
KOCW에 공개된 영남대 최규상 교수님 컴퓨터구조 강의를 수강 후 정리한 내용입니다.
4.1 Introduction
1. Instruction
- CPU 성능 측정 요인: Instruction count(ISA와 컴파일러에 의해 결정), CPI와 Cycle time(CPU 하드웨어에 의해 결정)
- MIPS 구현에 대해 배움

- MIPS의 모든 명령어를 다루지는 않지만 사진에 있는 명령어들이 MIPS의 대부분의 특성을 커버할 수 있기 때문에 간단한 명령어들만 배움
2. Instruction Execution
- fetch instruction: PC의 값을 참조해 instruction memory에 위치한 instruction을 읽어옴
- register number에 해당하는 register에 가서 register를 읽어옴
- ALU에서 산술 계산, load/store에서 메모리 주소 계산, branch에서 target address 계산
- load/store 명령어만 data memory에 접근
- data memory: instruction이 사용하는 data가 저장되어 있는 메모리
- PC에는 target address 또는 PC+4 값이 저장됨
3. CPU Overview
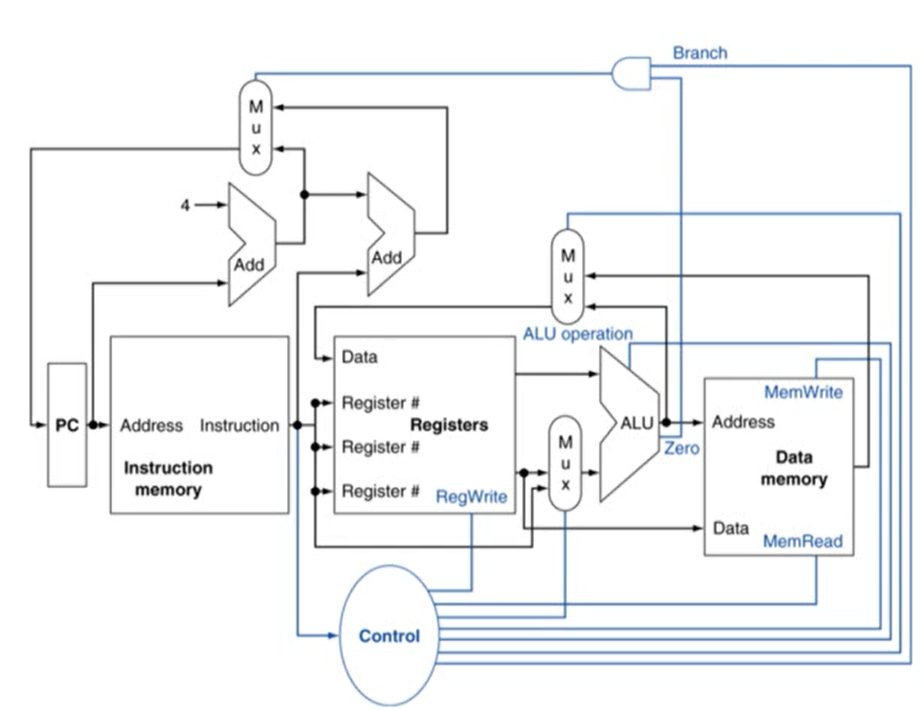
- control: 각가의 하드웨어 모듈이 어떻게 동작하는지를 제어해주는 회로
4.2 Logic Design Conventions
- 회로에서 정보는 binary로 표현. 1bit을 표현하기 위해서는 하나의 wire가 필요. Multi-bit를 표현하기 위해서는 multi-wire가 필요
- Logic 종류
- Combination logic
- 데이터에서 동작
- input에 의해 output이 결정

- Sequential(state) logic
- circuit에 정보를 저장하는데 사용
- clock signal에 의해 저장되어 있는 값이 바뀜
- output은 현재 저장되어 있는 값과 input에 결정
- ex) flip-flop, register, memory 구현에 사용
- Combination logic
Clocking Methodology

- 여러 logic 중 가장 긴 logic이 clock period로 사용됨
4.3 Building a Datapath
- datapath: 연산을 할 경우 데이터는 순차적으로 전달이되고 저장이 됨
