데이터 저장하기
1.[Apache Flink] 주요 기능: Checkpointing, Kafka 통합, Windowing 완벽 하게 이해하기
Apache Flink는 실시간 데이터 스트리밍과 배치 처리에 강력한 기능을 제공합니다. Checkpointing, Kafka 통합, Windowing 처리로 데이터를 효율적으로 관리하는 방법을 정리하였습니다.
2.[구현 패턴과 활용법] 트랜잭셔널 메시징으로 데이터 일관성 유지하기

트랜잭셔널 메시징을 활용한 데이터 일관성 유지 방법에 대해 학습하였습니다. 아웃박스 패턴과 트랜잭션 로그 테일링 패턴을 통해 안정적인 시스템을 구축하기위해 포스팅하였습니다.
3.[Apache Flink]실시간 데이터 스트리밍과 배치 처리의 차이점 완벽 정리

실시간 데이터 스트리밍 처리에 최적화된 강력한 분산 데이터 처리 시스템입니다. Flink의 배치 처리와 스트림 처리의 개념과 차이를 정리하였습니다.
4.[Apache Flink] 주요 구성 요소 JobManager부터 Window까지 이해하기

Apache Flink의 주요 구성 요소인 JobManager, TaskManager, State, Connector, Window를 깊이 탐구합니다. 실시간 데이터 처리 시스템의 핵심 메커니즘과 활용 사례를 정리하였습니다.
5.[Apache Flink] 기본 문법과 주요 구성 요소 정리하기

"Apache Flink를 시작하려는 분들을 위한 필수 가이드! 실행 환경 설정, 데이터 소스 정의, 변환 연산자, 상태 관리, 윈도우 처리 등 기본 개념부터 활용 사례까지 모두 정리했습니다
6.[Airflow & Spark] 대용량 데이터 처리 자동화하는 방법

Airflow를 활용한 대용량 데이터 처리 방법을 소개합니다. XCom 한계를 극복하는 방법, 데이터베이스와 파일 시스템 활용법, 그리고 Spark 연동까지 학습한내용을 포스팅하였습니다.
7.[맵리듀스] 중간 결과 처리 과정 완벽 분석
맵리듀스(MR)은 대규모 데이터 처리의 핵심 개념 중 하나입니다. 대용량 데이터를 한 대의 컴퓨터에서 처리하는 것이 불가능하거나 매우 비효율적일 때, 분산 시스템을 사용하여 여러 컴퓨터에 작업을 분배하고 처리 후 결과를 합치는 방식이 바로 맵리듀스입니다.
8.[실시간 데이터 처리] 스파크(Spark) vs 맵리듀스(MapReduce) 메모리 기반 처리로 속도와 효율성 극대화

스파크(Spark)는 메모리 기반 처리로 대용량 데이터를 빠르게 처리합니다. 맵리듀스와의 차이를 비교하며, 성능과 효율성 측면에서 스파크의 장점을 작성하였습니다.
9.[ETL] 오라클 데이터베이스파일 vs 스트리밍 처리 방식 비교
오라클 데이터베이스와의 연결을 통해 파일 처리와 스트리밍 처리 방식을 비교합니다. 각 방식의 장단점과 이를 지원하는 ETL 툴 소개글을 포스팅 하였습니다.
10.[PostgreSQL] 성능 최적화의 Shared Buffer 완벽 학습하기

PostgreSQL 성능을 향상시키는 핵심 요소인 Shared Buffer 설정 방법을 포스팅하였습니다. 메모리 최적화를 통해 데이터베이스 성능을 극대화할 수 있습니다!
11.[MongoDB] 트랜잭션 문제 해결하기

MongoDB 트랜잭션 도입 시 발생할 수 있는 문제들과 해결 방법을 실전 코드와 함께 다뤄봅니다. 이벤트 발행, Write Conflict, 성능 최적화 등 다양한 주제를 다루어 데이터 일관성을 유지하는 방법을 배워보세요.
12.[Oracle] 한글 처리하는 초성 검색 기능 구현하기

