
KOCW에 공개된 영남대 최규상 교수님 컴퓨터 구조 강의를 수강 후 정리한 내용입니다.
4.5 An Overview of Pipelining
1. Hazards
- Hazards: 다음 cycle에 다음 명령어를 시작하지 못하는 현상
- 매 cycle에 새로운 명령어를 수행해야하는데 그렇지 못한 상황을 의미
- Structure hazard
- 어떤 명령어를 실행하기 위해 하드웨어 resource가 필요한데 이미 하드웨어 resource가 사용되고 있어 해당되는 명령어를 실행하지 못하는 경우 발생
- Data hazard
- 어떤 명령어를 실행할 때 명령어에 필요한 데이터가 이전 명령어로부터 나오는데 이전 명령어의 실행이 종료될 때까지 기다려야할 경우 발생
- Control hazard
- 다음 사이클에 실행할 명령어가 이전 명령어의 결과에 의존하는 경우. 즉 control에 의존하는 경우 발생
2. Structure hazard
- 원인: resource 사용의 충돌에 의해 발생
- 해결방법: resource 추가
- 예시: MIPS pipeline에서 메모리가 하나라고 가정
- load/store의 경우 data를 가져오기 위해 메모리에 접근
- instruction fetch의 경우 명령어를 가져오기 위해 메모리에 접근
- load/store 명령어가 data를 가져오기 위해 메모리에 접근하는 동안에는 instruction fetch는 메모리에 접근할 수 없음. 하나의 메모리에 두 개가 동시에 access할 수 없음
