음
- pipeline stage를 증가시키면 됨
2. Multiple Issue
1. Static multiple issue
- 어떤 명령어가 실행될 때 이 명령어가 어떤 cycle에서 실행될지 미리 결정되어 있음
- 컴파일러가 어떤 명령어를 어떤 사이클에서 실행시킬지 결정
- issue slots: 컴파일러가 한 cycle에 실행될 명령어들을 묶은 것
- 컴파일러가 hazard를 감지하고 회피함
- 컴파일러가 명령어의 그룹을 issue packet으로 만듦
- issue packet이 매우 긴 명령어처럼 보이게 됨. 이런 아키텍쳐를 Very Long Instruction Word(VLIW) 라고 부름
- Scheduling Static multiple issue
- 컴파일러가 hazard를 감지하고 없애야 함
- 명령어를 reorder하고 dependency가 없는 packet를 만듦
- packet 사이에는 dependency가 생길 수 있는데 이럴 경우 nop operation를 두어 hazard를 해결
2. Dynamic multiple issue
- CPU가 동적으로 어떤 명령어를 실행할 cycle를 결정
- CPU가 runtime hazard를 감지하고 해결
- Superscalar processor: dynamic multiple issue를 지원하는 프로세서
- 필요에 따라 컴파일러가 도움을 줄 수 있음
3. Speculation
- 예측해서 미리 실행하는 것
- 명령어들을 가능한 빨리 시작시킴
- 예측한 것이 맞으면 그대로 실행. 틀리면 roll-back를 하고 제대로 된 명령어를 실행
- static, dynamic multiple issue에서 많이 사용하는 기법
- ex) branch prediction, load 명령어(같은 값을 load하는 경우가 많기 때문에 load 명령어의 결과를 기다리지 않고 기존의 값을 활용)
- Static speculation: ISA의 도움을 받아 exception 처리를 늦춤
- Dynamic speculation: 명령어가 끝날 때까지 exception를 buffering 해줌
3. Hazard in the Dual-Issue MIPS
1. EX data hazard
-
single issue인 경우 forwarding를 사용해서 해결
-
ALU의 결과를 같은 packet에서의 load/store 명령어에서 사용 불가
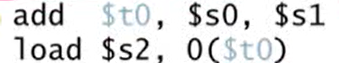
- 두 명령어가 하나의 packet으로 묶이게 되면 add 결과를 두 번째 명령어에서 load할 수 없음
- 제대로 된 결과를 얻기 위해서는 두 명령어를 다른 packet에 놓아야 함. 이럴 경우 stall이 발생
-
Dual-Issue의 경우 스케쥴링을 적극적으로 해야 hazard가 해결됨
2. Scheduling Example

4. Dynamic Pipline Scheduling
- dynamic multiple issue를 사용
- CPU가 stall를 방지하기 위해 out of order을 수행
- in order: 먼저 실행한 명령어가 먼저 끝나야 함. 일반적인 파이프라인 프로세스레에서 사용
- out of order: superscalar processor에서 지원. 먼저 명령어가 실행됐더라도 먼저 끝나지 않을 수 있음
- 단, 데이터가 쓰여지는 commit 단계는 in order
- Example
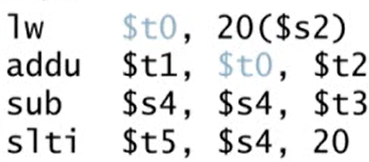
