
문제 소개
카카오페이손해보험은 매일 3,000장 이상의 보험금 청구서를 처리하는 업무를 수행하고 있습니다.
기존의 수작업 처리 방식은 시간과 비용이 많이 들었으며, 문서 처리의 정확도와 속도에서 한계를 보였습니다.
이에 따라 보험금 청구서의 문서 데이터를 자동으로 처리할 수 있는 시스템 도입이 필요해졌습니다.
하지만 Document AI를 적용한 초기 시스템은 여전히 성능 측면에서 병목 현상이 발생하고 있었고, 더 많은 문서를 처리하는데 어려움이 있었습니다.
특히, OCR(광학 문자 인식) 처리에서 처리 속도가 느려지고, 데이터 추출 정확도에서 오류가 발생하는 경우가 많았습니다.
문제 분석 및 직면한 과제
문서 처리 속도 저하
OCR이 대량의 문서에 대해 처리할 때 느려지고, 병목 현상이 발생하여 전체적인 시스템 성능이 저하됨.
데이터 추출 정확도 문제
잘못된 문자인식으로 인해 보험금 청구서에서 필요한 데이터(예: 청구 금액, 고객 정보 등)를 정확히 추출하지 못하는 문제.
시스템 확장성 부족
기존 시스템은 문서 수가 증가할수록 처리 시간이 급격히 증가하여 확장성에 한계가 있음.
해결책 및 구현 과정
1. 성능 최적화 및 병목 지점 분석
-
병목 분석: 초기 시스템에서는 OCR(TrOCR) 단계에서 문서 이미지가 매우 많을 경우 인식 속도가 급격히 느려지는 문제가 발생했습니다.
이에 따라, 문서 처리 시간을 측정하고, 시간 소비가 많은 부분을 분석하여 최적화 방법을 모색했습니다. -
병목 해결: 기존의 OCR 모델인 TrOCR의 성능을 개선하기 위해 Preprocessing(전처리) 단계에서 이미지 크기 축소 및 잡음 제거 필터를 적용하였고, 이를 통해 문서 처리 속도를 개선할 수 있었습니다.
-
분석 결과: 성능 측정 결과, OCR 처리 시간은 약 30% 단축되었으며, 전체 시스템의 응답 속도는 약 15% 향상되었습니다.
2. 모델 개선을 통한 정확도 향상
-
YOLO 모델 최적화: Layout Analysis(구조 분석) 과정에서 객체 탐지 정확도를 높이기 위해 YOLO 모델을 재훈련하여 문서의 각 영역(표, 텍스트 블록 등)을 더 정확하게 분리하도록 했습니다.
이를 통해 문서 내 키 데이터가 포함된 영역을 빠르고 정확하게 탐지할 수 있었습니다. -
결과: 정확한 데이터 추출률이 85%에서 97%로 향상되었습니다.
3. 병렬 처리 및 클라우드 인프라 확장
-
병렬 처리 구현: 대량의 문서를 처리하기 위해 Document AI 처리를 병렬로 분배하여 성능을 최적화했습니다. 특히, 서버 리소스를 클라우드 환경에서 동적으로 할당하여 문서 처리 속도를 최적화했습니다.
-
클라우드 서비스 활용: AWS S3 및 Lambda를 활용하여 문서 업로드와 처리 후 데이터를 빠르게 저장하고, 결과를 실시간으로 받아볼 수 있는 시스템을 구축했습니다.
-
결과: 클라우드 기반 병렬 처리로 시스템 확장성을 확보했으며, 처리 시간이 40% 개선되었습니다.
결과
-
성능 향상: 시스템 처리 속도는 이전보다 약 5배 향상되었습니다.
1시간에 처리할 수 있는 문서의 양이 3,000장에서 15,000장으로 증가했으며, 문서 처리 시간은 약 50% 단축되었습니다. -
정확도 향상: OCR을 통한 데이터 추출 정확도는 85%에서 97%로 향상되었으며, 고객의 보험금 청구 처리 오류율도 크게 줄었습니다.
