LLM과 RAG의 핵심, 임베딩 제대로 이해하기
안녕하세요!
오늘은 LLM(Large Language Model)과 RAG(Retrieval-Augmented Generation)의 핵심 기술인 '임베딩(Embedding)'에 대해 자세히 알아보는 시간을 갖겠습니다.
임베딩은 우리가 사용하는 언어를 컴퓨터가 이해할 수 있는 숫자 형태로 변환하는 과정으로, LLM과 RAG가 효과적으로 작동하는 데 필수적인 요소입니다.
1. 임베딩이란 무엇인가? - LLM 관점
LLM에서 임베딩은 토큰(단어, 문장 등 언어의 최소 단위)을 특정 차원의 벡터로 변환하는 과정을 의미합니다.
이 벡터는 단순히 숫자의 나열이 아니라, 신경망 학습을 통해 해당 토큰의 의미를 내포하게 됩니다.
-
토큰 추출 및 벡터화: 대량의 기초 데이터셋(예: 네이버 3년치 뉴스 데이터)을 학습하면, 모델은 텍스트에서 토큰을 추출하고 각 토큰을 고정된 차원의 벡터로 변환합니다.
-
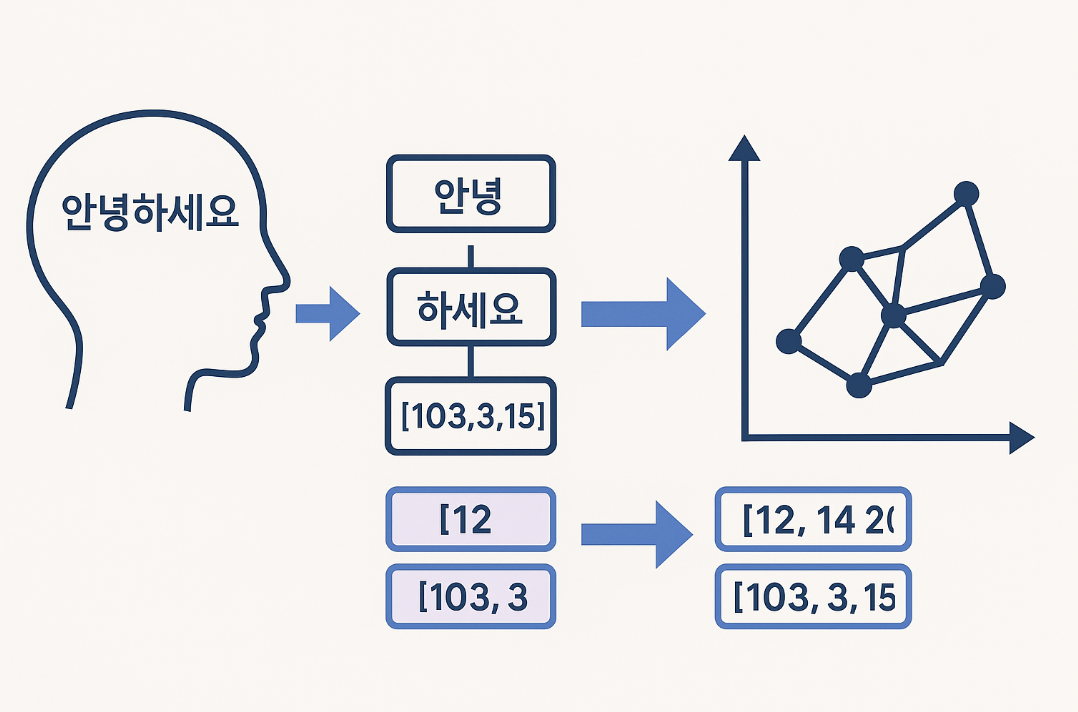
예시: "안녕하세요" -> [안녕, 하세요]
-
안녕: [12, 14, 20]
-
하세요: [103, 3, 15]
-
동일 차원의 벡터와 시맨틱 공간: 모든 토큰은 동일한 차원의 벡터가 됩니다.
이 벡터 공간 내에서 특정 차원은 유사한 시맨틱(의미)을 갖게 됩니다.
즉, 토큰(문자)이 여러 의미가 부여된 숫자의 집합(벡터)으로 인식되는 것입니다. -
LLM의 작동 방식
"궁금하면 스터디는 스터디그룹" 이라는 문장을 예로 들면, -
토큰화: [궁금하면스터디, 는, 스터디, 그룹]
-
각 토큰에 대한 초기 임베딩 벡터 생성: [[10, 23, 56], [32, 11, 19], [23, 40, 17], [32, 55, 67]]
-
어텐션(Attention) 및 FFN(Feed-Forward Network)을 통해 문맥을 반영한 새로운 임베딩 벡터 생성: [[78, 34, 77], [43, 7, 8], [55, 4, 12], [13, 17, 22]]
-
LLM은 이 벡터를 기반으로 다음 토큰을 예측하거나 특정 작업을 수행합니다.