- addu가 lw 명령어가 끝나기를 기다리는 동안 sub 명령어를 실행할 수 있음
- Dynamic Scheduled CPU
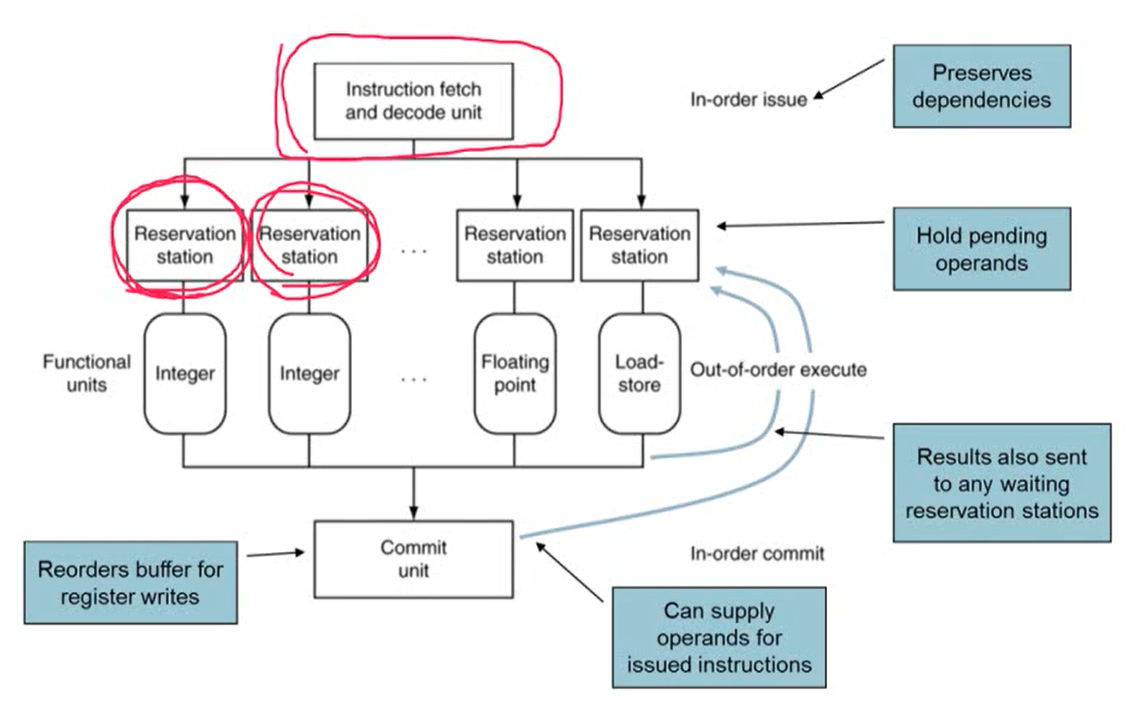
- issue: Instruction fetch. in-order로 이루어짐
- Reservation station: 명령어를 수행하기 위한 하드웨어 resource를 할당받음
- functional unit에서 명령어가 실행되고 결과는 out-of-order
- Commit: 실행된 결과를 실제 레지스터에 반영 (in-order)
- 사용하는 이유
- 컴파일러는 모든 stall를 예측하기 힘듦. 예를 들어 cache misses 같은 경우 runtime에만 알 수 있음
- branch 같은 경우 이런 schedule를 제대로 하기 어려움. branch의 결과도 동적으로 결정이 되기 때문에 컴파일러가 branch를 모두 고려해 스케쥴링하기 어려움
- ISA를 구현할 때 다른 구현은 다른 latency와 다른 hazard를 가지고 있음. 따라서 컴파일러가 모든 프로세서의 내부 구조를 완벽하게 알고 있어야 하기 때문에 이것에 맞춰 코드를 generation하기 어려움
5. Register Renaming
- superscalar 프로세스의 가장 큰 특징 중 하나
- 어떤 명령어가 어떤 레지스터를 사용하는 경우 요청한 레지스터가 아닌 다른 레지스터가 사용할 수 있는 상태라면 사용 가능한 레지스터를 사용하는 것
- operand가 register file과 reorder buffer에서 available한 경우
- reservation station으로 복사
- operand가 not available한 경우
- function unit에 의해 reservation station이 제공되고 register update는 필요하지 않음
- 실제 코드에 사용한 레지스터와 실행될 때 사용한 레지스터가 바뀔 수 있다는 것을 의미
4.15 Concluding Remarks
- ISA는 프로세스의 datapath와 control design에 영향을 주고 datapath와 control design도 ISA design에 영향을 줌
- pipeline은 throughput를 증가시켜 성능을 향상시킴
- Hazard: structural,data, control
- Multiple issue and dynamic scheduling (ILP)
- dependency는 parallelism를 제한
[Chapter 5] Exploiting Memory Hierarchy
5.2 Memory Technologies
The "Memory Wall"
- 프로세서의 성능 향상 비율에 비해 DRAM의 성능 향상 비율은 느리게 증가. 이로 인해 성능 향상이 저하되는 현상
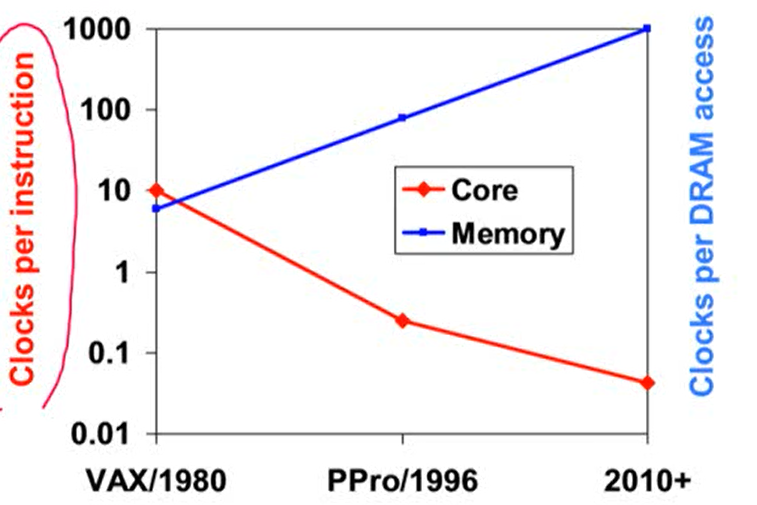
- Good memory hierarchy는 전체적인 성능에 아주 중요한 영향을 줌
5.1 Introduction
1. Principle of Locality (지역성의 원리)
- 프로그램에서 특정 시간에 메모리 주소에서 아주 적은 부분을 access하는 것
- 어떤 시간에 프로그램 전체 중에서 특정 부분만 access하는 것
- access하는 그 공간을 계속해서 access한다는 의미
1. Locality 종류
- Temporal locality
- 최근에 access한 item를 가까운 시간 내에 다시 access할 확률이 높다 (시간적인 의미)
- ex) loop 안의 명령어, induction variables
