
KOCW에 공개된 영남대 최규상 교수님 컴퓨터 구조 강의를 수강 후 정리한 내용입니다.
6.1 Introduction
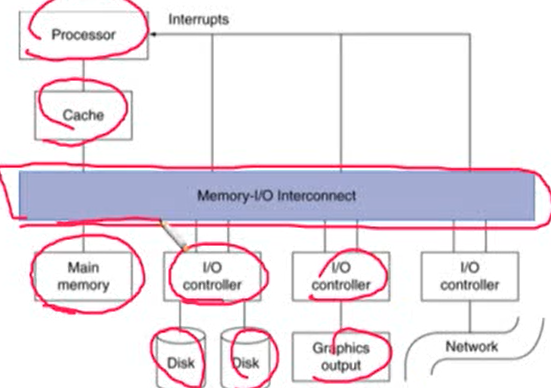
I/O bus connections
I/O System Characteristics
- dependability(신뢰성)가 중요. 특히 storage에서 중요
- dependability: 어떤 시스템을 오류없이 사용할 수 있는 것
- Performance measures
- latency (response time)
- throughput (bandwith)
- desktops & embedded systems: response time이 중요
- servers: throughput이 중요
6.2 Dependability, Reliability, and Availability
1. Dependability
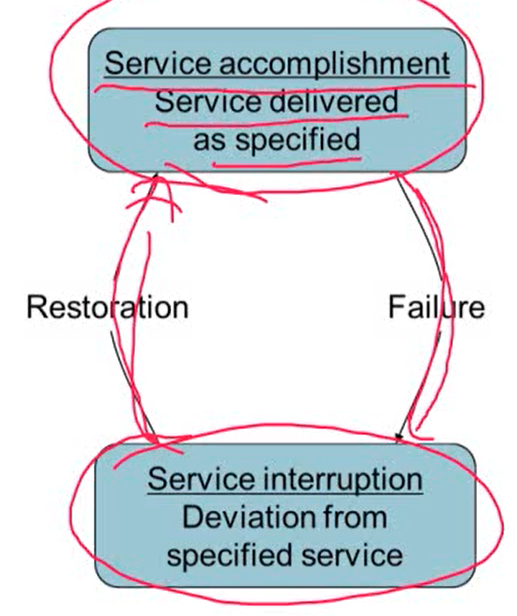
- fault: 컴포넌트에 오류가 생긴 것
- 전체 시스템이 멈출 수도 있고 그렇지 않을 수 있음
- 마우스, 키보드에 오류가 생길 경우 프로그램은 그대로 동작하지만, CPU에 오류가 생길 경우 프로그램은 멈추게 됨
- 어느 부품에 fault가 생기느냐에 따라 달라짐
2. Dependability Measures
1. Reliabilty: mean time to failure (MTTF)
- 오류까지의 평균 시간. 평균적으로 오류가 언제 한 번 발생하는가
- 값이 클수록 좋음
2. Service interruption: mean time to repair (MTTR)
- service interruption을 해결하는 시간
3. Mean time between failures
- 오류 간의 평균 시간
- MTBF = MTTF + MTTR
4. Availability
- MTTF / (MTTF + MTTR) = MTTF / MTBF
- 실제 어떤 서비스를 받을 확률
- 값이 클수록 좋음 (1이면 항상 서비스를 제공받음)
Improving Availability
- MTTF 증가: 오류 발생 간격을 더 늘림
- fault가 발생하지 않도록 하고, fault가 발생하더라도 극복하고 실행할 수 있도록 함.fault 예측을 수행
- MTTR 감소: 오류 극복 시간을 짧게 만듦
- diagnosis(왜 오류가 발생했는지)와 repair의 tool과 process를 향상시킴
6.3 Disk Storage
Disk Storage
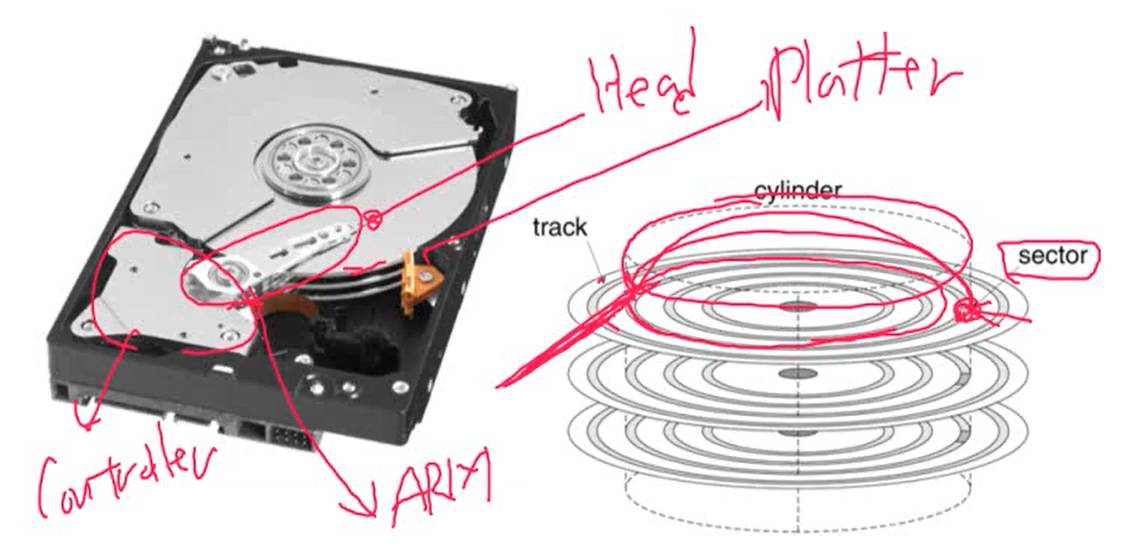
1. Disk Sectors and Access
- sector로 구성되어 있음. sector는 기본적으로 ID를 가짐
- 512 bytes, Error correctiong code(ECC)를 가짐
- sector 사이에는 약간의 gap이 존재. sector를 구분하기 위함
- 특정 sector를 access하고자 할 때
- Queuing delay: 앞의 내용을 처리하는 과정
- Seek: head를 옮기는 과정. sector의 위치에 따라 다르기 때문에 일반적으로 하드 디스크 드라이버를 제작하는 회사에서 average seek time를 구해놓음
- Rotational latency: 원하는 sector가 현재 head가 있는 곳까지 오는데 걸리는 시간
- Data transfer: 데이터를 읽는 과정
- Controller overhead: controller는 읽은 데이터를 메모리 버스 혹은 I/O 버스에 전달하는 역할. 이 때 걸리는 시간
Disk Access Example

2. Disk Performance Issues
- sector의 위치에 따라 다르기 때문에 일반적으로 하드 디스크 드라이버를 제작하는 회사에서 average seek time를 구해놓음
- disk controller는 disk의 physical sector에 바꿔줘야하는데 이 때 disk controller는 smart한 알고리즘을 사용