- instruction fetch의 경우 load/store가 종료될 때까지 기다려야 함
- bubble이 발생
- stall: 기다려야하는 상황, bubble: 아무것도 하지 않는 상황
- 따라서 instruction fetch 앞의 명령어가 load/store 명령어인 경우 structure hazard 발생
- 해결 방법: instruction 메모리와 data 메모리를 분리
3. Data hazard
- 원인: 명령어가 이전 명령어의 결과에 의존하는 경우 발생 (data dependency에 의해 발생)
- data dependency 종류: Read After Read, Write After Write, Read After Write, Write After Read
- Read After Write의 경우 data hazard 발생
- single cycle processor에서는 발생하지 않음
- 예시
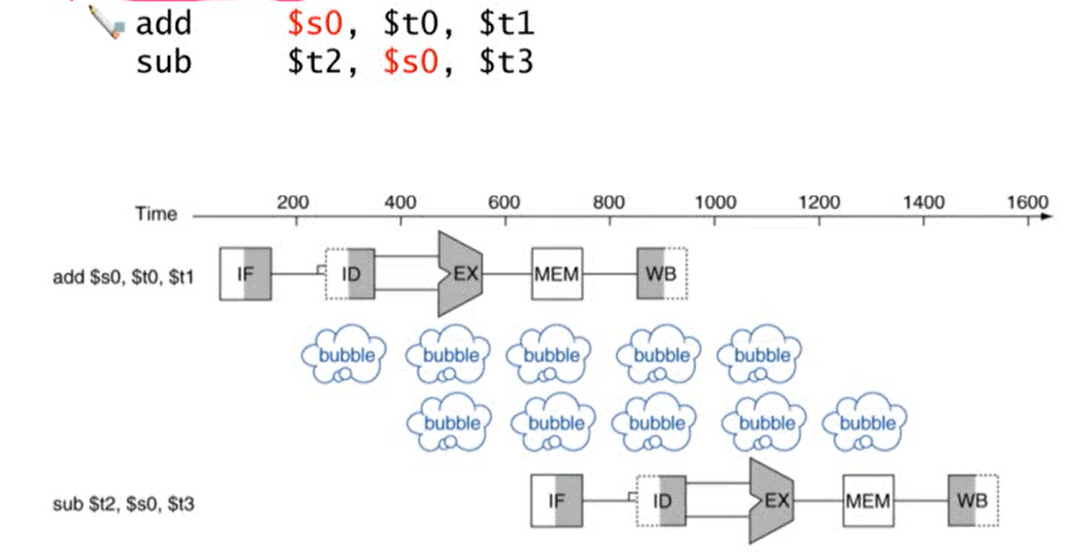
- 두 번째 명령어의 $s0는 앞의 명령어인 add의 결과에 의존
- add 명령어의 WB와 sub 명령어의 ID는 하나의 stage로 구성
- 두 cycle stall이 발생
- 해결 방법: Forwarding (Bypassing)
- 어떤 데이터의 값이 계산이 되면 그 결과를 바로 사용하는 것
