
KOCW에 공개된 영남대 최규상 교수님 컴퓨터 구조 강의를 수강 후 정리한 내용입니다.
4.10 Parallelism via Instrcutions
1. ILP
- Instruction-Level Parallelism: 여러 개의 명령어를 병렬적으로 실행하는 것
- ILP를 증가하기 위해서는
- pipeline stage를 증가시키면 됨
- 각각의 stage마다 하는 일이 적어지면 clock cycle이 짧아져 성능이 향상됨
- 여러 개의 명령어를 동시에 실행 (issue: instruction fetch 과정)
- 여러 개의 파이프라인을 만듦
- 각 cycle마다 실행하는 명령어가 여러 개가 될 수 있음
- pipeline stage를 증가시키면 됨
2. Multiple Issue
1. Static multiple issue
- 어떤 명령어가 실행될 때 이 명령어가 어떤 cycle에서 실행될지 미리 결정되어 있음
- 컴파일러가 어떤 명령어를 어떤 사이클에서 실행시킬지 결정
- issue slots: 컴파일러가 한 cycle에 실행될 명령어들을 묶은 것
- 컴파일러가 hazard를 감지하고 회피함
- 컴파일러가 명령어의 그룹을 issue packet으로 만듦
- issue packet이 매우 긴 명령어처럼 보이게 됨. 이런 아키텍쳐를 Very Long Instruction Word(VLIW) 라고 부름
- Scheduling Static multiple issue
- 컴파일러가 hazard를 감지하고 없애야 함
- 명령어를 reorder하고 dependency가 없는 packet를 만듦
- packet 사이에는 dependency가 생길 수 있는데 이럴 경우 nop operation를 두어 hazard를 해결
2. Dynamic multiple issue
- CPU가 동적으로 어떤 명령어를 실행할 cycle를 결정
- CPU가 runtime hazard를 감지하고 해결
- Superscalar processor: dynamic multiple issue를 지원하는 프로세서
- 필요에 따라 컴파일러가 도움을 줄 수 있음
3. Speculation
- 예측해서 미리 실행하는 것
- 명령어들을 가능한 빨리 시작시킴
- 예측한 것이 맞으면 그대로 실행. 틀리면 roll-back를 하고 제대로 된 명령어를 실행
- static, dynamic multiple issue에서 많이 사용하는 기법
- ex) branch prediction, load 명령어(같은 값을 load하는 경우가 많기 때문에 load 명령어의 결과를 기다리지 않고 기존의 값을 활용)
- Static speculation: ISA의 도움을 받아 exception 처리를 늦춤
- Dynamic speculation: 명령어가 끝날 때까지 exception를 buffering 해줌
3. Hazard in the Dual-Issue MIPS
1. EX data hazard
-
single issue인 경우 forwarding를 사용해서 해결
-
ALU의 결과를 같은 packet에서의 load/store 명령어에서 사용 불가
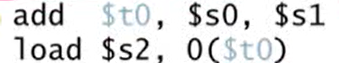
- 두 명령어가 하나의 packet으로 묶이게 되면 add 결과를 두 번째 명령어에서 load할 수 없음
- 제대로 된 결과를 얻기 위해서는 두 명령어를 다른 packet에 놓아야 함. 이럴 경우 stall이 발생
-
Dual-Issue의 경우 스케쥴링을 적극적으로 해야 hazard가 해결됨
2. Scheduling Example

4. Dynamic Pipline Scheduling