- Spatial locality
- 최근에 access한 item의 근처에 있는 다른 item을 access할 확률이 높다 (공간적인 의미)
- sequential instruction access
2. Taking Advantage of Locality
- memory hierarchy 사용해서 자주 사용하는 정보를 CPU와 가까운 곳으로 복사함
- 모든 중요한 정보는 disk에 존재. 자주 사용하는 정보는 disk에서 DRAM(main memory)으로 올림. DRAM에서 자주 사용하는 정보를 SRAM의 작은 memory 부분(cache)에 올림
- 캐시는 CPU와 통합되어 있음
- 모든 중요한 정보는 disk에 존재. 자주 사용하는 정보는 disk에서 DRAM(main memory)으로 올림. DRAM에서 자주 사용하는 정보를 SRAM의 작은 memory 부분(cache)에 올림
2. Memory Hierarchy Levels
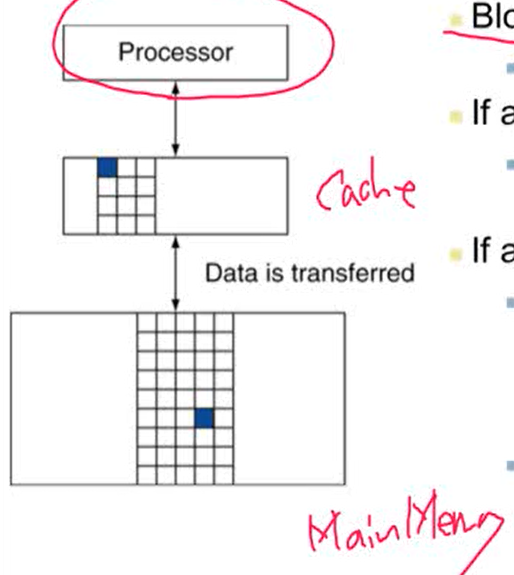
- Block(line): copy의 단위. 한 block은 여러 개의 word로 구성되어 있음
- Hit: CPU가 어떤 데이터에 접근하고자 할 때 접근할 데이터가 upper level에 존재하는 경우
- hit ratio: hits/accesses
- Miss: CPU가 어떤 데이터에 접근하고자 할 때 접근할 데이터가 upper level에 없는 경우, 즉 lower level에서 데이터를 가져와야하는 경우
- miss penalty: lower level에서 데이터를 가져오는데 걸리는 시간
- miss ratio = missess/accesses = 1 - hit ratio
- miss가 발생할 경우 upper level로 데이터를 전달해줌
Characteristics of the Memory Hierarchy
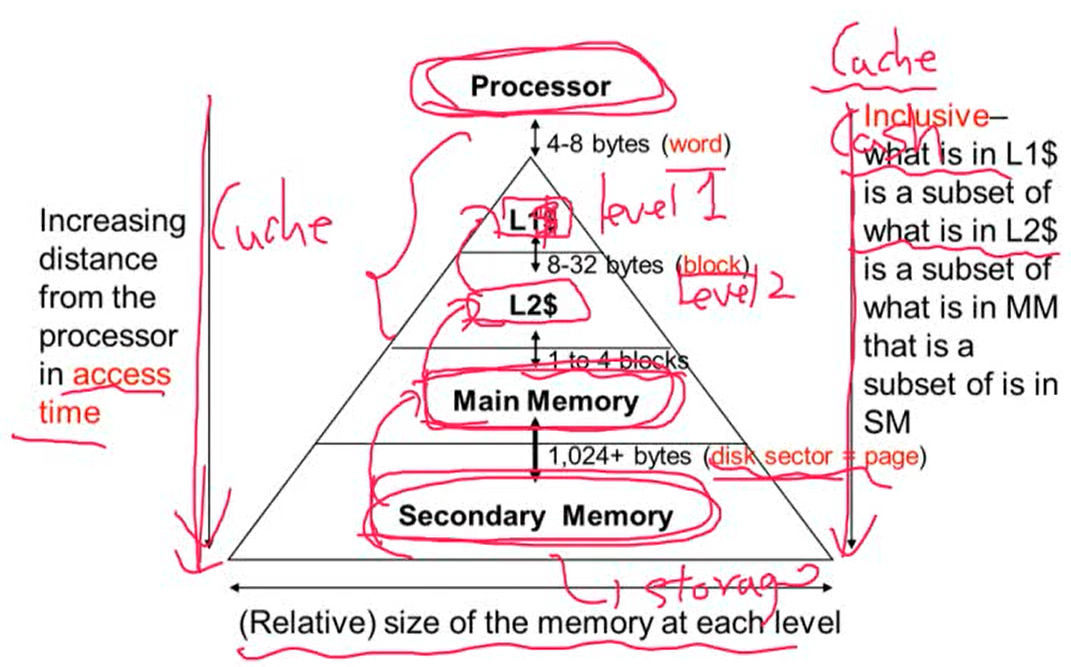
- secondart memory: storage
- L1$ + L2$: cache. cache를 간단하게 표한하고 싶을 때 $를 사용
- 프로세서에서 멀수록 access time은 증가. 밑의 level로 올수록 메모리의 크기는 커짐
- L1$ 에 있는 정보는 L2$에 있는 정보의 subset. inclusive의 특징을 가짐
3. DRAM Performace Factors
1. Row buffer
- row 단위로 데이터를 access할 때 row별로 buffer를 사용하기 때문에 여러 word를 한번에 read하거나 refresh하는 것이 가능
2. Synchronous DRAM (SDRAM)
- DRAM이 clock에 동기화 됨
- burst mode인 경우 연속된 access는 매번 주소를 줄 필요없이 바로 access 가능
5.3 The Basics of Caches
1. Cache Memory

- Main memory는 6bit로 구성
- main memory의 하위 두 비트는 word를 정의하는데 사용됨. 중간의 두 비트는 cache의 index 정보로 사용. 상위 두 비트는 cache의 tag 값으로 들어감
- cache는 4 blocks으로, 메인 메모리는 16 blocks으로 구성. 메인 메모리의 4 blocks이 cache의 하나의 line에 매핑됨
- block address를 cache의 block의 수로 나눠서 modulo operation(나머지 연산)을 취하면 cache의 index 값이 나옴
Is it there?