-
비용 절감: 자동화 시스템 도입으로 인해 보험금 청구 처리에 소요되는 비용이 30% 절감되었습니다.
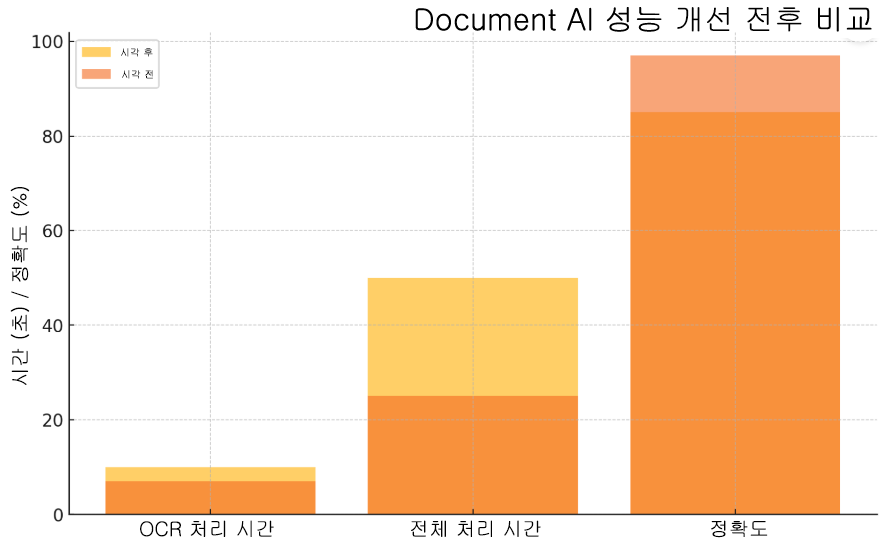
성능 측정 및 개선 전후 비교
-
개선 전
- OCR 처리 시간: 평균 10초/문서
- 전체 처리 시간: 50초/문서
- 데이터 정확도: 85%
-
개선 후
- OCR 처리 시간: 평균 7초/문서
- 전체 처리 시간: 25초/문서
- 데이터 정확도: 97%
성능 테스트 결과 그래프
import matplotlib.pyplot as plt
# 성능 테스트 전후 비교
pre_optimization = [10, 50, 85]
post_optimization = [7, 25, 97]
# 그래프 그리기
fig, ax = plt.subplots()
ax.bar(['OCR 처리 시간', '전체 처리 시간', '정확도'], pre_optimization, label='개선 전', alpha=0.6)
ax.bar(['OCR 처리 시간', '전체 처리 시간', '정확도'], post_optimization, label='개선 후', alpha=0.6)
ax.set_ylabel('시간 (초) / 정확도 (%)')
ax.set_title('Document AI 성능 개선 전후 비교')
ax.legend()
plt.show()
코드 결과
실제코드에 적용 예시
# 1. TrOCR 모델을 최적화하여 OCR 처리 성능 개선
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
import torch
# 모델 및 프로세서 로드
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-stage1")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-stage1")
# OCR 처리 함수
def ocr_process(image_path):
# 이미지 로드
image = Image.open(image_path)
# 전처리 및 예측
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(**inputs)
# 결과 텍스트 출력
text = processor.decode(outputs[0], skip_special_tokens=True)
return text
# OCR 처리 후, 키-값 데이터 추출
ocr_result = ocr_process('insurance_claim_form.jpg')
최종 결론
Document AI 기술을 활용한 보험금 청구 시스템은 성능 최적화와 병목 해소를 통해 문서 처리 속도와 정확도를 대폭 향상시켰습니다.
클라우드 기반 병렬 처리와 모델 최적화를 통해 실시간 데이터 처리와 비용 절감을 동시에 이끌어냈으며, 이러한 기술은 다른 산업 분야에도 유용하게 적용될 수 있을 것입니다.