한글 초성 검색 기능을 오라클에서 구현하고, 성능 최적화, 다국어 처리, UI/UX 개선 방법까지 자세히 다룹니다. 초성 검색의 효율적 적용법을 배우세요.
13.[ClickHouse] AI를 활용한 대규모 로그 분석 시스템 최적화 하기

ELK Stack에서 ClickHouse로의 전환 과정과 AI 모델 통합을 통한 대규모 로그 분석 시스템 최적화 사례를 공유합니다. 일 5천만 건의 로그 처리 성능을 10배 개선하고, 운영 비용을 75% 절감한 실제 프로젝트 경험을 Java 코드 레벨에서 상세히 다룹니
14.[Elasticsearch] 인덱스 재 설계와 벌크 인덱싱을 통한 처리 대규모 전자상거래 로그 시스템 성능 시키기

인덱스 설계 및 벌크 인덱싱 최적화를 통해 대규모 로그 시스템 성능을 획기적으로 향상시킨 경험을 공유합니다. 성능 개선의 핵심 전략과 구현 방법을 소개합니다
15.[Oracle] 오라클로 구현하는 초성 검색 인덱스 성능 최적화 활용 하기

초성 검색 기능을 효율적으로 구현하는 방법을 소개합니다. 초성 값 저장, 인덱스 활용, 대규모 데이터에서의 성능 최적화 전략까지 모두 담았습니다!
16.[데이터 조회] 오프셋 vs 커서 페이지네이션 완벽 비교 가이드

하루 8조 5천만 번의 검색 요청을 처리하는 구글처럼, 대용량 데이터를 효율적으로 다루는 비결은 무엇일까요? 오프셋과 커서 페이지네이션의 장단점을 비교하며 프로젝트에 적합한 페이지네이션 기법을 선택하는 방법을 알아봅니다. 데이터 일관성과 성능 최적화를 위한 필수 가이드
17.게시판 페이징, COUNT(*) 쿼리가 불러오는 재앙과 현명한 해결책

