
Apache Flink란?
Apache Flink는 실시간 데이터 스트리밍 처리에 최적화된 분산형 데이터 처리 시스템입니다.
Flink는 데이터 스트림과 배치 작업을 모두 처리할 수 있는 유연성과 강력한 기능을 제공하며,
대규모 데이터 처리 환경에서 높은 성능을 발휘합니다.
특히 이벤트 기반 응용 프로그램이나 실시간 데이터 분석, 데이터 파이프라인 구축에 적합합니다.
Flink의 주요 특징은 다음과 같습니다
1. 실시간 스트리밍 처리
- 데이터를 지속적으로 수집하고, 처리하고, 즉각적인 결과를 제공합니다.
2. 배치 처리 지원
기존의 경계가 있는 데이터 셋(batch)을 대상으로 정렬, 통계 계산, 요약 등을 수행합니다.
3.상태 기반 처리(Stateful Processing)
스트림의 상태를 유지하여 복잡한 이벤트 간 관계를 처리합니다.
4. 분산 환경에서의 확장성
클러스터 기반으로 동작하여 높은 처리량과 확장성을 제공합니다.
5. 다양한 커넥터 지원
Kafka, Kinesis, HDFS, Elasticsearch, JDBC 등 다양한 데이터 소스 및 싱크를 지원합니다.
배치 처리(Batch Processing)란?
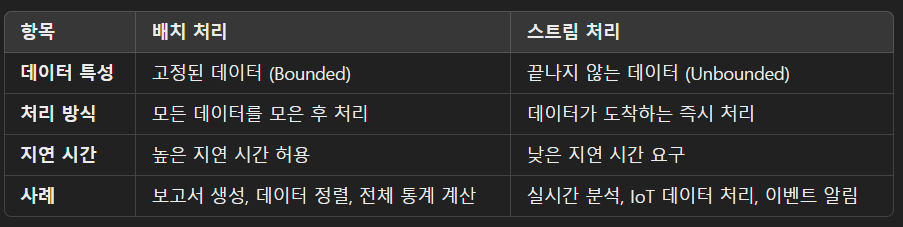
배치 처리는 경계가 있는 데이터 스트림을 처리할 때 사용되는 패러다임입니다.
즉, 고정된 데이터 셋에 대해 데이터를 수집한 뒤, 이를 한 번에 처리하여 결과를 생성합니다.
특징
완료된 데이터 셋을 처리하므로 데이터가 더 이상 변하지 않습니다.
일반적으로 높은 지연 시간(Latency)을 허용하며,
대규모 데이터를 한 번에 처리하는 데 적합합니다.
대표적 사례
- 데이터 정렬 (Sorting)
- 전체 통계 계산 (Aggregations)
- 보고서 생성
스트림 처리(Stream Processing)란?
스트림 처리는 경계가 없는 데이터 스트림을 처리합니다.
즉, 입력 데이터가 끊임없이 들어오며, 데이터는 끝나지 않을 수 있기 때문에 지속적인 실시간 처리가 필요합니다.
특징:
데이터가 도착하는 즉시 처리하며, 처리 결과를 계속 업데이트합니다.
낮은 지연 시간(Low Latency)이 중요한 환경에 적합합니다.
대표적 사례:
- 실시간 알림 시스템 (Real-time Notification)
- IoT 센서 데이터 처리
- 이벤트 기반 트랜잭션 분석
배치 처리와 스트림 처리의 차이점
Apache Flink의 실무 활용 사례
실시간 로그 처리
대규모 시스템에서 발생하는 로그 데이터를 Flink로 실시간 분석하여 이상 탐지를 수행합니다.
금융 거래 처리
은행이나 결제 시스템에서 실시간으로 거래 데이터를 처리하여 사기 탐지 및 보고를 제공합니다.
IoT 센서 데이터 분석
IoT 디바이스에서 지속적으로 생성되는 데이터를 처리하여 장비 상태를 모니터링하거나,
예측 유지보수를 구현합니다.
실시간 사용자 행동 분석
전자상거래 플랫폼에서 사용자의 클릭, 조회, 구매 데이터를 분석하여 추천 시스템에 반영합니다.