- 관련 하드웨어 모듈(레지스터, ALU, MUX, memory 등)을 연결한 것
1. Instruction Fetch
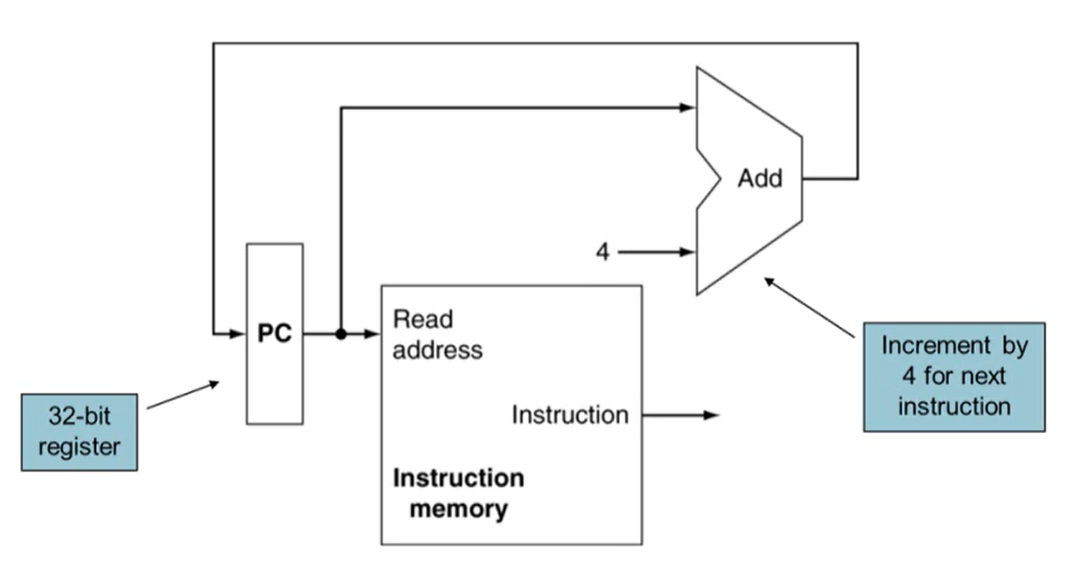
- instruction memory로부터 instruction을 읽어옴
- PC의 값이 instruction memory에 input으로 들어가면 해당되는 instruction이 output으로 나옴
- 동시에 현재 PC 값에 4를 더한 후 PC에 저장(Add를 사용)
2. R-Format Instruction
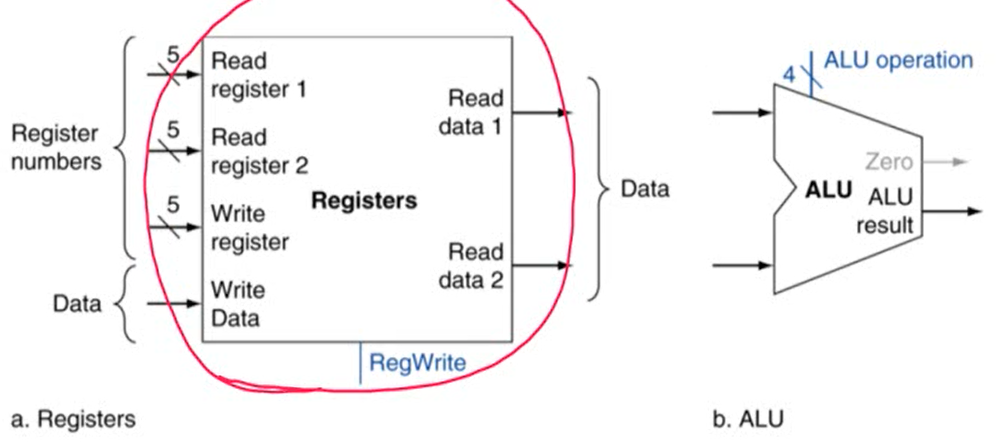
- 3개의 레지스터를 사용. 2개의 레지스터에서 데이터를 읽음
- arithmetic/logical operation 수행한 후 결과를 레지스터에 저장
3. Load/Store Instruction

- sign extension 사용. load/store 명령어의 경우 ALU가 32bit이므로 16bit를 다시 32bit로 변경해주어야 함
4. Branch Instruction
- 레지스터에서 operand를 읽은 후 operand의 값을 비교