게시글 300만 건, SELECT COUNT(*) 쿼리 한 번에 DB가 멈춘다고? 대규모 서비스에서 발생하는 페이징 성능 문제를 분석하고, 커서 기반 페이징, 통계 테이블, Redis 캐싱까지 실제 서비스에서 사용하는 다양한 해결책들의 장단점을 심층적으로 비교합니다.
18.무심코 저지르는 습관, 트랜잭션 순서가 성능을 망친다
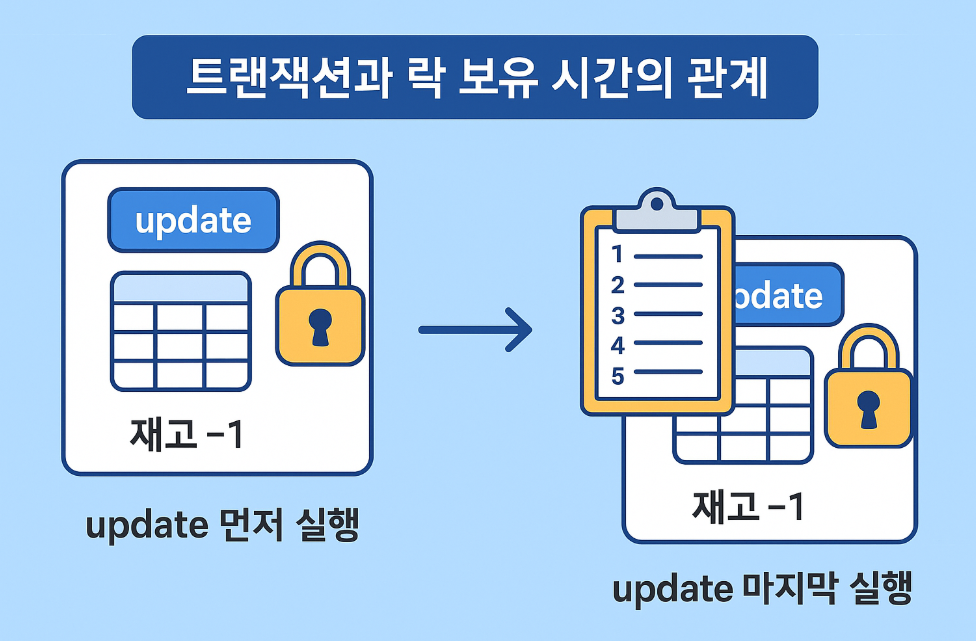
@Transactional만 걸면 끝이라고 생각했나요? 트랜잭션 내에서 UPDATE 쿼리 순서 하나만 바꿔도 성능이 수십 배 차이날 수 있습니다. 락(Lock)의 원리를 통해 동시성 문제를 해결하고, JPA의 더티 체킹이 이 문제를 어떻게 다루는지 알아봅니다.
19. 스프링 부트와 도커로 분산 머신러닝 시스템 구축하기
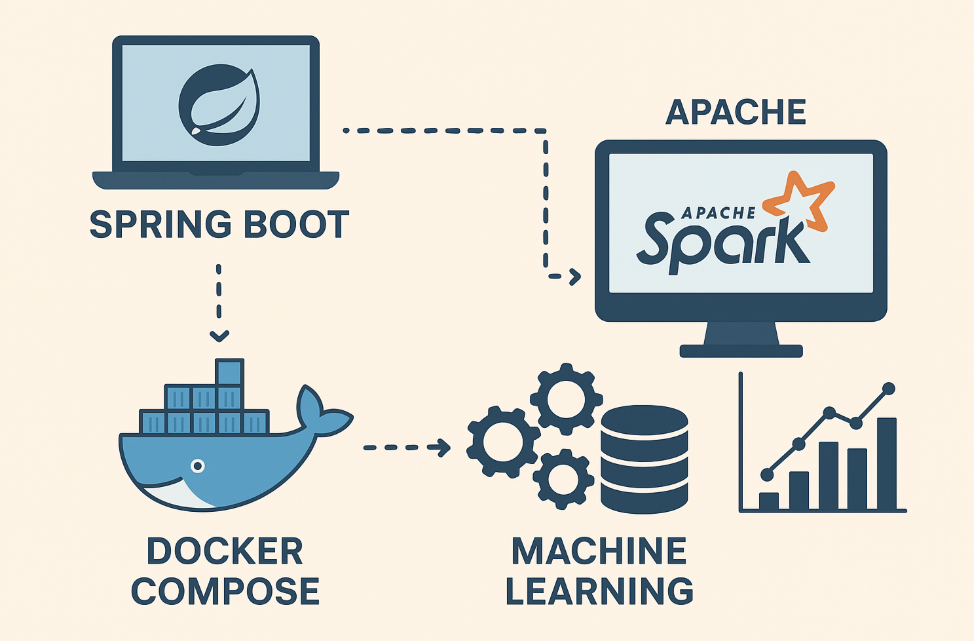
스프링 부트와 아파치 스파크를 결합해 대용량 데이터를 처리하는 분산 머신러닝 시스템을 구축하는 방법을 알려드립니다. 도커 컴포즈로 스파크 클러스터를 구성하고, 스프링에서 ML 모델을 활용하는 실용적인 예제까지 한 번에 배워보세요.
