쿼리와 뮤테이션
GraphQL을 처음 접할 때는 마치 복잡한 레고 블록을 조립하는 기분이 들곤 합니다.
하지만 제대로 된 설계와 사용법을 익히면, 여러분도 손쉽게 데이터를 다루는 마법사가 될 수 있어요.
여기서는 쿼리와 뮤테이션의 차이를 중심으로, 예제 코드와 함께 자세히 설명해보겠습니다.
1. GraphQL이란 무엇인가요?
GraphQL은 클라이언트가 필요한 데이터만 골라서 요청할 수 있도록 해주는 API 쿼리 언어예요.
REST API가 여러 엔드포인트를 돌아다녀야 하는 번거로움과는 달리, GraphQL은 단 하나의 엔드포인트로 원하는 데이터를 정확히 지정해 가져올 수 있죠.
이 과정은 마치 커피숍에서 자신이 원하는 커피의 온도, 우유의 양, 시럽의 종류까지 세밀하게 주문하는 것과 비슷합니다.
2. 쿼리(Query) vs. 뮤테이션(Mutation)
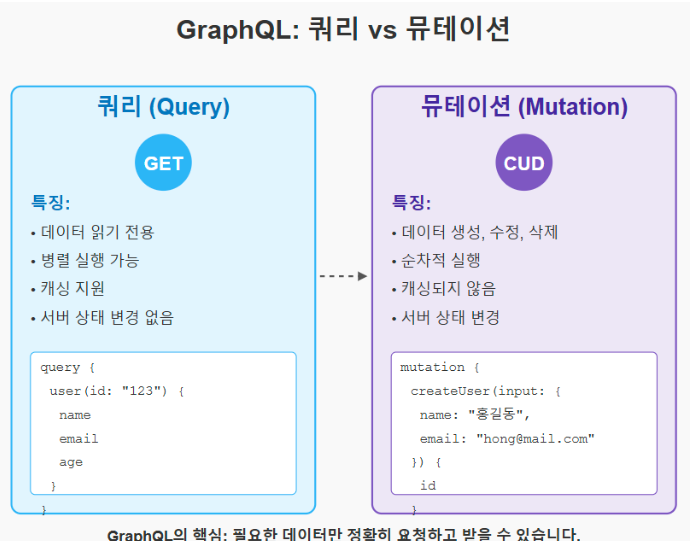
쿼리(Query)
쿼리는 데이터를 읽어오는 역할을 합니다.
- 읽기 전용: 쿼리는 서버의 상태를 변경하지 않고, 단순히 데이터를 조회합니다.
- 병렬 실행 가능: 여러 쿼리가 동시에 실행되어도 서로 간섭하지 않으므로, 병렬로 실행되어 빠른 응답을 기대할 수 있습니다.
- 캐싱 활용: 이미 받아온 데이터를 재활용할 수 있어 서버 부하를 줄이고, 응답 시간을 단축시키죠.
예를 들어, 사용자 정보를 가져올 때 쿼리를 사용하면, 필요한 필드만 지정해서 요청할 수 있습니다.
뮤테이션(Mutation)
뮤테이션은 데이터를 추가, 수정, 삭제하는 작업에 사용됩니다.
- 데이터 변경: 뮤테이션은 서버의 상태를 변화시키기 때문에, 실행 시 예상치 못한 사이드 이펙트를 고려해야 합니다.
- 순차 실행 필수: 데이터 변경은 순차적으로 실행되어야 하므로, 뮤테이션은 병렬 실행이 어려워요.
- 실시간 업데이트: 항상 최신 데이터를 요청하며 캐싱되지 않으므로, 실시간 데이터를 반영할 수 있습니다.
즉, 쿼리가 정보 조회를 위한 '검색'이라면, 뮤테이션은 '조작'에 해당한다고 볼 수 있겠죠.
3. GraphQL 쿼리 작성 예제
3-1. GraphQL 스키마 정의
스키마를 정의하는 과정은 데이터의 청사진을 그리는 작업과 같습니다.
예를 들어, 사용자 정보를 담는 스키마는 아래와 같이 구성할 수 있습니다.
type User {
id: ID!
name: String!
email: String!
age: Int
address: Address
}
type Address {
city: String
country: String
}
type Query {
user(id: ID!): User
}
위 스키마는 클라이언트가 어떤 데이터를 요청할 수 있는지 명확히 지정해줍니다.
3-2. 데이터 모델 및 서비스 생성
이제 실제 데이터를 다룰 모델과 서비스를 만들어본다면
여기서 중요한 점은 데이터베이스나 외부 소스에서 데이터를 가져오는 로직을 깔끔하게 작성하는 것입니다.