예를 들어, 마지막 벡터 [13, 17, 22]를 사용하여 '입니다' 토큰을 선택할 수 있습니다.
2. 임베딩이란 무엇인가? - RAG 관점
RAG에서 임베딩은 모든 토큰의 벡터를 '풀링(Pooling)'이라는 과정을 통해 결합한 값을 의미합니다.
LLM이 개별 토큰의 문맥적 의미를 다루는 데 비해, RAG는 문장이나 문서 전체의 의미를 하나의 벡터로 응축하는 데 중점을 둡니다.
-
의미 응축과 차원 유지: 토큰 하나가 4096차원이라도, 100개의 토큰으로 이루어진 문장 전체의 임베딩 결과는 여전히 4096차원입니다.
토큰의 각 차원이 시맨틱 공간을 나타내므로, 여러 토큰의 결합을 통해 문장 전체의 시맨틱이 강화됩니다. -
시맨틱 통합 (Semantic Aggregation) 및 풀링(Pooling): 토큰 결합을 '시맨틱 애그리게이션(semantic aggregation)'이라고 하며, 이를 수행하는 방법이 '풀링'입니다.
-
산술 평균 (Mean Pooling): 모든 토큰 벡터의 평균값을 사용합니다.
-
최대값 (Max Pooling): 각 차원별로 최대값을 사용합니다.
-
어텐션 가중치 (Attention-Weighted Pooling): 어텐션 메커니즘을 통해 중요한 토큰에 더 높은 가중치를 부여하여 결합합니다.
-
-
풀링의 이유: 단순히 모든 토큰을 합치는 이유는 임베딩 모델 학습 시 이미 토큰이 다양한 문장에서 학습되어 해당 차원에 문맥 정보가 반영되어 있기 때문입니다.
-
RAG의 작동 방식
"궁금하면 스터디는 스터디그룹" 이라는 문장을 예로 들면,-
토큰화 및 임베딩 벡터 생성: [[10, 23, 56], [0, 0, 0], [23, 40, 17], [32, 55, 67]] (여기서는 '는'과 같은 조사에는 의미가 적어 [0,0,0]으로 표현했다고 가정)
-
풀링: [34, 55, 89] (이 벡터는 '궁금하면스터디는 스터디그룹'이라는 문장 전체의 의미를 나타냄)
-
리트리버(Retriever) 단계: 이 벡터를 사용하여 벡터 데이터베이스에서 가장 유사한 벡터를 찾아내고, 해당 벡터에 연결된 문서를 얻어옵니다.
-
3. RAG 임베딩 모델의 특징
RAG를 위한 임베딩 모델은 LLM과 완전히 다르게 학습됩니다.
-
LLM 학습: 각 토큰이 문맥과 위치를 고려하여 다음 토큰을 예상하도록 학습됩니다.
즉, 순차적인 정보 흐름과 예측에 초점을 맞춥니다. -
RAG 학습: 풀링을 통한 토큰 결합 벡터가 특정 시맨틱에 부합하도록 학습됩니다.
문장이나 문서 전체의 의미론적 유사성을 파악하는 데 중점을 둡니다. -
임베딩 모델의 토큰 벡터 차원 < LLM 모델의 토큰 벡터 차원
-
LLM용 토큰은 위치와 어텐션을 고려한 시맨틱 차원이 더 많이 필요합니다.
-
RAG용 토큰은 모든 위치와 관계를 뭉쳐서 오직 의미적 중요성만 필요하므로, 보통 LLM의 절반 크기(예: 2천 차원의 RAG 임베딩은 4천 차원의 LLM과 대등한 의미 공간을 가질 수 있음)로도 충분합니다.
-
-
모델 학습 데이터셋의 중요성: 임베딩 모델의 학습 데이터셋은 실제 사용에 큰 영향을 미칩니다.
-
청크 크기의 적절성: 학습이 4문장 단위로 이루어졌는데, 실제 검색 시 청크가 20문장이면 의미가 희석될 수 있습니다.
-
학습셋의 도메인: 특정 분야(예: 법률, 의학)로 토큰 벡터가 조정되어 있다면, 다른 분야에서는 의미가 왜곡될 수 있습니다.