- access하고자하는 명령어 혹은 data의 주소가 cache에 들어오면 주소 값 index가 같은 라인을 찾은 후 cache의 tag 값을 비교해 같으면 해당 tag의 data를 사용
- tag의 값과 같은 경우 hit, 다른 경우 miss 발생
Direct Mapped Cache
- cache의 line이 하나의 block만 가지는 경우
- Direct mapped: 메모리 주소가 cache의 어느 line에 매핑되는지는 메모리 주소에 의해 결정됨
- (block address) % (number of blocks in cache)에 매핑
- block의 수는 2의 제곱으로 구성
2. Tags and Valid Bits
- cache 안에 들어있는 것이 어느 메모리에 매핑된 block인지 알아야 할 때 tag를 사용
- high order bit를 사용
- data와 block addressd의 tag 값을 cache에 저장
- tag에 해당되는 값이 없으면 valid bit은 0, 데이터가 있으면 1
- valide bit이 1이면 데이터가 유효하다는 것
- 처음 컴퓨터를 키면 모든 cache에 있는 validate bit은 0(N)으로 설정됨
- 메인 메모리의 값을 cache로 가져오면 1이 됨
Cache Example
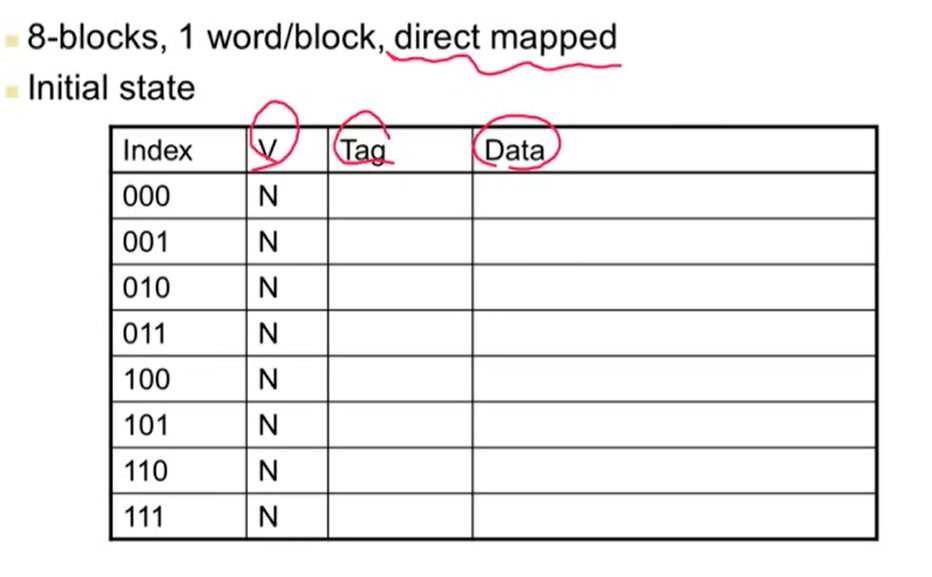
- word addr: block address
- 어느 line에 해당되는지 알기 위해 binary addr를 8로 나눈 나머지 연산을 수행
- 연산을 수행하면 하위 3bit의 값이 그대로 나옴
- block이 8개이기 때문에 하위 3bit가 그대로 나옴. block이 4개면 하위 2bit, 16개이면 하위 4bit이 나옴
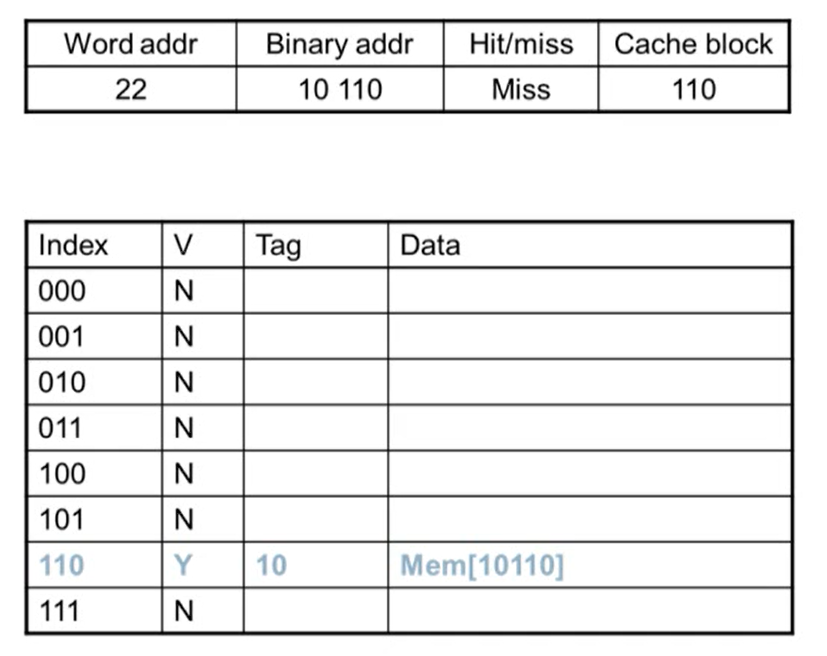
- Miss: Valid bit가 N인 경우 무조건 miss가 발생
- miss가 발생하면 메인 메모리에서 데이터를 읽어와 cache에 copy
- copy되면 valid bit이 1이 되고 tag는 cache block 값을 제외한 상위 bit가 저장됨
- 메모리 주소에 있는 데이터를 data에 저장
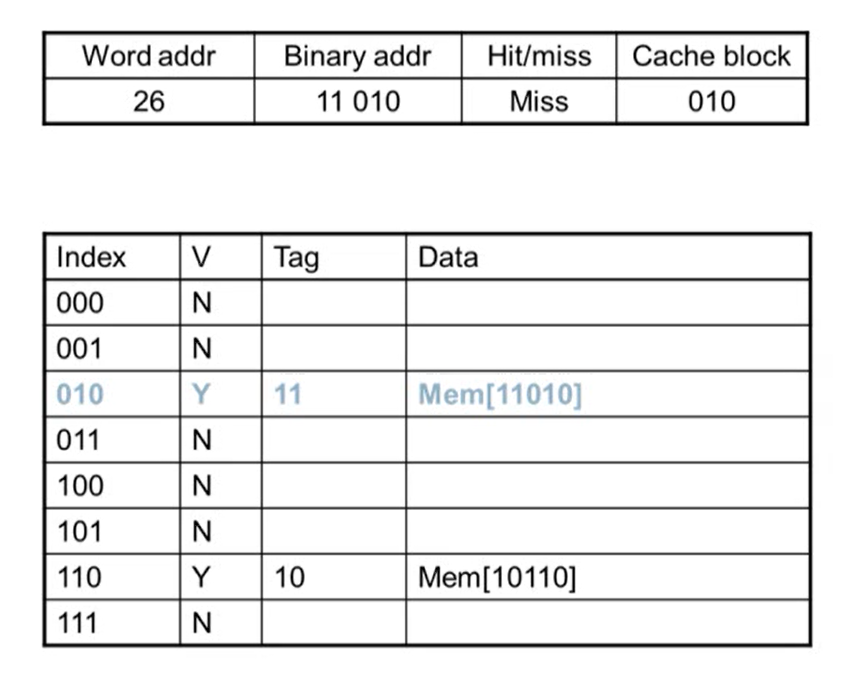