20.FDW/Gateway로 도커 컨테이너 DB Link 설정부터 연결 확인까지
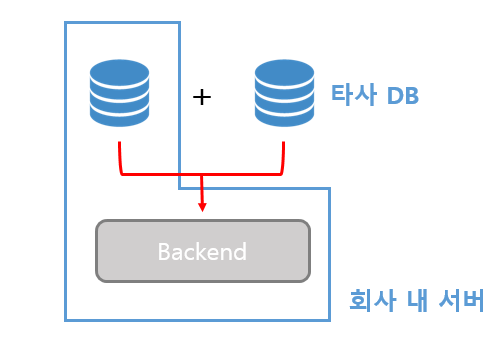
🛠️ 도커 환경에서 여러 종류의 데이터베이스를 동시에 사용하고 계신가요? PostgreSQL, Oracle, MySQL처럼 이기종 DB 간의 데이터를 연동해야 할 때, 복잡한 설정 때문에 막막하셨을 겁니다. 이 포스팅은 도커 컨테이너 환경에서 **FDW(Foreign
21.MySQL TEXT/BLOB 컬럼, CSV 없이 Oracle로 안전하게 옮기기
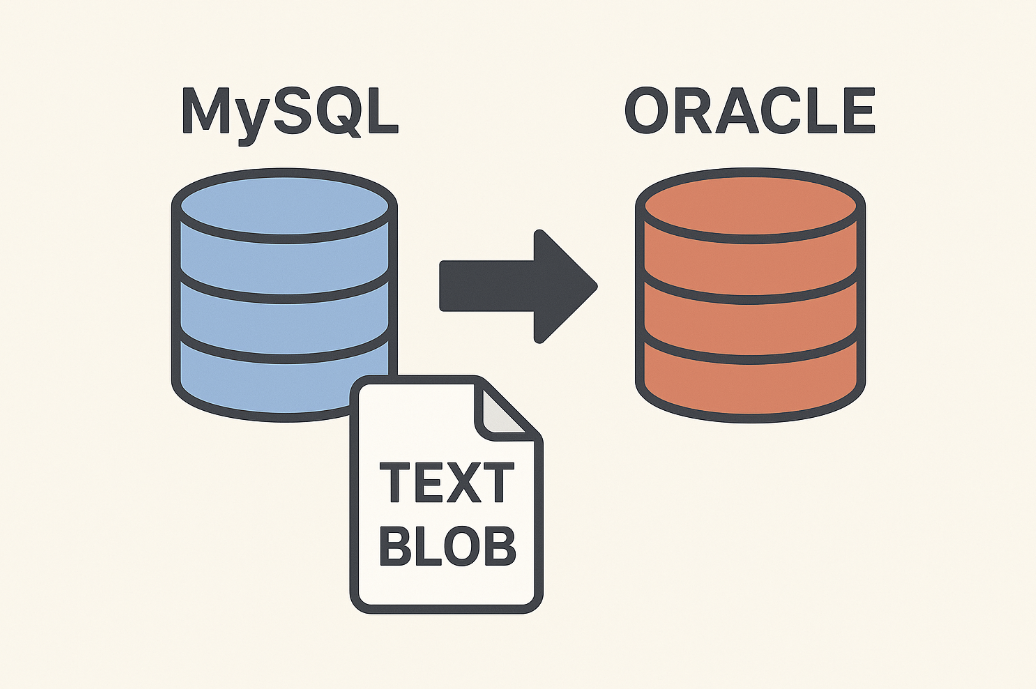
TEXT/BLOB 컬럼이 포함된 MySQL 데이터를 CSV로 옮기려다 멈칫하셨나요? 인코딩과 데이터 손상 리스크 없이 Oracle로 대용량 데이터를 안전하게 마이그레이션하는 SQL Developer 기반의 실전 해결 전략, 고민 과정, 그리고 성공 노하우를 공유합니다.
22.로그 필터링 100배로 바꾼 Aho-Corasick 알고리즘 적용한 가속화