-
문체: 학습셋의 문체
(예: 논문체, 소셜 미디어체, 상담체)에 따라 적합성이 달라집니다.
-
-
싱글 또는 페어 데이터
-
페어 데이터: "몸에 해로운 음료는?" -> "콜라, 사이다"와 같이 질의에 매칭되는 답변 쌍으로 학습하면, 질문에 부합하는 토큰 벡터가 생성됩니다.
-
싱글 데이터: "콜라에 나쁜 성분이 있다"와 같은 단일 문장으로만 학습하면, "콜라는 몸에 해롭나?"와 같은 질문에 대한 임베딩 일치도가 낮아질 수 있습니다.
-
4. RAG 임베딩 - 희소 벡터 (Sparse Vector)
희소 벡터는 특정 토큰의 존재 여부와 빈도에 기반한 벡터입니다.
전통적인 정보 검색 방식에서 주로 사용됩니다.
-
주요 솔루션: 엘라스틱서치(Elasticsearch), RDB 풀텍스트 인덱싱, 윈도우 파일 인덱싱 등이 있습니다. 최근에는 벡터 DB가 하이브리드 질의 지원을 위해 희소 벡터 기능을 내장하기도 합니다.
-
강점: 질의를 벡터로 변환하고 유사성을 계산하는 과정이 작은 비용으로 해결됩니다.
BM25(TF-IDF 변형)와 같은 알고리즘을 사용하여 유사성을 평가하며, CPU 연산으로도 충분합니다.
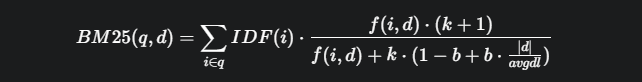
-
f(i,d): 문서 d에서 단어 i의 빈도
-
∣d∣: 문서 d의 길이
-
avgdl: 평균 문서 길이
-
k,b: 하이퍼파라미터 (보통 k=1.2,b=0.75)
-
단점
- 토큰이 추가되거나 삭제되면 전체 재인덱싱이 필요합니다.
- 토큰 수가 많아질수록 벡터 차원이 증가합니다.
-
예시
-
시스템 내 모든 토큰: [0:안녕, 1:궁금하면스터디, 2:스터디, 3:RAG]
-
데이터: "궁금하면스터디는 스터디 그룹이며 궁금하면스터디는 최근 RAG스터디를 진행 중" -> 빈도 벡터: [0, 2, 2, 1] (궁금하면스터디 2번, 스터디 2번, RAG 1번)
-
사용자 질의: "RAG를 공부하기 위한 스터디 추천해줘" -> 빈도 벡터: [0, 0, 1, 1] (스터디 1번, RAG 1번)
-
유사도 비교(BM25 사용)를 통해 [0, 2, 2, 1] 데이터가 적합하다고 판단됩니다.
-
5. RAG 임베딩 - 밀집 벡터 (Dense Vector)
밀집 벡터는 모든 차원에 0이 아닌 값을 가지며, 토큰의 의미를 다차원 공간에 표현합니다.
희소 벡터보다 더 정교한 의미론적 유사성 검색이 가능합니다.
-
주요 솔루션: 벡터 데이터베이스(Vector DB), PostgreSQL 벡터 지원, 엘라스틱서치 벡터 지원 등이 있습니다.
-
강점: 질의를 의미론적으로 분석하여 유사한 정보를 가져옵니다.
"사과"라는 단어를 검색하면 "과일"과 관련된 정보도 찾을 수 있습니다. -
단점: 비용이 크고, 의미 부여에 따라 불일치 가능성이 높습니다.
-
불일치 원인: 임베딩 모델의 학습 구조와 구축된 데이터 구조, 사용자 질의, 도메인, 또는 기타 의미론적인 부분의 불일치가 발생할 수 있습니다.
-
단점 보완 (정확성 향상)
- 질의 변형: 질의를 임베딩 모델의 학습 구조에 맞게 변형하거나 재작성합니다.
- 데이터 변형: 데이터를 임베딩 모델의 학습 구조에 맞게 변형합니다.
이러한 변형은 큰 유지보수 비용과 자동화된 프로세스를 필요로 하며, 실행 관련 비용과 정확성 사이에 트레이드오프가 존재합니다.
-
유사도 평가:
FAISS(Facebook AI Similarity Search)와 같은 라이브러리를 사용하며, 내적을 정규화한 뒤 코사인 유사도를 주로 사용합니다.
GPU 연산이 필수적입니다. -
유사도 개선 전략
- 질의 분해: 모델 학습셋과 비슷한 구조로 질의를 분해하거나 재작성 후 임베딩합니다.