- host가 사용하는 것은 logical sector
- SCSI, ATA, SATA, SAS
- disk drive는 아주 작은 메모리를 가지고 있어 이 메모리가 cache와 같은 역할을 수행
- 이 메모리에 데이터를 쓸 경우 seek하고 rotaion할 필요가 없어짐
6.4 Flash Storage
Flash Types
- endurance: flash 메모리 bit에 10000번 이상 접근하면 더 이상 사용이 불가능
- flash 메모리의 여러 군데를 모두 사용하도록 해주는 기술이 필요 => wear leveling
1. NOR flash
- cell 모양이 NOR gate와 유사해서 NOR flash
- random read/write
- 임베디드 시스템의 instruction memory로 사용됨
2. NAND flash
- cell 모양이 NAND gate와 유사해서 NAND flash
- random read/write 방식이 아닌 block으로 access해야함
- 가격이 싸기 때문에 일반적인 storage로 사용
6.5 Connecting Processors, Memory, and I/O Devices
1. Interconnecting Components
- CPU, memory, I/O controlls를 연결해주는 components가 필요
- bus: shared communication channel
- 여러 개의 wire로 데이터와 control를 전송
- 여러 개가 공유하기 때문에 performance bottleneck이 생길 수 있음
- wire의 length, number of connction에 따라 성능에 제약이 받을 수 있음
- Processor-Memory busses: 짧고 속도가 빠름
- I/O busses: 길이가 길고 여러 개의 connection을 지원. bridge를 통해 메모리 버스에 연결되어 있음
2. Bus Signals and Synchronization
- data line: 실제 데이터를 전송
- control line: data의 type, transaction의 synchronize를 위해 필요한 signal을 전송
- synchronous: bus clock를 사용
- asynchronous: handshaking 방식. request를 보낸 후 acknowledge를 보내고 실제 데이터를 전송하는 방식
6.6 Interfacing I/O Devices to the Processoer, Memory, and Operating System
1. I/O Data Transfer
- Polling, interrupt-driven I/O: CPU가 개입하기 때문에 시간이 오래 걸림
- Direct memory access (DMA)
- OS가 메모리의 시작 주소를 알려주면 자동적으로 IO controller가 메모리와 device간의 데이터를 전송
- 전송이 끝나면 interrupt를 발생시켜 operation의 완료를 알려줌
- 처음 부분을 제외하고는 CPU가 개입하지 않으므로 데이터가 전송되는 동안 CPU는 다른 일을 할 수 있음
- 시스템의 throughput를 높여주는데 기여
2. DMA/Cache Interaction
- DMA는 CPU가 개입하지 않기 때문에 메모리에 있는 데이터만 읽음
- DMA가 cache에 있는 memory block의 데이터를 쓰면 cache는 잘못된 데이터를 가지고 있게 됨
- 해결 방법
- DMA가 사용하게 될 블럭을 flush block으로 만듦
- memory location을 non-cacheable로 사용 (메모리 공간이 cahce에 올라가지 않음)
3. DMA/VM Interaction
- OS는 virtual addresses를 사용하고 DMA는 physical memory를 사용
- DMA가 physical address를 사용하게 되면
- page-size chunks로 나눠져야 함
- chain multiple transfer이 발생