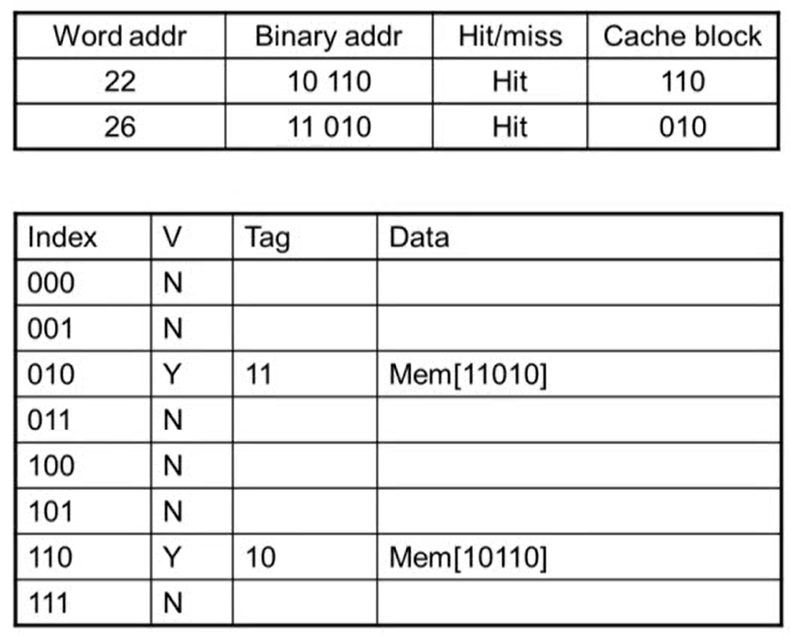
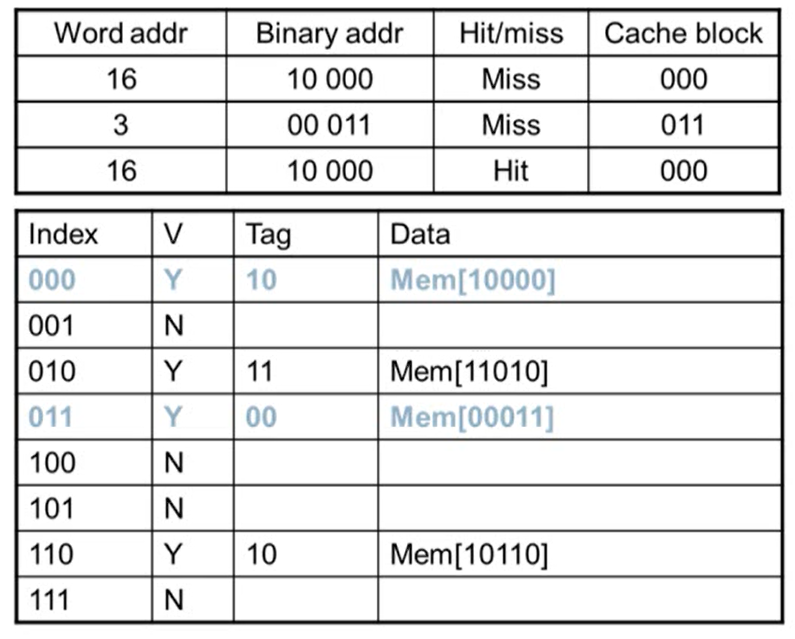
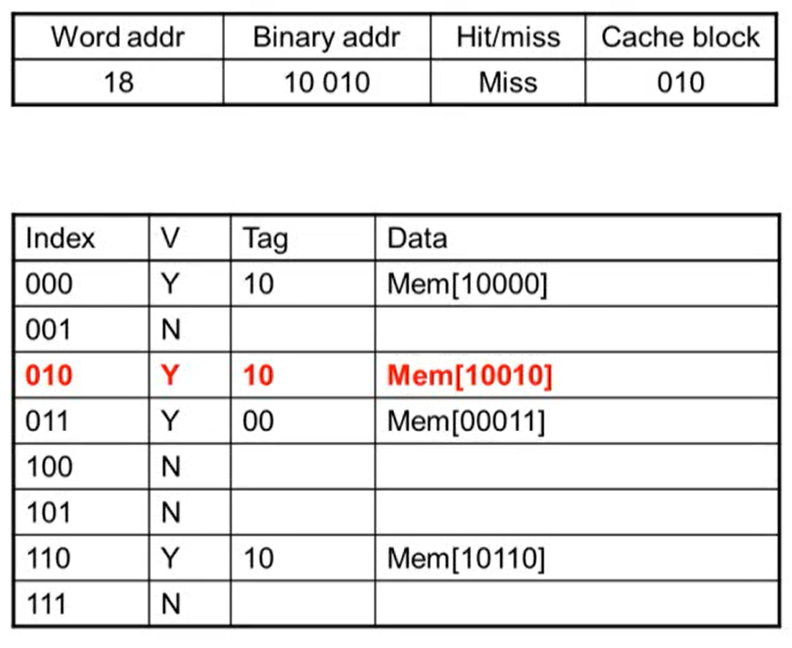
- index의 값은 같지만 tag 값이 같지 않아 valid bit이 Y임에도 불가하고 miss가 발생
- access한 후 tag, data 값이 변경됨
3. Cache Misses
- hit이 발생한 경우 CPU는 그대로 진행
- miss가 발생하게 되면
- CPU의 pipeline은 멈추게 됨
- low-level에 가서 해당 명령어를 가지고 옴
- instruction cache miss인 경우 그 명령어의 fetch를 다시 시작하고, data cache miss인 경우 data access를 완료함
4. Write-Through vs Write-Back
1. Write-Through cache
- data-write가 hit인 경우 cache의 block를 update. 이럴 경우 cache의 내용과 메모리의 내용이 달라지게 되는데 이를 해결하는 방법이 Write-Through
- Write-Through: cache를 update할 때 memory도 함께 update하는 방식
- write through의 경우 write하는 속도가 느려짐
- 속도가 느려지는 문제를 해결하는 방법은 write buffer를 사용하는 것
- write buffer: cache에 아주 작은 buffer를 추가해 memory에 써야할 내용을 memory에 쓰지 않고 buffer에 쓴 후 buffer에서 다시 memory에 씀
- 이 때 CPU는 wirte buffer에 memory에 쓸 내용을 쓰면 바로 시작할 수 있음. 따라서 메인 메모리에 데이터를 쓸 때까지 기다리지 않아도 됨
- write buffer가 꽉 찬 경우 write buffer의 내용을 메모리에 쓴 후 없애주어야 함. write buffer의 내용을 하나 빼서 메모리에 쓸 때까지 CPU는 기다려야하는 상황이 발생
2. Write-Back cache
- cache만 update를 수행. 이럴 경우 cache의 data와 메인 메모리의 data가 달라지기 때문에 cache의 data와 메모리의 data가 같은지 다른지를 파악해야 함