- 다중 범주: 다양한 관점으로 원본 데이터를 여러 개로 만들어 복합적으로 비교합니다.
- 하이브리드 질의: 키워드 검색
(희소 벡터)과 임베딩 유사도(밀집 벡터)를 동시에 진행하여 상호 보완합니다. - 질의 구조: 데이터를 정해진 질의 구조에 맞게 재작성하여 비교합니다.
- 메타 필드 병합 질의: 본문과 무관한 필드값(메타데이터)으로 질의한 결과와 본문의 임베딩 유사도를 복합적으로 비교합니다. (DB 기능 활용)
-
메타 필드 병합 질의 예시
- DB 구조: embedding (밀집 벡터), meta (메타데이터, 예: {a:3...}), contents (문서 내용)
- 사용자 질의: "a가 5 이상인 스터디 그룹은?"
-
처리 과정
-
질의 분해: meta['a'] > 5 조건과 "스터디 그룹"에 대한 임베딩 벡터 (예: [1, 35, 56, 6, 32...])로 분해됩니다.
-
검색: 메타 검색을 통해 meta['a'] > 5인 문서를 필터링하고, 동시에 벡터 유사도 비교를 통해
"스터디 그룹"과 유사한 문서를 찾습니다. -
결과: 필터링된 문서 중 벡터 유사도가 높은 "궁금하면스터디..."과 같은 문서가 검색됩니다.
-
임베딩은 LLM과 RAG의 성능을 좌우하는 핵심 기술이며, 희소 벡터와 밀집 벡터는 각각의 장단점을 가지고 있습니다.
사용 사례와 데이터 특성에 따라 적절한 임베딩 방식과 유사도 개선 전략을 선택하는 것이 중요합니다.
앞으로도 임베딩 기술은 LLM과 RAG의 발전에 따라 더욱 정교해지고 다양한 형태로 발전할 것입니다.
결론 및 느낀점
임베딩, LLM과 RAG의 심장
지금까지 LLM과 RAG의 핵심 기술인 '임베딩'에 대해 깊이 있게 살펴보았습니다.
언어를 컴퓨터가 이해할 수 있는 숫자 형태로 변환하는 이 과정은 단순한 데이터 변환을 넘어, 인공지능이 인간의 언어를 '이해'하고 '활용'하는 데 필수적인 다리 역할을 합니다.
LLM 관점에서 임베딩은 개별 토큰이 문맥 속에서 어떤 의미를 갖는지, 그리고 다음 토큰을 예측하는 데 어떻게 기여하는지를 나타내는 다차원 벡터입니다.
이는 마치 우리 뇌가 단어 하나하나의 의미뿐 아니라 문장 전체의 흐름과 뉘앙스를 파악하듯이, 언어 모델이 정교한 예측과 생성 작업을 수행할 수 있도록 돕습니다.
특히 어텐션 메커니즘을 통해 문맥적 중요성을 반영하는 방식은 언어의 복잡성을 포착하는 임베딩의 힘을 보여줍니다.
RAG 관점에서 임베딩은 문장이나 문서 전체의 의미를 하나의 압축된 벡터로 표현하는 데 중점을 둡니다.
이는 방대한 정보 속에서 사용자의 질의와 의미적으로 가장 유사한 문서를 빠르게 찾아내는 '검색' 과정의 핵심입니다.
희소 벡터가 키워드 기반의 전통적인 검색 효율성을 제공한다면, 밀집 벡터는 더 넓은 의미론적 유사성을 파악하여 검색의 정확도와 유연성을 크게 향상시킵니다.
특히 임베딩 모델의 학습 데이터셋이 실사용 환경과 얼마나 부합하는지가 검색 품질에 결정적인 영향을 미친다는 점은, 고품질의 RAG 시스템 구축에 있어 데이터의 중요성을 다시 한번 강조합니다.
결론적으로, 임베딩은 LLM이 언어를 생성하고 이해하는 창조의 불씨이자, RAG가 방대한 지식 속에서 필요한 정보를 찾아내는 탐색의 나침반이라고 할 수 있습니다.
두 기술 모두 임베딩의 정교함과 효율성에 크게 의존하며, 이는 앞으로 AI가 더욱 인간의 언어와 상호작용하는 데 있어 임베딩 기술의 지속적인 발전이 필수적임을 시사합니다.
이번 포스팅을 통해 임베딩이 단순한 기술 용어를 넘어, 인공지능이 우리 삶에 더욱 밀접하게 다가오는 데 어떤 중요한 역할을 하는지 이해하는 데 도움이 되었습니다.