// User.java
public class User {
private String id;
private String name;
private String email;
private Integer age;
private Address address;
// 생성자, getter, setter 생략
}
// Address.java
public class Address {
private String city;
private String country;
// 생성자, getter, setter 생략
}
// UserService.java
public class UserService {
public User getUserById(String id) {
// 실제 데이터베이스나 외부 API에서 데이터를 가져오는 로직을 구현
return new User("123", "John Doe", "john@example.com", 30, new Address("New York", "USA"));
}
}
3-3. GraphQL 리졸버 생성
리졸버는 클라이언트의 요청에 맞춰 데이터를 제공하는 중개자 역할을 합니다.
@Component
public class QueryResolver implements GraphQLQueryResolver {
@Autowired
private UserService userService;
public User user(String id) {
return userService.getUserById(id);
}
}
3-4. Spring Boot 애플리케이션 설정
마지막으로, Spring Boot 애플리케이션을 구성해 GraphQL 스키마를 등록하는 과정을 살펴봅니다.
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public GraphQLSchema graphQLSchema(QueryResolver queryResolver) {
return new GraphQLSchemaGenerator()
.withOperationsFromSingleton(queryResolver)
.generate();
}
}
이처럼 쿼리 작성은 하나의 완성된 이야기처럼 이어지며, 각 단계가 자연스럽게 연결되어 데이터의 흐름을 명확하게 보여줍니다.
4. GraphQL 뮤테이션 작성 예제
4-1. GraphQL 스키마 정의
데이터를 변경하는 뮤테이션도 스키마를 정의하는 것부터 시작합니다.
여기서는 새 사용자를 생성하는 예제를 살펴보겠습니다.
type Mutation {
createUser(input: CreateUserInput!): User!
}
input CreateUserInput {
username: String!
email: String!
password: String!
}
4-2. 데이터 모델 및 서비스 생성
사용자 생성에 필요한 데이터를 담는 모델과, 실제 생성 로직을 구현하는 서비스입니다.
// CreateUserInput.java
public class CreateUserInput {
private String username;
private String email;
private String password;
// 생성자, getter, setter 생략
}
// UserService.java
public class UserService {
public User createUser(CreateUserInput input) {
// 새로운 사용자 생성 로직을 구현 (예: 데이터베이스에 저장)
return new User("456", input.getUsername(), input.getEmail(), null, null);
}
}
4-3. GraphQL Mutation 리졸버 생성
뮤테이션 리졸버는 데이터 변경 요청을 받아 실제 서비스 로직을 호출합니다.
@Component
public class MutationResolver implements GraphQLMutationResolver {
@Autowired
private UserService userService;
public User createUser(CreateUserInput input) {
return userService.createUser(input);
}
}
4-4. Spring Boot 애플리케이션 설정
쿼리와 마찬가지로, 뮤테이션 리졸버도 스키마에 포함되도록 설정해줍니다.
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public GraphQLSchema graphQLSchema(QueryResolver queryResolver, MutationResolver mutationResolver) {
return new GraphQLSchemaGenerator()
.withOperationsFromSingletons(queryResolver, mutationResolver)
.generate();
}
}
뮤테이션이 데이터베이스에 어떻게 영향을 미치는지, 그리고 왜 순차적으로 실행되어야 하는지를 이해할 수 있었습니다.
5. 실제 상황에서의 복잡한 쿼리와 중첩된 필드 활용하기
실제 커머스 플랫폼 같은 경우, 사용자, 제품, 주문, 결제, 배송 등 다양한 데이터가 서로 얽혀 있습니다.
예를 들어, 특정 주문과 관련된 모든 정보(제품, 배송, 결제)를 한 번에 요청할 수 있는 복잡한 쿼리를 작성할 수 있습니다.
이런 상황에서는 DataLoader를 활용해 중복된 데이터 요청을 최소화하고, 성능 최적화를 꾀할 수 있어요.
비유하자면, 마치 한 번의 주문으로 여러 가지 음식을 동시에 준비해주는 요리사의 손맛과도 같습니다.
또한, 로깅과 모니터링 시스템을 구축해 이상 징후를 빠르게 탐지하는 것이 중요합니다.
보안과 권한 관리도 마찬가지인데, 뮤테이션 실행 시에는 반드시 인증 및 권한 부여가 필요합니다.
실제로 여러 공격 유형에 대응하기 위해서는 정기적인 보안 검사와 감시가 필수적이라 생각합니다.
6. 마무리하며
GraphQL은 쿼리와 뮤테이션의 개념을 정확히 이해하고 적절히 활용할 때, 기존의 REST 방식보다 훨씬 더 유연하고 효율적인 데이터 처리가 가능합니다.
쿼리는 데이터를 읽어오는 '조회 요청'으로, 병렬로 실행되어 빠르게 응답을 받을 수 있고, 캐싱을 통해 서버의 부하를 줄이는 데 유리합니다.
반면, 뮤테이션은 데이터를 변경하는 '조작 요청'이기 때문에 순차 실행이 필요하며, 최신 데이터를 반영해야 하는것을 배웠습니다