- 파악하기 위해 dirty bit를 추가. cache의 data가 update된 경우 dirty block이 replace되면 dirty block의 data를 메모리에 씀
- write back에서도 write buffer 사용 가능
5.4 Measuring and Improving Cache Performance
1. Associative Caches
- 지금까지 다룬 cache는 direct mapped cache(하나의 cache line에 하나의 block만 가지는 구조)
- Associative caches: 하나의 cache line에 여러 block를 가지는 구조
1. Associative caches 종류
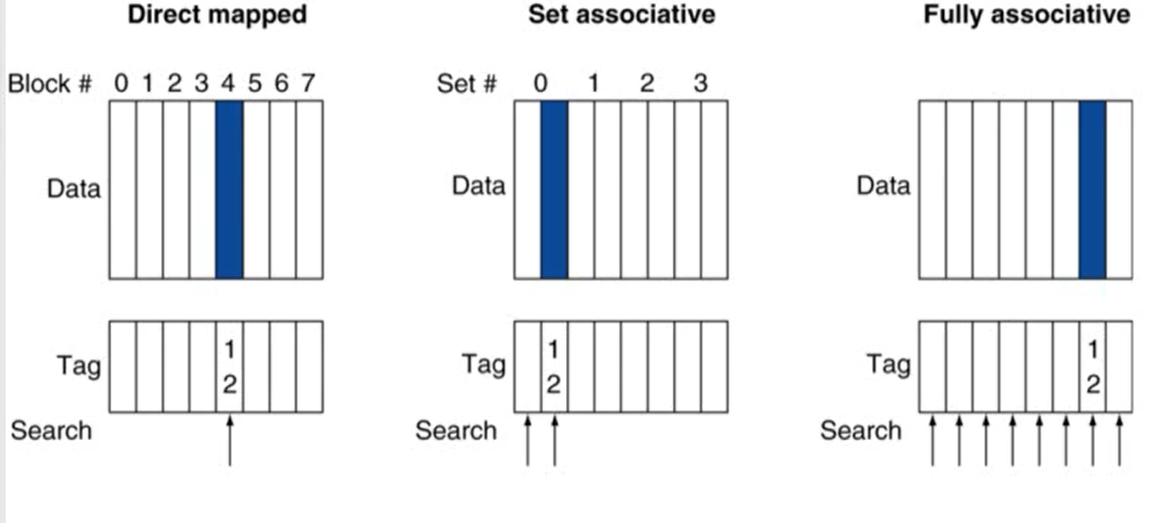
-
entry: tag + data
-
Fully associative
- set이 하나인 경우
- 특정 block이 cache의 어느 entry에도 들어갈 수 있음
- 모든 cache entry를 비교해야 함
- entry가 많아질수록 많은 비교 연산이 필요해 비용이 비싸짐
-
n-way set associative
- 하나의 set(cache line)은 n개의 entry로 구성
- block number는 어느 set에 매핑이 될지 결정 (block number % cache set number)
- 해당 set에 들어있는 모든 entry를 비교
- 따라서 n개의 comparator가 필요
2. Spectrum of Associativity

3. Associativity Example
- 4개의 block caches가 있다고 가정
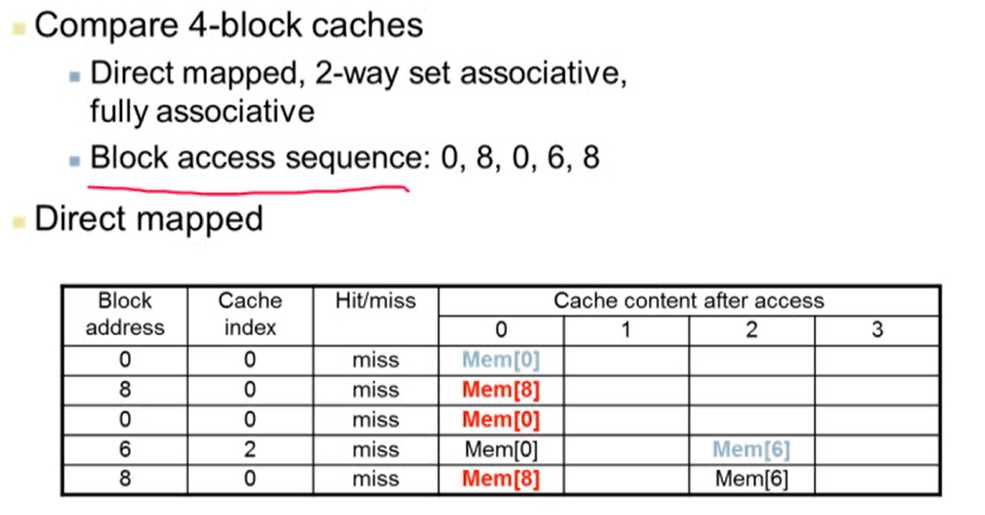
- Cache index는 (block address % 4)를 계산한 값
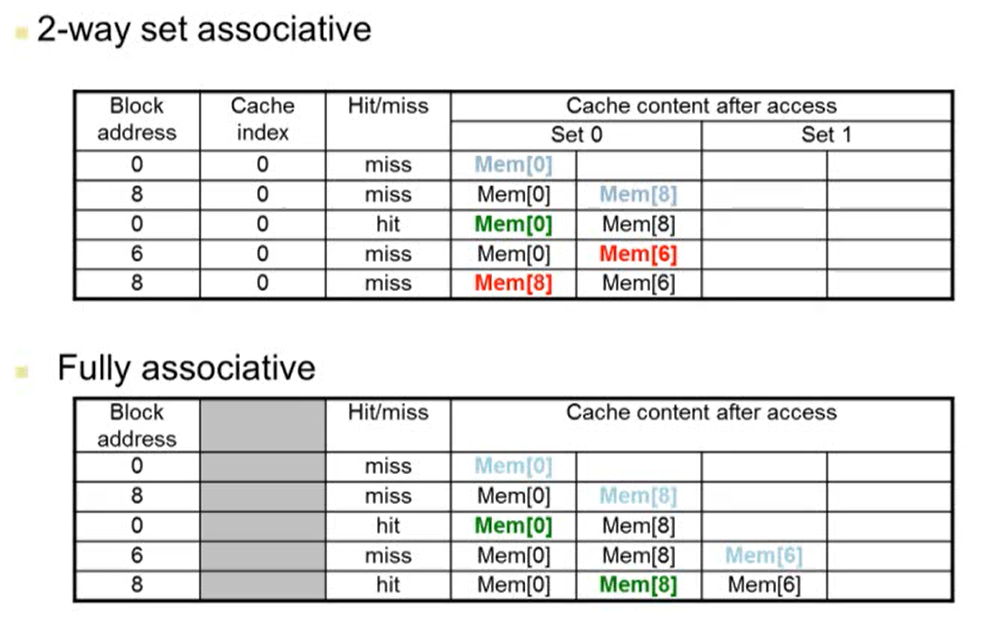
- 2way set associative에서 Cache index는 (block address % 2)를 계산한 값
- 2way set associative에서 block address 6의 값을 cache에 넣을 때 MEM[8]이 바뀌는 이유는 오래된 것을 replace하기 때문
4. How Much Associativity