- 값을 비교할 때 ALU 사용. 두 값을 뺏을 때 0이면 같은 값 아니면 다른 값
- target address 계산
- sign extension 사용
- 2bit만큼 shift left
- PC+4를 더해줌

5. Composing the Elements
- component를 통합해 하나의 cycle이 돌아가도록 함
- MIPS의 구현은 한 명령어가 하나의 cycle에 돌아가도록 하는 것
- data memory와 instruction 메모리를 분리. 하나의 명령어가 두 메모리에 동시에 access하지 못하도록 나눠줌
- instruction에 따라 data source가 달라지기 때문에 MUX를 사용
1. R-Type/Load/Store Datapath
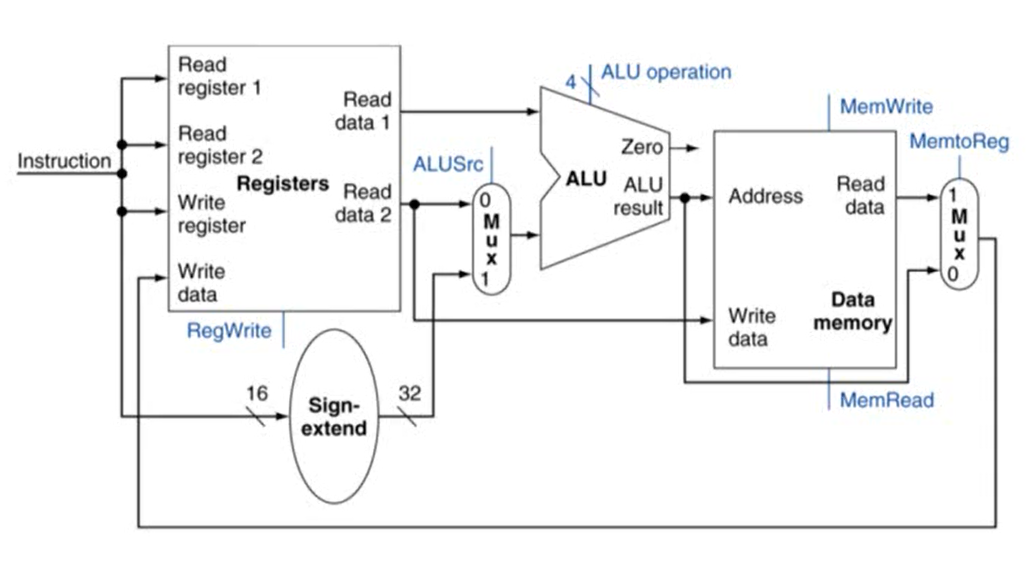
2. single cycle로 돌아가는 MIPS의 구현 회로
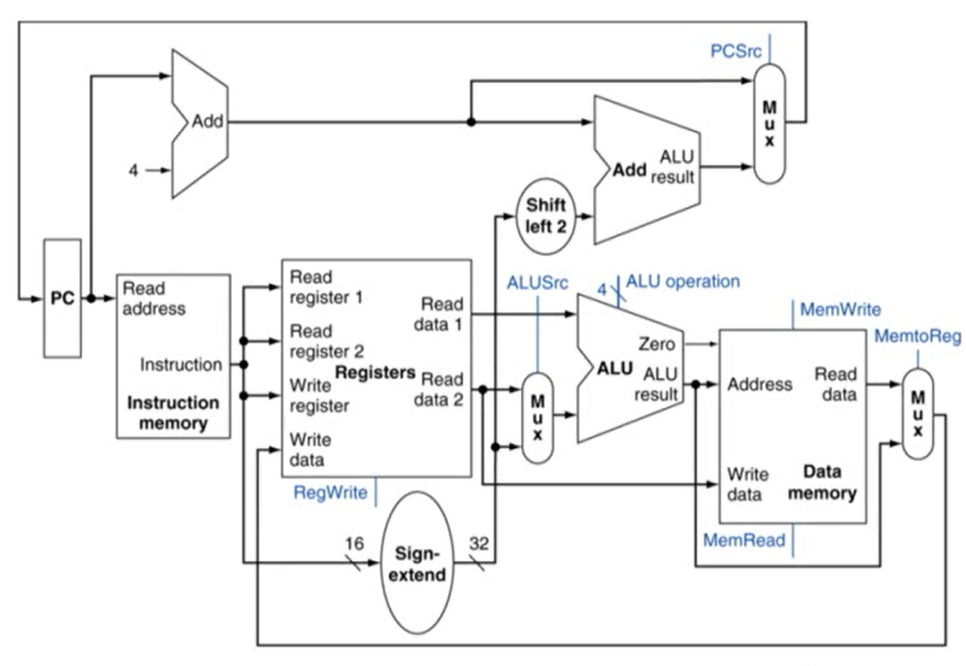
- 위쪽이 branch, 아래쪽이 load/store 회로
4.4 A Simple Implementation Scheme
1. ALU(Arithmetic Logical Unit) Control