- dynamic multiple issue를 사용
- CPU가 stall를 방지하기 위해 out of order을 수행
- in order: 먼저 실행한 명령어가 먼저 끝나야 함. 일반적인 파이프라인 프로세스레에서 사용
- out of order: superscalar processor에서 지원. 먼저 명령어가 실행됐더라도 먼저 끝나지 않을 수 있음
- 단, 데이터가 쓰여지는 commit 단계는 in order
- Example
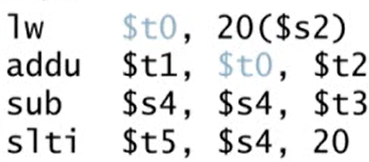
- addu가 lw 명령어가 끝나기를 기다리는 동안 sub 명령어를 실행할 수 있음
- Dynamic Scheduled CPU
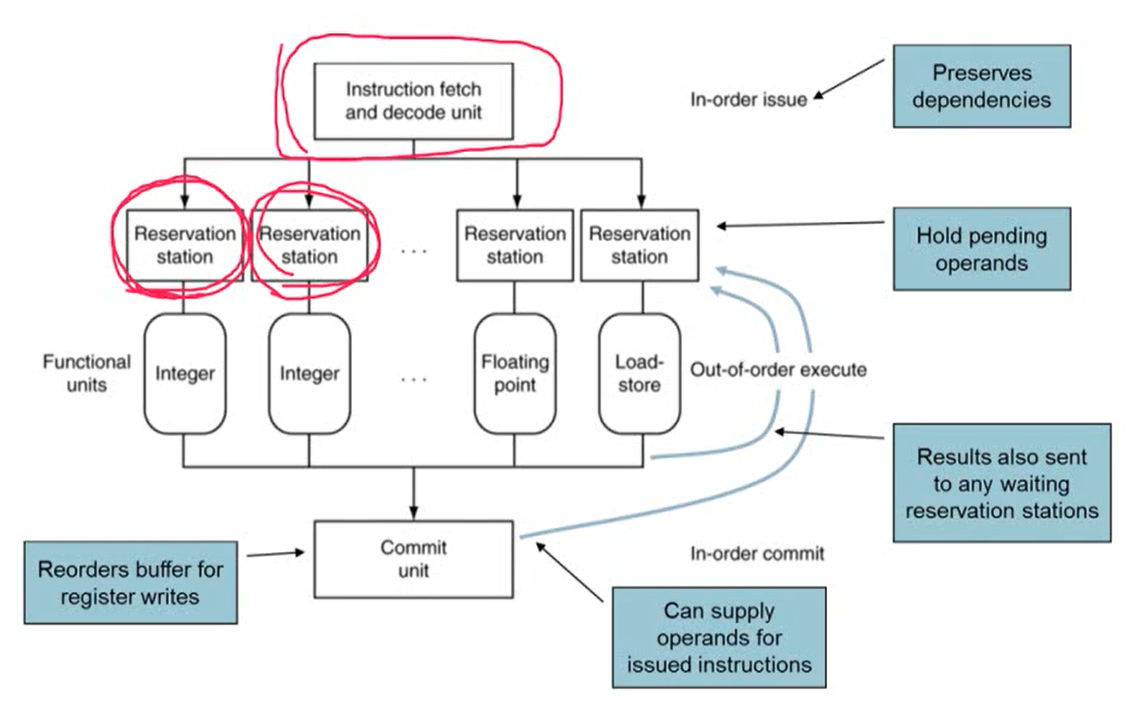
- issue: Instruction fetch. in-order로 이루어짐
- Reservation station: 명령어를 수행하기 위한 하드웨어 resource를 할당받음
- functional unit에서 명령어가 실행되고 결과는 out-of-order
- Commit: 실행된 결과를 실제 레지스터에 반영 (in-order)
- 사용하는 이유
- 컴파일러는 모든 stall를 예측하기 힘듦. 예를 들어 cache misses 같은 경우 runtime에만 알 수 있음
- branch 같은 경우 이런 schedule를 제대로 하기 어려움. branch의 결과도 동적으로 결정이 되기 때문에 컴파일러가 branch를 모두 고려해 스케쥴링하기 어려움
- ISA를 구현할 때 다른 구현은 다른 latency와 다른 hazard를 가지고 있음. 따라서 컴파일러가 모든 프로세서의 내부 구조를 완벽하게 알고 있어야 하기 때문에 이것에 맞춰 코드를 generation하기 어려움
5. Register Renaming
- superscalar 프로세스의 가장 큰 특징 중 하나
- 어떤 명령어가 어떤 레지스터를 사용하는 경우 요청한 레지스터가 아닌 다른 레지스터가 사용할 수 있는 상태라면 사용 가능한 레지스터를 사용하는 것
- operand가 register file과 reorder buffer에서 available한 경우
- reservation station으로 복사
- operand가 not available한 경우
- function unit에 의해 reservation station이 제공되고 register update는 필요하지 않음
- 실제 코드에 사용한 레지스터와 실행될 때 사용한 레지스터가 바뀔 수 있다는 것을 의미
6. Multiple Issue가 잘 동작하는가?
- YES. 하지만 data dependency 때문에 예상한만큼은 아님
- 몇몇이 dependency는 없애기 어려움 (ex. pointer aliasing)
- parallelism은 실제로 사용하기 여러움
- memory delay와 bandwidth 제한 때문에 예상한만큼의 높은 성능을 내지는 않음
- Speculation은 multiple issue가 잘 동작하는데 도움을 줌
4.15 Concluding Remarks
- ISA는 프로세스의 datapath와 control design에 영향을 주고 datapath와 control design도 ISA design에 영향을 줌
- pipeline은 throughput를 증가시켜 성능을 향상시킴
- Hazard: structural,data, control
- Multiple issue and dynamic scheduling (ILP)
- dependency는 parallelism를 제한
게시물에 사용된 사진은 강의 내용을 캡쳐한 것입니다.

예비 백엔드 개발자