- 레지스터에 값이 쓰여질 때까지 기다리지 않음
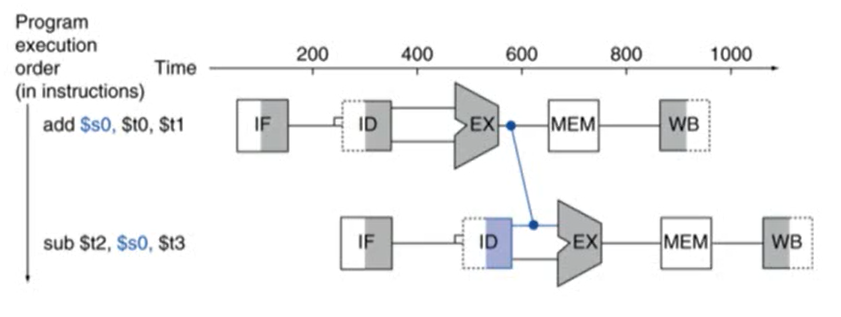
- 두 번째 명령어에서 $s0의 값은 ID stage에서 읽어오는데 이 때 레지스터에서 값을 읽어오는 것이 아니라 앞의 명령어에서 계산된 결과값을 바로 사용해 연산을 수행
- Forwarding을 사용하면 hazard가 발생하지 않음
Load-Use Data Hazard
- Forwarding으로도 해결 불가능한 data hazard
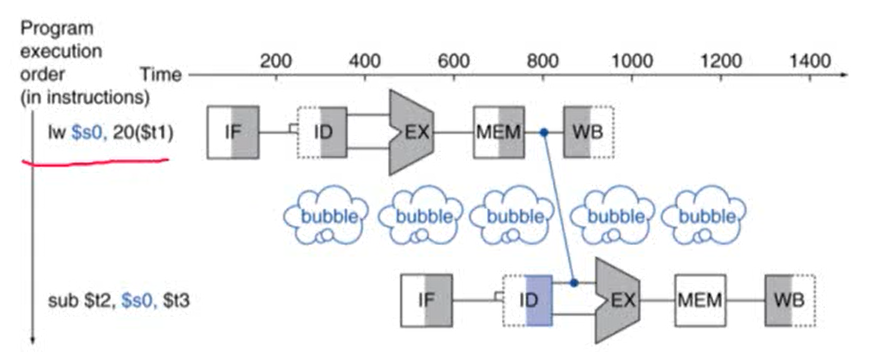
- 해결방법: Code Scheduling
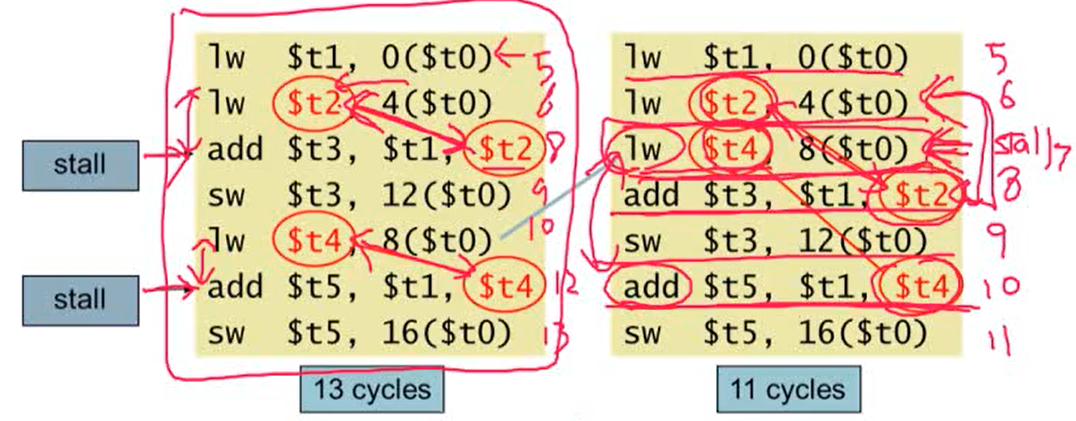
- load-use data hazard를 해결하기 위해 혹은 명령어를 빠르게 실행시키기 위해 명령어의 순서를 바꿔주는 것
4. Control Hazard
-
원인: branch 명령어에 의해 발생하는 hazard
- branch는 프로그램의 flow를 결정. 다음에 실행할 명령어는 branch의 결과에 의해 결정됨
- pipline에서 다음에 실행할 명령어를 정확히 fetch할 수 없음. branch의 ID stage에서 다음 명령어를 fetch해야하기 때문
-
MIPS pipeline에서는
- 레지스터를 비교하고 target address 계산하는 것을 pipeline에서 더 일찍 수행하도록 수정해야함