- load/store, branch, R-type(add, subtract, AND, OR) 연산시 사용
- opcode로부터 2bit ALUOp를 만들 수 있음
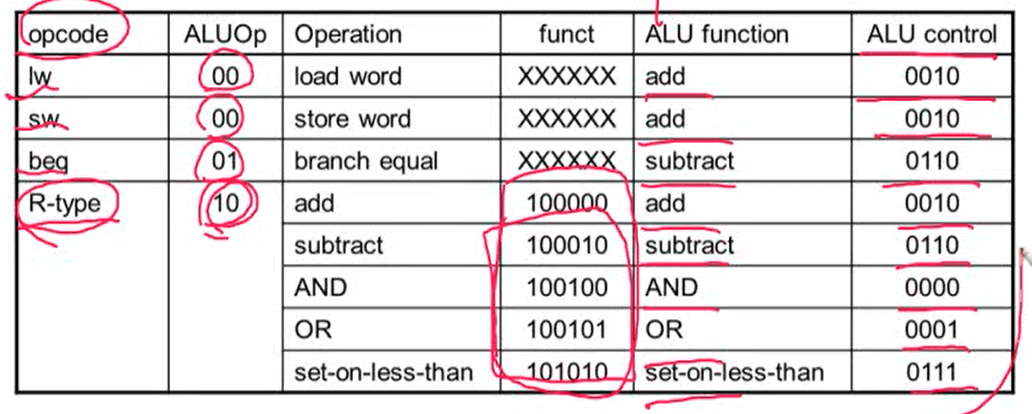
- 이런 테이블이 있는 경우, k-map을 사용해서 combination logic을 만들 수 있음
2. The Main Control Unit
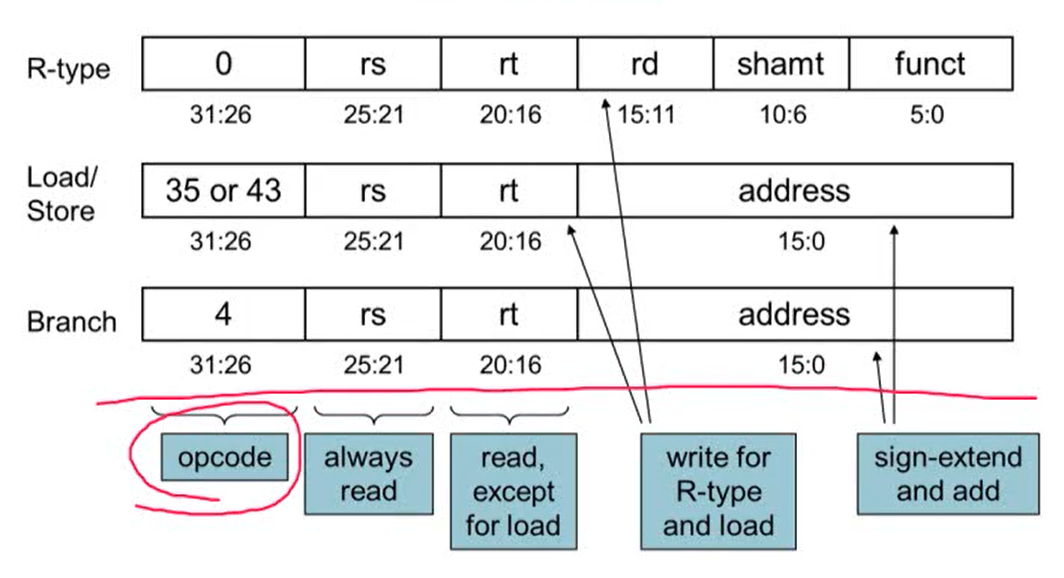
- instruction에 의해 control signal이 만들어짐
Datapath of Control
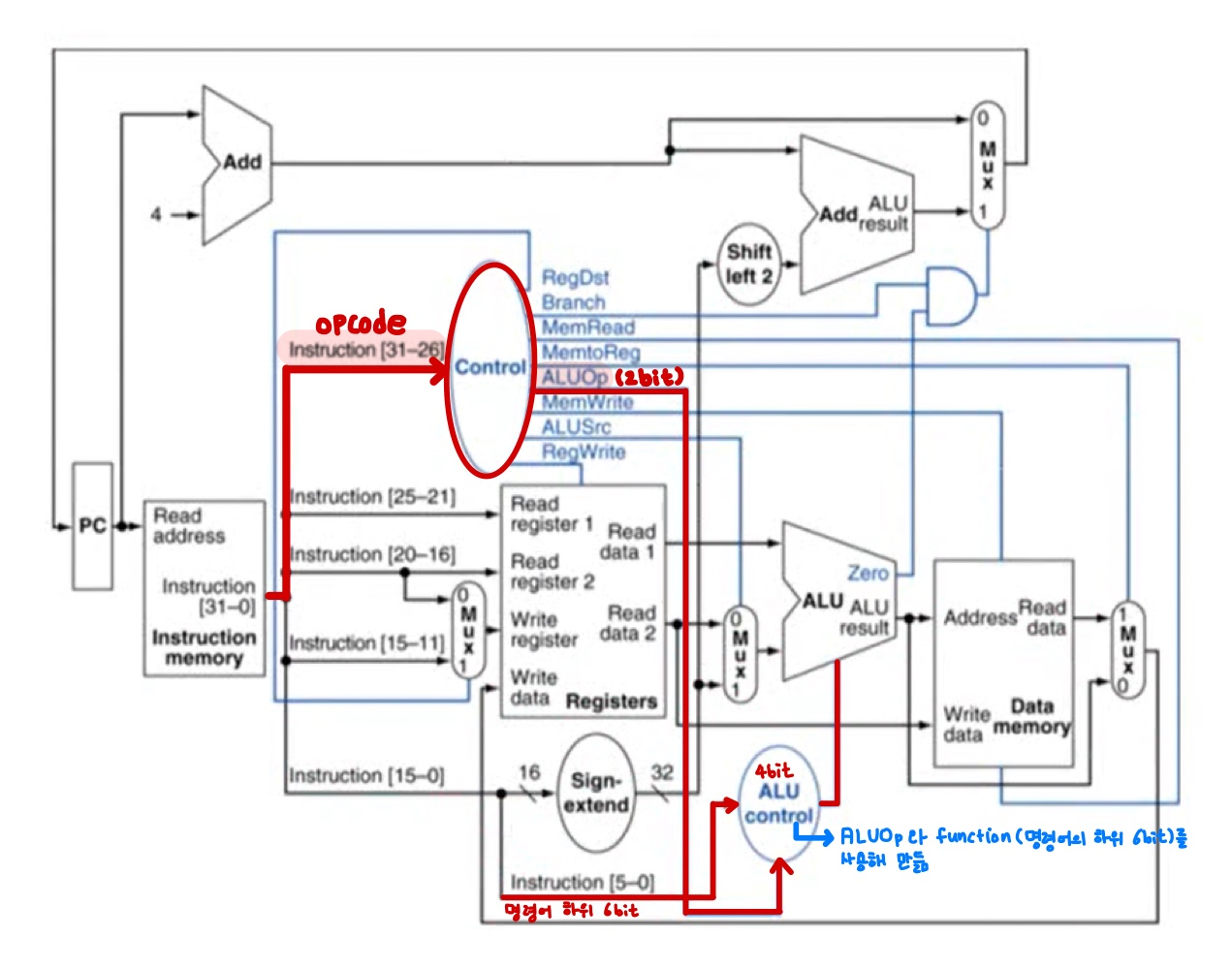
3. Performance Issues
- 회로에서 가장 오래된 delay가 clock period를 결정
- MIPS 구현에서 가장 오래 걸리는 delay는 load instruction
- 이유: Instruction memory -> register file -> ALU -> data memory -> register file. 총 5단계가 필요하기 때문
- 각각의 명령어에 따라 다른 clock period를 사용하면 어떨까?