- associativity를 증가시키면 miss rate는 감소하게 됨
2. Replacement Policy
- cache miss가 발생할 경우 어떤 block를 replacement할지에 대한 규칙
1. direct mapped: 다른 선택권이 없음
2. set associative
- non-valid entry가 있으면 이것을 replace
- entry가 모두 valid인 경우 하나의 entry를 선택해야하는데 이 때 가장 많이 사용하는 알고리즘이 LRU
- least-recently used (LRU): 사용한지 가장 오래된 entry를 선택
- 실제 구현할 때 쉽지 않음. 2way와 4way의 경우 구현 가능하지만 그 이상은 힘듦
- Random: entry를 random하게 선택
- 구현하기 쉬움
- 8way 이상부터는 LRU와 유사한 성능을 보임
5.7 Virtual Memory
- 프로그램들은 main memory를 공유
- 각각의 프로그램들은 private virtual address를 가짐. 자주 사용하는 코드와 데이터를 올림
- 하나의 프로그램이 사용한 virtual address는 다른 프로그램으로부터 보호되어야 함
- CPU와 OS는 virtual memory를 physical address로 변환해주어야함
- VM에서 하나의 block를 page라고 부름
- VM translation에서 miss를 page fault라고 부름
Virtual Addressing with a Cache
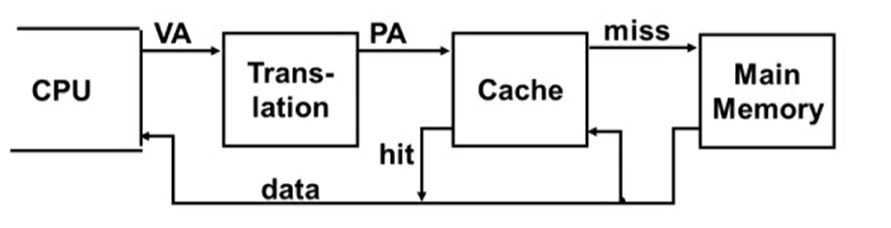
- CPU가 사용하는 주소는 virtual address, cache에서 사용하는 주소는 physical address
- translation: virtual address를 physical address로 변환
- translation를 하는데 extra memory가 필요
- translation 정보는 main memory에 저장되기 때문에 translation 정보에 access하기 위해서는 main memory에 access해야 함
- main memory를 access하는데 걸리는 시간은 cache 메모리에 access하는 시간보다 오래 걸림
- 따라서 매번 cache를 access하는데 main memory를 access하는 건 비효율적