- 이 과정을 ID stage에서 할 수 있도록 하드웨어를 추가해줌
- 따라서 MIPS pipeline에서는 ID stage에서 branch의 결과를 알 수 있게됨
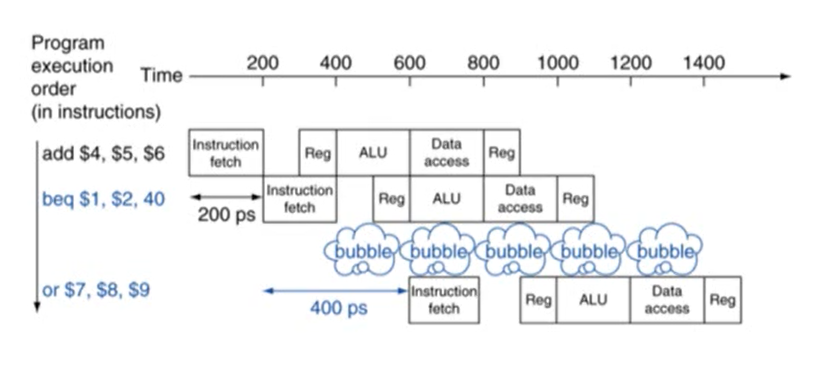
-
해결방법: Branch Prediction
- branch의 결과를 예측해 다음에 실행할 명령어를 미리 실행
- 최근 processor에는 pipline stage가 많음. 많을수록 성능 향상이 되기 때문. 하지만 longer pipline일수록 branch의 결과 늦게 알기 때문에 여러 stall이 발생
- stall을 줄이기 위해 branch의 결과를 예측. 결과 예측이 틀릴 경우 stall이 발생하지만, 맞을 경우 stall이 발생하지 않음
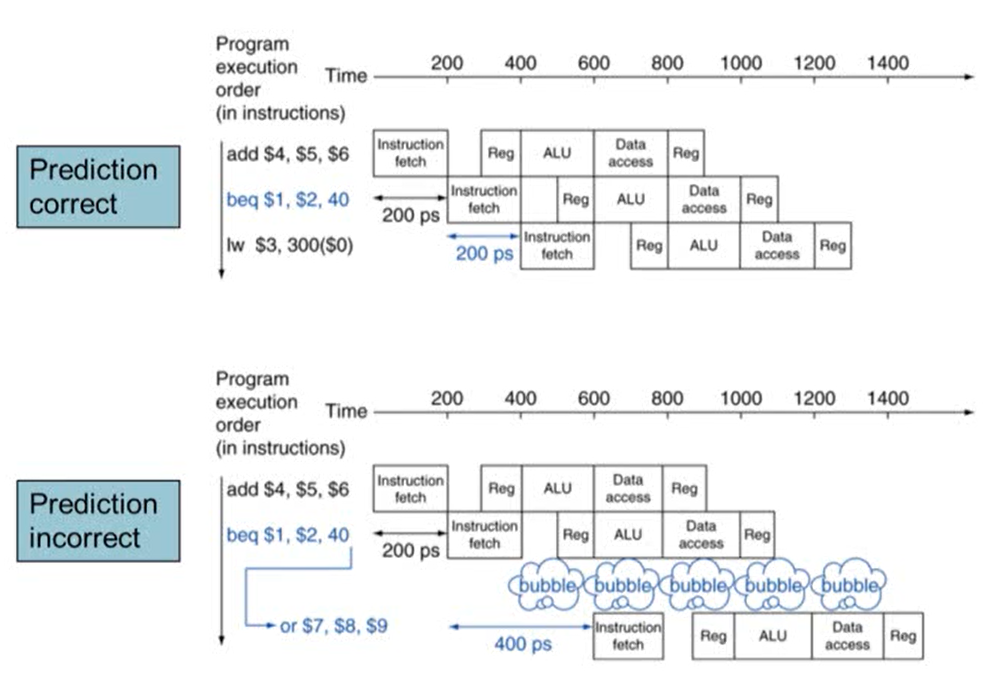
- Static branch prediction
- branch prediction의 결과가 고정되어 있음 (ex. if, loop: 항상 taken or not taken으로 예측)
- 정확도가 떨어질 수 있음
- Dynamic branch prediction
- 기존 branch의 결과를 활용. 최근 branch의 결과 history를 기록해 그 결과를 활용해서 branch의 결과를 prediction
- 잘못 예측했을 경우, 제대로 된 명령어를 fetch하고 history를 update
