1. GraphQL 개요
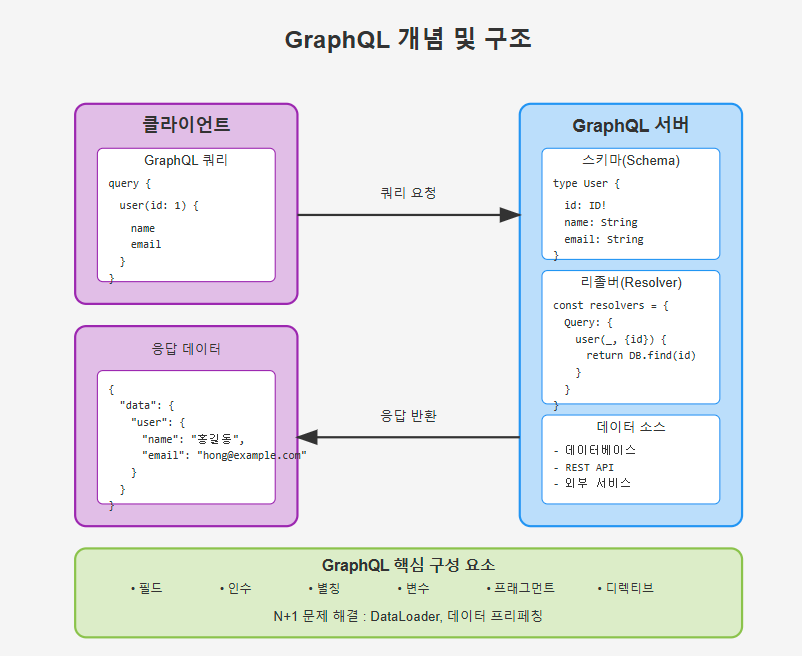
GraphQL은 클라이언트가 서버에 요청하는 데이터의 형식과 범위를 명확하게 정의할 수 있는 쿼리 언어입니다.
이 언어는 클라이언트가 필요한 데이터만 요청하고, 서버는 해당 데이터만 제공하는 방식으로 작동합니다.
이를 통해 클라이언트와 서버 간의 데이터 전송 효율성을 극대화할 수 있습니다.
- 클라이언트 쿼리: 클라이언트에서 필요한 데이터를 요청하는 부분.
- 서버 응답: 요청된 데이터가 서버에서 반환되는 부분.
2. GraphQL 쿼리 작성 및 구문 설명
- 쿼리 구문: GraphQL 쿼리는 중괄호({})로 묶어서 작성하며, 필드와 필드의 하위 필드로 구성됩니다.
각 필드는 해당 필드가 반환해야 하는 데이터 유형을 나타냅니다.
3. GraphQL 쿼리 구성 요소
- 필드(Fields): 데이터를 요청하는 기본 요소입니다. 필드는 객체 타입의 속성이나 스칼라 값일 수 있습니다.
- 인수(Arguments): 쿼리 필드에 전달되는 매개변수로, 필드의 동작을 제어합니다.
- 별칭(Alias): 같은 필드를 여러 번 요청할 때 필드의 이름을 변경하여 결과를 식별합니다.
- 변수(Variables): 쿼리의 일부 값을 동적으로 설정할 때 사용됩니다.
- 프래그먼트(Fragments): 쿼리 내에서 중복되는 필드 집합을 재사용할 수 있도록 도와줍니다.
- 인라인 프래그먼트(Inline Fragments): 특정 타입의 필드를 포함하는 쿼리를 작성할 수 있도록 합니다.
- 디렉티브(Directives): 쿼리나 스키마 정의에 메타데이터를 추가하여 동적으로 동작을 변경합니다.
4. GraphQL 서버 스키마와 상호작용
GraphQL 서버는 클라이언트의 쿼리 요청을 처리하기 위해 스키마를 사용합니다.
스키마는 데이터 타입, 필드 정의, 쿼리 및 뮤테이션, 디렉티브 등을 포함합니다.