- 따라서 DMA가 virtual address를 사용하기 때문에 controller에서 translation이 필요
6.9 Parallelism and IO: Redundant Arrays of Inexpensive Disks
RAID(Redundant Arrays of Inexpensive Disks)
- 여러 개의 작은 disk를 사용해서 array를 구성
- parallelism을 통해 성능 향상
RAID 종류
- RAID0: no redundancy
- stripe: storage가 여러 개일 경우 data를 번갈아가면서 쓰는 방식
- stripe 방식을 사용해 성능이 향상됨
- 데이터에 오류가 발생할 경우 복원할 방법이 없음
- RAID1: Mirroring
- N+N disks로 구성. 데이터를 중복해서 쓰게 함
- 성능은 향상되지 않지만 다른 disk에 오류가 발생했을 때, 다른 disk에 데이터가 똑같이 들어있기 때문에 오류 해결이 가능 => fault-tolorance 가능
- RAID2 : ECC(Error correcting code) 지원
- N+E disk로 구성. N은 데이터를 저장하는데 사용하는 disk, E는 ECC가 저장되어 있는 disk
- data를 bit level에서 N disk만큼 나눠게 됨
- 너무 복잡해서 사용하지 않게 됨
- RAID3: Bit-Interleaved Parity
- N+1 disks
- data는 byte 단위로 N disk에 strip
- extra disk에 parity를 저장
- data를 읽을 경우 N disk에 access, data를 쓸 경우 새로운 parity를 만들어줘야하기 때문에 모든 disk access
- failure가 발생하면 parity를 사용해서 오류가 난 데이터 복원이 가능
- 많이 사용하지 않음
- RAID4: Block-Interleaved Parity
- RAID3와 유사하지만 block 단위로 한다는 것이 차이점
- N+1 disks
- data는 block 단위로 N disk에 strip
- extra disk에 blocks의 parity를 저장
- data를 읽을 때는 필요한 block이 있는 disk만 access
- data를 쓸 경우 block이 있는 disk를 읽은 후 parity disk를 access한 다음 parity를 계산하고 block이 저장되어 있는 data disk와 parity disk를 update
- failure가 발생하면 parity를 사용해서 오류가 난 데이터 복원이 가능
- 많이 사용하지 않음
- RAID5: Distributed Parity
- RAID4의 변형. parity를 어떻게 어디에 저장할 건인지에 차이가 있음
- N+1 disks
- parity block을 모든 disk에 나눠서 stripe 방식으로 저장
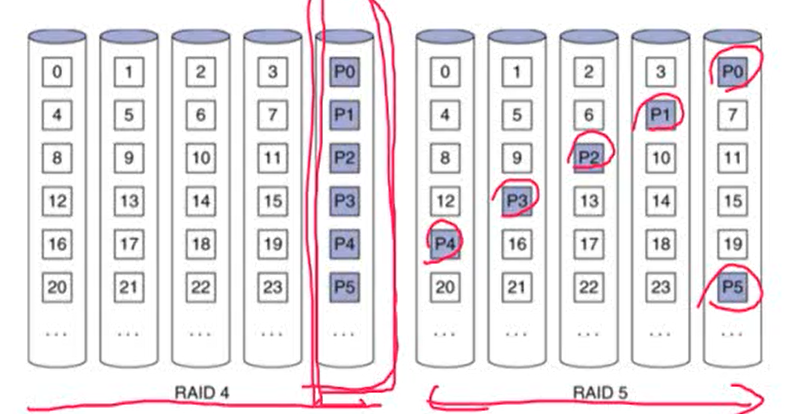
- RAID4 같은 경우 parity disk가 집중적으로 사용될 가능성이 높음. 따라서 parity disk에 오류가 발생할 확률이 높음
- ex) write이 발생할 경우 반드시 parity disk에 access해야 함
- RAID5는 parity가 분산되어 있어 IO가 균등하게 분산됨
- 어떤 하나의 disk가 집중적으로 access되어 오류가 발생할 확률이 낮음
- 모든 disk가 오류가 발생할 확률이 비슷해짐
- RAID4의 변형. parity를 어떻게 어디에 저장할 건인지에 차이가 있음
6.13 Concluding Remarks
1. IO performance measures
- throughput, response time
- dependability와 cost가 매우 중요
2. Bus
- bus는 CPU, memory, IO controller를 연결하는데 사용됨
- polling, interrupts, DMA
3. RAID
- RAID를 사용하면 performance와 dependability를 향상시킴
14주차 강의 끝!!!
게시물에 사용된 사진은 강의 내용을 캡쳐한 것입니다.

예비 백엔드 개발자