- 현실 회로에서는 불가능
- (design principle 중) 가장 많이 사용하는 것을 빠르게 만들어주어야 하지만 clock은 가장 느린 것에 맞추기 때문에 이 규칙에 위배됨 => 성능을 향상시키기 위해 pipline을 사용
4.5 An Overview of Pipelining
Pipeline
- overlapping excution: 병렬성을 통해 성능을 향상시킴
1. MIPS Pipeline
- 5단계로 구성
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
2. Pipline Performance
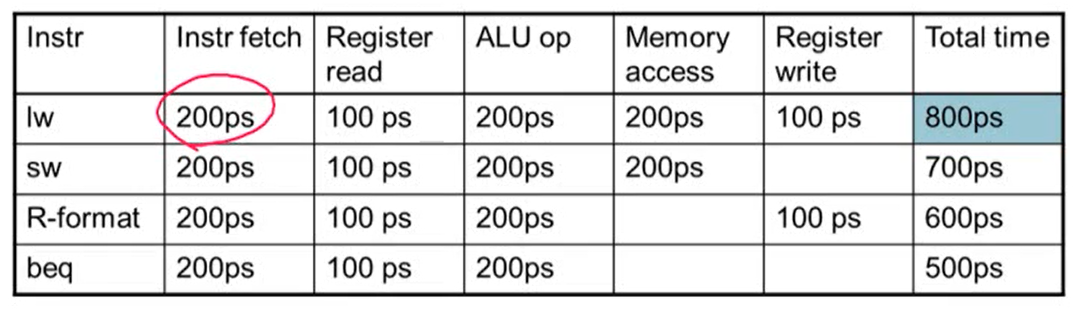
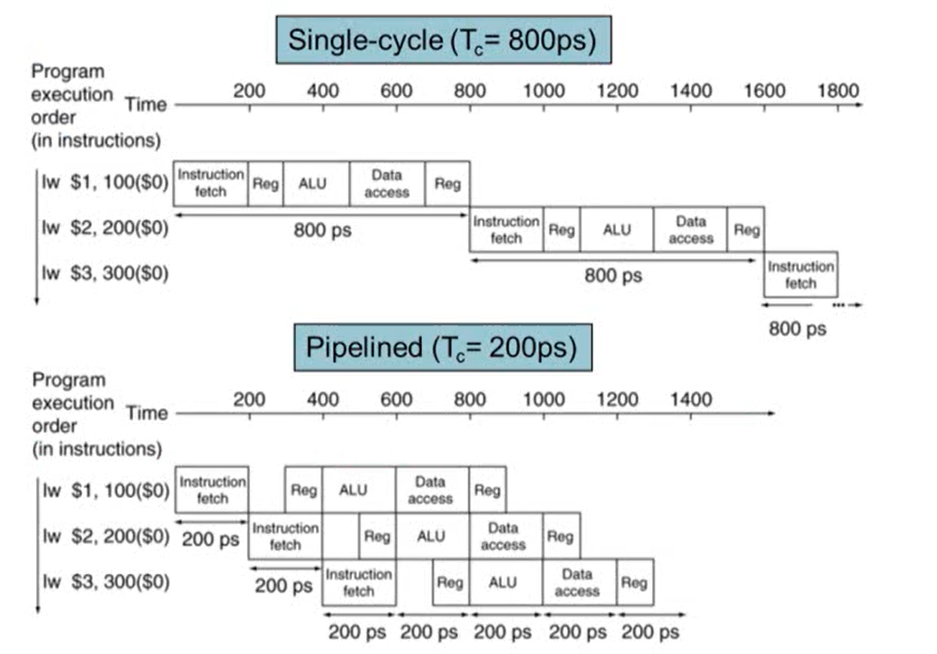
- Single-cycle의 경우 각 step의 시간을 모두 더한 시간 중 가장 긴 시간에 clock period가 맞춰짐
- 파이프라인은 각각의 step 중 가장 긴 시간에 clock period가 맞춰짐
Pipeline Speedup
- pipeline은 throughput이 증가하기 때문에 속도가 빨라짐. 즉 pipline을 사용하는 경우 성능 향상은 throughput 때문에 발생
3. Piplining and ISA Design
- MIPS ISA은 pipeline에 적합
- 모든 명령어가 32bit이고 명령어 format이 적기 때문
- load/store addressing: 3단계에서 주소를 계산하고 4단계에서 메모리에 access
- memory operand가 4byte씩 구성
7주차 수업 끝!!!
게시물에 사용된 사진은 강의 내용을 캡쳐한 것입니다.

예비 백엔드 개발자