클라이언트는 이 스키마를 기반으로 쿼리를 작성하고 서버로 요청을 보냅니다.
- 스키마 검사(Introspection Query): 클라이언트는 Introspection 쿼리를 통해 서버가 제공하는 스키마를 확인할 수 있습니다.
이는 SQL의 INFORMATION_SCHEMA와 유사한 개념으로, 클라이언트가 요청할 수 있는 타입과 필드 목록을 알 수 있게 합니다.
5. 내부 타입과 리졸버(Resolver)
- 내부 타입(Internal Types): GraphQL은 내장된 스칼라 타입과 사용자 정의 객체 타입을 지원합니다.
- 내장 스칼라 타입: String, Int, Float, Boolean, ID 등 기본적인 데이터 유형.
- 사용자 정의 객체 타입: User, Post, Comment와 같은 개발자가 정의하는 데이터 구조.
- 리졸버(Resolver): 리졸버는 GraphQL 필드에 대한 실제 데이터를 가져오는 함수입니다.
필드에 대해 쿼리가 실행될 때마다 리졸버 함수가 호출되어 값을 반환합니다.- DataFetcher: 데이터베이스나 다른 소스에서 데이터를 가져와 반환하는 역할을 합니다.
- DataLoader: 여러 필드에서 동일한 데이터를 요청할 때, 중복 요청을 최소화하고 성능을 향상시키는 역할을 합니다. 이를 통해 데이터 로딩의 효율성을 높일 수 있습니다.
6. 예를들어서..
기본 GraphQL 쿼리
query {
user(id: 1) {
name
email
posts {
title
content
}
}
}
이 쿼리는 user 필드를 요청하며, 해당 사용자의 name, email, 그리고 posts 필드(게시물의 제목과 내용)를 포함한 데이터를 요청합니다.
필드 별칭
query {
user1: user(id: 1) {
name
email
}
user2: user(id: 2) {
name
email
}
}
위 쿼리에서, user1과 user2라는 별칭을 사용하여 서로 다른 두 사용자의 데이터를 요청하고 있습니다.
변수 사용
query getUser($userId: ID!) {
user(id: $userId) {
name
email
}
}여기서 $userId는 변수를 사용하여 쿼리 실행 시 동적으로 값을 바인딩합니다.
이를 통해 여러 사용자의 정보를 한 번에 요청할 수 있습니다.
7. 리졸버 최적화 및 N+1 문제 해결
GraphQL에서는 각 필드에 대해 리졸버가 실행되므로, 여러 필드를 요청할 때 N+1 문제(불필요한 중복 데이터 요청)가 발생할 수 있습니다.
이를 해결하기 위해 DataLoader나 데이터 프리페칭(Data Prefetching) 기법을 사용할 수 있습니다.
- DataLoader: 여러 번 요청되는 데이터를 배치 처리하여 성능을 최적화합니다.
- Data Prefetching: 쿼리 실행 전에 데이터를 미리 가져와 캐시에 저장하고, 후속 요청에서는 캐시된 데이터를 사용하여 N+1 문제를 방지합니다.
DataLoader
const userBatchLoader = new BatchLoader(userIds => userManager.loadUsersById(userIds));
const userLoader = DataLoaderFactory.newDataLoader(userBatchLoader);위 코드에서는 userBatchLoader를 사용하여 배치 방식으로 데이터를 요청하고,
중복된 요청을 최소화하고 있습니다.
8. 결론
GraphQL은 효율적이고 유연한 데이터 요청 방식으로, 쿼리 언어와 서버 스키마를 통해 클라이언트와 서버 간의 데이터 전송을 최적화합니다.
리졸버와 데이터 로딩 최적화 기법을 사용하면 성능을 더욱 향상시킬 수 있으며, GraphQL의 다양한 쿼리 구성 요소를 잘 활용하면 복잡한 데이터를 효율적으로 처리할 수 있습니다.