가장 임팩트 있는 문제점과 해결책을 150자 이내로 요약하여 독자의 클릭을 유도합니다.실시간 로그 필터링 시스템이 패턴 수에 따라 기하급수적으로 느려지는 병목 현상을 겪었습니다. 기존 $O(N \times K)$ 방식 대신, Aho-Corasick 알고리즘을 도입하여
23.Msa에서 Pagination 으로 로딩 속도 빠르게하는 교훈

게시글 목록의 마지막 페이지 조회 시간이 6초 이상 소요되는 성능 문제를 커서 페이징 도입으로 0.3초까지 단축한 구체적인 쿼리 튜닝 및 구현 사례를 공유합니다
24.스키마의 속박을 넘어 임베딩과 HNSW 알고리즘 벡터 학습하기
단순한 표 형태의 정형 데이터를 넘어, AI 시대의 핵심 자산인 비정형 데이터를 어떻게 다루어야 할까요? 데이터의 의미를 다차원 수치로 변환하는 '임베딩'의 원리부터, 수억 개의 데이터 속에서 초고속으로 정답을 찾아내는 'HNSW 인덱싱'의 상세 매커니즘까지 핵심만 짚
25.초개인화 상품 추천 시스템 만들기
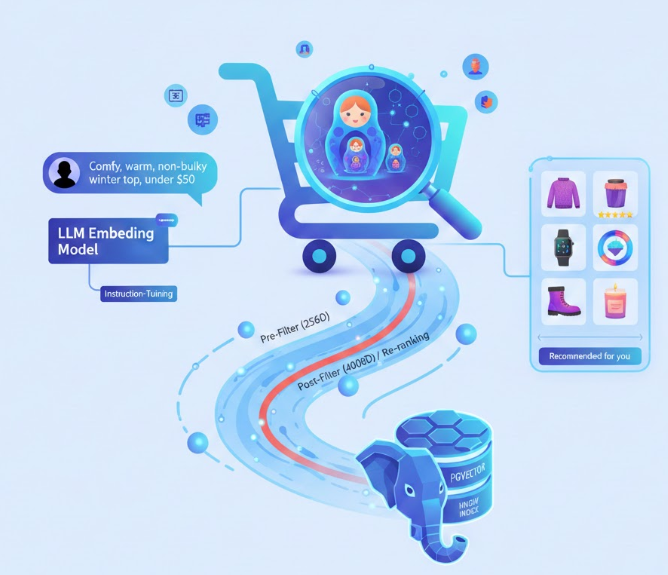
이커머스 검색, 아직도 키워드에 머무르시나요? Matryoshka Representation Learning과 PGVector를 활용해 고객의 '의도'를 파악하는 초개인화 상품 추천 시스템을 구축하세요. 성능과 비용 효율을 동시에 잡는 혁신적인 검색 아키텍처를 소개합니
26.PostgreSQL FTS의 커스텀 BM25 한계를 넘다

PostgreSQL 내장 전체 텍스트 검색(FTS)만으로는 정교한 랭킹을 구현하기 어렵습니다. 이 글에서는 FTS의 한계를 극복하고, 진정한 BM25 랭킹 모델을 DB 내부에 직접 구현하기 위한 커스텀 테이블 설계와 비동기 데이터 처리 아키텍처를 상세히 파헤쳐 봅니다.
27.대규모 문서 검색을 위한 최적의 PostgreSQL 기반 벡터 DB 최적화 처리하기

RAG 시스템 구축 시 겪는 벡터 DB 선택의 고민, 이제 끝내보세요. ChromaDB의 한계를 넘어, 실제 문서 검색 시스템에 적용하고 검증한 PostgreSQL(PGVector)과 BM25 기반의 강력한 하이브리드 검색 최적화 및 아키텍처 설계 경험을 공유합니다.
28.Named Lock의 병목을 해결하는 비동기 전략과 HikariCP 최적화 하기

MySQL Named Lock을 활용한 분산 락 설계에서 가장 큰 병목은 '락을 기다리는 동안 스레드와 DB 커넥션이 함께 점유된다'는 점입니다. 이를 해결하기 위해 사이드프로젝트에서 적용한 비동기 락 획득 전략과 HikariCP 최적화 방법으로 처리를 포스팅하게 되었습니다. 1. CompletableFuture와 별도 스케줄러 활용 MySQL N...
29.별도 벡터 DB 없이 PostgreSQL 하나로 시맨틱,키워드 검색 통합하기

벡터 검색만으로 충분할까요? PostgreSQL 하나로 벡터 연산, BM25 키워드 검색, 한국어 형태소 분석까지 통합하는 실전 가이드를 공유합니다. 복잡한 인프라 추가 없이도 강력한 하이브리드 검색을 구현하는 시니어의 설계 노하우를 지금 확인해 보세요.