- 최신 processor의 경우 dynamic branch prediction을 사용
5. Pipeline 정리
- pipeline: instruction throughput를 증가시켜 성능을 향상시킴
- 여러 개의 명령어를 동시에 실행. 각각의 명령어의 실행시간은 같음
- Subject to hazards: Structure, data, control
- ISA는 pipline 구현의 복잡도에 영향을. ISA가 간단할수록 pipline 구현이 쉬워짐
4.6 Pipelined Datapath and Control
MIPS Pipelined Datapath
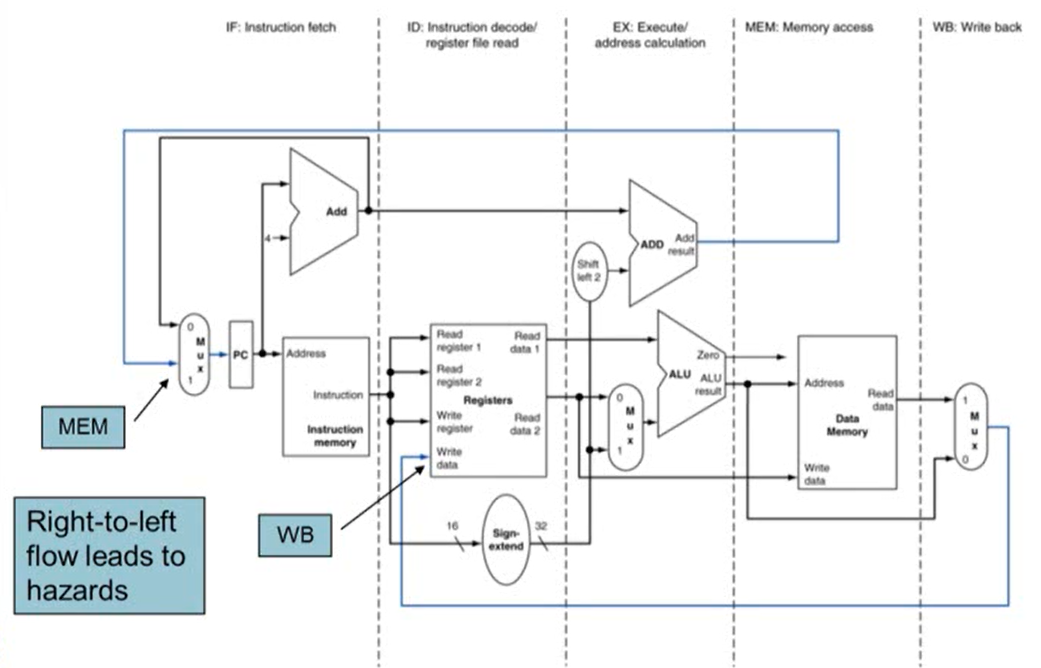
- 오른쪽에서 왼쪽으로 진행되는 경우 hazard 발생
- MIPS에서 pipline를 구현하기 위해서는 각가의 stage마다 register가 필요
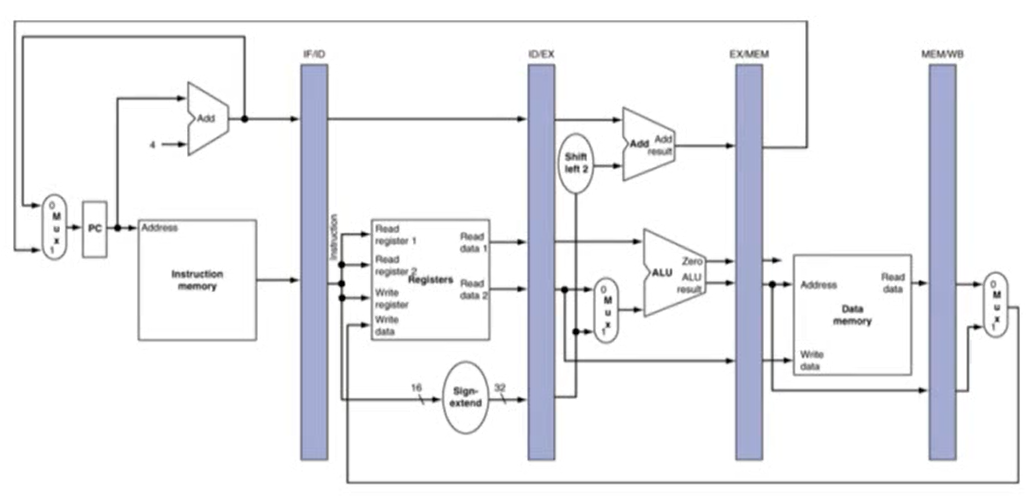
- pipeline register: 전 stage의 결과를 다음 stage에서 사용하기 위해 전 stage의 결과를 저장하는 register
1. Pipline Operation
- pipeline process를 이해하기 위해서는 cycle-by-cycle로 어떤 명령어가 수행되는지 이해해야함
- cycle by cycle로 수행되는 명령어의 흐름을 표현하는 두 가지 방법
- 'Single clock cycle' pipeline diagram