- 하드웨어가 CPU에 Translation Lookaside Buffer(TLB)를 추가
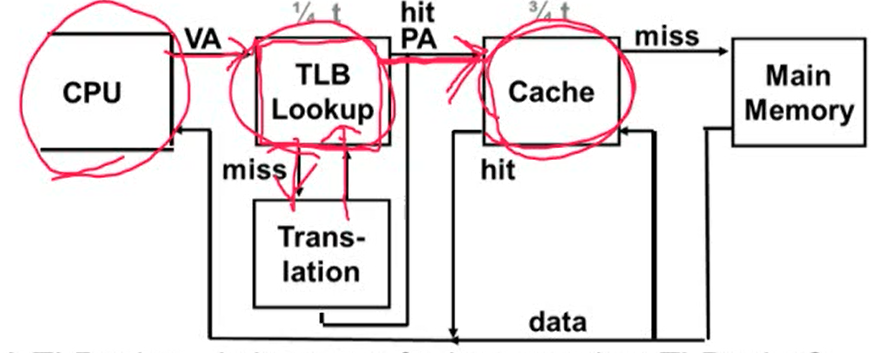
- TLB: 최근에 address translation된 정보를 가지고 있는 buffer
- TLB에 먼저 접근해서 사용하고자하는 데이터의 주소가 TLB에 있다면 바로 사용하고, 없으면 main memory에 접근해서 address translation 수행
- 변환된 physical address를 사용해 cache에 access
- hit이 발생하면 데이터를 cpu에 보냄
- miss가 발생하면 physical address를 사용해 main memory에 access
5.9 Using a Finite State Machine to Control A Simple Cache
Cache Coherence Problem
- Cache에 있는 같은 physical memory에 대해서 서로 다른 cache의 다른 data가 가지고 있을 때 cache coherence 문제가 발생
- 항상 가장 최근에 쓴 값을 읽게되는 것을 원함. p가 X를 쓰고 o가 X를 썼을 때 X에는 o가 쓴 값이 들어가 있어야 함
Cache Coherence Protocols
- Snpoping protocol: 각각의 cache들은 bus의 read, write를 모니터링하다가 본인 cache에 올라와있는 entry에 해당되는 data가 read 혹은 write되면 본인 cache를 update
- bus를 share하는 경우 많이 사용
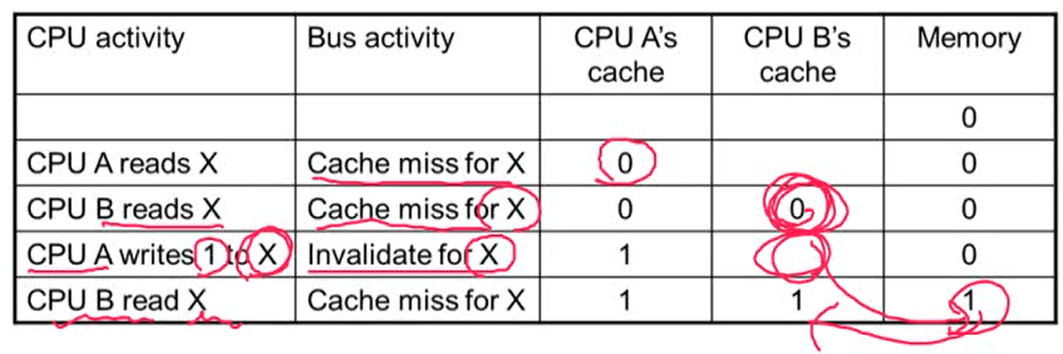
- invalid message를 bus에 broadcasting해서 다른 cache에 있는 해당되는 data를 invalid시킨 후에 read 혹은 write를 수행
- bus를 share하는 경우 많이 사용
- Directory-based protocols: directory에서 cache의 각각의 status 정보를 가지고 있음
- core의 수가 많거나 memory가 다 차지 않은 경우 적합
8~14번 게시물 요약 끝!!!
좀 더 자세한 내용과 예시를 보고 싶다면 컴퓨터구조 시리즈를 확인하세요!