- 특정 cycle의 pipeline의 현재 상태를 보여줌
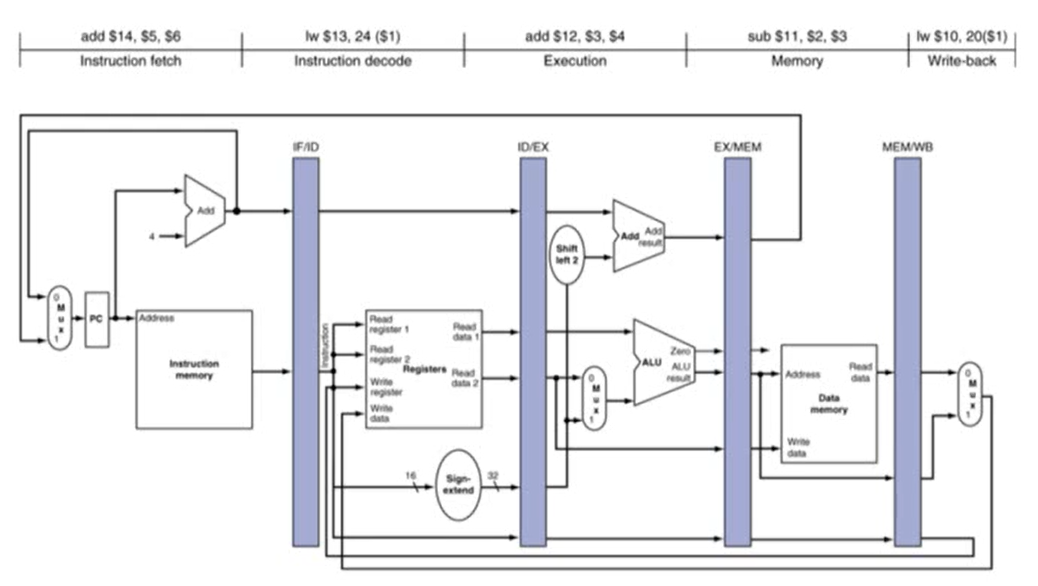
- 아래 그림에서 5번째 cycle를 표현
- 특정 cycle의 pipeline의 현재 상태를 보여줌
- 'Multi clock cycle' diagram
- 시간의 흐름에 따라 pipeline 프로세스가 어떻게 실행되는지를 보여줌
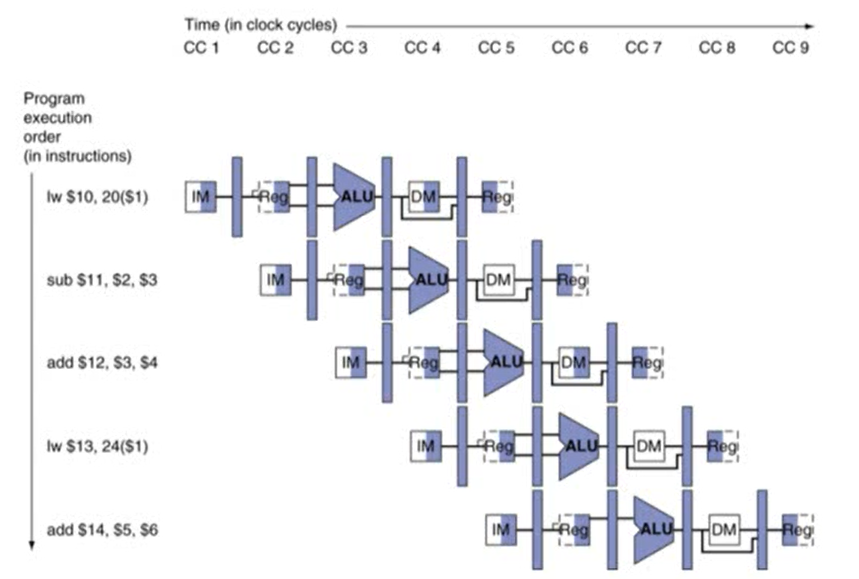
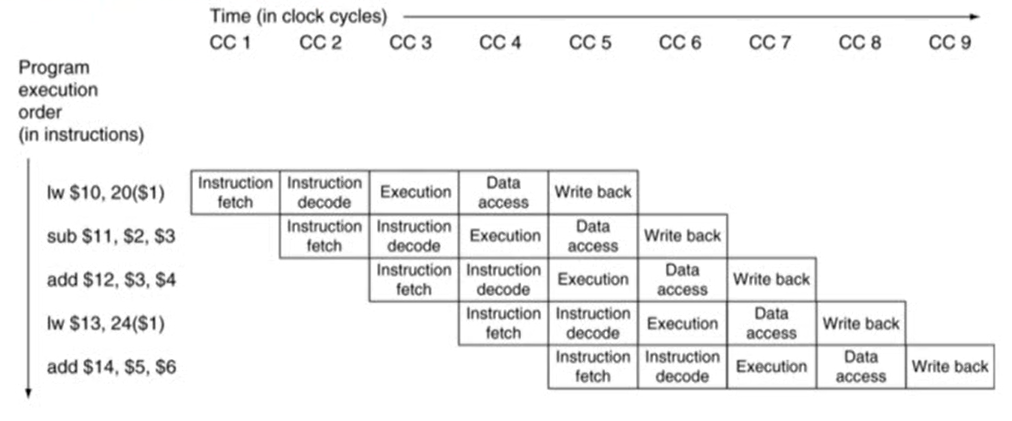
- 시간의 흐름에 따라 pipeline 프로세스가 어떻게 실행되는지를 보여줌
- 'Single clock cycle' pipeline diagram
2. Pipelined Control

- pipeline control은 ID stage에서 만들어짐
- instruction을 fetch한 후 instruction을 decode할 때 fetch된 instruction을 사용해 control를 만듦
- ID, EX, MEM, WB stage에서 사용
- 각각의 stage에서 사용하는 control를 pipeline register를 사용해서 전달해줘야 함
- pipeline processor은 single-cycle processor보다 훨씬 복잡함
9주차 강의 끝!!!
게시물에 사용된 사진은 강의 내용을 캡쳐한 것입니다.

예비 백엔드 개발자